







机器学习概述
1.1机器学习(Machine Learning ML):是指从有限的观测数据中学习或猜测出具有的一般性的规律,并利用这些规律对数据进行预测的方法,是人工智能一个重要的分支。
1.2 传统机器学习的数据处理过程:

上述流程中特征处理和预测两部分是分开进行处理的,传统机器模型一般关注最后一步即构造预测函数,但在实际操作中不同的预测模型性能相差不多,
因此前三步的特征处理对最后系统的准确性有着十分重要的作用。而特征处理一般需要人工进行利用人类的经验选取最好的特征,因此许多机器学习的问题
变成了特征工程问题:数据预处理、特征提取、特征转换等。
1.3表示学习:如果有一种算法可以自动的学习出有效的特征并最终提高机器学习模型的性能,那么这种学习就可以成为表示学习。为了提高机器学习系统的准确性,
我们需要将输入信息转换为有效的特征。
1.4局部式和分布式:在机器学习中通常用局部式和分布式来表示特征。以颜色表示为例,我们可以用很多词来形容不同的颜色1,除了基本的“红” “蓝”“绿”“白”“黑”等之外,还有很多以地区或物品命名的,比如“中国红”“天蓝 色”“咖啡色”“琥珀色”等.如果要在计算机中表示颜色,一般有两种表示方法. 一种表示颜色的方法是以不同名字来命名不同的颜色,这种表示方式叫 作局部表示,也称为离散表示或符号表示.局部表示通常可以表示为one-hot 向 量的形式. one-hot 向 量 参 见 第A.1.4节. 假设所有颜色的名字构成一个词表 𝒱,词表大小为 |𝒱|.我们可以用 一个|𝒱|维的one-hot向量来表示每一种颜色.在第𝑖 种颜色对应的one-hot向量 中,第𝑖 维的值为1,其他都为0.
另一种表示颜色的方法是用RGB值来表示颜色,不同颜色对应到R、G、B三 维空间中一个点,这种表示方式叫作分布式表示. 将分 布 式 表 示叫 作分 散式表示可能更容易 理解,即一种颜色的语 义分散到语义空间中 的不同基向量上. 分布式表示通常可以表示为低 维的稠密向量. 和局部表示相比,分布式表示的表示能力要强很多,分布式表示的向量维度 一般都比较低.我们只需要用一个三维的稠密向量就可以表示所有颜色.并且, 分布式表示也很容易表示新的颜色名.此外,不同颜色之间的相似度也很容易计算
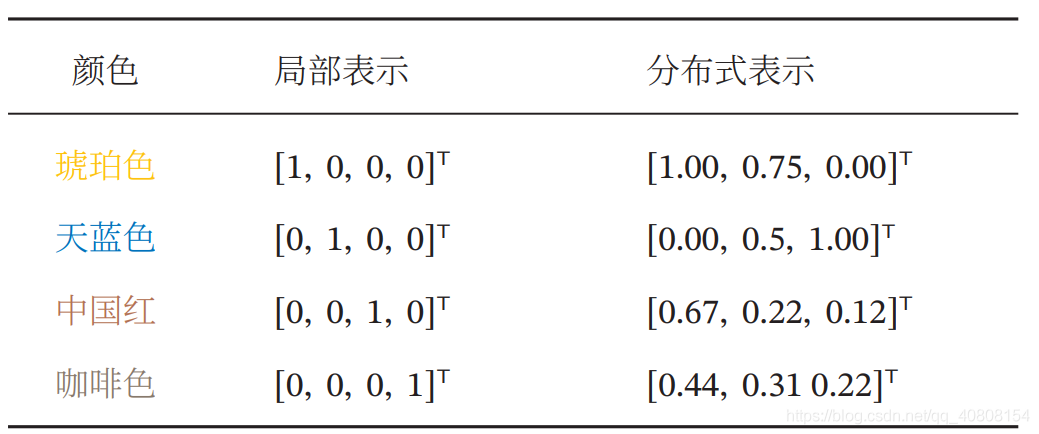
下图展示了一个3维one-hot向量空间和一个2维嵌入空间的对比.图中有 三个样本 𝑤1,𝑤2 和 𝑤3.在 one-hot 向量空间中,每个样本都位于坐标轴上,每个 坐标轴上一个样本.而在低维的嵌入空间中,每个样本都不在坐标轴上,样本之 间可以计算相似度.
1.5深度学习(Deep Learning):是机器学习的一个子问题,其主要目的就是从数据中自动学到有效的特征表示。深度学习的数据处理过程如下:

深度学习通过多层次的转换,把原始数据变成更高层次更抽象的表示,从而避免特征工程。
1.5贡献度分配问题:即一个系统中的不同组件或其参数对最终系统输出的结果的影响或贡献。深度学习将原始的特征数据经过多步的特征转换得到一种特征表示,并进一步输入到预测函数得到最终结果,深度学习需要解决的关键问题是贡献度分配问题。以下围棋为例,一盘棋的结果只有两种:要么输要么赢,我们会思考那几步导致了输的结果或者赢的结果,如果判断每一步棋的贡献就是贡献度分配问题。这是一个比较困难的问题。
目前深度学习采用的是神经网络模型,主要原因是神经网络模型可以使用误差反向传播算法,从而可以比较好的解决贡献度分配问题。
1.6神经网络:是指由很多人工神经元构 成的网络结构模型,这些人工神经元之间的连接强度是可学习的参数。
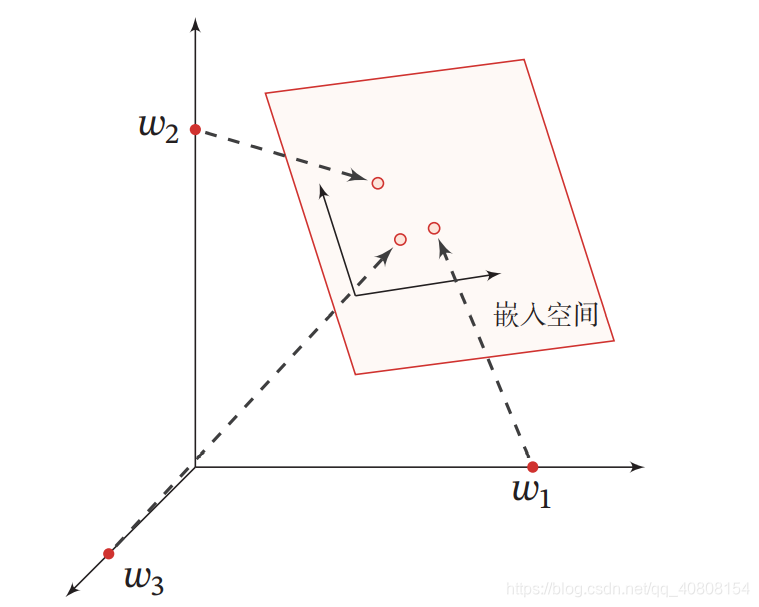
神经元可以接收其他神经元的信息,也可以发送信息给其他神经元.神经元 之间没有物理连接,两个“连接”的神经元之间留有 20 纳米左右的缝隙,并靠突 触(Synapse)进行互联来传递信息,形成一个神经网络,即神经系统.突触可以 理解为神经元之间的连接“接口”,将一个神经元的兴奋状态传到另一个神经元. 一个神经元可被视为一种只有两种状态的细胞:兴奋和抑制.神经元的状态取决 于从其他的神经细胞收到的输入信号量,以及突触的强度(抑制或加强).当信 号量总和超过了某个阈值时,细胞体就会兴奋,产生电脉冲.电脉冲沿着轴突并 通过突触传递到其他神经元
典型的神经元结构如下:
(1) 细胞体(Soma)中的神经细胞膜上有各种受体和离子通道,胞膜的受体可与相应的化学物质神经递质结合,引起离子通透性及膜内外电位差发生改变,产生相应的生理活动:兴奋或抑制.
(2) 细胞突起是由细胞体延伸出来的细长部分,又可分为树突和轴突. a ) 树突(Dendrite)可以接收刺激并将兴奋传入细胞体.每个神经元可 以有一或多个树突. b ) 轴突(Axon)可以把自身的兴奋状态从胞体传送到另一个神经元或 其他组织.每个神经元只有一个轴突.
一个人的智力不完全由遗传决定,大部分来自生活经验,也就是说人脑神经网络是一个具有学习能力的系统。那么人脑的神经元是如何学习呢?在人脑神经网络中,每个神经元本身并不重要,重要的是神经元如何组成网络.不同神经元之间的突触有强有弱,其强度是可以通过学习(训练)来不断改变的,具有一定的可塑性:
“当神经元 A 的一个轴突和神经元 B 很近,足以 对它产生影响,并且持续地、重复地参与了对神经元 B 的兴奋,那么在这两个神 经元或其中之一会发生某种生长过程或新陈代谢变化,以致神经元 A 作为能使 神经元B兴奋的细胞之一,它的效能加强了.”这个机制称为赫布理论(Hebbian Theory)或赫布规则(Hebbian Rule,或 Hebb’s Rule).如果两个神经元总是相 关联地受到刺激,它们之间的突触强度增加.这样的学习方法被称为赫布型学习 (Hebbian learning).Hebb认为人脑有两种记忆:长期记忆和短期记忆.短期记 忆持续时间不超过一分钟.如果一个经验重复足够的次数,此经验就可储存在长 期记忆中.短期记忆转化为长期记忆的过程就称为凝固作用.人脑中的海马区为 大脑结构凝固作用的核心区域.
1.7.常用的两个深度学习框架:
(1)TensorFlow:由 Google 公司开发的深度学习框架,可以在任意具 备CPU或者GPU的设备上运行.TensorFlow的计算过程使用数据流图来表示. TensorFlow 的名字来源于其计算过程中的操作对象为多维数组,即张量(Tensor).TensorFlow 1.0版本采用静态计算图,2.0 版本之后也支持动态计算图
(2) PyTorch:由 Facebook、NVIDIA、Twitter 等公司开发维护的深度学习框架,其前身为 Lua 语言的 Torch3.PyTorch 也是基于动态计算图的框架,在需要动态改变神经网络结构的任务中有着明显的优势.
1.8.机器学习的三要素:模型、学习准则、优化算法。
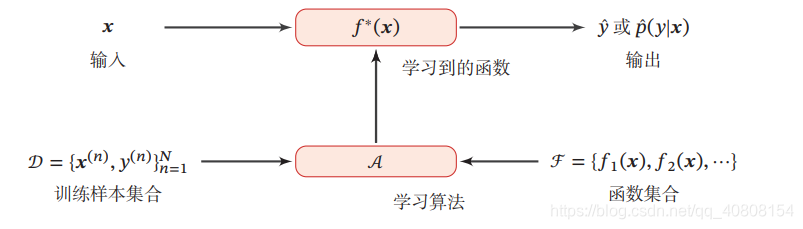
下图是机器学习系统示例:对一个预测任务,输入特征向量为 𝒙,输出标签为𝑦,我们选择一个函数集合ℱ,通过学习算法𝒜和一组训练样本𝒟,从ℱ 中学习到函数𝑓 ∗ (𝒙).这样对新的输入𝒙,就可以用函数𝑓 ∗ (𝒙)进行预测.
1.8模型:线性模型和非线性模型
(1)线性模型的假设空间为一个参数化的线性函数族,即 对于分类问题,一般为 广义线性函数,𝑓(𝒙; 𝜃) = 𝒘T𝒙 + 𝑏, 其中参数𝜃 包含了权重向量𝒘和偏置𝑏.
(2)广义的非线性模型可以写为多个非线性基函数𝜙(𝒙)的线性组合 𝑓(𝒙; 𝜃) = 𝒘T𝜙(𝒙) + 𝑏,其中𝜙(𝒙) = [𝜙1 (𝒙), 𝜙2 (𝒙), ⋯ , 𝜙𝐾(𝒙)]T 为𝐾 个非线性基函数组成的向量,参数 𝜃 包含了权重向量𝒘和偏置𝑏.
1.9学习准则:损失函数和风险最小化准则
(1)损失函数(Loss Function):是一个非负实数函数,用来量化模型预测和真实数据之间的差异。有以下几种常用的损失函数:
1. 0-1 损失函数 :最直观的损失函数是模型在训练集上的错误率,即0-1 损失函数 (0-1 Loss Function):
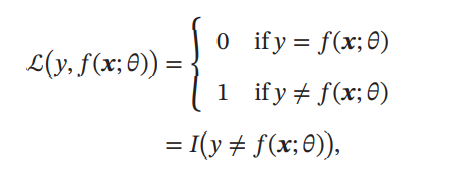
其中𝐼(⋅)是指示函数.
虽然0-1损失函数能够客观地评价模型的好坏,但其缺点是数学性质不是很好:不连续且导数为0,难以优化.因此经常用连续可微的损失函数替代 。
2. 平方损失函数:(Quadratic Loss Function):经常用在预测标签𝑦 为实数值的任务中,定义为 :
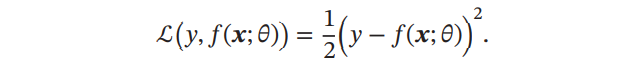
平方损失函数一般不适用于分类问题.为什么呢?假设分类问题的类别是1,2,3,那么对于一个真实类别样本x来说,模型分类的结果是1或3,平方损失函数得到的结果都是一样的,显然不合理。
3.交叉熵损失函数(Cross-Entropy Loss Function):一般用于分类问题,主要用于度量两个概率分布间的差异性。假设样本的标签 𝑦 ∈ {1, ⋯ , 𝐶} 为离散的类别,模型 𝑓(𝒙; 𝜃) ∈ [0, 1]𝐶 的输出为类别标签的条件概率分布,即
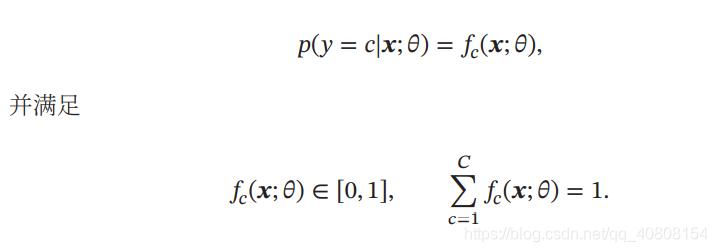
4.Hinge 损失函数:对于二分类问题,
(2)风险最小化准则:
优化算法:梯度下降算法、提前停止、随机梯度下降法、小批量梯度下降法














 4779
4779











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









