







数据分析项目中固然是用到很多的数据分析工具和技巧,但是业务知识也占比不小,本案例分析了来自CDNow网站的一份用户购买CD明细,业务结合技术进一步分析用户的消费行为,提高决策质量。CD数据包括用户ID,购买日期,购买数量,购买金额四个字段。
数据下载:https://pan.baidu.com/share/init?surl=pL2qo1H 密码g6vv
用到的工具,pycharm,python3.7
项目的总体内容包括一下几个部分:
- 数据清洗:处理缺失值,数据类型转化,按照需要将数据整理好
- 按月对数据进行分析:每月用户消费次数,每月用户的购买量,每月用户的购买总金额以及每月用户数量对比这些图标分析数据是否存在误差
- 用户个体消费数据分析:用户个体消费金额与消费次数的统计描述,用户消费金额和消费次数的散点图,用户消费金额的分布图(符合二八法则),用户消费次数的分布图,用户累计消费金额的占比。
- 用户消费行为分析:用户第一次消费时间,用户最后一次消费时间,用户分层,新老客消费比,用户购买周期,用户生命周期
一 数据清洗:
拿到数据使用pandas的read_table读出txt文件,列名为'user_id','order_dt','order_products','order_amount',由于这里的txt文件不是逗号分割的,所以sep = ‘\s+’。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
columns = ['user_id','order_dt','order_products','order_amount']
# 用户id 购买日期 购买产品数 购买金额
df = pd.read_table("master.txt",names = columns,sep = '\s+')
#df.info() 检查数据是否存在空值
print(df.head())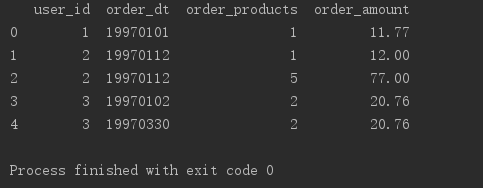
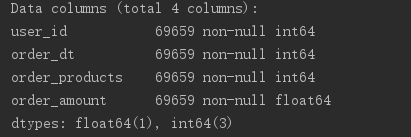
数据读出无误时要检查数据中是否存在空值,并检查数据的数据类型。发现数据中并不存在空值,很干净的数据。那接下来既然我们需要每月这个数据,就要给order_dt这一列的数据进行适当的转换一下,转化成通常的时间格式,Y(年)m(月)D(日)。下面那句代码的意思是:在df里心增加一列列名是mounth,取出这一列的日期order_dt然后掉取这一列的值把值转换成以月为单位的,例如6月1号到30号统统属于6月1号即是六月。看第二个图结果:
df['order_dt'] = pd.to_datetime(df.order_dt,format ='%Y%m%d')
df['mouth'] = df.order_dt.values.astype('datetime64[M]')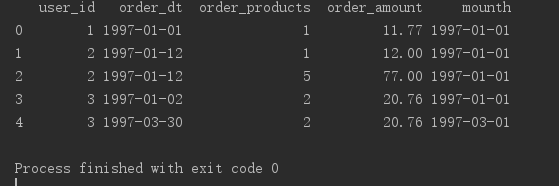
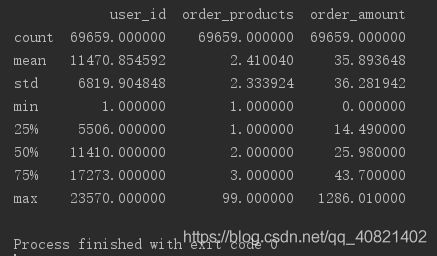
这时候可以对数据进行简单初步分析,用df.describe()。产品购买数量均值在2.4,中位数是2,其分位数是3,说明用户购买量大部分都不多,少部分购买量大的,最高购买量是99,其中存在一定的极致干扰。用户的订单金额比较稳定,人均购买CD金额在35,中位数在25元,存在极致干扰,很多销售行业都是类似这种分布,小额比较多,大额的较少,收入来源很大一部分是来自大额。也即是二八
到这里数据都准备好了进行下一步分析。
二 按月分析数据趋势:
在这里用到了一个groupby,一个在数据分析中非常好用的函数,这一节是要按月分析用户行为,用groupby对用户按照月分分组。
group_month = df.groupby('month')#按月对数据分组
order_month_amount = group_month.order_amount.sum()# 每个月份的销售总额
order_month_times = group_month.order_products.sum()# 每个月份的产品购买总数量
order_month_persons = group_month.user_id.count() # 每个月份用户的数量统计
order_mounth_amount.plot()
# order_mounth_times.plot()
# order_mounth_persons.plot()
plt.show()
分组完成之后得到一个新的dataframe叫group_month,然后直接取出组里的order_amount并求和可得到每个月份的销售总额,并且画出折线图,(控制折线图的三行代码挨个运行可得到仨图,一起运行的话就在一个图里展示三条线)
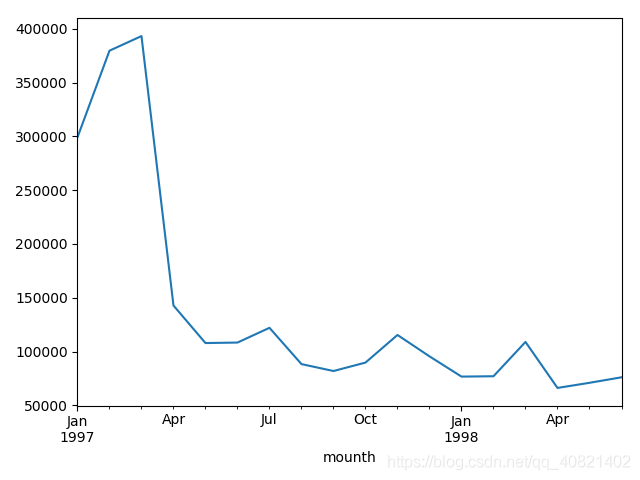
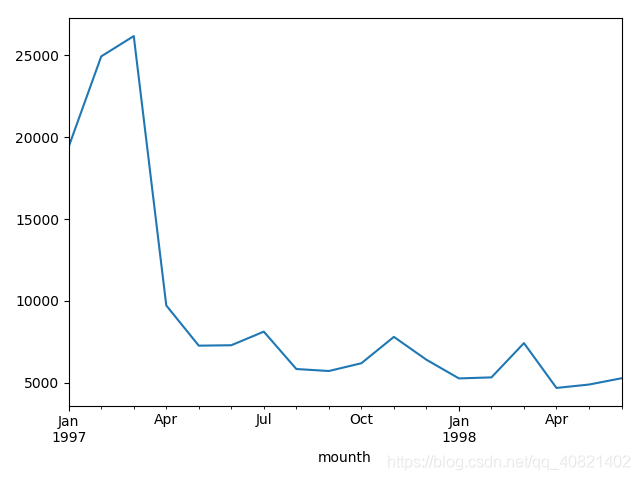
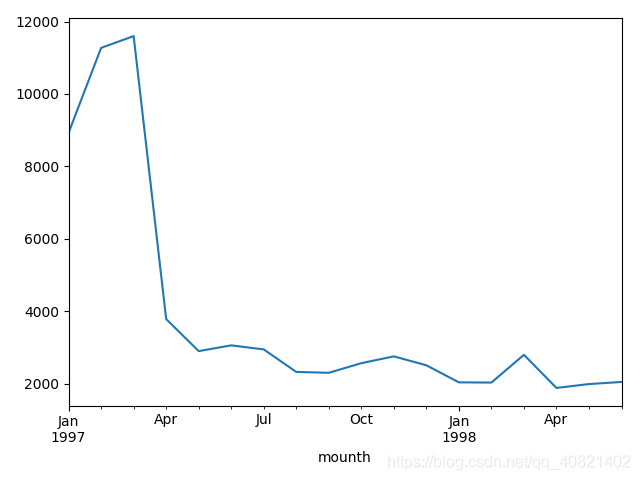
从上面仨图可以看出数据没有什么问题,用户购买总额跟用户购买次数以及用户购买量走势是大致相同的,但是从四月份开始销量严重下滑,具体是原因是什么,我们可以再来看一下每个月的消费人数:
df.groupby('month').user_id.nunique().plot()
plt.show()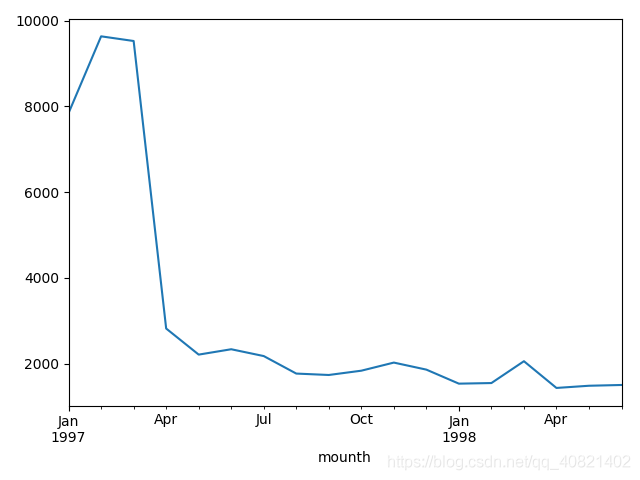
每月的消费人数小于每月的消费次数,但是区别不大。前三个月每月的消费人数在8000—10000之间,后续月份,平均消费人数在2000不到。一样是前期消费人数多,后期平稳下降的趋势。
三 用户个体消费数据分析:
之前的都是看趋势,现在看个体的消费水平如何,
主要分析的对象是:
- 用户消费金额和消费次数的统计以及散点图来观察用户的平均消费水平
- 用户消费金额的分布图(二八原则)
- 用户消费次数的分布图
- 用户累计消费金额的占比(百分之多的用户占了百分之多少的消费额)
group_userID = df.groupby('user_id')
print(group_user.sum().describe())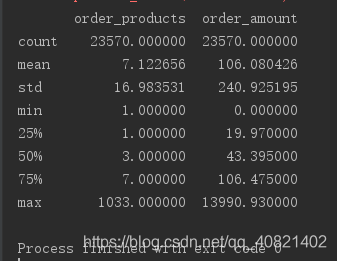
以user_id为索引进行分组,在用户的角度来看,每位用户平均购买七张CD,最少的用户购买了一张,最多购买1033张,中位数是三张,反映出有些数据的波动还是挺大,用户购买的金额平均是106中位数是43,购买最大金额是13990,四分位数19,这些数据加上之前的按月分析,大致勾勒出CD销售大致趋势,在一段时间销量上升,突然在某时期不景气开始猛地下跌,但是大部分还都是处于平稳,销售额也低。
group_userID = df.groupby('user_id')
group_userID.sum().query("order_amount<3000").plot.scatter(x = 'order_amount',y = 'order_products')
# group_userID.sum().order_amount. plot.hist(bins = 20)
# group_userID.sum().query("order_products<100").order_products.plot.hist(bins = 40)
#柱状图
plt.show()上一段代码的意思是以user_id为索引进行分组但是分组之后可能会发现打印出来的是对象,因为需要对分组完的数据进行进一步操作,例如求和求均值等等。然后再这里用到的是对数据进行求和,然后调用quary方法规定x轴坐标order_amunt的值小于3000,调用plot里的scatter散点图,画出散点图。
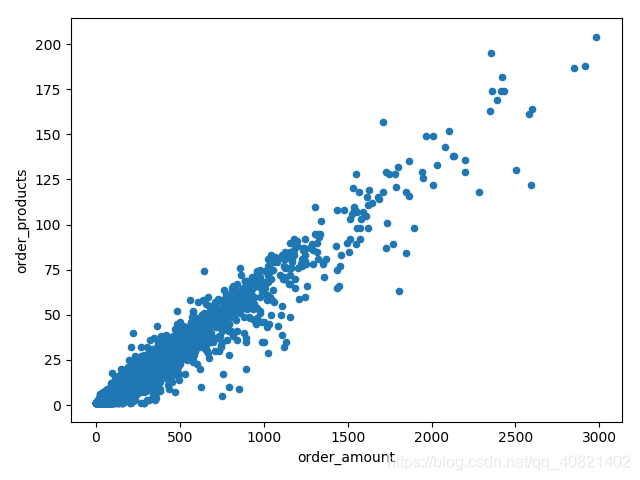
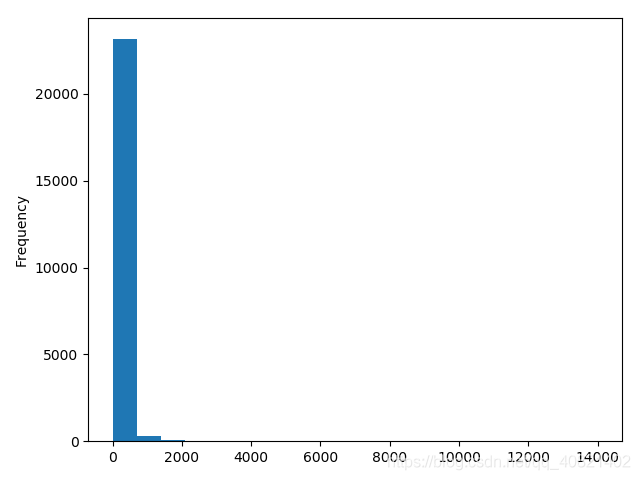
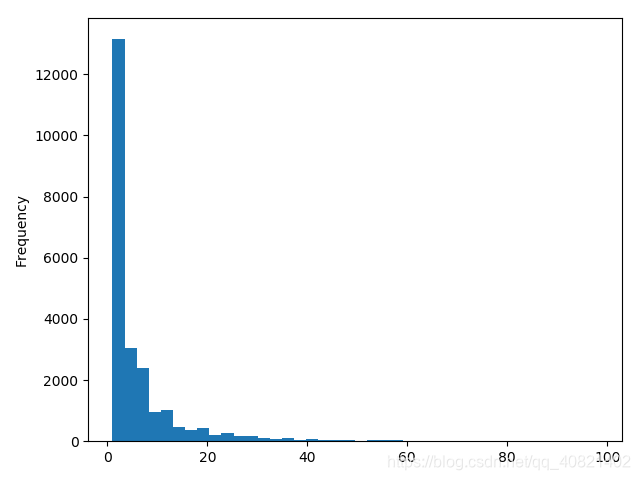
从散点图中看出数据集中分布在购买金额小购买量少上, 数据基本成线性分布,购买CD金额大数量就多,金额少数量也少。
从消费金额中可以看出消费金额偏向很低基本在0-1000元之间,可看出其主要还是面向低消费人群。从消费次数柱状图中可以看出,绝大部分用户消费次数并不多,甚至很少,消费次数基本在0-20次之间。
cum1 = group_userID.sum().sort_values("order_amount").apply(lambda x:x.cumsum()/x.sum())
cum1.reset_index().order_amount.plot()
plt.show()上面这段代码的意思是求出用户的累计消费金额占比,cumsum方法是滚动求和,对求完占比之后的dataframe进行重置 索引,重置索引之后的索引是按照升序排列好的,所以画出的图横坐标就是索引,纵坐标就是消费额所占比例,可以反映出百分之多少的用户占了消费额的百分之多少。
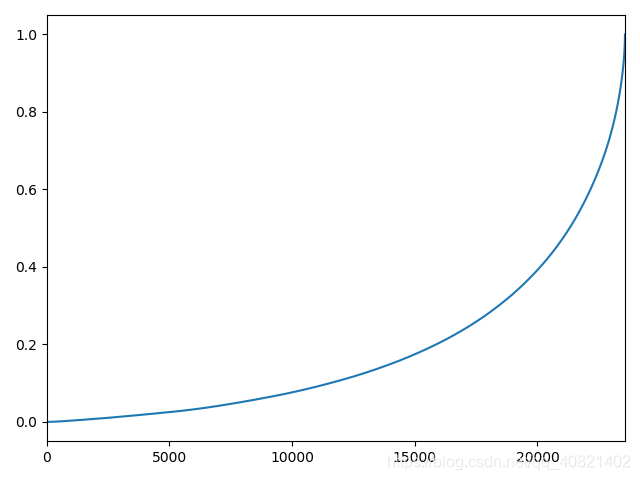
从消费额占比中看得出百分之五十的用户才占了百分之二十不到的消费额,排名前五百的用户占有了快百分之五十的消费额,消费还是主要集中在一些大客户上。
三 用户消费行为分析:
- 用户第一次消费&用户最后一次消费
- 新老客消费比(多少客户仅消费一次,每月新客占比)
- 用户分层(RFM,新,老,活跃,流失)
- 用户消费周期
- 用户生命周期
看一下用户本身第一次消费和最后一次消费都集中在几月
print(group_userID.month.min().value_counts())
print(group_userID.month.max().value_counts())
# group_userID.month.min().value_counts().plot()
# group_userID.month.max().value_counts().plot()
# group_userID.order_dt.max().value_counts().plot()
plt.show() 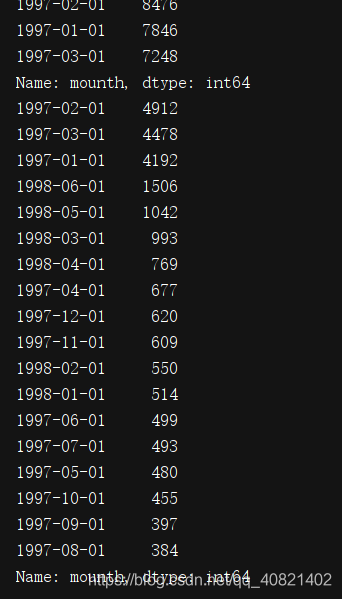
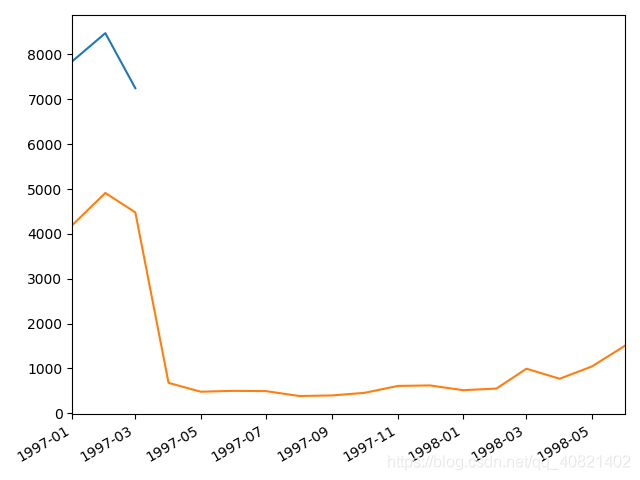
首购都在一月到三月份,最后一次购买也基本集中在一月到三月份,长期活跃的客户不是很多,大部分用户是购买一次之后不在购买,随着时间的增长,最后一次购买的用户量也在不断增加
new = group_userID.order_dt.agg(['min','max'])
print((new['min']==new['max']).value_counts())
exit() 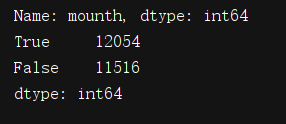
第一次消费时间等于最后一次消费时间的数量占到了一半,说明很多顾客仅消费一次不再消费。
接下来对用户进行分层:
将用户分成:
111':'重要价值客户',
'011':'重要保持客户',
'101':'重要挽留客户',
'001':'重要发展客户',
'110':'一般价值客户',
'010':'一般保持客户',
'100':'一般挽留客户',
'000':'一般发展客户'
至于前面数字的意义等下会解释。到这里就开始使用一个新的函数,及python的透视函数,point_table此函数功能跟excel的透视表一样,但是比透视表更加灵活,pd.point_table(index = [],columns = [],values = [],aggfunc = [])这几个参数等会要用到,先来解释一下这几个参数的意思:
index指的是分组的时候选择哪个字段作为索引,columns指的是指定的列名是什么,values可以决定保留哪些属性字段,aggfunc则是决定对每个字段执行的函数,不写默认执行sum
rfm = df.pivot_table(index = 'user_id',
values = ['order_products','order_amount','order_dt'],
aggfunc = {'order_dt':'max','order_amount':'sum','order_products':'sum'})
# 消费产品数 消费总金额 最近一次消费时间
rfm["R"] = -(rfm.order_dt-rfm.order_dt.max())/np.timedelta64(1,'D')
rfm.rename(columns = {'order_amount':'M','order_products':'F'},inplace=True)
print(rfm)
exit() 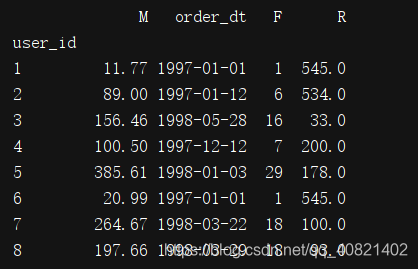
用order_id(用户购买日期的最大值)减去截至到当前的时间,也就是1998-06-30 00:00:00(执行代码print(rfm.order_dt.max()查看),那就要假设我,们现在处于1998-06-30 00:00:00这个时间,用户购买的最后一次时间到这个时间的时间间隔就是用户最近一次交易时间间隔。F的值越大说明交易的越频繁,M的值越大说明交易金额月大,用户的价值就越高。
在这里呢可以思考一下怎样可以让客户分组呢,什么样的客户是重要客户呐!!当然肯定是消费产品多,消费金额高,消费距今时间短的了。但是这些指标怎样能体现出来呢,这就要用到均值,如果这个值跟均值相减是负数说明消费水平不高,但是又分成几种情况。
print(rfm[["R", 'F', "M"]].apply(lambda x: x - x.mean()))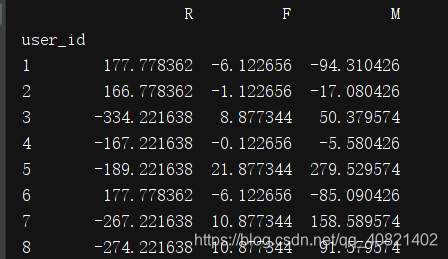
均值相减之后分成了这样几种情况 可以判断一下假设每个值正数就是“1”,负数就是“0”:
111':'重要价值客户',
'011':'重要保持客户',
'101':'重要挽留客户',
'001':'重要发展客户',
'110':'一般价值客户',
'010':'一般保持客户',
'100':'一般挽留客户',
'000':'一般发展客户'
def aggfc(k):
level = k.apply(lambda x:'1' if x >0 else '0')
leable = level.R+level.M+level.F
d = {
'111': '重要价值客户',
'011': '重要保持客户',
'101': '重要挽留客户',
'001': '重要发展客户',
'110': '一般价值客户',
'010': '一般保持客户',
'100': '一般挽留客户',
'000': '一般发展客户'
}
result = d[leable]
return result
rfm['lable'] = rfm[["R",'F',"M"]].apply(lambda x:x-x.mean()).apply(aggfc,axis=1)
print(rfm.groupby('lable').sum())
print(rfm.groupby('lable').count())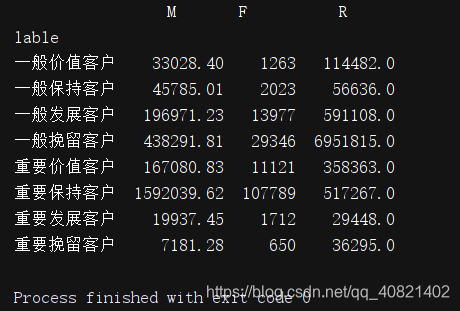
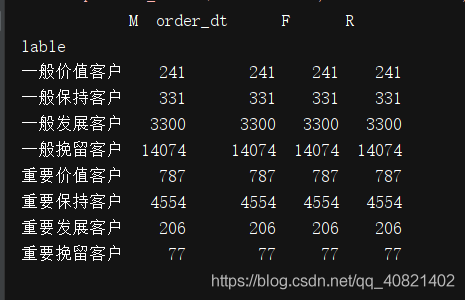
实现了对用户的分层 ,重要爆出客户的总消费金额达到159万,重要保持客户的人数达到了4554人
rfm.loc[rfm.lable == '重要价值客户','color'] = 'g'
rfm.loc[~(rfm.lable == '重要价值客户'),'color'] = 'r'
rfm.plot.scatter("F",'R',c = rfm.color)
plt.show()
exit()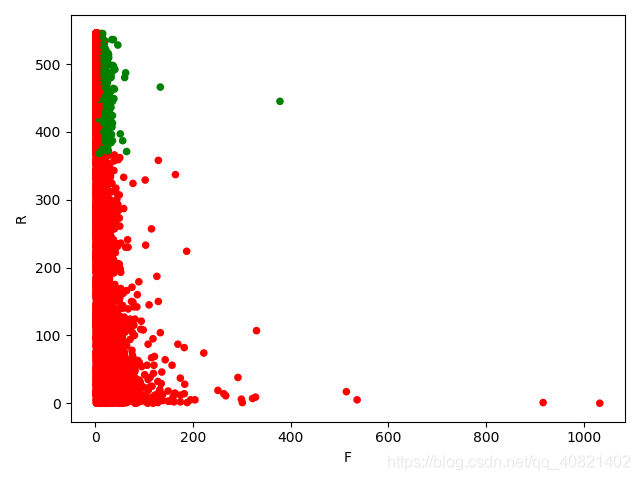
从RFM分层可知,大部分用户为重要保持客户,但是这是由于极致的影响,所以RFM的划分应该尽量以业务为准。尽量用小部分的用户覆盖大部分的额度,不要为了数据好看划分等级。
RFM是人工使用象限法把数据划分为几个立方体,立方体对应相应的标签,我们可以把标签运用到业务层面上。比如重要保持客户贡献金额最多159203.62,我们如何与业务方配合把数据提高或者维护;而重要发展客户和重要挽留客户他们有一段时间没有消费了,我们如何把他们拉回来
col = ['1997-01-01', '1997-02-01', '1997-03-01', '1997-04-01',
'1997-05-01', '1997-06-01', '1997-07-01', '1997-08-01',
'1997-09-01', '1997-10-01', '1997-11-01', '1997-12-01',
'1998-01-01', '1998-02-01', '1998-03-01', '1998-04-01',
'1998-05-01', '1998-06-01']
def active_status(data):
status = []
for i in range(18):
#若本月没有消费
if data[i] == 0:
if len(status) > 0:
if status[i-1] == 'unreg': # unreg未注册用户
status.append('unreg')
else:
status.append('unactive') # 不活跃用户
else:
status.append('unreg')
#若本月消费
else:
if len(status) == 0:
status.append('new')
else:
if status[i-1] == 'unactive':
status.append('return')# 回流用户
elif status[i-1] == 'unreg':
status.append('new')# 新用户
else:
status.append('active') # 活跃用户
return pd.Series(status,index = col)
pivoted_status = df_purchase.apply( active_status,axis = 1)
pivoted_status.head() 
对于以上代码分析一下:首先对于参数data,data是单独的一行,也即是secris类型的数据apply方法默认取出的数据是一列,但是在后面直接明确了取数据的方式axis=1,代表每次取一行,一行进行函数中间的逻辑运算。既然是一行数据了,一行里有十八中类型,则需要遍历循环十八次,所以for i in range(18):默认从0到十八,但是包括0不包括十八(python的半包)。先定义一个空数组status,然后开始讨论本月是否有消费,假设本月没有消费,那么data[i]==0,判断status里是否有值即判断data[i-1],如果status里有值,看他里边的值是什么状态,如果说值等于unreg那本月依然是未注册。就往status里加入“unreg”,如果上个月是不活跃或者回流,这个月不消费依然是不活跃,status加入“unactive”。其他如果本身status里都没有值,这个月又不消费那么就是还没开始注册。假设本月已经消费那么data[i-1]==1,看一下status的状态,如果len(status)>0即是status里有值就要判断一下这里边值的状态了,如果这里边data[i-1]==‘unreg’就是说上个月就没注册,这个月突然消费了,那他就是新客啦!如果上个月是不活跃那这个月就是回流用户了,其他情况都是活跃用户。这一块代码有点多,不过逻辑上还是很清晰的。
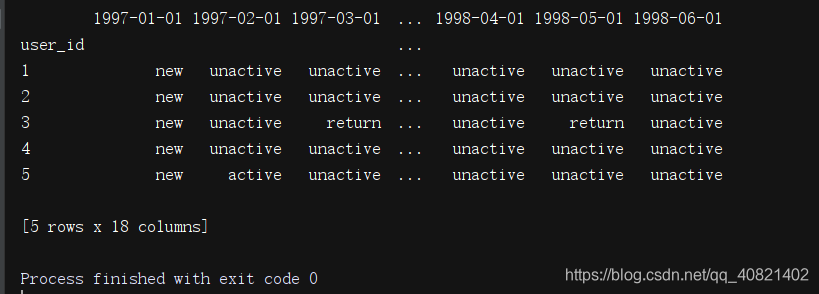
接下来就来看一下每个月的新用户,未注册用户,活跃用户回流用户有多少,由于没注册的用户在数据里是干扰项,则直接让没注册的用户为NaN,这样的话看起来应该会好看一些。用replace函数,用np.NaN进行替代apply在这里默认每次取出一列进行逻辑运算,用到lambda匿名函数,以及panads的计数函数value_counts。对每一列的不同情况值进行计数。然后生成下图;
print(pivoted_status.replace('unreg',np.NAN).apply(lambda x:pd.value_counts(x)))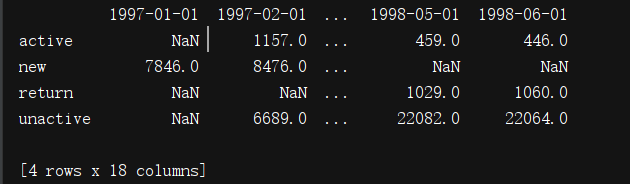
上面的仅仅看数据的话不够直观,我们就给他在图上展示出来,先将NaN用0填充一下,然后再进行转置把月份当作索引,等下画图的时候会生成横坐标各个区域的数据大小会生成不同的面积显示出来。
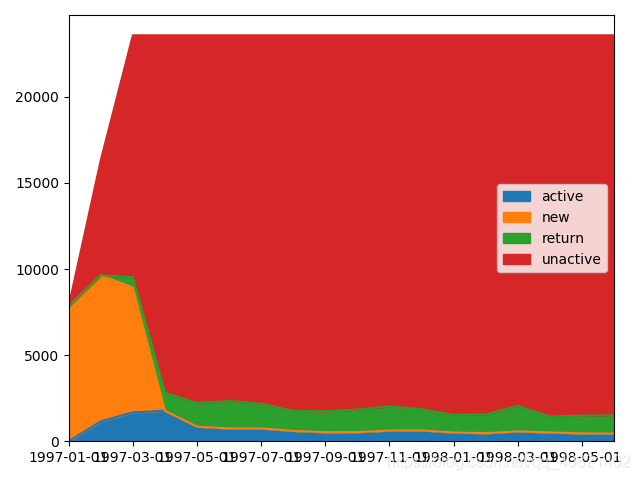
从这幅图上可以清晰的看出,不活跃用户,也就是红色区域占了大部分面积,新客主要还是集中在1到3月份,活跃的用户和回流在四月份之后就比较稳定总量不多。
再来看一下新增用户比,
pivoted_status = df_purchase.apply(active_status, axis=1)
new_point = pivoted_status.replace('unreg',np.NAN).apply(lambda x:pd.value_counts(x))
print(new_point.fillna(0).T.apply(lambda x:x/x.sum(),axis = 1))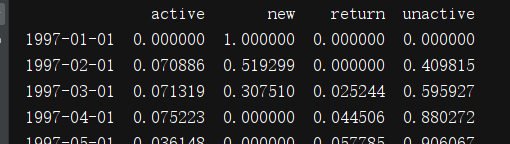
由上表可知,每月用户的消费状态变化。活跃用户、持续消费的用户对应的是消费运营质量。回流用户,之前不消费本月才消费对应的是唤回运营。不活跃的用户对应的是流失,这里可以针对业务模型下个定义:流失用户增加,回流用户正在减少
group_ID = df.groupby('user_id')
order = group_ID.apply(lambda x: x.order_dt-x.order_dt.shift())
print(order)
print(order.describe())
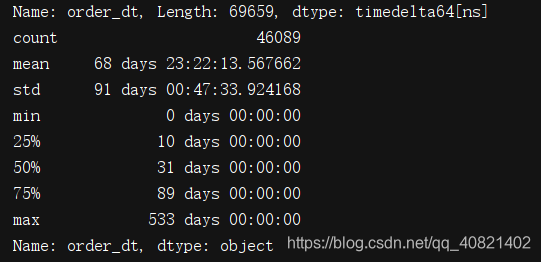
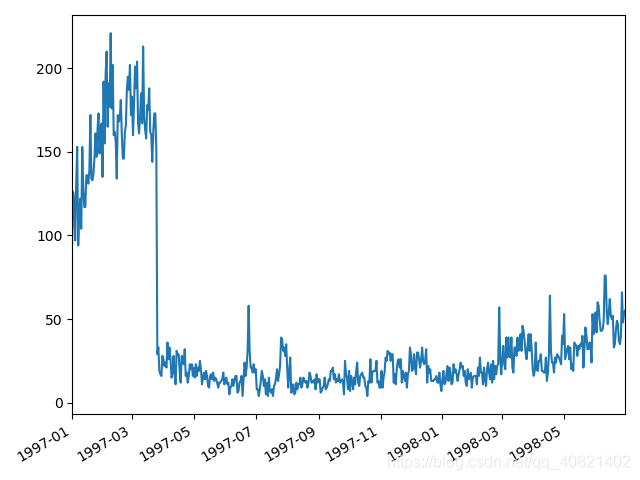
从用户购买周期的均值中可以看出,平均消费周期为68天,中位数是31天,可以根据用户的购买周期对用户进行定期召回。
依然是用图来更直观的看一下消费周期的分布:基本用户的消费周期都集中在100天一下,平均消费周期就一个月。
group_ID = df.groupby('user_id')
order = group_ID.apply(lambda x: x.order_dt-x.order_dt.shift())
# print(order)
# print(order.describe())
# x.order_dt-x.order_dt.shift()
(order/np.timedelta64(1,'D')).hist(bins = 20)
plt.show()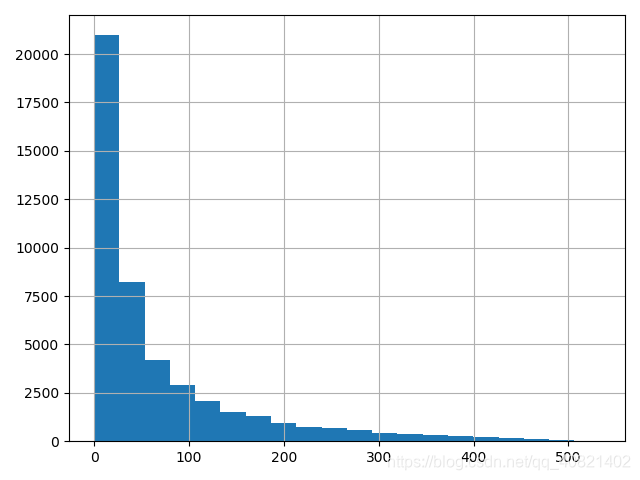
再来看一下用户的生命周期:也就是用户的最后一笔订单时间减去第一笔订单时间就是用户的生命周期。
purchase_r = word.applymap(lambda x : 1 if x > 1 else np.NaN if x == 0 else 0)
(purchase_r.sum()/purchase_r.count()).plot()
plt.show()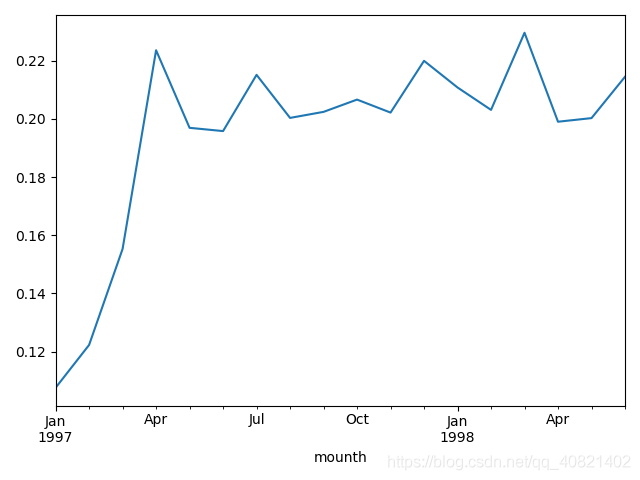
显而易见,前三个月复购率一直在猛增,但是慢慢复购率有下降但是基本在保持在包分之19以上,在百分之二十上下波动。再来看一下回购率:
pivoted_amount = df.pivot_table(index = 'user_id',columns = 'month',values = 'order_amount',aggfunc = 'mean').fillna(0)
pivoted_purchase = pivoted_amount.applymap(lambda x:1 if x>0 else 0)
columns_mounth = df.month.sort_values().astype('str').unique()
pivoted_amount.columns = columns_month
def purchase_return(data):
status = []
for i in range(17):
if data[i] == 1:
if data[i+1] ==1:
status.append(1)
if data[i+1] == 0:
status.append(0)
else:
status.append(np.NaN)
status.append(np.NaN)
return pd.Series(status,index=col)
pivoted_purchase_return = pivoted_purchase.apply(purchase_return,axis = 1)
(pivoted_purchase_return.sum()/pivoted_purchase_return.count()).plot()
plt.show()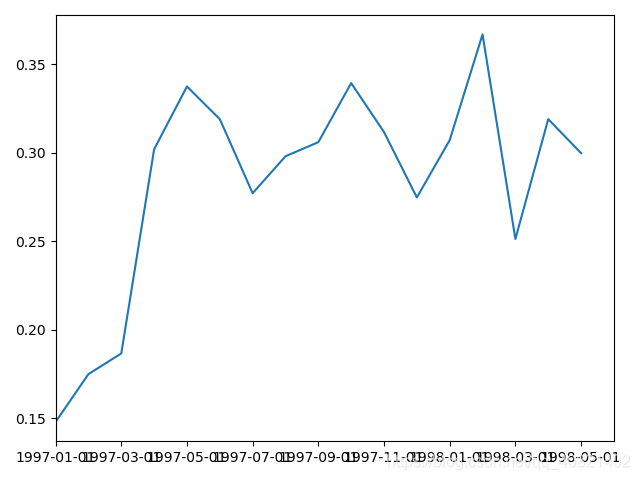
0代表当月消费过次月没有消费过,1代表当月消费过次月依然消费
新建一个判断函数。data是输入数据,既用户在18个月内是否消费的记录,status是空列表,后续用来保存用户是否回购的字段。因为有18个月,所以每个月都要进行一次判断,需要用到循环。if的主要逻辑是,如果用户本月进行过消费,且下月消费过,记为1,没有消费过是0.本月若没有进行过消费,为NAN,后续的统计中进行排除。apply函数应用在所有行上,获得想要的结果。
最后计算和复购率大同小异,用count和sum求出,从图中可以看出,用户的回购率高于复购,约在30%左右,和老客户差异不大。从回购率和复购率综合分析可以得出,新客的整体质量低于老客,老客的忠诚度(回购率)表现较好,消费频次稍次,这是CDNow网站的用户消费特征。
里边有些地方的“month”写错了,由于之前写的时候没发现(捂脸)如果大家这一块有错了,统一改一下就行啦!














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









