







一、线性回归算法简介
m:训练样本的个数
x:输入特征
y:输出变量,也就是要预测的目标变量
(x,y):表示一个训练样本
():表示一个特定的训练样本,即第i个训练样本,上标i是第i个的意思
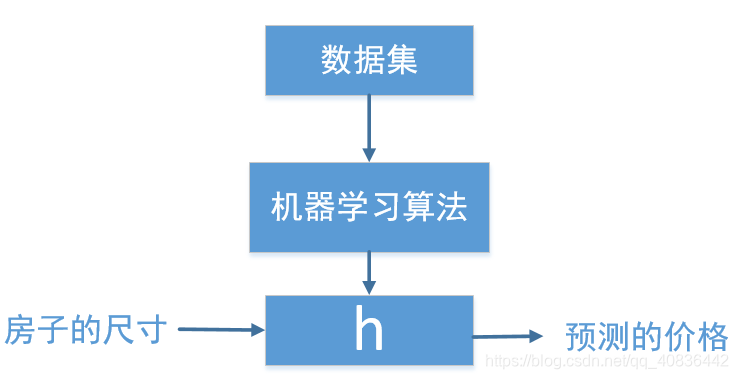
h是hypothesis的意思,在此处是假设函数,即引导从x得到y的函数h(x)=y。当我们设计一个学习算法的时候,需要考虑怎么表示这个假设函数h,在线性回归算法中,我们通常使用如下的假设函数:,有时
会简写为h(x)。从函数中可以看出假设函数h为一个线性函数。线性函数的模型最简单,所以从线性函数开始学习。这个函数处理的是一个回归问题,只有单个变量x,所以又叫做一元线性回归函数或单变量回归函数。
二、代价函数
(一)提出问题
问题:m代表训练样本的数量,比如m=47。假设函数h的方程为:,我们把
和
叫做模型参数,我们要做的就是确定这两个模型参数。不同的参数会得到不同的假设函数h(x),如下:

我们的目的是得出最优的和
让假设函数表示的直线尽量的与数据点很好的拟合。

(二)标准化定义
标准化定义:在线性回归中,我们要解决的是一个最小化问题。我们需要使预测值h(x)和真实值y之间的差异尽量的小,也就是尽量减少假设的输出与房子真实价格之间差的平方,公式如下:
其中
在线性回归中一般采用均方误差(平方误差)作为代价函数,在吴恩达老师的课中采用了均方误差的1/2作为代价函数。现在问题变成了,寻找使训练集中预测值和真实值的差的平方的和的1/2m最小的和
的值,所以上述函数就是线性回归的整体目标函数。代价函数一般用J表示,所以完整的代价函数可以写成:
代价函数也被称为平方误差函数,有时也称为平方误差代价函数。平方误差代价函数对大多数回归问题都适用。
三、梯度下降法
定义代价函数J(),我们需要得到代价函数的最小值使得假设函数与真实数值最接近。
(一)梯度下降算法思路:
1、给定和
的初始值,通常将他们都初始化为0
2、不断的改变和
的值来减小J(
)的值,直到找到J(
)的最小值
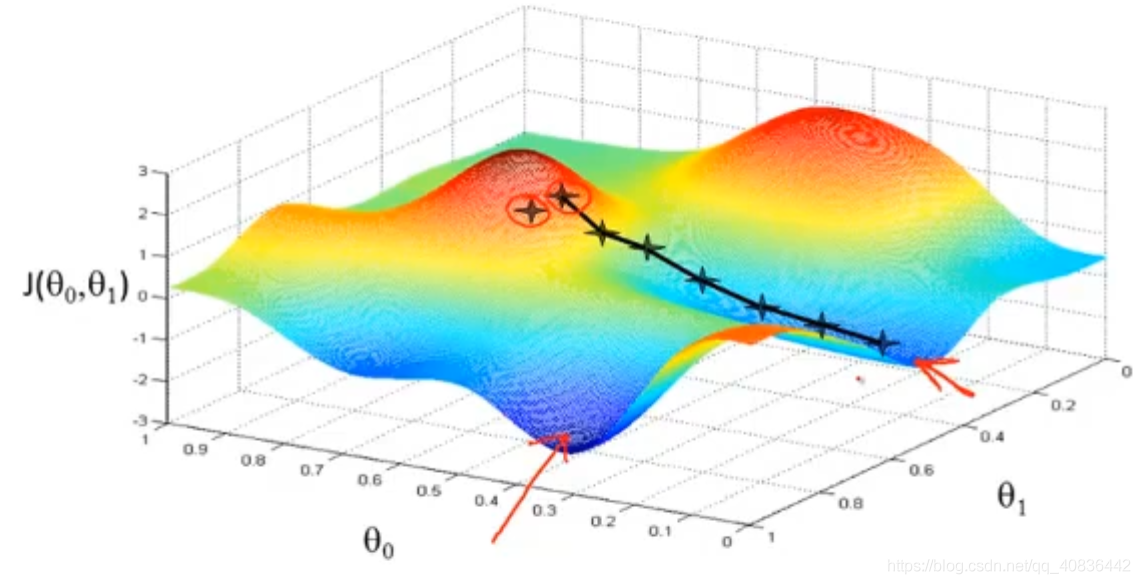
梯度下降法容易陷入局部最优,如下图,存在多个局部的最低点,不同的开始位置会导致陷入不同的局部最优解。
(二)梯度下降算法的定义:
重复此步骤,直到函数收敛{
(for j=0 and j=1)
}
更新过程:
其中符号:=表示赋值,其中的α被称为学习率,α控制的是梯度下降时的步长,比如后面的偏导数求出的是5,阿尔法=0.1,那么参数就会下降0.1*5=0.5个步长,α=1,那么就会下降1*5=5个步长。
注意,其中的和
是同步更新的,这是正确的梯度下降方法,如果改成下面这样
在计算的时候,
的值已经发生了更新,它们不是同步更新的,是不正确的实现方法。
(三)演算梯度下降算法几何展示
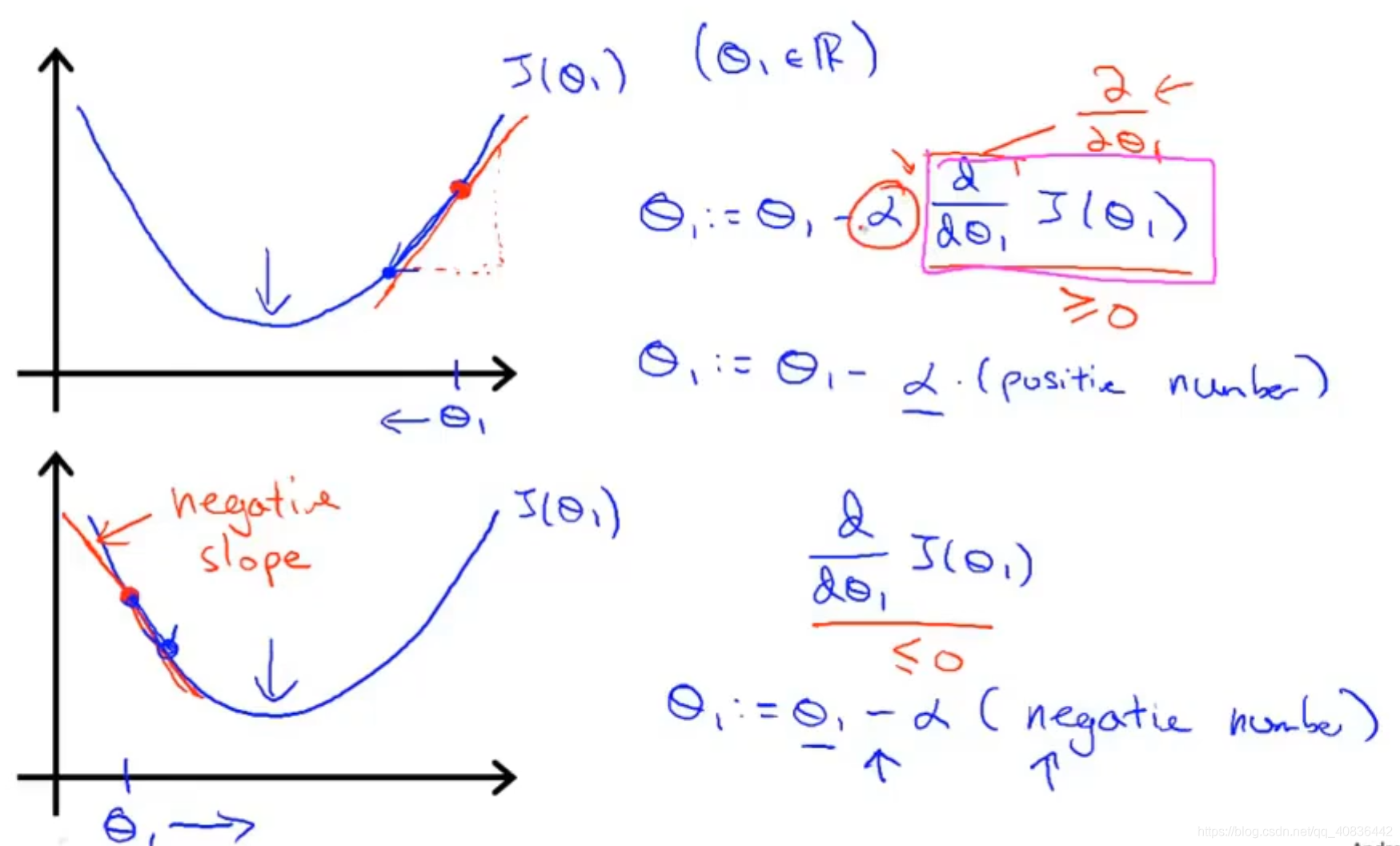
假设只有一个参数,那么上述公式可以简化为
,因为是一个参数即函数只有一个自变量,所以偏导数变为了导数。
根据导数的几何意义可知:为点
处的切线斜率,当函数J在点
处单调增时,导数为正,
减去一个正数数值变小,则由单调性可知J值变小,同理如果在点处单调减,则导数为负数,
减去一个负数相当于加上一个正数,
变大,则J值还是变小。
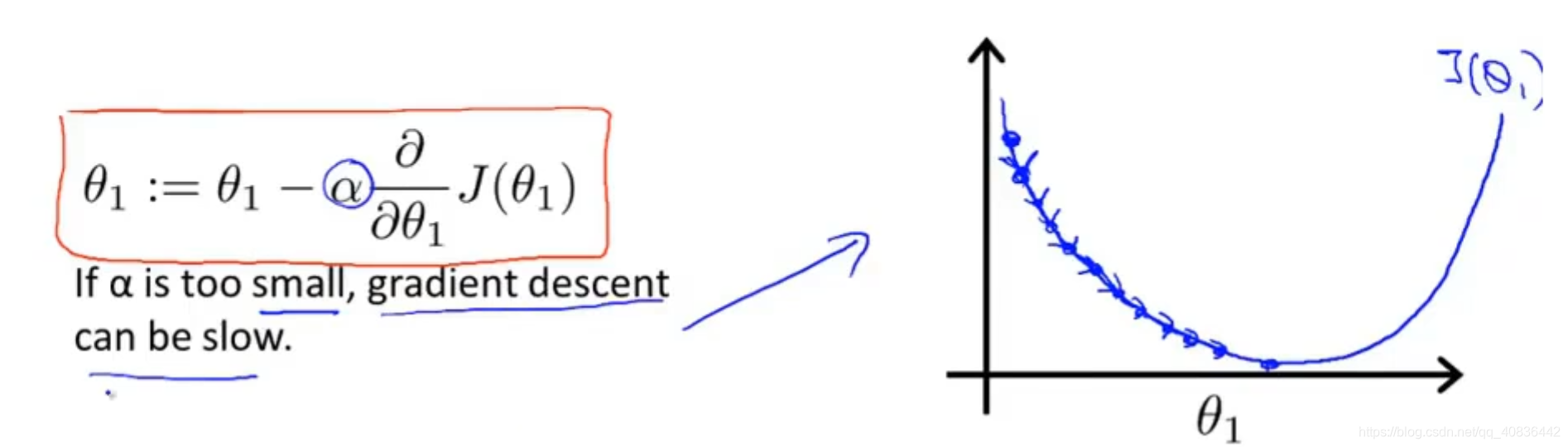
(四)α的取值影响
(1)如果α取值太小,那么每次的步长就会变小,函数收敛速度就会很慢
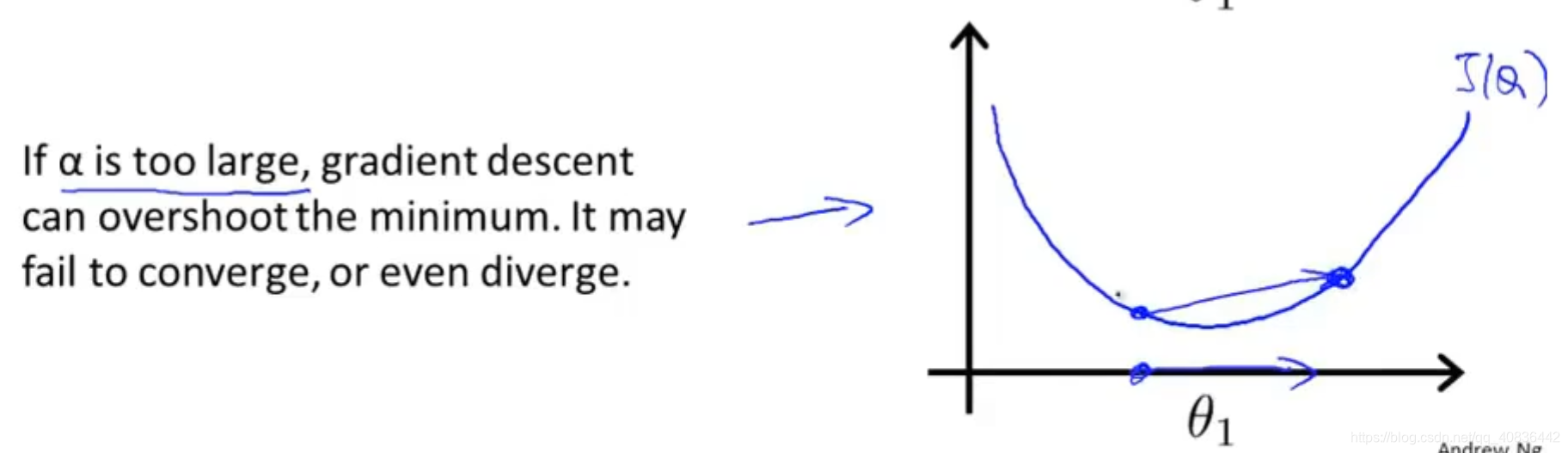
(2)如果α取值太大,那么每次就会的步长就会很大,当接近最低点的时候,可能因为步长过大而越过最低点,会导致函数无法收敛甚至发散。
四、线性回归算法
假设函数:
代价函数:
我们要做的就是将梯度下降法应用到线性回归算法的最小化平方差代价函数中,得到函数的最小值。将两个方程代入到梯度下降算法中,得:
接下来要做的就是不断重复计算上面得出的公式,直到函数收敛,这就是线性回归算法。















 707
707











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











