







设计自动化测试框架的前提技能介绍
1. 手工测试用例转换成自动化测试脚本的过程
2. 能设计自动化测试框架,至少能够维护自动化测试框架。
3. 流程自动化方案设计,例如,一键打包,自动开始测试,自动发送测试报告,自动运维部署上线等。
1. 主流Python开发IDE工具的基本使用,例如Pycharm
2. Python中模块,类和对象的具体代码讲解。
3. Selenium 常见方法的二次封装。
4. 自定义方法的封装和方法的调用-浏览器引擎类。
5. Python读写配置文件介绍
6. Python如何获取系统时间和时间的格式化处理。
7. Python中常见字符串切割处理。
8. Python自定义一个日志生成方法封装。
9. Selenium中一个截图方法的封装。
10. Python中继承的使用。
通过介绍以上中级技能学习后,我们才可以,或者有能力去思考和动手去设计一个简单的自动化测试框架。
————————————————
Python中类/函数/模块的简单介绍和方法调用
新建一个包,然后在包下面新建一个demo.py文件。抄写以下代码到你的环境里,尝试运行下,看看有没有问题。
关于Python中类和函数及方法的调用,我们写在这个demo.py文件,具体代码如下:
# coding=utf-8
class ClassA(object):
string1 = "这是一个字符串。"
def instancefunc(self):
print ('这是一个实例方法。')
print (self)
@classmethod
def classfunc(cls):
print ('这是一个类方法。')
print (cls)
@staticmethod
def staticfun():
print ('这是一个静态方法。')
test = ClassA() # 初始化一个ClasssA的对象,test是类ClassA的实例对象
test.instancefunc() # 对象调用实例方法
test.staticfun() # 对象调用静态方法
test.classfunc() # 对象调用类方法
print test.string1 # 对象调用类变量
ClassA.instancefunc(test) # 类调用实例方法,需要带参数,这里的test是一个对象参数
ClassA.instancefunc(ClassA) # 类调用实例方法,需要带参数,这里的ClassA是一个类参数
ClassA.staticfun() # 类调用静态方法
ClassA.classfunc() # 类调用类方法
1. 类的定义,class开头的就表示这是一个类,小括号里面的,表示这个类的父类,涉及到继承,默认object是所有类的父类。python中定义类,小括号内主要有三种:1. 具体一个父类,2. object 3. 空白
2. 函数或方法的定义, def开头就表示定义一个函数,方法包括,实例方法,类方法,静态方法,注意看类方法和静态方法定义的时候上面有一个@标记。
3. 对象调用方法和类调用方法的使用。
————————————————
最后,来说下python中的模块,在python中,你新建一个demo.py文件,那么一个.py文件可以说是一个模块,一个模块中,可以定义多个class,模块中也可以直接定义函数。和java一样,访问不同包下的类和方法之前,需要导入相关路径下的包。例如from selenium import webdriver 这个导入语句,我们知道webdriver这个接口是在selenium的模块下。
本篇文章的学习目的,会用函数或者类来编写我们之前写过的脚本。
以下用百度搜索举例,模仿上面用类调用实例的方法来写这个脚本,可能看起来比较啰嗦,但是代码多了,你就会体会到类的作用,注意这里self指的是当前BaiduSearch这个类本身:
————————————————
# coding=utf-8
import time
from selenium import webdriver
class BaiduSearch(object):
driver = webdriver.Chrome()
driver.maximize_window()
driver.implicitly_wait(10)
def open_baidu(self):
self.driver.get("https://www.baidu.com")
time.sleep(1)
def test_search(self):
self.driver.find_element_by_id('kw').send_keys("selenium")
time.sleep(1)
print self.driver.title
try:
assert 'selenium' in self.driver.title
print ('Test pass.')
except Exception as e:
print ('Test fail.')
self.driver.quit()
baidu = BaiduSearch()
baidu.open_baidu()
baidu.test_search()
二次封装Selenium中几个方法
本文来介绍,如何把常用的几个webdriver的方法封装到自己写的一个类中去,这个封装过程叫二次封装Selenium方法。我们把打开站点,浏览器前进和后退,关闭和退出浏览器这这个方法封装到一个新写的类中去。
我们按照如下层次结构在PyCharm中新建两个包和两个.py文件:
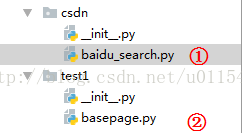
上图,baidu_search.py是我们编写测试脚本的python文件,具体测试代码写在这个文件。包test1下的basepage.py文件是这次我们介绍的二次封装selenium方法而新建的。这里提一下,python中默认规则,包名和文件名都是小写,类名称单词首字母大写,函数名称小写,多个字母下划线隔开。我们尽量遵守下这个不成文的约定
————————————————
# coding=utf-8
class BasePage(object):
"""
主要是把常用的几个Selenium方法封装到BasePage这个类,我们这里演示以下几个方法
back()
forward()
get()
quit()
"""
def __init__(self, driver):
"""
写一个构造函数,有一个参数driver
:param driver:
"""
self.driver = driver
def back(self):
"""
浏览器后退按钮
:param none:
"""
self.driver.back()
def forward(self):
"""
浏览器前进按钮
:param none:
"""
self.driver.forward()
def open_url(self, url):
"""
打开url站点
:param url:
"""
self.driver.get(url)
def quit_browser(self):
"""
关闭并停止浏览器服务
:param none:
"""
self.driver.quit()
上面的''''''是文档注释,一般在类的开始和函数的开始,用两个''''''括起来,简单描述下这个类或者函数的功能。
接下来看看,我们脚本文件中如何去调用我们自己封装过的方法。
baidu_search.py的内容如下:
# coding=utf-8
import time
from selenium import webdriver
from test1.basepage import BasePage
class BaiduSearch(object):
driver = webdriver.Chrome()
driver.maximize_window()
driver.implicitly_wait(10)
basepage = BasePage(driver)
def open_baidu(self):
self.basepage.open_url("https://www.baidu.com")
time.sleep(1)
def test_search(self):
self.driver.find_element_by_id('kw').send_keys("Selenium")
time.sleep(1)
self.basepage.back()
self.basepage.forward()
self.basepage.quit_browser()
baidu = BaiduSearch()
baidu.open_baidu()
baidu.test_search()
上面self.basepage的几行代码就是调用我们自己封装的方法去执行相关webdriver操作。这个只是一个简单的封装介绍,等后面,我们介绍了字符串切割,我们会再次介绍二次封装Selenium方法,例如将会把八大find_element方法封装到一个方法里去。
封装一个自己的类-浏览器引擎类
我们知道了,如何去封装几个简单的Selenium方法到我们自定义的类,这次我们编写一个类,叫浏览器引擎类,通过更改一个字符串的值,利用if语句去判断和控制启动那个浏览器。这里我们暂时,支持三大浏览器(IE,Chrome,Firefox)。这里有一个前提条件,在基础篇中,启动三大浏览器的driver文件,检查下你的Python安装路径下有没有这三个driver插件,如果没有,请回到基础篇的如何启动火狐和IE浏览器文章去看看如何做。
我们继续在test1这个包下新建一个browser_engine.py文件,然后在另外一个包下新建一个test.py文件去测试这个浏览器引擎类是否工作正常。这个浏览器引擎类,我们一开始写简单一点,只写启动浏览器。
先看看browser_engine.py中的代码:
————————————————
# coding=utf-8
from selenium import webdriver
class BrowserEngine(object):
"""
定义一个浏览器引擎类,根据browser_type的值去,控制启动不同的浏览器,这里主要是IE,Firefox, Chrome
"""
def __init__(self, driver):
self.driver = driver
browser_type = "IE" # maybe Firefox, Chrome, IE
def get_browser(self):
"""
通过if语句,来控制初始化不同浏览器的启动,默认是启动Chrome
:return: driver
"""
if self.browser_type == 'Firefox':
driver = webdriver.Firefox()
elif self.browser_type == 'Chrome':
driver = webdriver.Chrome()
elif self.browser_type == 'IE':
driver = webdriver.Ie()
else: driver = webdriver.Chrome()
driver.maximize_window()
driver.implicitly_wait(10)
return driver
再看看test.py代码,进行测试,更改browser_engine.py中browser_type的值,去测试三大浏览器是否启动正常。
# coding=utf-8
import time
from test1.browser_engine import BrowserEngine
class TestBrowserEngine(object):
def open_browser(self):
browserengine = BrowserEngine(self)
driver = browserengine.get_browser()
tbe = TestBrowserEngine()
tbe.open_browser()
目前,自定义的浏览器引擎类到这里就封装好了,只支持打开不同浏览器,需要手动修改,引擎类中browser_type的值。看起来功能简单,但是我们只是需要学习这种做事的方式和思维,在下一个部分,框架设计的时候,我会再告诉大家如何去加强这个引擎类的功能,到时候去修改配置文件中的浏览器类型,而不是修改代码中的字段。通过修改配置文件,从而去打开不同浏览器,并开始测试相关脚本。
————————————————
Python读取配置文件内容
本文来介绍下Python中如何读取配置文件。任何一个项目,都涉及到了配置文件和管理和读写,Python支持很多配置文件的读写,这里我们就介绍一种配置文件格式的读取数据,叫ini文件。Python中有一个类ConfigParser支持读ini文件。
1. 在项目下,新建一个文件夹,叫config,然后在这个文件夹下新建一个file类型的文件:config.ini
文件内容如下:
————————————————
# this is config file, only store browser type and server URL [browserType] #browserName = Firefox browserName = Chrome #browserName = IE [testServer] URL = https://www.baidu.com #URL = http://www.google.com 2. 百度搜索一下,python中如何获取当前项目的根目录的相对路径
这里采用:
os.path.dirname(os.path.abspath('.'))
3. 在另外一个包下新建一个测试类,用来测试读取配置文件是否正常。
# coding=utf-8
import configparser
import os
class TestReadConfigFile(object):
def get_value(self):
root_dir = os.path.dirname(os.path.abspath('.')) # 获取项目根目录的相对路径
print(root_dir)
config = configparser.ConfigParser()
file_path = os.path.dirname(os.path.abspath('.')) + '/configwj/config.ini'
config.read(file_path)
print(file_path)
browser = config.get("browserType", "browserName")
url = config.get("testServer", "URL")
return(browser, url) # 返回的是一个元组
trcf = TestReadConfigFile()
print(trcf.get_value()) 注意config.ini 文件需要手动到文件路径修改名称加后缀
你可以试试更改config.ini的内容,看看测试打印出来是不是你更改的东西,在配置文件一般#表示注释,你想要哪行配置代码起作用,你就把前面的#去除,并且在注释其他同一个区域。在ini文件中 中括号包裹起来的部分叫section,了解一下就可以。
Python获取系统时间和格式化时间显示
前面一篇文章介绍了,Python如何读取config.ini文件,还有如何获取当前项目根目录相对路径写法。在实际项目的开发,获取项目根路径的相对路径写法是很有必要的,不要去是绝对路径。因为,你自己开发的一个项目,如果拷贝到别的电脑里,发现运行不了,需要更改很多文件的路径,那是不是很失败。本篇文章介绍如何去获取和打印格式化系统时间,我们很多时候,看到一些日志,前面都会记录年月日,时分秒,甚至毫秒,然后才是日志描述。这一篇文章,介绍时间获取和格式化时间,就是为了后面,如何写一个简单的日志类做铺垫的。
在PyCharm下的一个包,右键,新建一个get_time.py文件,输入一下代码:
这里提醒一个小技巧:在输入导入包的时候,有些包你没有安装,不是系统自带的,可能会遇到红色下划线,你需要鼠标悬停在这个红色下划线,然后在这行的左侧有一个小灯泡,鼠标点击这个小灯泡,一般会有import this xxx 或者install xxx,根据提示来导入包或者安装第三方插件。
————————————————
# coding=utf-8
import time
class GetTime(object):
def get_system_time(self):
print (time.time()) # time.time()获取的是从1970年到现在的间隔,单位是秒
print (time.localtime())
new_time = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime()) # 格式化时间,按照 2017-04-15 13:46:32的格式打印出来
print (new_time)
gettime = GetTime()
gettime.get_system_time()
Python中字符串切割操作
本文来介绍Python中字符串切割操作,在Python中自带的一个切割方法split(),这个方法不带参数,就默认按照空格去切割字段,如果带参数,就按照参数去切割。为了演示切割效果,我们用百度搜索一个关键字,然后去找一共找到了多个结果的数字。
例如,百度搜索“selenium”,查看找到了多少个结果,我们需要单独摘取出这个数字。
————————————————

相关脚本代码如下:
# coding=utf-8
# __author__ = 'lenovo'
import time
from selenium import webdriver
class GetSubString(object):
def get_search_result(self):
driver = webdriver.Chrome()
driver.maximize_window()
driver.implicitly_wait(6)
driver.get('https://www.baidu.com')
driver.find_element_by_id('kw').send_keys('selenium')
time.sleep(5)
search_result_string = driver.find_element_by_xpath("//*/div[@class='nums']").text
print(search_result_string)
new_string = search_result_string.split('约')[1] # 第一次切割得到 xxxx个,[1]代表切割右边部分
print(new_string)
last_result = new_string.split('个')[0] # 第二次切割,得到我们想要的数字 [0]代表切割参照参数的左边部分
print(last_result)
getstring = GetSubString()
getstring.get_search_result()
split的另一种用法,切割的同时直接指给对象 -
-
a = '1234567890' -
b,c = a.split('5') -
print(b) -
print(c)
Python自定义封装一个简单的Log类
本文介绍如何写一个Python日志类,用来输出不同级别的日志信息到本地文件夹下的日志文件里。为什么需要日志输出呢,我们需要记录我们测试脚本到底做了什么事情,最好的办法是写事件监听。这个事件监听,对我们现在来说,还是有点复杂去理解,所以我这里,选择封装一个简单的日志类,同样达到这个效果。
我们大概需要如下日志输出效果:
————————————————
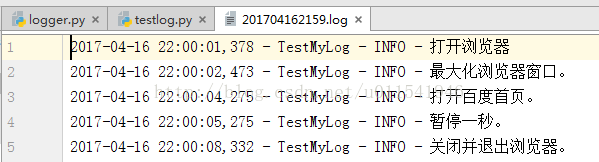
问题分析:
我们需要封装一个简单的日志类,主要有以下内容:
1. 生成的日志文件格式是 年月日时分秒.log
2. 生成的xxx.log文件存储在项目根目录下Logs文件夹下
3. 这个日志类,支持INFO,ERROR两种日志级别
4. 日志里,每行日志输出,如上图,时间日期+执行类名称+日志级别+日志描述
解决问题思路:
1. 在根目录下新建一个Logs的文件夹,如何获取这个Log的相对路径,前面介绍过。
2. 日志的保存命名,需要系统时间,前面也介绍过时间格式化输出
3. Python中有一个logging模块来支持我们自定义封装一个新日志类。
4. 在脚本里,初始化一个日志类的实例对象,然后去控制输出INFO还是ERROR日志信息。
自定义日志类封装如下:logger.py,新建在test包下
————————————————
# coding=utf-8
# __author__ = 'lenovo'
# _*_ coding: utf-8 _*_
import logging
import os.path
import time
class Logger(object):
def __init__(self, logger):
"""
指定保存日志的文件路径,日志级别,以及调用文件
将日志存入到指定的文件中
:param logger:
"""
# 创建一个logger
self.logger = logging.getLogger(logger)
self.logger.setLevel(logging.DEBUG)
# 创建一个handler,用于写入日志文件
rq = time.strftime('%Y%m%d%H%M', time.localtime(time.time()))
log_path = os.path.dirname(os.getcwd()) + '/test1/logs/'
log_name = log_path + rq + '.log'
fh = logging.FileHandler(log_name)
fh.setLevel(logging.INFO)
# 再创建一个handler,用于输出到控制台
ch = logging.StreamHandler()
ch.setLevel(logging.INFO)
# 定义handler的输出格式
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
fh.setFormatter(formatter)
ch.setFormatter(formatter)
# 给logger添加handler
self.logger.addHandler(fh)
self.logger.addHandler(ch)
def getlog(self):
return self.logger
新写一个测试日志类,相关代码如下:
# coding=utf-8
# __author__ = 'lenovo'
import time
from selenium import webdriver
from test1.logger import Logger
mylogger = Logger(logger='TestMyLog').getlog()
class TestMyLog(object):
def print_log(self):
driver = webdriver.Chrome()
mylogger.info("打开浏览器")
driver.maximize_window()
mylogger.info("最大化浏览器。")
driver.implicitly_wait(6)
driver.get("https://www.baidu.com")
mylogger.info("打开百度首页。")
time.sleep(3)
mylogger.info("暂停三秒")
driver.quit()
mylogger.info("关闭并推出浏览器。")
testlog = TestMyLog()
testlog.print_log()
在PyCharm里运行下这个测试类,会在根目录下的Logs文件下,新建一个日志文件,打开效果如文章开头的日志输出图。好了,关于自定义封装log类,自己好好去读下代码,理解下每行代码的意思,日志类的封装和调用就介绍到这里。
把截图类方法封装到前面的BasePage.py
本文介绍把截图类方法封装到BasePage.py文件里,这个文件是在前面Selenium方法二次封装文章里创建的,具体代码请到前面这篇里找。我们截图类写死了把截图图片保存到根目录下的Screenshots文件夹里,图片名称是当前系统时间,图片后缀名是png。新的BasePage.py内容如下:
————————————————
# coding=utf-8
import os
import time
from test.logger import Logger
mylog = Logger(logger='BasePage').getlog()
class BasePage(object):
"""
主要是把常用的几个Selenium方法封装到BasePage这个类,我们这里演示以下几个方法
back()
forward()
get()
quit()
"""
def __init__(self, driver):
"""
写一个构造函数,有一个参数driver
:param driver:
"""
self.driver = driver
def back(self):
"""
浏览器后退按钮
:param none:
"""
self.driver.back()
def forward(self):
"""
浏览器前进按钮
:param none:
"""
self.driver.forward()
def open_url(self, url):
"""
打开url站点
:param url:
"""
self.driver.get(url)
def quit_browser(self):
"""
关闭并停止浏览器服务
:param none:
"""
self.driver.quit()
def take_screenshot(self):
"""
截图并保存在根目录下的Screenshots文件夹下
:param none:
"""
file_path = os.path.dirname(os.getcwd()) + '/Screenshots/'
rq = time.strftime('%Y%m%d%H%M%S',time.localtime(time.time()))
screen_name = file_path + rq + '.png'
try :
self.driver.get_screenshot_as_file(screen_name)
mylog.info("开始截图并保存")
except Exception as e:
mylog.error("出现异常",format(e))
主要看最后一个截图类方法的封装。
测试类相关代码如下:
# coding=utf-8
import time
from selenium import webdriver
from test.basepage import BasePage
class TestScreenshot(object):
driver = webdriver.Chrome()
driver.maximize_window()
driver.implicitly_wait(10)
basepage = BasePage(driver)
def test_take_screen(self):
self.basepage.open_url("https://www.baidu.com")
time.sleep(1)
self.basepage.take_screenshot()
self.basepage.quit_browser()
test = TestScreenshot()
test.test_take_screen()
运行后,可以在根目录下Screenshots文件夹里找到百度首页截图。
本文就介绍了截图类方法添加到BasePage里,介绍了如何保存到根目录下的Screenshots文件夹。
Python+Selenium中级篇之10-Python中的继承的使用
本文开始介绍一个面向对象设计领域里,很常见的一种思想,继承。继承有很多好处,常听到的一句话就是,子类能够直接使用父类的方法,这样就可以减少子类代码量。其实,在自动化测试框架设计过程中,是很有必要把继承加入到你的测试脚本中去。接下来我们,简单写一个Python文件,来演示下继承的基本使用。
1. 在test1包名下新建一个classA.py,这个就是我们的父类,里面有一个打开chrome浏览器和打开百度首页的方法。
————————————————
#coding = utf-8
from selenium import webdriver
import time
class ClassA(object):
def open_baidu(self):
driver = webdriver.Chrome()
driver.maximize_window()
driver.get("https://www.baidu.com")
time.sleep(1)
driver.quit()
2. 在test2包下新建一个classB.py文件,这个继承classA.py里的CassA类。
# coding = utf-8
from test1.classA import ClassA
class ClassB(ClassA):
def test_inherit(self):
self.open_baidu()
test = ClassB()
test.test_inherit()
通过上面可以看出,只需要一句代码就可以实现ClassA中的方法,这个就是继承的好处,减少了很多代码的书写,提高代码的复用。在定义ClassB的时候就要指明ClassB的父类是ClassA. 继承相关的话题就介绍到这里,将在后面自动化框架设计会再次提到。















 437
437











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









