






原文链接:点击打开链接
摘要: 随着大数据和深度学习技术的发展,创建一个自动的人机对话系统作为我们的私人助理或聊天伙伴,将不再是一个幻想。而对话系统是否真的像媒体那样报道的“未来已来”呢?目前人机对话系统在研究领域有哪些问题和挑战呢?本文就带你了解人机对话系统的技术现状与挑战。
摘要:随着大数据和深度学习技术的发展,创建一个自动的人机对话系统作为我们的私人助理或聊天伙伴,将不再是一个幻想。而对话系统是否真的像媒体那样报道的“未来已来”呢?目前人机对话系统在研究领域有哪些问题和挑战呢?本文就带你了解人机对话系统的技术现状与挑战。在《云栖大讲堂第三期|未来人机交互技术沙龙》上,北京大学助理教授严睿站在学者的角度做出了解答。
数十款阿里云产品限时折扣中,赶紧点击这里,领劵开始云上实践吧!
本场技术沙龙回顾链接:大咖分享 | 人机交互技术需要什么样的创新?
演讲嘉宾简介:
严睿,北京大学计算机科学与技术研究所研究员,北京大学助理教授,博士生导师,前百度公司资深研发,华中师范大学与中央财经大学客座教授与校外导师。主持研发多个开放领域对话系统和服务类对话系统,发表高水平研究论文近50篇,担任多个学术会议(KDD, IJCAI, SIGIR, ACL, WWW, AAAI, CIKM, EMNLP等)的(高级)程序委员会委员及审稿人。以下内容根据演讲嘉宾PPT以及视频整理而成(云栖社区做了不修改原意的编辑)。

目前在国内,对话系统是非常热门的,下图中就列举了一些对话系统,比如大型互联网公司旗下的阿里小蜜、百度的度秘等,当然还有很多初创公司也都进军了对话系统,比如比较知名的三角兽等。


对话系统的问题定义
回到主题上来,既然要做一个对话系统,那么首先需要了解对话的流程。对于对话流程最简单的定义就是针对用户的输入,产生一个输出。而产生怎样的输出则属于算法需要考虑的问题,比如需要用到哪些信息作响应。因为对话是一个连续的过程,所以上下文是非常重要的,回复的话需要考虑上下文的语境,此外还需要从知识库中获取信息,这是因为如果对话系统不了解人类世界的知识,那就变成了胡说八道,这样对话也无法继续进行下去。当然,在对话的过程中还需要一些语义逻辑信息,对话系统应该可以顺着逻辑主线聊天,否则就会让人觉得人格分裂。而以上这些问题就使得对话系统实现起来变得困难。

然而,对话系统源自于人类对于直觉行为的认知,而目前对话系统做的不够好的原因是人类对于如何进行对话还没有充分的认识。大家可以想象一下,人与人之间的对话基本上也都来自于直觉,很少会思考为什么会产生这样的回答,所以人类对于对话过程并不是很清晰,还处于一个认知的瓶颈期。对话系统也有一些需要考虑的任务点,比如现在能够解决的比较好的相关性,目前至少产生的回答能够与上下文是相关的,当然还有更多的点比如像趣味性,如果和机器聊天很无聊,那么人就不会继续聊下去了。此外还有信息量,人与人之间聊天是希望达到信息交互的过程,但是如果和对话机器人聊天,机器人提供的都是无营养的内容,可能聊天也就没有了意义。以上这些问题就是在对话系统需要解决的问题,但是目前并没有都被很好地解决。
对话系统分类

按回复方式进行分类,目前工业界的主流是检索式对话系统,基本上就是获取大量的人与人对话的语料,当系统接收到一句话,则判断语料中是否存在类似的回答,如果存在则直接将回答返回即可。检索式对话系统是比较可控的,因为语料库中都是人类写的回答。第二种就是生成式对话系统,这是目前的潮流和趋势,但是该技术目前还不够成熟。这种方式就是通过大量的语料学习出当接收到人发来的一句话应该如何回答,系统可能就会为这句话产生一个新的回答,而不需要一定是原来语料库中包含的,这样就是生成式对话系统。但是其中也存在一些问题,即便神经网络技术将生成式对话的水平向上提升了一大截,但是有时候获得的结果还是不像人话。对话系统的可行做法就是将现有主流系统与未来系统进行结合,使得其可用。
按照场景进行分类,一般会分为单轮对话和多轮对话。单轮对话就是只考虑当前的用户输入并产生相应的回答,通常在做初步研究的时候可以使用这种最简单的假设,但是在实际应用的时候却不应该采用这种假设,因为一般而言对话是连续的,也是多轮交互的。
按照方式分类则比较有意思,通常情况下现在的对话系统都是被动式的,接收到人发来的消息之后,对话系统再产生一个回答。但是实际上人与人的对话不是这样的,有可能某一方在对话中会带节奏,也就是挑起一些新内容,在对话中加入主动因素,有意识地进行交互。
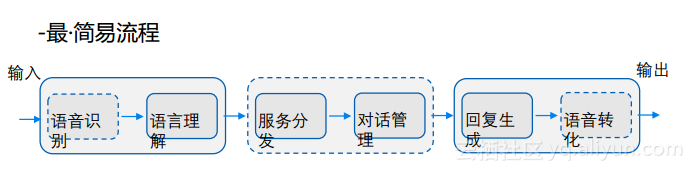
对话系统的简易流程
学术界构建的流程相比于工业界是非常抽象的,大致就是来了语音输入,先将其转化为文本,进行对话管理以及意图理解,转化成回答然后输出。学术界构建的流程不外如是这样的抽象流程,而在工业界具体应用的时候就会做得非常细致,每一个步骤都会进行详细的设计和处理,这就是学术界和工业界的区别。
对话系统会有一个线下的过程,获取数据以及建立检索模型和深度模型都是在线下完成的。当然也会有线上过程,当用户来了一句话就需要为其产生相应的回答并返回给用户。
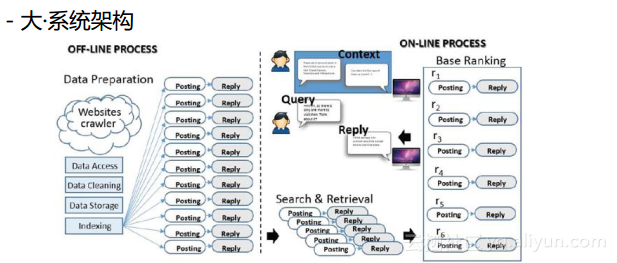
对于对话系统而言,数据很重要,所以首先分享一下学术界可以获得的公开数据。学术界和企业不同,因为企业界有真实的用户和日志等数据,而学术界没有,只能拿到一些公开的数据,比如新浪微博、豆瓣以及贴吧等的数据。这个过程是比较复杂的,首先要爬取人与人之间的对话数据,做过滤和清洗,抽取出对话对以及对话的模式。

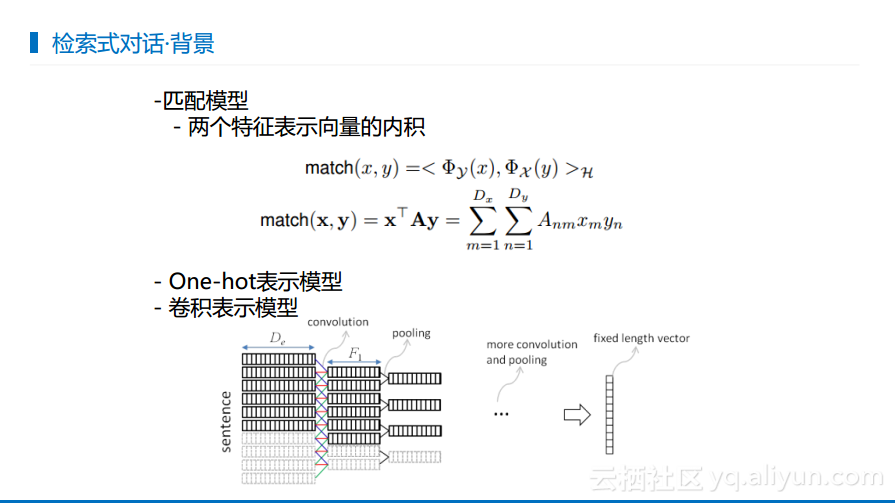
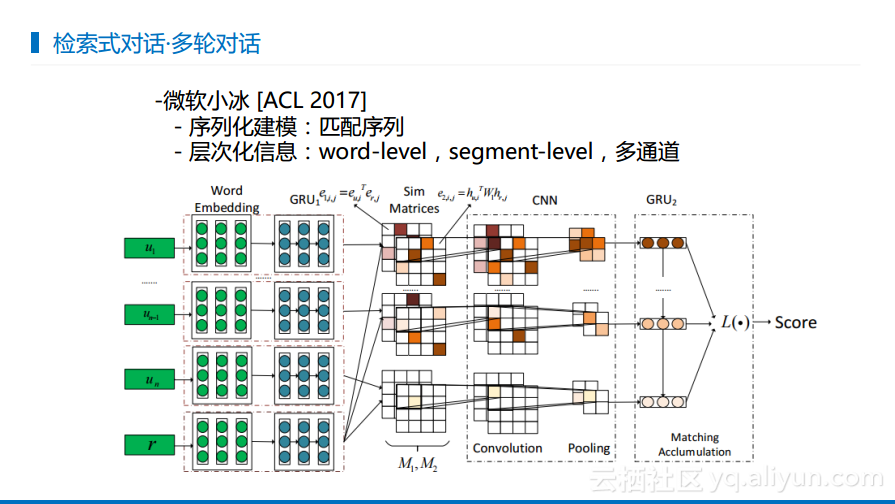
检索式对话-背景
检索式对话的思想非常简单,无非就是来了一句输入需要产生一个回答,也就是将对话进行匹配,只要两者能够匹配成功那就是一个好的回答。基本思想就是将输入和候选输出投射到一个语义空间中,判断两者是否相似,如果相似那就是好的,否则就不是好的回答。对于是否相似的计算而言,传统方式就是基于One-hot,某一个词出现就是1,不出现就是0,这是一个比较陈旧的表达方式。而当深度学习崛起之后,大家开始使用表示学习,也就是学习出一个embedding然后嵌入,无论是word embedding还是sentence embedding都是表示抽象的,也可以是基于抽象表示的相似度计算。
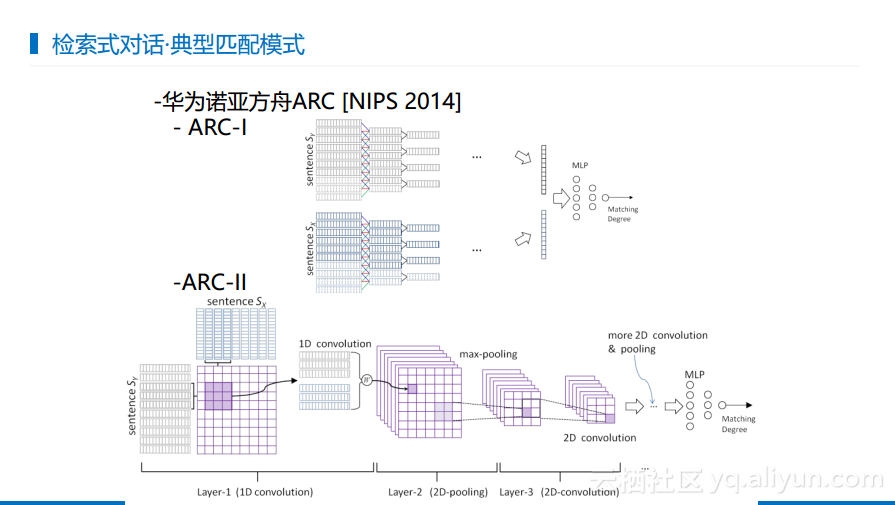
下图展现了华为早期做的判断两句话是否相似的工作,其提供了两种比较好的Architecture,一种是将每句话单独做成一个表示来计算相似度,另一种是在匹配的过程中通过更细腻的Intention来做相似度计算。这两种Architecture在后面的检索式对话都有上都有被沿用。
在检索式匹配里面有一些比较有意思的点。通常情况下进行匹配是将一句话整个输入完成之后得到最终状态,之后计算其匹配,但是借助计算机中常用的递归思想可以将中间的状态拿下来进行匹配,这样能够拿到更多的证据来匹配,这样就会有更多的自信来判断两者匹配的情况。此外还有两种匹配方式,一种是基于LSTM的匹配,另外一种是基于GRU的匹配。
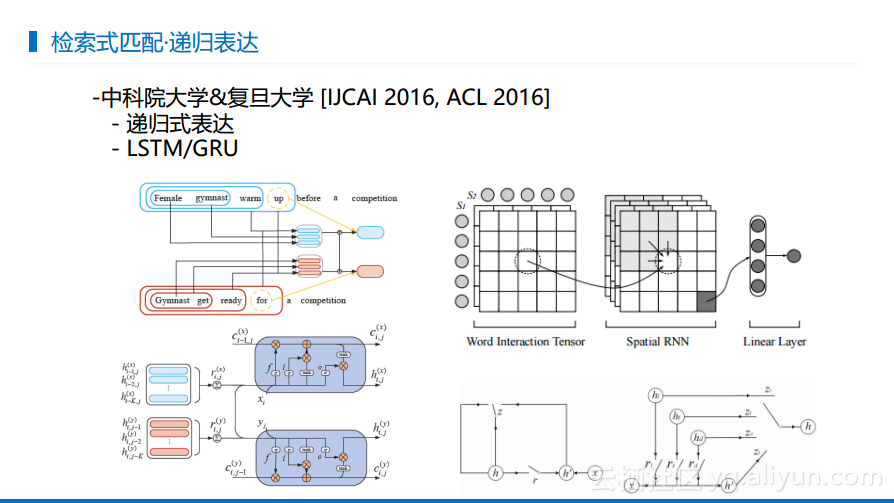
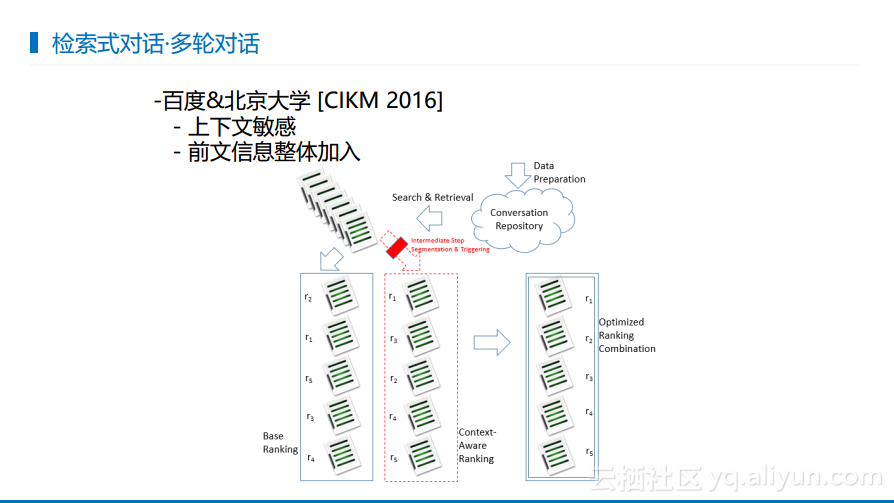
百度最早做了检索式对话上下文敏感部分。最初的想法是比较简单的,首先根据当前用户输入寻找一个候选的结果来判断哪个更加合适,这时候叫做上下文无关的。之后还要看在给定上下文之后,哪一个候选更加合适,从而形成另外一个排序,这样就能够形成一个优化的排序,这样最终的结果就既和查询相关又和上下文相关。
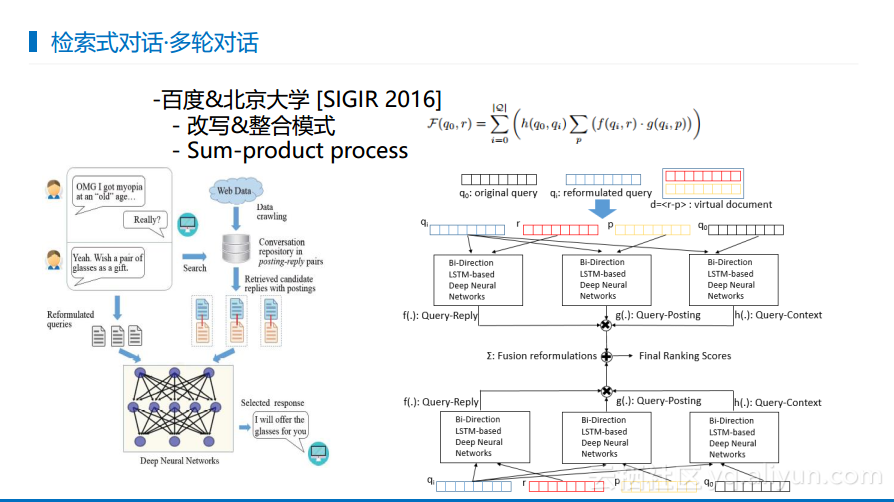
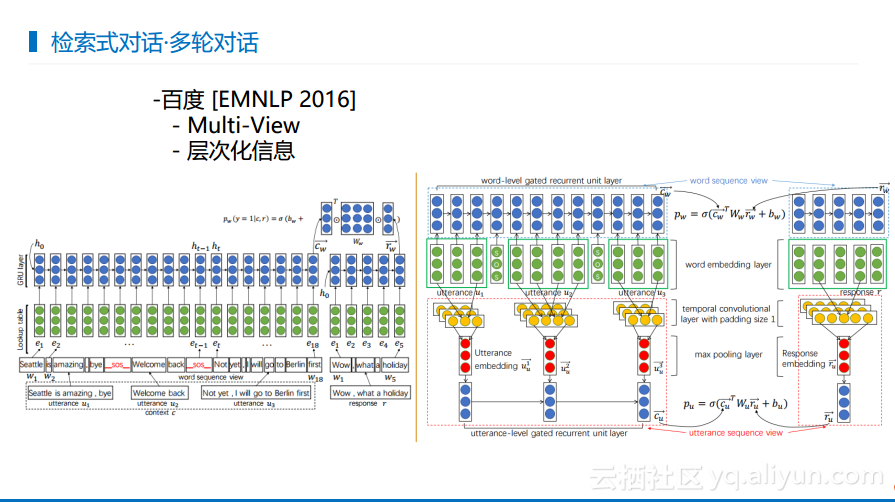
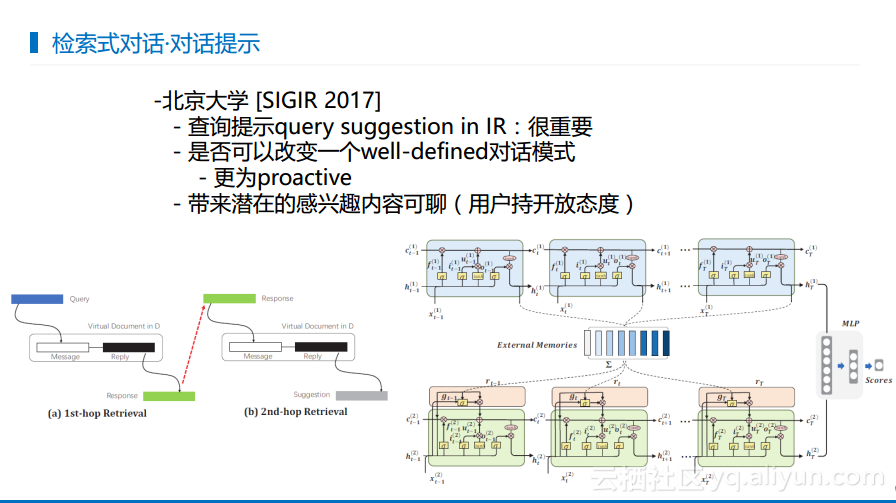
下图展现的是北京大学所做的一些相关工作。检索式对话的思想来自于信息检索,在信息检索里面有一个有意思的概念叫做查询提示,也就是用户查询了一些东西,系统给出反馈告诉用户其他相关的东西或者更好的说法。所以在北大的工作中也借鉴了这样的做法,就是用户输入一句话,系统会产生回答并且给出相应的建议,用户可以顺着这个建议继续聊下去。这也是主动式对话的一个尝试,也就是有意识地让系统可以学习出引领用户走下去的内容,目前这部分工作在学术界看来是很有意义的内容,但是具体实践还需要工业界去尝试。
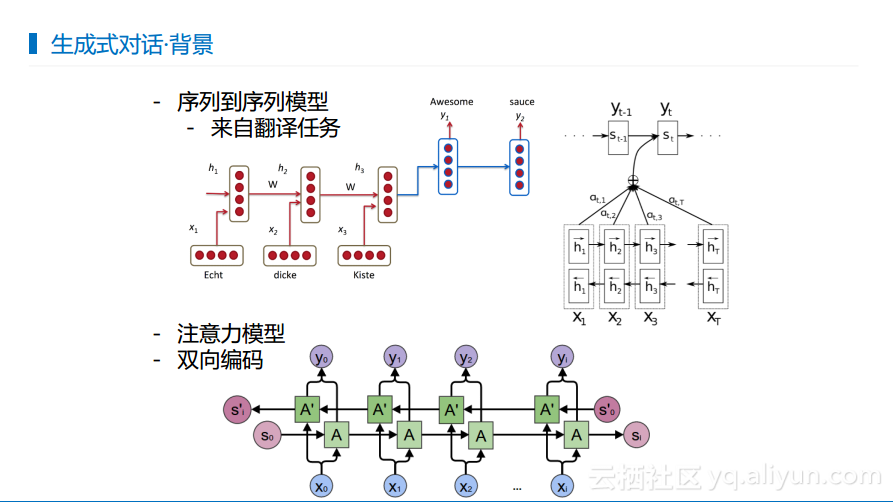
生成式对话-背景
对于生成式对话而言,一般认为下图所展示的三个模型是标配,分别是序列到序列模型,用于判断输入和输出之间的对齐关系的注意力机制,以及双向编码机制。
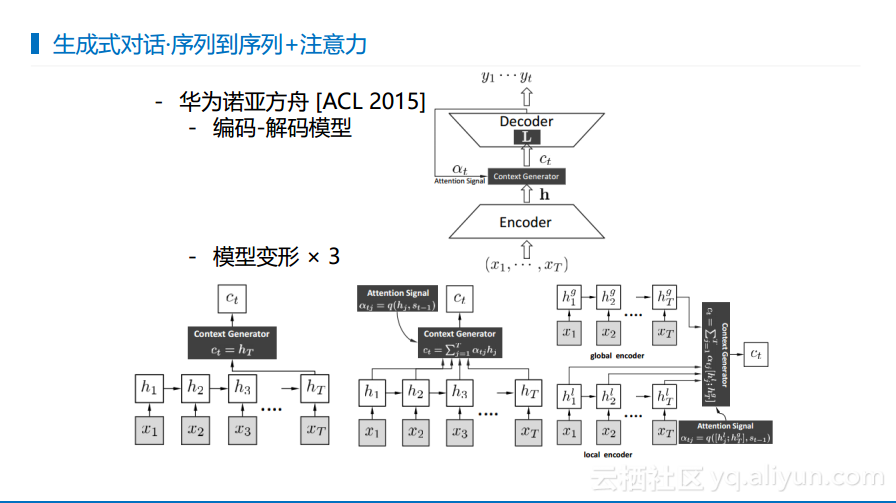
下图是华为的诺亚方舟实验室做的生成式对话的早期工作,就是将序列到序列模型用到对话领域,并且加上了不同层次的注意力机制。
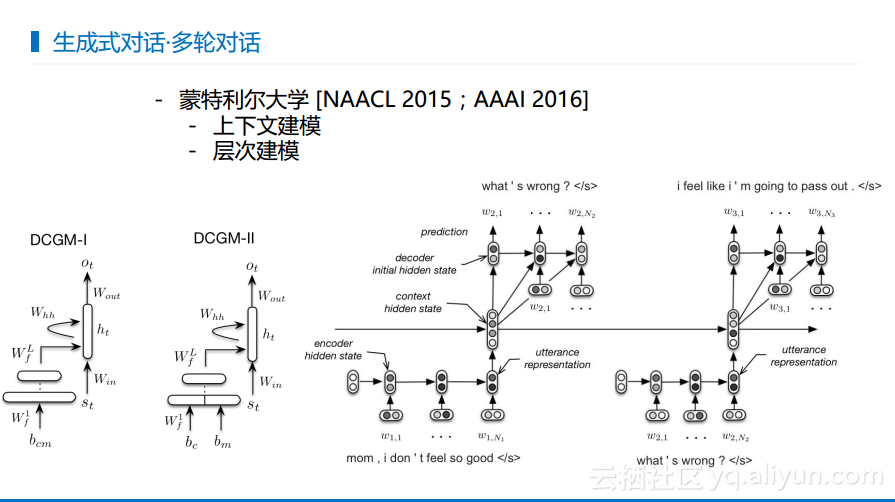
对话需要有上下文,那么如何将上下文整合到生成式对话里面去呢?最简单的就是将上下文做一个生成式表示然后拼接到当前的输入里面去作为表示+表示的方式,然后进行解码并得到一个回复的结果。第二种方式就是加上了层次化的因素,加上了一个中间状态,每一轮都会有当前轮的信息,当前轮的信息会传递给全局的表示,全局表示会一直带着信息走,所以在后面产生回复的时候是对上下文信息有感知的。
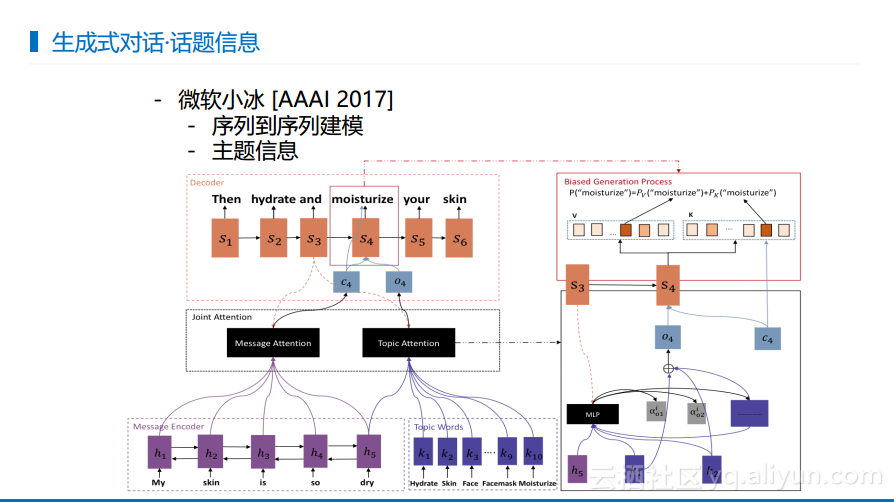
微软小冰团队所做的工作就是希望一方面使得回答保持字面的相关性还不够,还需要对于产生的回答保持话题相关性,这是比字面意义更加抽象的一层概念。可以看出下图中左侧是基于字面生成的概率,右侧是基于话题的概率,这样使得最终可以既考虑字面意义也考虑话题意义。这就是带有话题信息的生成式对话的语义模型。
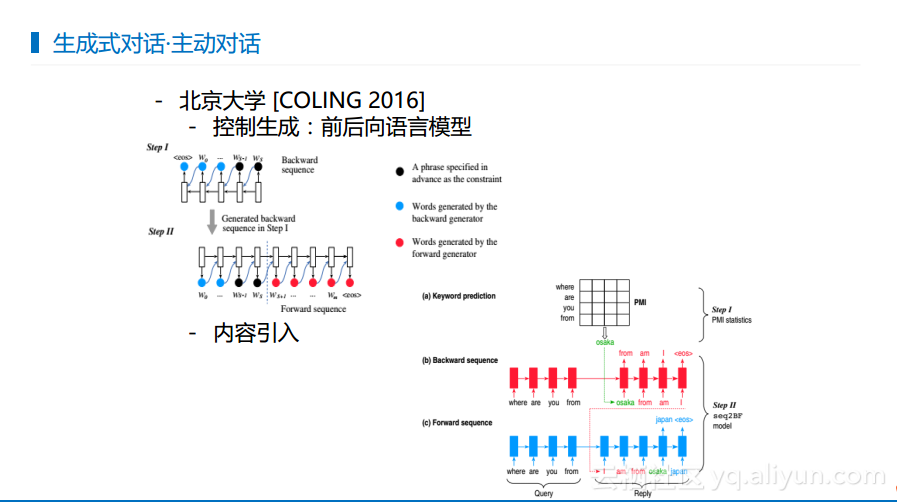
下图展现的是北京大学所做的与主动对话相关的工作。大家在聊天的时候通常希望告诉对方一些信息,往往是带着一定的目的讲话的,所以在回答里面也会含有想要传达的信息,可以将这种信息称作约束。而约束又分为了几种方式,当来了输入的查询之后判断出什么词在回复中一定要出现,然后将这个词预先生成出来,并根据输入的查询从后往前生成半句话,根据这半句话进行补全,所以这样就一定包含了强制约束的信息。
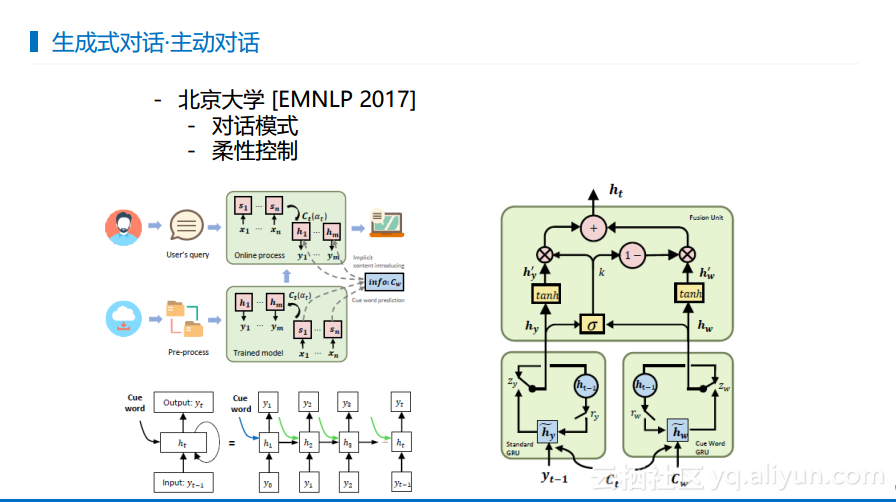
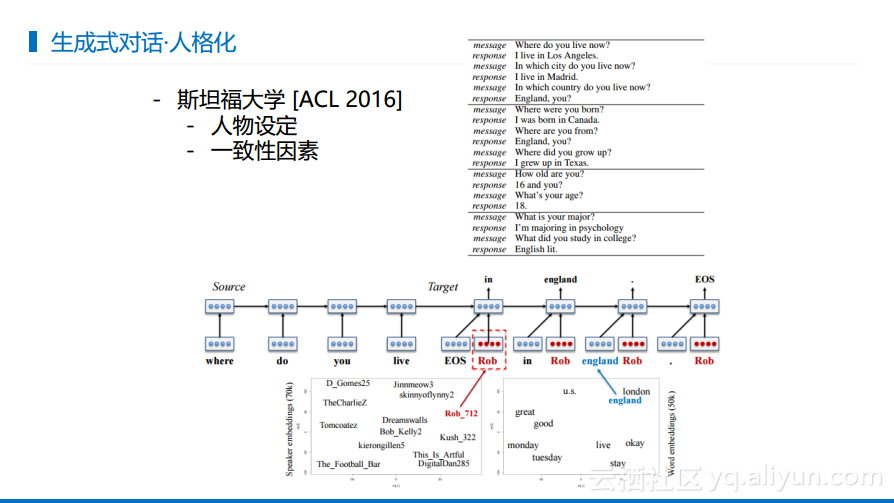
在对话中,每个人讲话都是有不同的人物设定的,东北汉子和江南妹子肯定具有不同的人物设定。所以通常对话系统在人格上需要保持一些,不能出现人格分裂的情况。斯坦福大学做的工作就是将人格通过additional personal进行刻画,在产生回复的时候需要从personal中获取信息,使得回复符合人物设定。
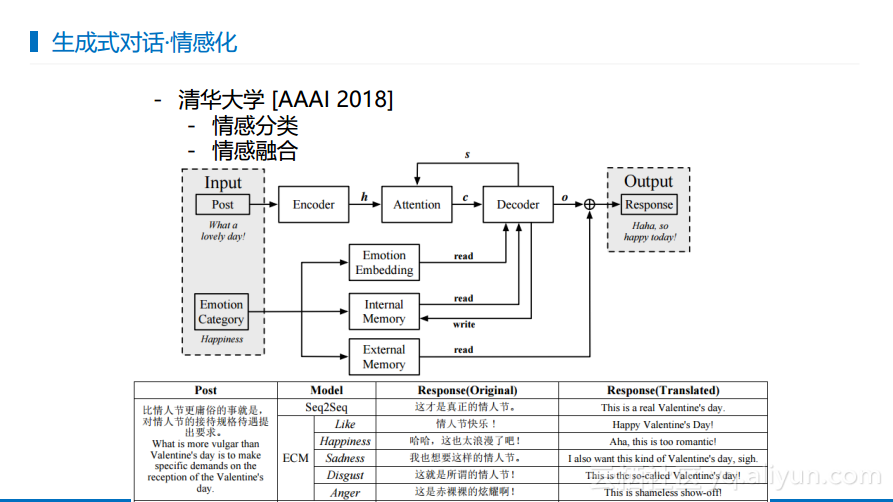
清华大学做了情感对话的相关工作。因为人在对话时会传递出自己的感情,如果对话系统的情绪完全不受控也是不合理的,如果你将一件很悲伤的事情向对话系统宣泄,但是它却表示兴高采烈,那么可能你就会分分钟想要关电脑。清华大学在自己的工作中加入了控制单元来判断当前这句话需要产生什么情感,这个情感是否能够在产生的输出里面得到体现,使得最终的回复体现了情感。
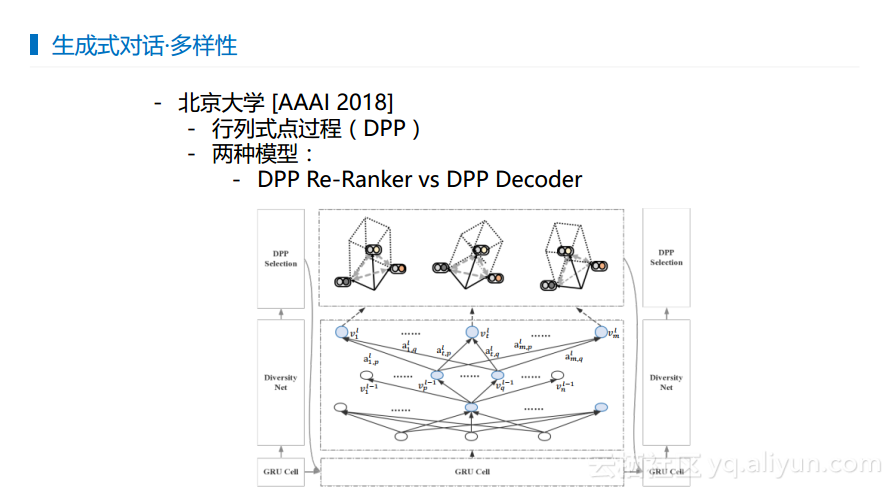
对话多样性也是很重要的问题,因为对话和其他语言任务不太一样。对于机器翻译而言,输入英文产生中文,结果的大致意思是一致的,基本上只需要对照英文进行翻译。而对于对话而言,输入一句话可能有N种回复,并且每种回复都不一样,但是每种回复都是可以用的,这样就有一个很强烈的多样性的体现。但是仅依靠模型学习很难体现这样的特征,因为机器往往会学习出最有可能的那种,而最有可能的就是“我不知道”或者“哈哈”这样的无关痛痒的回答,因为无论输入什么,都可以用“我不知道”或者“哈哈”回答。所以需要将一些经常出现的东西压下去,把一些不经常出现的内容提上来,使得对话具有多样性的特征。

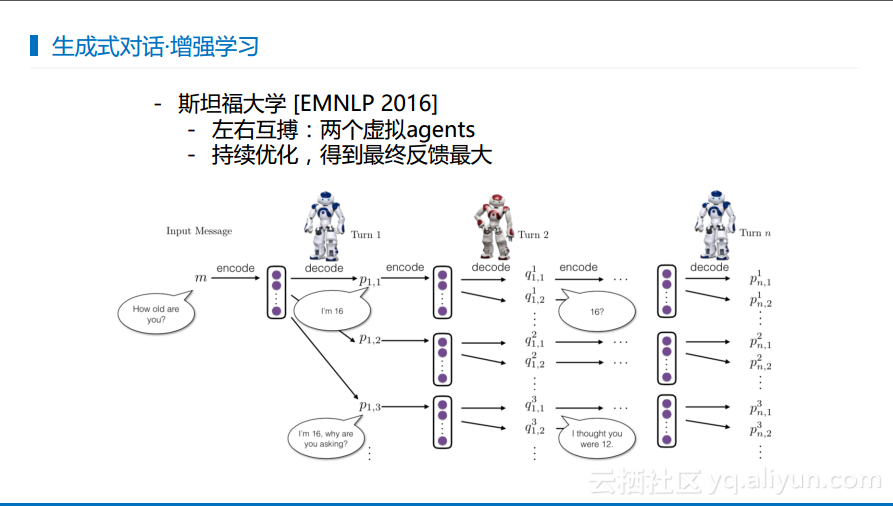
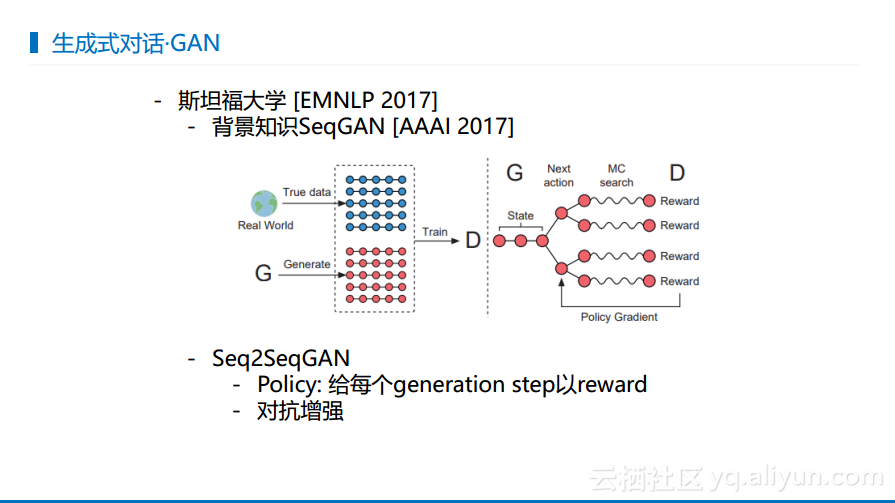
下图展现的是斯坦福在生成式对话中使用增强学习所做的工作。类似于两个对话机器人互相对话达到增强的效果,也就是左右手互搏的过程。其目标很明确就是选择什么样的模式才能使得对话的过程尽可能长,尽可能选择合适的对话模式。
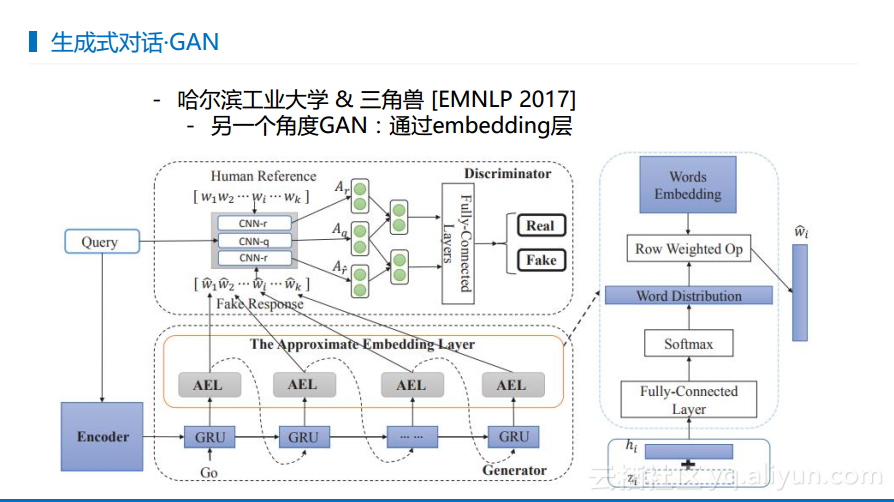
GAN就是对抗生成神经网络,这个概念是比较火的,属于左右手互搏的概念。就是生成假的数据让系统进行判断,GAN在2107年应用于语言方面,因为语言和图片不一样,图片都是连续的数据,比较容易处理,但是语言却是离散的数据,不太容易应用。而斯坦福大学加以改进实现了Seq2SeqGAN,使得生成的回答也需要做一次区分,判断出是真的回答还是系统产生的回答,当区分器都无法判断出来对话是人产生的还是系统产生的,就说明对话系统的能力已经很强大了。
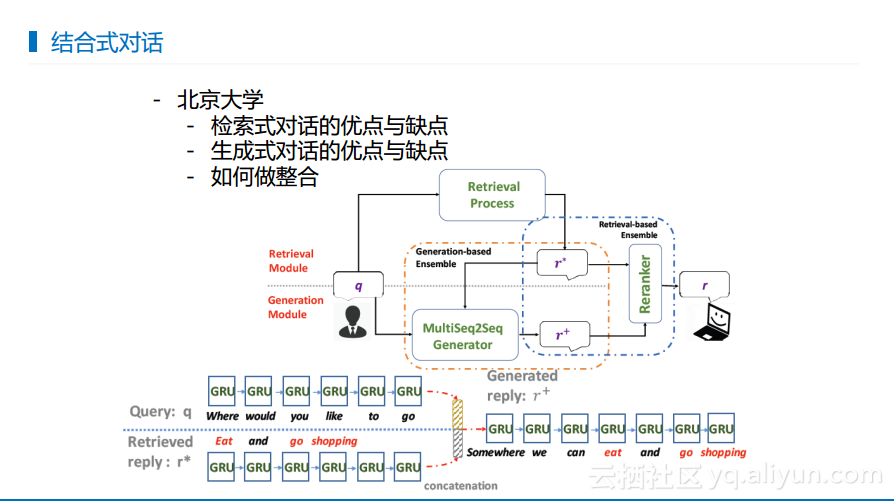
北京大学提出了一个想法,而且该想法目前在阿里小蜜中已经应用了。大家都知道检索式对话存在一定的瓶颈,数据永远不会满足“够”的条件,而生成式对话的优点就是灵活,只要是学到了对话的模式,不一定要数据储备也能够回答。其问题就是有时候生成的回答不太可控,所以需要将检索式对话和生成式对话进行结合,这个结合也在阿里小蜜的相关工作中发表出来了。
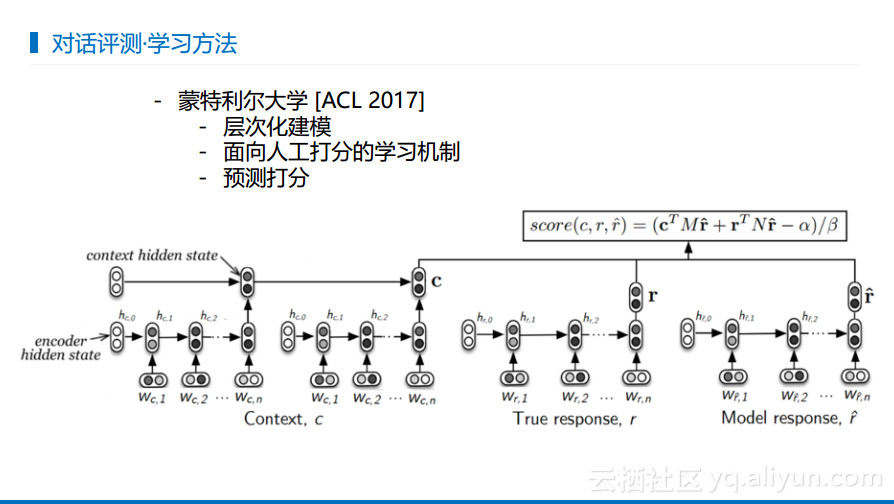
对话的自动化评价也是大家所关心的,因为缺少评价就无法知道所做的东西是否够好。对话的方式通常是从机器翻译里面来的,所以使用机器翻译的评价指标其实是不太好用的,这是因为机器翻译有一一对应关系,而对话却没有。所以蒙特利尔大学也做了相关的工作证明使用机器翻译的评价指标来衡量对话系统是不科学的。

蒙特利尔大学提出了将所有输入的查询、上下文以及产生的回答都扔到神经网络中,让神经网络和人工进行打分,以这种方式评判对话系统是否够好,这是一种解决思路。但是会发现里面存在另一个问题,这里面需要人工打分,但是人工打分就可能不够客观。
北京大学也提出了一个工作来做对话评价,这时候就不需要人工打分了。这个工作出于两种假设,一种是产生的回答能够与真实的结果很像,那么就是一个很好的结果;如果不像则去判断回复能否与查询产生很好的匹配,如果能够则也是很好的回复,通过这样的方式做对话评价,而不需要人工打分。
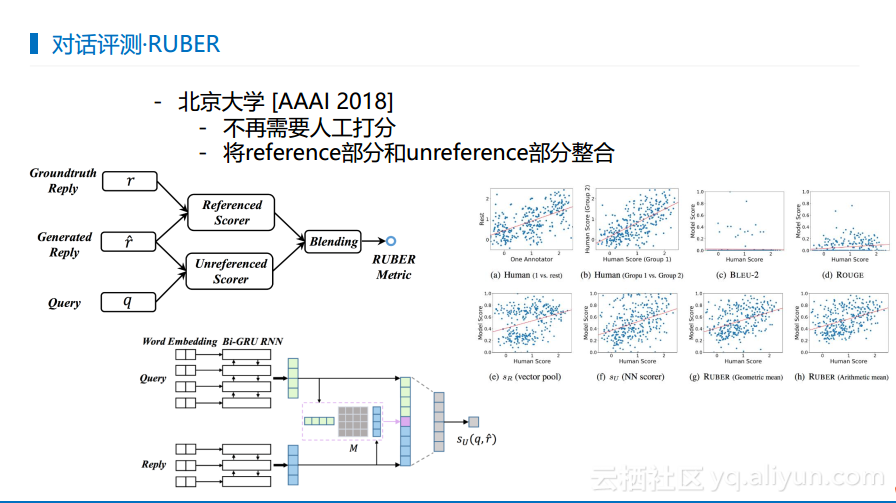
总结而言,人机对话看起来已经做得很好,媒体都在说“未来已来”,今天一个“重磅”,明天一个“号外”,让民众以为我们离“终结者”已经不远了,但是当真正使用对话系统才会知道,其实技术上还存在很大的差距。














 1053
1053











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









