







什么是Mapping
- Mapping 类似数据库中的 schema 的定义,作用如下
- 定义索引中的字段的名称
- 定义字段的数据类型, 例如 字符串,数字,布尔 。。。
- 字段,倒排索引的相关配置,(Analyzed or Not Analyzed Analyzer)
- Mapping 会把 JSON 文件映射成 Lucene 所需要的扁平格式
- 一个Mapping 属于一个索引的Type
- 每个文档都属于一个索引的Type
- 一个Type 有一个Mapping 定义
- 7.0 开始, 不需要在 Mapping 定义中指定 type 信息、
字段的数据类型
- 简单类型
- Text / Keyword
- Date
- Integer / Floating
- Boolean
- Ipv4 & Ipv6
- 复杂类型 - 对象和嵌套对象
- 对象类型 / 嵌套类型
- 特殊类型
- geo_point & geo_shape / percolator
什么是 Dynamic Mapping
- 在写入文档时候,如果索引不存在,会自动创建索引
- Dynamic Mapping 的机制,使得我们无需手动定义 Mappings。ElasticSearch 会自动根据文档信息推算出字段的类型
- 但是有时候会推算的不正确,例如 地理位置信息
- 当类型如果设置不对时,会导致一些功能无法正常运行, 例如 Range 查询
尝试添加一个文档
// 写入文档,查看Mapping
PUT mapping_test/_doc/1
{
"firstName": "Chan",
"lastName" : "Jackie",
"loginDate" : "2018-07-24T10:29:48.103Z"
}
查看mapping
// 查看Mapping 文件
GET mapping_test/_mapping
返回
{
"mapping_test" : {
"mappings" : {
"properties" : {
"firstName" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"lastName" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"loginDate" : {
"type" : "date"
}
}
}
}
}
** 我们看到这里。es 将 loginDate 字符串自动处理成了 date 类型的**
重新添加一份
// dynamic mapping 推断字段的类型
PUT mapping_test/_doc/1
{
"uid":"123",
"isVip": false,
"isAdmin":"true",
"age":19,
"heigh":180
}
查看 mapping
{
"mapping_test" : {
"mappings" : {
"properties" : {
"age" : {
"type" : "long"
},
"heigh" : {
"type" : "long"
},
"isAdmin" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"isVip" : {
"type" : "boolean"
},
"uid" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
}
我们看到age和heigh 都被处理为了long 类型, isVip 被处理为了 布尔类型,uId 被处理为了 text 类型,isAdmin 也被处理为了 text类型
ES 的类型自动识别
| JSON类型 | ElasticSearch 类型 |
|---|---|
| 字符串 | 匹配日期格式 |
| 字符串 | 设置数字设置为float 或者long ,该选项默认关闭 |
| 字符串 | 设置为Text,并且增加 keyword 子字段 |
| 布尔值 | boolean |
| 浮点数 | float |
| 整数 | long |
| 对象 | Object |
| 数组 | 由第一个非空数值的类型所决定 |
| 空值 | 忽略 |
能否修改Mapping的类型
两种情况
- 新增加字段
- Dynamic 设置为true 时, 一旦有新增字段的文档写入, Mapping 也同时被更新
- Dynamic 设置为false 时,Mapping 不会被更新,新增字段的数据无法被索引,但是信息会出现在_source 中
- Dynamic 设置成Strict, 文档写入失败
- 对已有字段,一旦已经有数据写入,就不再支持修改字段定义
- Lucene 实现的倒排索引, 必须Reindex API, 重建索引
- 因为如果修改了字段的数据类型,会导致已被索引的属性无法被搜索,
- 但是如果是增加新的字段,就不会有这样的影响。
| true | false | strict | |
|---|---|---|---|
| 文档可索引 | YES | YES | NO |
| 字段可索引 | YES | NO | NO |
| Mapping可以被更新 | YES | NO | NO |
控制 Dynamic Mappings
- 当 dynamic 被设置为 false 的时候,存在新增字段的数据写入,该数据可以被索引。但是新增字段被丢弃
- 当设置为 Strict 模式的时候,数据写入直接报错
PUT index_test
{
"mappings": {
"_doc":{
"dynamic" : "false"
}
}
}
如何显示的定义一个Mapping
PUT movies
{
"mappings" : {
// defome your mappings here
}
}
举个例子
Index - 控制当前字段是否被索引, 默认为 true ,如果设置为 false ,那么该字段就不可被搜索
// 显示的创建Mapping
PUT address_book
{
"mappings": {
"properties": {
"name":{
"type": "text"
},
"address":{
"type": "text"
},
"phone_num":{
"type": "text",
"index": false
}
}
}
}
- 如果对 phone_num 进行搜索。那么将会报错
GET address_book/_search
{
"query": {
"match": {
"phone": "151"
}
}
}
报错
{
"error": {
"root_cause": [
{
"type": "query_shard_exception",
"reason": "failed to create query: {\n \"match\" : {\n \"phone\" : {\n \"query\" : \"151\",\n \"operator\" : \"OR\",\n \"prefix_length\" : 0,\n \"max_expansions\" : 50,\n \"fuzzy_transpositions\" : true,\n \"lenient\" : false,\n \"zero_terms_query\" : \"NONE\",\n \"auto_generate_synonyms_phrase_query\" : true,\n \"boost\" : 1.0\n }\n }\n}",
"index_uuid": "2DiCWC3-Q762F70ezJS7RQ",
"index": "address_book"
}
],
"type": "search_phase_execution_exception",
"reason": "all shards failed",
"phase": "query",
"grouped": true,
"failed_shards": [
{
"shard": 0,
"index": "address_book",
"node": "oBuLww9BSBOBEg8MebGboA",
"reason": {
"type": "query_shard_exception",
"reason": "failed to create query: {\n \"match\" : {\n \"phone\" : {\n \"query\" : \"151\",\n \"operator\" : \"OR\",\n \"prefix_length\" : 0,\n \"max_expansions\" : 50,\n \"fuzzy_transpositions\" : true,\n \"lenient\" : false,\n \"zero_terms_query\" : \"NONE\",\n \"auto_generate_synonyms_phrase_query\" : true,\n \"boost\" : 1.0\n }\n }\n}",
"index_uuid": "2DiCWC3-Q762F70ezJS7RQ",
"index": "address_book",
"caused_by": {
"type": "illegal_argument_exception",
"reason": "Cannot search on field [phone] since it is not indexed."
}
}
}
]
},
"status": 400
}
- 如果对name 进行搜索,那么手机号码还是会出现在_source 里面的
GET address_book/_search
{
"query": {
"match": {
"name": "gaosongsong"
}
}
}
搜索结果
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.2876821,
"hits" : [
{
"_index" : "address_book",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.2876821,
"_source" : {
"name" : "gaosongsong",
"phone" : "15152268067"
}
}
]
}
}
Index Options
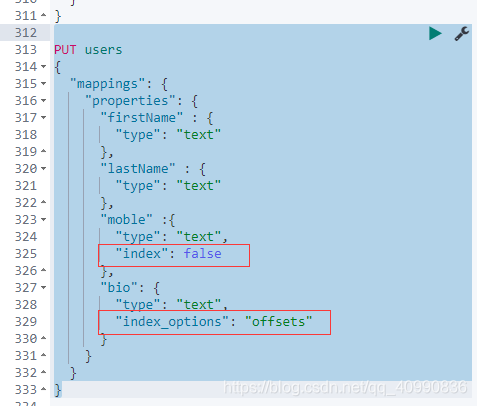
- 四种不同的级别的Index Options 设置,可以控制倒排索引记录的内容
- docs - 记录 doc id
- freqs - 记录 doc id 和 term frequencies
- positions - 记录 doc id 和 term frequencies / term position
- offsets - doc id / term frequencies / term position /character offects
- Text 类型默认记录 positions,其他默认为 docs
- 记录内容越多,占用存储空间越大
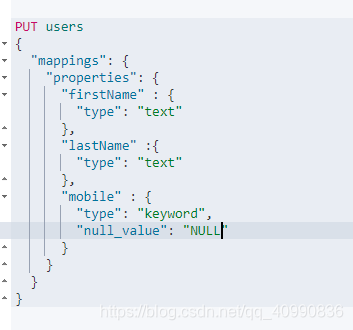
null_value
- 需要对null 值进行搜索
- 只有 KeyWord类型支持设定 null_Value
copy_to
- _all 在 7 中被 copy_to 所替代
- 满意一些特定的搜索要求
- copy_to 将字段的数值拷贝到 目标字段, 实现类似 _all 的作用
- copy_to 的目标字段不出现在 _source 中

多字段类型
特性
- 厂商名字实现精确匹配
- 增加一个 keyword 字段
- 使用不同的 analyzer
- 不同语言
- pinyin 字段的搜索
- 还支持为搜索和索引指定不同的 analyzer
Exact Value(精确值) 不需要被分词 比如 Apple Store
ElsticSearch 中的 keyword
全文本,非结构化的文本数据, ElasticSearch 中的 text
- ElasticSearch 为每一个字段创建一个倒排索引
- Exact Value 在索引时, 不需要做特殊的粉刺处理














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









