










哈希
排列组合
数组求同积元组
例:
nums = [2,3,4,6]
输出:8
解释:存在 8 个满足题意的元组:
(2,6,3,4) , (2,6,4,3) , (6,2,3,4) , (6,2,4,3)
(3,4,2,6) , (3,4,2,6) , (3,4,6,2) , (4,3,6,2)
思路:
使用一个hash,存储每个可能出现的乘积以及乘积对应出现的次数即可。
[2,3,4,6]
可能出现的乘积有 6,8,12,18,24
且每个乘积出现的次数为
map[6] = 1
map[8] = 1
map[12] = 2 (乘积出现 1 次,则只存在 2 个数的乘积为该数,不足以形成四元组)
map[18] = 1
map[24] = 1
问题转化为:
从n组数对中任取2对进行组合
那么公式就是 C n 2 C_n^2 Cn2
最后每个四元组又有八种组合 8 ∗ C n 2 8*C_n^2 8∗Cn2
代码:
class Solution {
public:
int tupleSameProduct(vector<int>& nums)
{
unordered_map<int,int> um;
for(int i=0;i<nums.size();i++)
{
for(int j=i+1;j<nums.size();j++)
{
um[nums[i]*nums[j]]++;
}
}
int res = 0;
// for(std::unordered_map<int,int>::iterator j = um.begin();j != um.end();j++)
// for(auto iter = um.begin(); iter != um.end(); ++iter)
// {
// if((iter->second)<=1) continue;
// res += (iter->second)*(iter->second-1)/2*8;
// }
for(auto& [k, v] : um) //结构化绑定
{
if(v<=1) continue;
res += v*(v-1)/2*8;
}
return res;
}
};
[auto基本用法]
①for(auto x : range)
创建拷贝,无法修改range中的元素
②for(auto& x : range)
可以修改range中的元素,也可用以下这种
for(auto&& x : range)
③for(const auto & x : range)
只读range中的元素
设计集合
705. 设计哈希集合 E 3.13
不使用任何内建的哈希表库设计一个哈希集合(HashSet)。
输入:
["MyHashSet", "add", "add", "contains", "contains", "add", "contains", "remove", "contains"]
[[], [1], [2], [1], [3], [2], [2], [2], [2]]
输出:
[null, null, null, true, false, null, true, null, false]
法一:超大数组
class MyHashSet {
public:
/** Initialize your data structure here. */
int HashSet[1000001] = {0};
MyHashSet() {
}
void add(int key) {
HashSet[key] = true;
}
void remove(int key) {
HashSet[key] = false;
}
/** Returns true if this set contains the specified element */
bool contains(int key) {
return HashSet[key];
}
};
/**
* Your MyHashSet object will be instantiated and called as such:
* MyHashSet* obj = new MyHashSet();
* obj->add(key);
* obj->remove(key);
* bool param_3 = obj->contains(key);
*/
法二:拉链法
class MyHashSet {
public:
/** Initialize your data structure here. */
vector<list<int>> data;
int hash(int key)
{
return key%1009;
}
MyHashSet():data(1009) { //构造函数初始化列表
}
void add(int key) {
int h = hash(key);
for(auto it = data[h].begin();it != data[h].end();++it)
{
if(*(it)==key)
{
return;
}
}
data[h].push_back(key);
}
void remove(int key) {
int h = hash(key);
for(auto it = data[h].begin();it != data[h].end();++it)
{
if(*(it) == key)
{
data[h].erase(it);
return;
}
}
}
/** Returns true if this set contains the specified element */
bool contains(int key) {
int h = hash(key);
for(auto it = data[h].begin();it != data[h].end();++it)
{
if(*(it) == key)
{
return true;
}
}
return false;
}
};
/**
* Your MyHashSet object will be instantiated and called as such:
* MyHashSet* obj = new MyHashSet();
* obj->add(key);
* obj->remove(key);
* bool param_3 = obj->contains(key);
*/
list容器使用: https://www.cnblogs.com/scandy-yuan/archive/2013/01/08/2851324.html
706. 设计哈希映射 E 3.14
输入:
["MyHashMap", "put", "put", "get", "get", "put", "get", "remove", "get"]
[[], [1, 1], [2, 2], [1], [3], [2, 1], [2], [2], [2]]
输出:
[null, null, null, 1, -1, null, 1, null, -1]
数组:
class MyHashMap {
public:
/** Initialize your data structure here. */
int HashSet[1000001];
// memset(HashSet, -1, sizeof(int)*1000001);
MyHashMap() {
for ( int i = 0; i < 1000001; i++ )
{
HashSet[i] = -1;
}
}
/** value will always be non-negative. */
void put(int key, int value) {
HashSet[key] = value;
}
/** Returns the value to which the specified key is mapped, or -1 if this map contains no mapping for the key */
int get(int key) {
return HashSet[key];
}
/** Removes the mapping of the specified value key if this map contains a mapping for the key */
void remove(int key) {
HashSet[key] = -1;
}
};
/**
* Your MyHashMap object will be instantiated and called as such:
* MyHashMap* obj = new MyHashMap();
* obj->put(key,value);
* int param_2 = obj->get(key);
* obj->remove(key);
*/
链表:
class MyHashMap {
private:
vector<list<pair<int, int>>> data;
static const int base = 769; //素数既可
static int hash(int key) {
return key % base;
}
public:
/** Initialize your data structure here. */
MyHashMap(): data(base) {}
//类构造函数初始化
//https://www.runoob.com/w3cnote/cpp-construct-function-initial-list.html
/** value will always be non-negative. */
void put(int key, int value) {
int h = hash(key);
for (auto it = data[h].begin(); it != data[h].end(); it++)
{
if ((*it).first == key)
{
(*it).second = value;
return;
}
}
data[h].push_back(make_pair(key, value));
}
/** Returns the value to which the specified key is mapped, or -1 if this map contains no mapping for the key */
int get(int key)
{
int h = hash(key);
for (auto it = data[h].begin(); it != data[h].end(); it++)
{
if ((*it).first == key)
{
return (*it).second;
}
}
return -1;
}
/** Removes the mapping of the specified value key if this map contains a mapping for the key */
void remove(int key)
{
int h = hash(key);
for (auto it = data[h].begin(); it != data[h].end(); it++)
{
if ((*it).first == key)
{
data[h].erase(it);
return;
}
}
}
};
贪心算法
字符串 替换隐藏数字得到的最晚时间
own:
class Solution {
public:
string maximumTime(string time) {
// if(time == NULL) return NULL;
char Time[6];
strcpy(Time,time.c_str());
char temp[3];
temp[0] = Time[0];
temp[1] = Time[1];
temp[2] = '\0';
if(temp[0] == '?')
{
if(temp[1] >= '4')
{
temp[0] = '1';
}
if(temp[1] == '?')
{
temp[0] = '2';
temp[1] = '3';
}
if(temp[1] < '4')
{
temp[0] = '2';
}
}
if(temp[1] == '?')
{
if(temp[0] == '0' || temp[0] == '1')
{
temp[1] = '9';
}
else
{
temp[1] = '3';
}
}
char tmp[3];
tmp[0] = time[3];
tmp[1] = time[4];
tmp[2] = '\0';
if(tmp[0] == '?')
{
tmp[0] = '5';
}
if(tmp[1] == '?')
{
tmp[1] = '9';
}
char res[6];
res[0] = temp[0];
res[1] = temp[1];
res[2] = ':';
res[3] = tmp[0];
res[4] = tmp[1];
res[5] = '\0';
string rest = res;
return rest;
}
};
other:
class Solution {
public:
string maximumTime(string time) {
if (time[0] == '?') {
if (time[1] == '?' || time[1] < '4')
time[0] = '2';
else
time[0] = '1';
}
if (time[1] == '?') {
if (time[0] == '2')
time[1] = '3';
else
time[1] = '9';
}
if (time[3] == '?')
time[3] = '5';
if (time[4] == '?')
time[4] = '9';
return time;
}
};
5697. 检查二进制字符串字段
给你一个二进制字符串 s ,该字符串 不含前导零 。
如果 s 最多包含 一个由连续的 ‘1’ 组成的字段 ,返回 true 。否则,返回 false 。
注:
1 <= s.length <= 100
s[i] 为 ‘0’ 或 ‘1’
s[0] 为 ‘1’
分析:
不是【二进制中的连续 1 判定】
示例 1:
输入:s = “1001”
输出:false
示例 2:
输入:s = “110”
输出:true
此外:
1 —— true
10 ——true
11000111——false
从头到尾遍历一遍每一位只能找出是否有连续的1存在,而非判断【最多包含】
class Solution {
public:
bool checkOnesSegment(string s) {
bool res1 = false;
bool res2 = false;
// bit numT = stoi(s);
int num = stoi(s, nullptr, 2);
// int num = numT.to_ullong();
while(num > 0)
{
res1 = num % 2;
if(res1&&res2)
return true;
num = num >> 1;
res2 = res1;
}
return false;
}
};
1.从第一个0开始只要出现1就是false。
2.s[0]=1。
正确的方法:
设置标志ans记录是否“最多只有一个”包含,last记录遍历过程字符串末位,一次遍历即可。【时间复杂度O(∣S∣);空间复杂度O(1)】
class Solution {
public:
bool checkOnesSegment(string s) {
int ans = 0;
char last = '0';
for (char c : s) {
if (c == '1' && last == '0') {
ans++;
}
last = c;
}
return ans <= 1;
}
};
注:
char c : s
相当于C++的:
for( int i = 0; i < s.length(); i++)
{
s[i]....
}
for (char c : s)
复制一个s字符串再进行遍历操作,而使用
for (char& c : s)
直接引用原字符串进行遍历操作,由于复制一个字符串会花费更多时间,故快于前者。
动态规划
区域和检索
数组 3.1 M
给定一个整数数组 nums,求出数组从索引 i 到 j(i ≤ j)范围内元素的总和,包含 i、j 两点。
示例:
输入:
[“NumArray”, “sumRange”, “sumRange”, “sumRange”]
[[[-2, 0, 3, -5, 2, -1]], [0, 2], [2, 5], [0, 5]]
输出:
[null, 1, -1, -3]
解释:
NumArray numArray = new NumArray([-2, 0, 3, -5, 2, -1]);
numArray.sumRange(0, 2); // return 1 ((-2) + 0 + 3)
numArray.sumRange(2, 5); // return -1 (3 + (-5) + 2 + (-1))
numArray.sumRange(0, 5); // return -3 ((-2) + 0 + 3 + (-5) + 2 + (-1))
分析:
1.
2.
resize带两个参数,一个表示容器大小,一个表示初始值(默认为0)
reserve只带一个参数,表示容器预留的大小。
代码:
class NumArray {
public:
vector<int> sums;
NumArray(vector<int>& nums) {
int n = nums.size();
sums.resize(n+1);
for(int i = 0;i<n;i++)
{
sums[i+1] = sums[i] + nums[i];
}
}
int sumRange(int i, int j) {
return sums[j+1] - sums[i];
}
};
/**
* Your NumArray object will be instantiated and called as such:
* NumArray* obj = new NumArray(nums);
* int param_1 = obj->sumRange(i,j);
*/
二维区域和检索
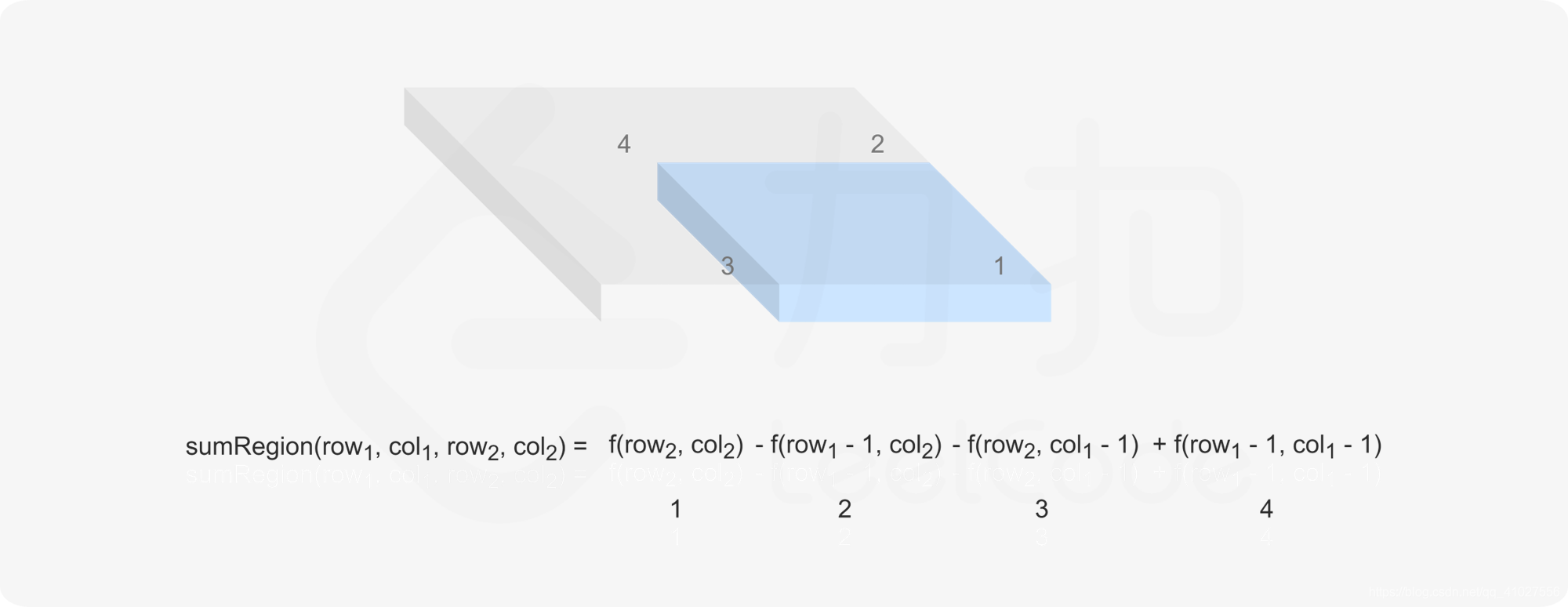
矩阵区域不可变 3.2 M
给定一个二维矩阵,计算其子矩形范围内元素的总和,该子矩阵的左上角为 (row1, col1) ,右下角为 (row2, col2) 。
例:
给定 matrix = [
[3, 0, 1, 4, 2],
[5, 6, 3, 2, 1],
[1, 2, 0, 1, 5],
[4, 1, 0, 1, 7],
[1, 0, 3, 0, 5]
]
sumRegion(2, 1, 4, 3) -> 8
sumRegion(1, 1, 2, 2) -> 11
sumRegion(1, 2, 2, 4) -> 12
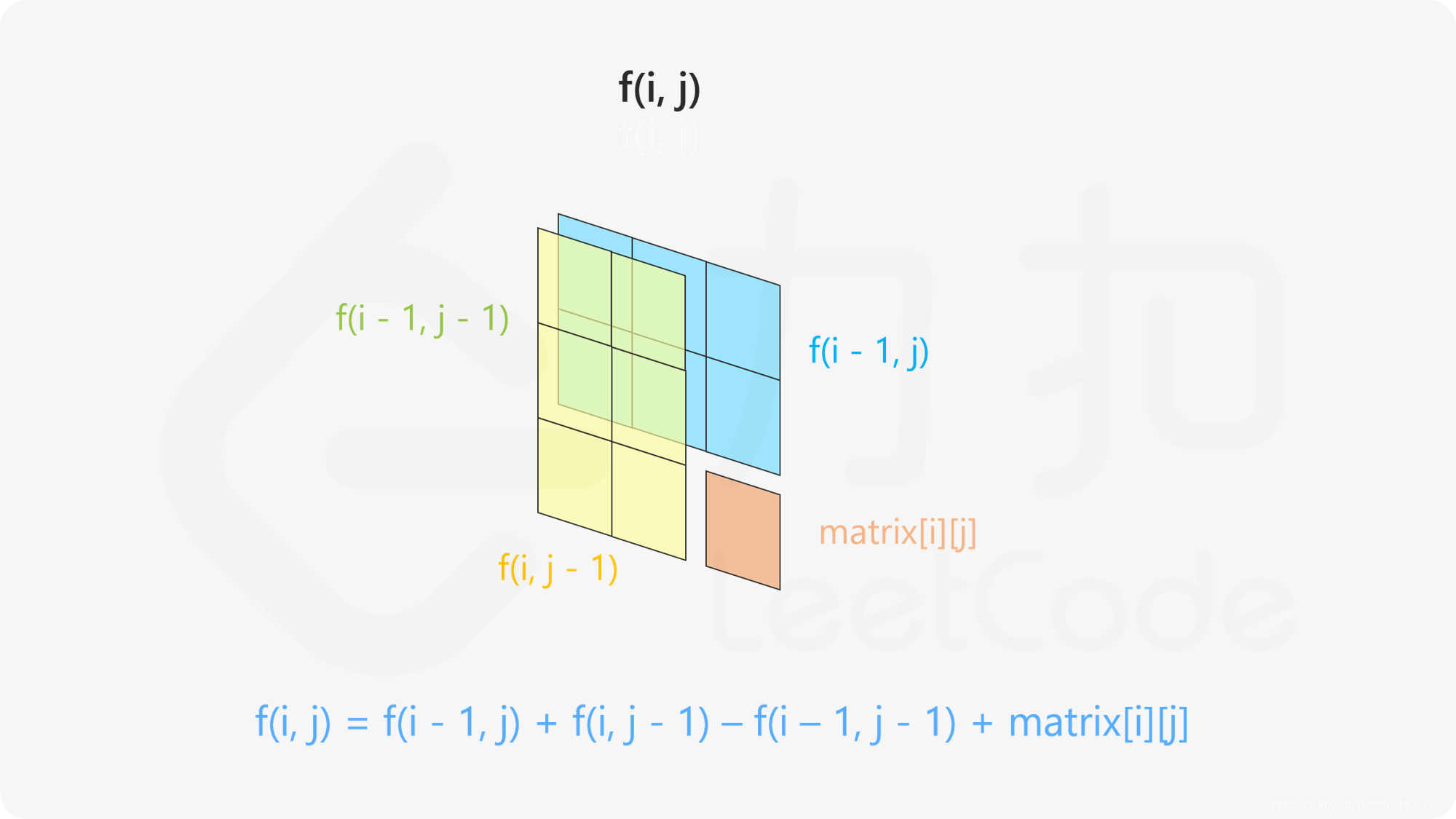
分析:
前缀和方法同上一题
代码:
class NumMatrix {
public:
vector<vector<int>> sums;
NumMatrix(vector<vector<int>>& matrix) {
int n1 = matrix.size(); if(n1==0) return;
int n2 = matrix[0].size();
sums.resize(n1+1,vector<int>(n2+1));
for(int i=0;i<n1;i++)
{
for(int j=0;j<n2;j++)
{
sums[i+1][j+1] = sums[i][j+1]+sums[i+1][j]+matrix[i][j]-sums[i][j];
}
}
}
int sumRegion(int row1, int col1, int row2, int col2) {
return sums[row2+1][col2+1] - sums[row2+1][col1] - sums[row1][col2+1] + sums[row1][col1];
}
};
/**
* Your NumMatrix object will be instantiated and called as such:
* NumMatrix* obj = new NumMatrix(matrix);
* int param_1 = obj->sumRegion(row1,col1,row2,col2);
*/
注意:
1.
为零情况,
if(n1==0) return;
2.
sums.resize(n1+1,vector(n2+1));
vector(n) 表示构造一个匿名且含n个 0 的vector对象。
排序
最长递增子序列 3.4 H
例如:
输入: envelopes = [[5,4],[6,4],[6,7],[2,3]]
输出: 3
解释: 最多信封的个数为 3, 组合为: [2,3] => [5,4] => [6,7]。
一维情况
本题为二维情况,代码:
class Solution {
public:
int maxEnvelopes(vector<vector<int>>& envelopes) {
//先让w升序排序;w相等者无法套入,则选择(w相等)其中h最小者继续讨论,此时,h应当降序,使最小者最后。
if(envelopes.empty())
return 0;
int n = envelopes.size();
//Lambda表达式
sort(envelopes.begin(),envelopes.end(),[](const vector<int>& a1,const vector<int>& a2)
//也可以使用auto:const auto& e1, const auto& e2
{
if(a1[0] != a2[0])
{
return a1[0] < a2[0]; //升序
}
else
{
return a1[1] > a2[1]; //降序
}
//或return a1[0] < a2[0] || (a1[0] == a2[0] && a1[1] > a2[1]);
});
vector<int> find(n,1);
for(int i = 1;i < n;i++)
{
for(int j = 0;j<i;j++)
{
if(envelopes[j][1]<envelopes[i][1])
{
find[i] = max(find[i],find[j]+1);
}
}
}
return *max_element(find.begin(),find.end());
//vector容器求最大最小元素 max_element、min_element。
}
};
动态规划+二分查找
class Solution {
public:
int maxEnvelopes(vector<vector<int>>& envelopes) {
//先让w升序排序;w相等者无法套入,则选择(w相等)其中h最小者继续讨论,此时,h应当降序,使最小者最后。
if(envelopes.empty())
return 0;
int n = envelopes.size();
sort(envelopes.begin(),envelopes.end(),[](const vector<int>& a1,const vector<int>& a2)
//也可以使用auto:const auto& e1, const auto& e2
{
if(a1[0] != a2[0])
{
return a1[0] < a2[0]; //升序
}
else
{
return a1[1] > a2[1]; //降序
}
//或return a1[0] < a2[0] || (a1[0] == a2[0] && a1[1] > a2[1]);
});
vector<int> res = {envelopes[0][1]};
for(int i = 1;i<n;++i)
{
if(int num = envelopes[i][1];num > res.back())
{
res.push_back(num);
}
else
{
auto it = lower_bound(res.begin(),res.end(),num);
//返回一个迭代器,从begin位置到end位置二分查找第一个大于或等于num的数字
*it = num;
}
}
return res.size();
}
};
类似题目(一维):
https://leetcode-cn.com/problems/longest-increasing-subsequence/
回溯法
131. 分割回文串 M 3.7
给定一个字符串 s,将 s 分割成一些子串,使每个子串都是回文串。返回 s 所有可能的分割方案。
例如:
输入: “aab”
输出:
[
[“aa”,“b”],
[“a”,“a”,“b”]
]
分析:
回溯法模板:
res = []
path = []
def backtrack(未探索区域, res, path):
if 未探索区域满足结束条件:
res.add(path) // 深度拷贝
return
for 选择 in 未探索区域当前可能的选择:
if 当前选择符合要求:
path.add(当前选择)
backtrack(新的未探索区域, res, path)
path.pop()
//只用了一个变量 path,所以当对 path 增加一个选择并 backtrack 之后,需要清除当前的选择,防止影响其他路径的搜索。
代码:
class Solution {
public:
vector<vector<string>> partition(string s) {
vector<vector<string>> res;
back(s,res,{}); //注意初识path为 {}
return res;
}
void back(string s,vector<vector<string>>& res,vector<string> path)
{
if(s.size()==0)
{
res.push_back(path);
return;
}
for(int i=1;i<=s.size();++i)
{
string pre = s.substr(0,i);
if(isPalindrome(pre))
{
path.push_back(pre);
back(s.substr(i),res,path);
path.pop_back();
}
}
}
bool isPalindrome(string s)
{
// if (s.size() == 0) return true;
int start = 0;int end = s.size()-1;
while(start<end)
{
if(s[start]!=s[end])
return false;
++start;
--end;
}
return true;
}
};
132. 分割回文串2 H 3.8 ※
一个字符串 s,将 s 分割成一些子串,使每个子串都是回文。
返回符合要求的 最少分割次数 。
输入:s = "aab"
输出:1
解释:只需一次分割就可将 s 分割成 ["aa","b"] 这样两个回文子串。
输入:s = "a"
输出:0
输入:s = "ab"
输出:1
分析:
https://leetcode-cn.com/problems/palindrome-partitioning-ii/solution/xiang-tong-de-si-lu-cong-zui-chang-di-ze-9kfm/
dp[i] 是以 i 结尾的分割成回文串的最少次数,那么 dp[j] 是以 j 结尾的分割成回文串的最少次数。只有子字符串 s[j + 1…i] 是回文字符串的时候,dp[i] 可以通过 dp[j] 加上一个回文字符串 s[j + 1…i] 而得到。我们遍历所有的 j ∈ [0, i - 1],dp[i] 就是所有的 s[j + 1…i] 是回文字符串的情况下, dp[j]的最小值 + 1。
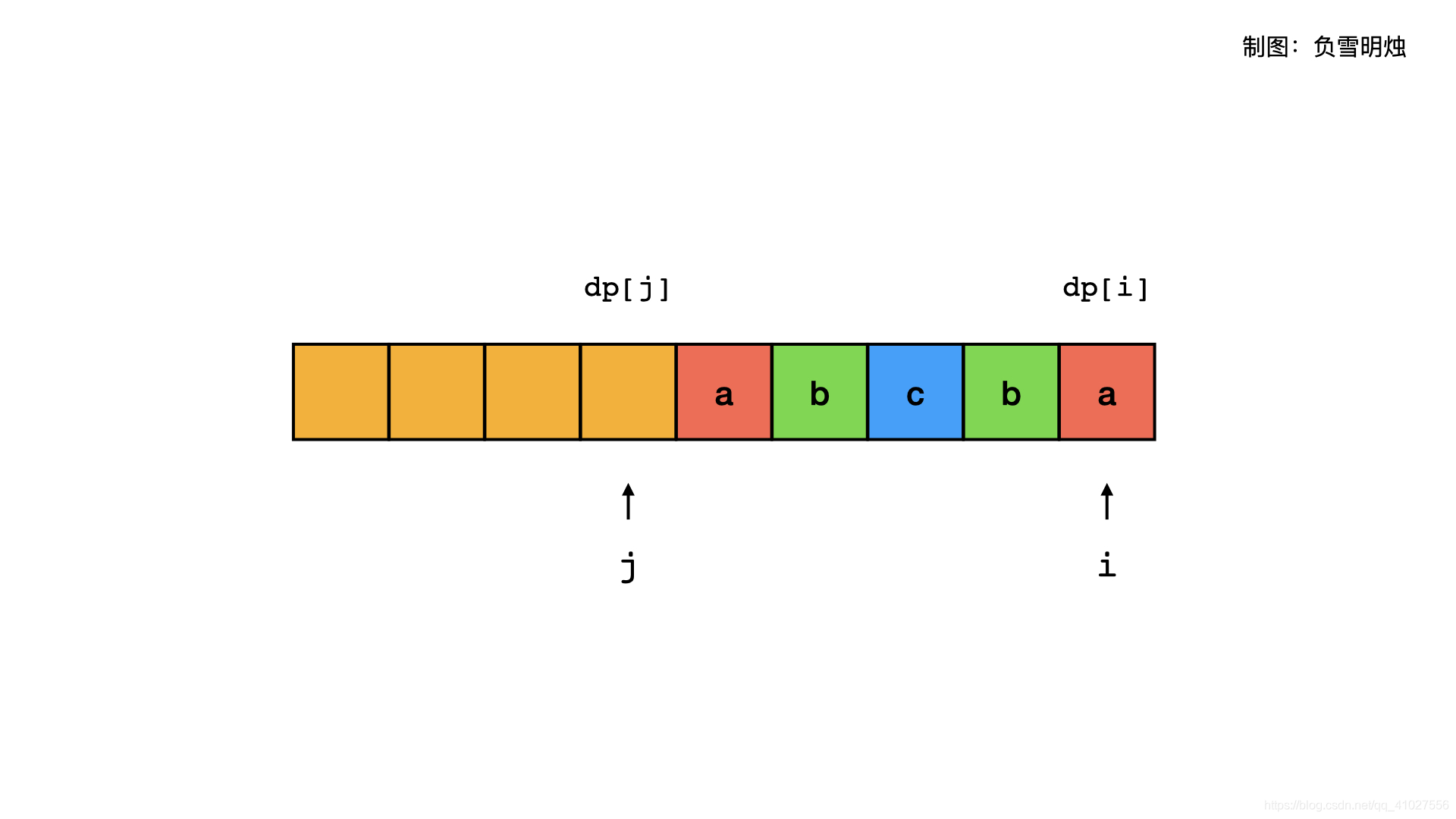
代码:
class Solution {
public:
bool isPalindrome(string str)
{
for(int i = 0 ,j = str.size()-1;i<j;++i,--j)
{
if(str[i]!=str[j])
return false;
}
return true;
}
int minCut(string s) {
int n = s.size();
vector<int>dp(n,n);
for(int i = 0;i<n;++i)
{
if(isPalindrome(s.substr(0,i+1)))
{
dp[i] = 0;
continue;
}
for(int j = 0;j<i;++j)
{
if(isPalindrome(s.substr(j+1,i-j)))
{
dp[i] = min(dp[i],dp[j]+1);
}
}
}
return dp[n-1];
}
};
90. 子集 II M 3.31
输入:nums = [1,2,2]
输出:[[],[1],[1,2],[1,2,2],[2],[2,2]]
输入:nums = [0]
输出:[[],[0]]
https://leetcode-cn.com/problems/subsets-ii/solution/hui-su-fa-mo-ban-tao-lu-jian-hua-xie-fa-y4evs/
求 nums = [1,2,2] 的子集,那么对于子集 [1,2] 是选择了第一个 2,那么就不能再选第二个 2 来构成 [1,2] 了。所以,此时的改动点,就是先排序,每个元素 nums[i] 添加到 path 之前,判断一下 nums[i] 是否等于 nums[i - 1] ,如果相等就不添加到 path 中。
class Solution {
public:
vector<vector<int>> subsetsWithDup(vector<int>& nums) {
sort(nums.begin(),nums.end());
vector<vector<int>>res;
vector<int>path;
helper(nums,res,path,0);
return res;
}
void helper(vector<int>&nums,vector<vector<int>>&res,vector<int>&path,int start)
{
// if(start > nums.size()) return;
res.push_back(path);
for(int i = start;i < nums.size();++i)
{
if(i != start&&nums[i]==nums[i-1]) continue;
path.push_back(nums[i]);
helper(nums,res,path,i+1);
path.pop_back();
}
}
};
字符串
115. 不同的子序列 H 3.17
输入:s = "rabbbit", t = "rabbit"
输出:3
解释:
如下图所示, 有 3 种可以从 s 中得到 "rabbit" 的方案。
(上箭头符号 ^ 表示选取的字母)
rabbbit
^^^^ ^^
rabbbit
^^ ^^^^
rabbbit
^^^ ^^^
输入:s = "babgbag", t = "bag"
输出:5
分析:
动态规划,(子串由右向左)分别计算每一部分的子序列数目,最后相加。


class Solution {
public:
int numDistinct(string s, string t) {
int n1 = s.length();
int n2 = t.length();
if(n1 < n2) return 0;
vector<vector<long>> res(n1+1,vector<long>(n2+1));
//n1+1行,n2+1列,初值默认为0
for(int i = 0;i < n1+1;++i)
res[i][n2] = 1;
for(int i = n1-1;i >= 0;--i)
{
char schar = s.at(i);
for(int j = n2-1;j >= 0;--j)
{
char tchar = t.at(j);
// if(s[i]==t[j])
if(schar == tchar)
{
res[i][j] = res[i+1][j+1] + res[i+1][j];
}
else
{
res[i][j] = res[i+1][j];
}
}
}
return res[0][0];
}
};
栈
设计
232.用栈实现队列 3.5 E
示例:
输入:
[“MyQueue”, “push”, “push”, “peek”, “pop”, “empty”]
[[], [1], [2], [], [], []]
输出:
[null, null, null, 1, 1, false]
解释:
MyQueue myQueue = new MyQueue();
myQueue.push(1); // queue is: [1]
myQueue.push(2); // queue is: [1, 2] (leftmost is front of the queue)
myQueue.peek(); // return 1
myQueue.pop(); // return 1, queue is [2]
myQueue.empty(); // return false
代码:
class MyQueue {
public:
/** Initialize your data structure here. */
stack<int>s1,s2;
void InToOut()
{
while(!s1.empty())
{
s2.push(s1.top());
s1.pop();
}
}
MyQueue() {
}
/** Push element x to the back of queue. */
void push(int x) {
s1.push(x);
}
/** Removes the element from in front of queue and returns that element. */
int pop() {
if(s2.empty()) //注意不要与InToOut()函数混乱,s2为空才需要插入。
{
InToOut();
}
int res = s2.top();
s2.pop();
return res;
}
/** Get the front element. */
int peek() {
if(s2.empty())
{
InToOut();
}
int res2 = s2.top();
return res2;
}
/** Returns whether the queue is empty. */
bool empty() {
if(s1.empty()&&s2.empty())
return true;
else
return false;
}
//也可以直接return s1.empty() && s2.empty();
};
/**
* Your MyQueue object will be instantiated and called as such:
* MyQueue* obj = new MyQueue();
* obj->push(x);
* int param_2 = obj->pop();
* int param_3 = obj->peek();
* bool param_4 = obj->empty();
*/
341. 扁平化嵌套列表迭代器 M 3.23
设计一个迭代器,使其能够遍历这个整型列表中的所有整数。
输入: [[1,1],2,[1,1]]
输出: [1,1,2,1,1]
解释: 通过重复调用 next 直到 hasNext 返回 false,next 返回的元素的顺序应该是: [1,1,2,1,1]。
输入: [1,[4,[6]]]
输出: [1,4,6]
解释: 通过重复调用 next 直到 hasNext 返回 false,next 返回的元素的顺序应该是: [1,4,6]。
法一:DFS
1.深度优先搜索的顺序就是迭代器遍历的顺序。递归。
2.先遍历整个嵌套列表,将所有整数存入一个数组,然后遍历该数组从而实现 next 和 hasNext 方法。
/**
* // This is the interface that allows for creating nested lists.
* // You should not implement it, or speculate about its implementation
* class NestedInteger {
* public:
* // Return true if this NestedInteger holds a single integer, rather than a nested list.
* bool isInteger() const;
*
* // Return the single integer that this NestedInteger holds, if it holds a single integer
* // The result is undefined if this NestedInteger holds a nested list
* int getInteger() const;
*
* // Return the nested list that this NestedInteger holds, if it holds a nested list
* // The result is undefined if this NestedInteger holds a single integer
* const vector<NestedInteger> &getList() const;
* };
*/
class NestedIterator {
public:
vector<int>vals;
vector<int>::iterator cur;
void dfs(const vector<NestedInteger>& nestedList)
{
for(auto &nest : nestedList)
{
if(nest.isInteger())
{
vals.push_back(nest.getInteger());
}
else
{
dfs(nest.getList());
}
}
}
NestedIterator(vector<NestedInteger> &nestedList) {
dfs(nestedList);
cur = vals.begin();
}
int next() {
return *cur++;
}
bool hasNext() {
return cur!=vals.end();
}
};
/**
* Your NestedIterator object will be instantiated and called as such:
* NestedIterator i(nestedList);
* while (i.hasNext()) cout << i.next();
*/
法二:栈
调用 hasNext() 或者 next() 方法的时候扁平化当前的嵌套的子列表。
在递归方法中,我们在遍历时如果遇到一个嵌套的 子list,就立即处理该 子list,直到全部展开;
在迭代方法中,我们不需要全部展开,只需要把 当前list 的所有元素放入 list 中。(作者:@fuxuemingzhu)
/**
* // This is the interface that allows for creating nested lists.
* // You should not implement it, or speculate about its implementation
* class NestedInteger {
* public:
* // Return true if this NestedInteger holds a single integer, rather than a nested list.
* bool isInteger() const;
*
* // Return the single integer that this NestedInteger holds, if it holds a single integer
* // The result is undefined if this NestedInteger holds a nested list
* int getInteger() const;
*
* // Return the nested list that this NestedInteger holds, if it holds a nested list
* // The result is undefined if this NestedInteger holds a single integer
* const vector<NestedInteger> &getList() const;
* };
*/
class NestedIterator {
private:
stack<NestedInteger>st;
public:
NestedIterator(vector<NestedInteger> &nestedList) {
for(int i = nestedList.size()-1;i >= 0;--i)
{
st.push(nestedList[i]);
}
}
int next() {
NestedInteger cur = st.top();st.pop();
return cur.getInteger();
}
bool hasNext() {
while(!st.empty())
{
NestedInteger cur = st.top();
if(cur.isInteger())
return true;
st.pop();
for(int i = cur.getList().size()-1;i >= 0;--i)
{
st.push(cur.getList()[i]);
}
}
return false;
}
};
/**
* Your NestedIterator object will be instantiated and called as such:
* NestedIterator i(nestedList);
* while (i.hasNext()) cout << i.next();
*/
为什么在 hasNext() 方法中摊平 list,而不是在 next() 方法中。
比如对于 [[]] 的输入, hasNext() 方法是判断其中是否有 int 元素了,则必须把内层的 list 摊平来看,发现是空的,返回 false。
456. 132 模式 M 3.24
输入:nums = [1,2,3,4]
输出:false
解释:序列中不存在 132 模式的子序列
输入:nums = [3,1,4,2]
输出:true
解释:序列中有 1 个 132 模式的子序列: [1, 4, 2]
法一:暴力解法 [时间复杂度为 O(n^2),空间复杂度O(1)]
class Solution {
public:
bool find132pattern(vector<int>& nums) {
int num = nums[0];
for(int i = 1;i < nums.size();++i)
{
for(int j = nums.size()-1;j > i;--j)
{
if(num < nums[j] && nums[j] < nums[i])
{
return true;
}
}
num = min(num,nums[i]);
}
return false;
}
};
法二:单调栈(时间/空间复杂度O(n))
如果维护的是 【132 模式】中的 3,那么就希望 1 尽可能小,2 尽可能大。
https://leetcode-cn.com/problems/132-pattern/solution/fu-xue-ming-zhu-cong-bao-li-qiu-jie-dao-eg78f/
1.求任何位置的左边最小的元素 nums[i] ,可以提前遍历一次而得到;【用数组保存i值的左边最小值】
2.使用「单调递减栈」,把 nums[j] 入栈时,需要把栈里面比它小的元素全都 pop 出来,由于越往栈底越大,所以 pop 出的最后一个元素,就是比 3 小 的 最大 元素 nums[k] 。
3.判断如果 nums[i] < nums[k] ,那就说明得到了一个 132 模式。
class Solution {
public:
bool find132pattern(vector<int>& nums) {
if(nums.size() < 3) return false;
vector<int> leftMin(nums.size(),INT_MAX);
for(int i = 1;i < nums.size();++i)
{
leftMin[i] = min(leftMin[i-1],nums[i-1]);
}
stack<int>st;
for(int j = nums.size()-1;j >= 0;--j)
{
int numk = 0;
while(!st.empty()&&st.top()<nums[j])
{
numk = st.top();
st.pop();
if(numk > leftMin[j]) return true;
}
st.push(nums[j]);
}
return false;
}
};
循环数组
503. 下一个更大元素 II M 3.6
输入: [1,2,1]
输出: [2,-1,2]
解释: 第一个 1 的下一个更大的数是 2;
数字 2 找不到下一个更大的数;
第二个 1 的下一个最大的数需要循环搜索,结果也是 2。
** 分析:**
https://leetcode-cn.com/problems/next-greater-element-ii/solution/dong-hua-jiang-jie-dan-diao-zhan-by-fuxu-4z2g/
遍历一次数组,如果元素是单调递减的(则他们的「下一个更大元素」相同),我们就把这些元素保存,直到找到一个较大的元素;把该较大元素逐一跟保存了的元素比较,如果该元素更大,那么它就是前面元素的「下一个更大元素」。
故应使用单调栈来实现。
代码:
class Solution {
public:
vector<int> nextGreaterElements(vector<int>& nums) {
stack<int>st;
vector<int>res(nums.size(),-1); //注意括号[初始化]内容
if(nums.empty()) return res;
for(int i = 0;i<nums.size()*2;i++) //循环数组,遍历长度为2倍
{
while(!st.empty()&&nums[i % nums.size()]>nums[st.top()]) //循环数组,类似循环队列 天勤P64
{
res[st.top()] = nums[i % nums.size()];
st.pop();
}
st.push(i % nums.size());
}
return res;
}
};
删除重复字符
1047. 删除字符串中的所有相邻重复项 E 3.9
给出由小写字母组成的字符串 S,重复项删除操作会选择两个相邻且相同的字母,并删除它们。
输入:“abbaca”
输出:“ca”
解释:
例如,在 “abbaca” 中,我们可以删除 “bb” 由于两字母相邻且相同,这是此时唯一可以执行删除操作的重复项。之后我们得到字符串 “aaca”,其中又只有 “aa” 可以执行重复项删除操作,所以最后的字符串为 “ca”。
代码:
class Solution {
public:
string removeDuplicates(string S) {
string res;
for(char c : S)
{
if(!res.empty()&& c == res.back())
{
res.pop_back();
}
else
{
res.push_back(c);
}
}
return res;
}
};
注:
string类也可使用pop_back和push_back。
计算器
224. 基本计算器 H 3.10
实现一个基本的计算器来计算一个简单的字符串表达式 s 的值。
输入:s = "1 + 1"
输出:2
输入:s = "(1+(4+5+2)-3)+(6+8)"
输出:23
https://leetcode-cn.com/problems/basic-calculator/solution/ru-he-xiang-dao-yong-zhan-si-lu-lai-zi-y-gpca/
if 当前是数字,更新计算当前 数字;
if 当前是+||-,更新计算当前计算的 结果 res,并把当前数字 num 设为 0,sign 设为正负,重新开始;
if 当前是 ( ,说明遇到了右边的表达式,而后面的小括号里的内容需要优先计算,所以要把 res,sign 进栈,更新 res 和 sign 为新的开始;
if 当前是 ) ,那么说明右边的表达式结束,即当前括号里的内容已经计算完毕,所以要把之前的结果 出栈,然后计算整个式子的结果;
最后,当所有数字结束的时候,需要把 最后 的一个 num 也更新到 res 中。
class Solution {
public:
int calculate(string s) {
long int res = 0,num = 0;
int sign = 1;
stack<int>st;
for(char c : s)
{
if(c >= '0' && c <= '9')
//也可以 isdigit(c) 判断
{
//num = 10*num + (int)c;
//这里如果强转是把字符转成对应的ascii码,比如字符1就转成了48。
num = 10*num + c - '0';
}
else if(c=='+'||c=='-')
{
res = res + sign*num;
num = 0;
if(c=='+')
{
sign = 1;
}
else
{
sign = -1;
}
}
else if(c == '(')
{
st.push(res);
st.push(sign);
res = 0;
sign = 1;
}
else if(c == ')')
{
res = res + sign*num;
num = 0;
res = res * st.top();
st.pop();
res = res + st.top();
st.pop();
}
// else if(c == ' ') //char c : s 不满足条件执行,则继续遍历,可不用判此断
// {
// continue;
// }
}
res = res + sign*num;
return res;
}
};
stack容器常用函数:http://c.biancheng.net/view/6971.html
227. 基本计算器 II 3.11
给你一个字符串表达式 s ,请你实现一个基本计算器来计算并返回它的值。整数除法仅保留整数部分。
示例 1:
输入:s = "3+2*2"
输出:7
示例 2:
输入:s = " 3/2 "
输出:1
代码:
class Solution {
public:
int calculate(string s) {
if(s.empty()) return 0;
vector<int> st;
char presign = '+';
long int num = 0;
int n = s.length();
for(int i = 0;i<n;++i)
{
if(isdigit(s[i]))
{
num = 10*num + s[i] -'0';
}
if(!isdigit(s[i]) && s[i]!=' '|| i == n-1) //i == n-1不能忽略,否则最后一个num未入账,最后求和会遗失。
{
switch(presign)
{
case '+':
st.push_back(num);
break;
case '-':
st.push_back(-num);
break;
case '*':
st.back() *= num;
break;
default:
st.back() /= num;
}
presign = s[i]; //这两句注意放置位置于条件执行完之内
num = 0;
}
}
return accumulate(st.begin(),st.end(),0);
}
};
150. 逆波兰表达式求值 M 3.20
逆波兰表达式【后缀表达式】
输入:tokens = ["2","1","+","3","*"]
输出:9
解释:该算式转化为常见的中缀算术表达式为:((2 + 1) * 3) = 9
class Solution {
public:
int evalRPN(vector<string>& tokens) {
stack<int>s1;
int n1,n2,tmp;
for(int i = 0;i < tokens.size();++i)
{
string& s = tokens[i]; //可选使用引用
if((s != "+")&&(s != "-")&&(s != "*")&&(s != "/"))
//可定义函数
//if(isNum(s))
{
s1.push(atoi(s.c_str()));
}
else
{
n1 = s1.top();
s1.pop();
n2 = s1.top();
s1.pop();
tmp = 0;
// switch(atoi(s.c_str())) 错误
switch(s[0])
{
case '+':
tmp = n2+n1; break;
case '-':
tmp = n2-n1; break;
case '*':
tmp = n2*n1; break;
case '/':
tmp = n2/n1; break;
}
s1.push(tmp);
}
}
return s1.top();
}
// bool isNumber(string& token) {
// return !(token == "+" || token == "-" || token == "*" || token == "/");
// }
};
注:
atoi(s.c_str()):
- const char *c_str(); c_str()函数返回一个指向正规C字符串的指针常量, 内容与本string串相同。
const _Elem *c_str() const
{ // return pointer to null-terminated nonmutable array
return (_Myptr());
}
- C库函数 int atoi(const char *str) 把参数 str 所指向的字符串转换为一个整数(类型为 int型)。
二叉树
331. 验证二叉树的前序序列化 M 3.11
给定一串以逗号分隔的序列,验证它是否是正确的二叉树的前序序列化。
示例 1:
输入: "9,3,4,#,#,1,#,#,2,#,6,#,#"
输出: true
示例 2:
输入: "1,#"
输出: false
示例 3:
输入: "9,#,#,1"
输出: false
思路:
https://leetcode-cn.com/problems/verify-preorder-serialization-of-a-binary-tree/solution/pai-an-jiao-jue-de-liang-chong-jie-fa-zh-66nt/
结合栈和前序遍历特点:
如输入: “9,3,4,#,#,1,#,#,2,#,6,#,#” ,当遇到 x # # 的时候,就把它变为 #。
9,3,4,#,# => 9,3,#,继续
9,3,#,1,#,# => 9,3,#,# => 9,# ,继续
9,#2,#,6,#,# => 9,#,2,#,# => 9,#,# => #,结束
class Solution {
public:
bool isValidSerialization(string preorder) {
int n = preorder.length();
if(n == 0) return false;
vector<char>stk;
for(int i = 0;i<n;++i)
{
if(preorder[i]==',')
continue;
stk.push_back(preorder[i]);
while(stk.size()>=3 && stk[stk.size()-1] == '#' && stk[stk.size()-2] == '#' && stk[stk.size()-3] != '#')
{
stk.pop_back();
stk.pop_back();
stk.pop_back();
stk.push_back('#');
}
}
return stk.size()==1 && stk[0]=='#';
}
};
"9,#,92,#,#" 需要考虑非0-9数
预期 True
输出 False
正确:
class Solution {
public:
bool isValidSerialization(string preorder) {
int n = preorder.length();
// 或 int n = preorder.size();
if(n == 0) return false;
vector<string>stk;
int i = 0;
// for(int i = 0;i<n;++i)
while(i < n)
{
if(preorder[i]==',')
{
++i;
continue;
}
if(preorder[i] != '#')
{
string num;
// while(preorder[i] != ',') 不加另外两个约束条件则错误。
while(i < preorder.size() && preorder[i] != '#' && preorder[i] != ',')
{
num += preorder[i++];
}
stk.push_back(num);
}
else
{
stk.push_back("#");
++i;
}
// while(stk.size()>=3 && stk[stk.size()-1] == '#' && stk[stk.size()-2] == '#' && stk[stk.size()-3] != '#') 应使用 "" ---> 字符串!
while(stk.size()>=3 && stk[stk.size()-1] == "#" && stk[stk.size()-2] == "#" && stk[stk.size()-3] != "#")
// 也可以 while(stk.size() >= 3 && stk.back() == "#" && *(stk.rbegin()+1) == "#" && *(stk.rbegin()+2) == "#")
{
stk.pop_back();
stk.pop_back();
stk.pop_back();
stk.push_back("#");
}
}
return stk.size()==1 && stk[0]== "#";
//也可以 return stk.size()==1 && *stk.begin() == "#";
}
};
思路2:出入度计算
加入一个非空节点时,都会先减去一个入度,再加上两个出度。但是由于根节点没有父节点,所以其入度为 0,出度为 2。
因此 diff 初始化为 1,是为了在加入根节点的时候,先减去一个入度,再加上两个出度,此时 diff 正好应该是2。
class Solution {
public:
bool isValidSerialization(string preorder) {
int n = preorder.length();
int i = 0;
int slots = 1; //slots = 出度 - 入度
while (i < n)
{
if (slots == 0)
{
return false;
}
if (preorder[i] == ',')
{
i++;
}
else if (preorder[i] == '#')
{
slots--;
i++;
}
else
{
// 读一个数字
while (i < n && preorder[i] != ',')
{
i++;
}
slots++; // slots = slots - 1 + 2 头结点初试为1,+1恰对应两出度。
}
}
return slots == 0;
}
};
173. 二叉搜索树迭代器 M 3.28
实现一个二叉搜索树迭代器类BSTIterator ,表示一个按中序遍历二叉搜索树(BST)的迭代器:
输入
["BSTIterator", "next", "next", "hasNext", "next", "hasNext", "next", "hasNext", "next", "hasNext"]
[[[7, 3, 15, null, null, 9, 20]], [], [], [], [], [], [], [], [], []]
输出
[null, 3, 7, true, 9, true, 15, true, 20, false]
解释
BSTIterator bSTIterator = new BSTIterator([7, 3, 15, null, null, 9, 20]);
bSTIterator.next(); // 返回 3
bSTIterator.next(); // 返回 7
bSTIterator.hasNext(); // 返回 True
bSTIterator.next(); // 返回 9
bSTIterator.hasNext(); // 返回 True
bSTIterator.next(); // 返回 15
bSTIterator.hasNext(); // 返回 True
bSTIterator.next(); // 返回 20
bSTIterator.hasNext(); // 返回 False
辅助栈迭代:(O(n),O(n))
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class BSTIterator {
public:
TreeNode* p;
stack<TreeNode*>st;
BSTIterator(TreeNode* root):p(root) {
}
int next() {
while(p)
{
st.push(p);
p = p->left;
}
p = st.top();
st.pop();
int res = p->val;
p = p->right;
return res;
}
bool hasNext() {
return p||!st.empty();
}
};
/**
* Your BSTIterator object will be instantiated and called as such:
* BSTIterator* obj = new BSTIterator(root);
* int param_1 = obj->next();
* bool param_2 = obj->hasNext();
*/
法二:扁平化
直接对二叉搜索树做一次完全的递归遍历,获取中序遍历的全部结果并保存在数组中。随后,我们利用得到的数组本身来实现迭代器。
class BSTIterator {
private:
void inorder(TreeNode* root, vector<int>& res) {
if (!root) {
return;
}
inorder(root->left, res);
res.push_back(root->val);
inorder(root->right, res);
}
vector<int> inorderTraversal(TreeNode* root) {
vector<int> res;
inorder(root, res);
return res;
}
vector<int> arr;
int idx;
public:
BSTIterator(TreeNode* root): idx(0), arr(inorderTraversal(root)) {}
int next() {
return arr[idx++];
}
bool hasNext() {
return (idx < arr.size());
}
};
数组
矩阵
54. 螺旋矩阵 M 3.15
给你一个 m 行 n 列的矩阵 matrix ,请按照 顺时针螺旋顺序 ,返回矩阵中的所有元素。
https://leetcode-cn.com/problems/spiral-matrix/solution/cxiang-xi-ti-jie-by-youlookdeliciousc-3/
- 首先设定上下左右边界 其次向右移动到最右,此时第一行因为已经使用过了,可以将其从图中删去,体现在代码中就是重新定义上边界
- 判断若重新定义后,上下边界交错,表明螺旋矩阵遍历结束,跳出循环,返回答案
- 若上下边界不交错,则遍历还未结束,接着向下向左向上移动,操作过程与第一,二步同理
- 不断循环以上步骤,直到某两条边界交错,跳出循环,返回答案
class Solution {
public:
vector<int> spiralOrder(vector<vector<int>>& matrix) {
int m = matrix.size();
int n = matrix[0].size();
int left = 0,right = n - 1,up = 0,down = m - 1;
vector<int>res;
if(matrix.empty()) return res;
while(1)
{
for(int i = left;i<=right;++i) //记得加=
{
res.push_back(matrix[up][i]);
}
if(++up > down) break;
for(int i = up;i <= down;++i)
{
res.push_back(matrix[i][right]);
}
if(--right < left) break;
for(int i = right;i >= left;--i)
{
res.push_back(matrix[down][i]);
}
if(--down < up) break;
for(int i = down;i >= up;--i)
{
res.push_back(matrix[i][left]);
}
if(++left > right) break;
}
return res;
}
};
59. 螺旋矩阵 II M 3.16
给一个正整数 n ,生成一个包含 1 到 n2 所有元素,且元素按顺时针顺序螺旋排列的 n x n 正方形矩阵 matrix 。
输入:n = 3
输出:[[1,2,3],[8,9,4],[7,6,5]]
输入:n = 1
输出:[[1]]
class Solution {
public:
vector<vector<int>> generateMatrix(int n) {
vector<vector<int>> res(n, vector<int>(n));
//例如:vector< vector<int> > b(10, vector<int>(5));
//创建一个10*5的int型二维向量
//括号内的内容如果不写是错误的(直接赋值了,没有使用push_back等)
int left = 0;
int right = n-1;
int up = 0;
int down = n-1;
int num = 0;
while(1)
{
for(int i = left;i <= right;++i)
{
res[up][i] = ++num;
}
if(++up > down) break;
for(int i = up;i <= down;++i)
{
res[i][right] = ++num;
}
if(--right < left) break;
for(int i = right;i >= left;--i)
{
res[down][i] = ++num;
}
if(--down < up) break;
for(int i = down;i >= up;--i)
{
res[i][left] = ++num;
}
if(++left > right) break;
}
return res;
}
};
73. 矩阵置零 M 3.21
给定一个 m x n 的矩阵,如果一个元素为 0 ,则将其所在行和列的所有元素都设为 0 。请使用 原地 算法。
输入:matrix = [[1,1,1],[1,0,1],[1,1,1]]
输出:[[1,0,1],[0,0,0],[1,0,1]]
输入:matrix = [[0,1,2,0],[3,4,5,2],[1,3,1,5]]
输出:[[0,0,0,0],[0,4,5,0],[0,3,1,0]]
法一:复制矩阵(空间复杂度O(MN))
class Solution {
public:
void setZeroes(vector<vector<int>>& matrix) {
if(matrix.size()==0) return;
int m = matrix.size();
int n = matrix[0].size();
vector<vector<int>>tmp(matrix);
for(int i = 0;i < m;++i)
{
for(int j = 0;j < n;++j)
{
if(tmp[i][j] == 0)
{
for(int t = 0;t < m;++t)
{
matrix[t][j] = 0;
}
for(int u = 0;u < n;++u)
{
matrix[i][u] = 0;
}
}
}
}
}
};
或者使用queue<pair<int, int>> q;记录数组中0出现的位置,最后auto p = q.front(); q.pop();以及matrix[p.first][j] = 0;、matrix[i][p.second] = 0;也可以。
法二:使用标记数组,空间复杂度O(M+N)
class Solution {
public:
void setZeroes(vector<vector<int>>& matrix) {
int m = matrix.size();
int n = matrix[0].size();
vector<int> row(m), col(n);
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
if (!matrix[i][j]) {
row[i] = col[j] = true;
}
}
}
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
if (row[i] || col[j]) {
matrix[i][j] = 0;
}
}
}
}
};
74. 搜索二维矩阵 M 3.30
编写一个高效的算法来判断 m x n 矩阵中,是否存在一个目标值。该矩阵具有如下特性:
每行中的整数从左到右按升序排列。
每行的第一个整数大于前一行的最后一个整数。
输入:matrix = [[1,3,5,7],[10,11,16,20],[23,30,34,60]], target = 3
输出:true
输入:matrix = [[1,3,5,7],[10,11,16,20],[23,30,34,60]], target = 13
输出:false
法一:遍历
时间复杂度: O(M * N)
空间复杂度:O(1)
class Solution {
public:
bool searchMatrix(vector<vector<int>>& matrix, int target) {
if(matrix.size() == 0 || matrix[0].size() == 0) return false;
int m = matrix.size(),n = matrix[0].size();
for(int i = 0;i < m*n;++i)
{
if(matrix[i/n][i%n]==target)
return true;
}
return false;
}
};
法二:先寻找到所在行
class Solution {
public:
bool searchMatrix(vector<vector<int>>& matrix, int target) {
if (matrix.size() == 0 || matrix[0].size() == 0) return false;
const int M = matrix.size(), N = matrix[0].size();
for (int i = 0; i < M; ++i) {
if (target > matrix[i][N - 1])
continue;
auto it = find(matrix[i].begin(), matrix[i].end(), target);
return it != matrix[i].end();
}
return false;
}
};
设计
1603. 设计停车系统 E 3.19
输入:
["ParkingSystem", "addCar", "addCar", "addCar", "addCar"]
[[1, 1, 0], [1], [2], [3], [1]]
输出:
[null, true, true, false, false]
解释:
ParkingSystem parkingSystem = new ParkingSystem(1, 1, 0);
parkingSystem.addCar(1); // 返回 true ,因为有 1 个空的大车位
parkingSystem.addCar(2); // 返回 true ,因为有 1 个空的中车位
parkingSystem.addCar(3); // 返回 false ,因为没有空的小车位
parkingSystem.addCar(1); // 返回 false ,因为没有空的大车位,唯一一个大车位已经被占据了
代码:
class ParkingSystem {
public:
int sys[3];
ParkingSystem(int big, int medium, int small) {
sys[0] = big;
sys[1] = medium;
sys[2] = small;
}
bool addCar(int carType) {
if(carType < 1 || carType >3)
return false;
else if(sys[carType-1] <= 0)
return false;
else
{
--sys[carType-1];
return true;
}
}
};
/**
* Your ParkingSystem object will be instantiated and called as such:
* ParkingSystem* obj = new ParkingSystem(big, medium, small);
* bool param_1 = obj->addCar(carType);
*/
链表
逆置
92. 反转链表 II M 3.18
输入:head = [1,2,3,4,5], left = 2, right = 4
输出:[1,4,3,2,5]
输入:head = [5], left = 1, right = 1
输出:[5]
分析:
头插法:一次遍历【穿针引线】
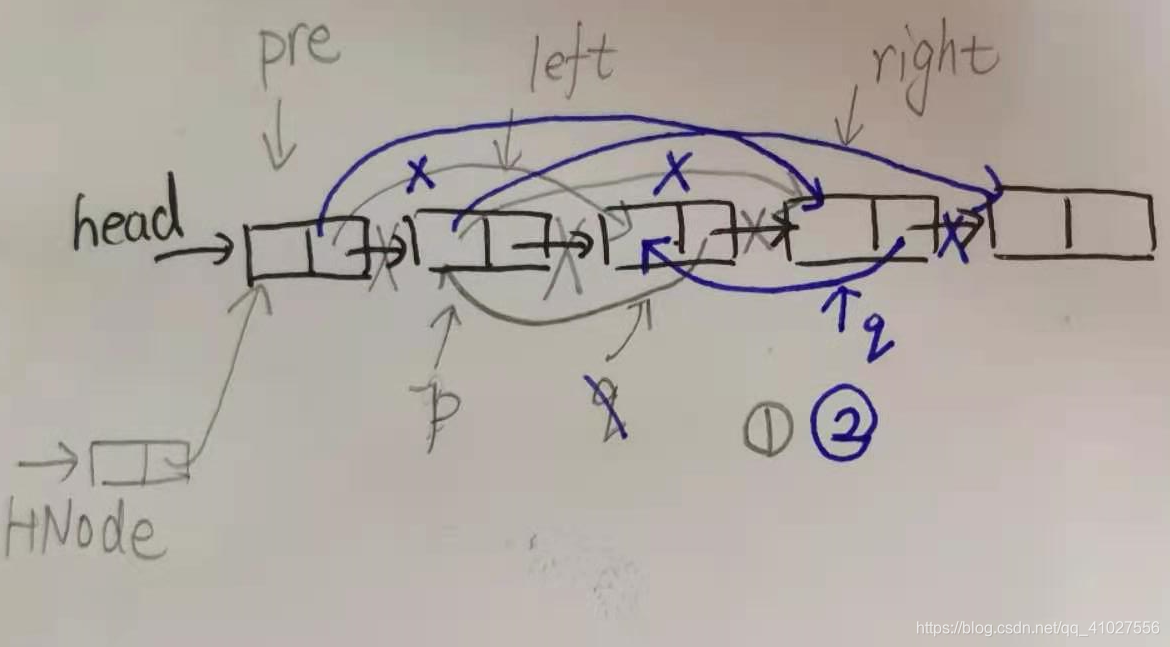
代码:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* reverseBetween(ListNode* head, int left, int right) {
ListNode *HNode = new ListNode();
//()内不写值,默认val为0。
HNode->next = head;
ListNode *pre = HNode;
for(int i = 0;i < left-1;++i)
{
pre = pre->next;
}
ListNode *p = pre->next;
ListNode *q;
for(int i = 0;i < right-left;++i)
{
q = p->next;
p->next = q->next;
q->next = pre->next;
pre->next = q;
}
return HNode->next;
}
};
删除
82. 删除排序链表中的重复元素 II M 3.25
输入:head = [1,2,3,3,4,4,5]
输出:[1,2,5]
输入:head = [1,1,1,2,3]
输出:[2,3]
法一:递归
https://leetcode-cn.com/problems/remove-duplicates-from-sorted-list-ii/solution/fu-xue-ming-zhu-di-gui-die-dai-yi-pian-t-wy0h/
1.如果 head || head->next 为空,那么肯定没有值出现重复的节点,直接返回 head;
2.如果 head.val != head.next.val ,说明头节点的值不等于下一个节点的值,所以当前的 head 节点必须保留;但是 head.next 节点要不要保留呢?我们还不知道,需要对 head.next 进行递归,即对 head.next 作为头节点的链表,去除值重复的节点。所以 head.next = self.deleteDuplicates(head.next).
如果 head.val == head.next.val ,说明头节点的值等于下一个节点的值,所以当前的 head 节点必须删除;但是 head.next 节点要不要删除呢?我们还不知道,需要一直向后遍历寻找到与 head.val 不等的节点。与 head.val 相等的这一段链表都要删除,因此返回 deleteDuplicates(move);
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* deleteDuplicates(ListNode* head) {
if(head==NULL||head->next==NULL) return head;
if(head->val != head->next->val)
{
head->next = deleteDuplicates(head->next);
}
else
{
ListNode* move = head->next;
while(move && head->val == move->val)
{
move = move->next;
}
return deleteDuplicates(move);
}
return head;
}
};
法二:迭代
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* deleteDuplicates(ListNode* head) {
if(!head||!head->next) return head;
ListNode* NewHead = new ListNode();
NewHead->next = head;
ListNode* pre = NewHead;
ListNode* q = head;
while(q)
{
while(q->next&&q->val == q->next->val)
{
q = q->next;
}
if(pre->next == q)
{
pre = pre->next;
}
else
{
pre->next = q->next;
}
q = q->next;
}
return NewHead->next;
}
};
83. 删除排序链表中的重复元素 E 3.26
输入:head = [1,1,2]
输出:[1,2]
输入:head = [1,1,2,3,3]
输出:[1,2,3]
方法同上。
迭代法:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* deleteDuplicates(ListNode* head) {
if(!head || !head->next) return head;
ListNode* NewHead = new ListNode();
NewHead->next = head;
ListNode* pre = NewHead;
ListNode* q = head;
while(q)
{
while(q->next&&q->val == q->next->val)
{
q = q->next;
}
if(pre->next == q)
{
pre = pre->next;
}
else
{
pre->next = q;
pre = pre->next;
}
q = q->next;
}
return NewHead->next;
}
};
递归:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* deleteDuplicates(ListNode* head) {
if(!head||!head->next) return head;
if(head->val != head->next->val)
{
head->next = deleteDuplicates(head->next);
}
else
{
ListNode* move = head;
while(move->next&&head->val == move->next->val)
{
move = move->next;
}
return deleteDuplicates(move);
}
return head;
}
};
旋转
61. 旋转链表 M 3.27
输入:head = [1,2,3,4,5], k = 2
输出:[4,5,1,2,3]
输入:head = [0,1,2], k = 4
输出:[2,0,1]
闭合城环
取倒数第k个节点为头结点,倒数第k+1个节点的next为空。
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* rotateRight(ListNode* head, int k) {
if(!head||!head->next||k==0) return head;
ListNode *newhead = head;
ListNode *p = head;
ListNode *hnext = head;
int size = 1;
while(p->next)
{
++size;
p = p->next;
}
p->next = head;
for(int i = 0;i < size - k%size;++i) //如果从左向右数,无法得出合适结果。
{
newhead = newhead->next;
}
ListNode *q = newhead;
for(int j = 1;j < size;++j)
{
q = q->next;
}
q->next = NULL;
return newhead;
}
};
位运算
比特位计数 3.3 E
给定一个非负整数 num。对于 0 ≤ i ≤ num 范围中的每个数字 i ,计算其二进制数中的 1 的数目并将它们作为数组返回。
例如:
输入: 2
输出: [0,1,1]
分析: x &= (x-1)
对于任意的x,转换成二进制后,是形如这样的数字:
aa…aa10…00,
从右向左数有任意多个0,直到遇见第一个1,字母a用来占位,代表1左边的任意数字。
x-1转换成二进制后,是形如这样的数字:
aa…aa01…11,
从右向左数,原来的任意多个0都变成1,原来的第一个1,变成0,字母a部分不变。
对x 和 x-1 进行 按位与 计算,会得到:aa…aa00…00,从右向左数,原来的第一个1变成了0,字母a部分不变。 所以 x
& (x-1)相当于消除了 x 从右向左数遇到的第一个1。
x转换成二进制后包含多少个1,func函数里的循环就会进行多少次,直到x所有的1都被“消除”。
代码:
直接计算法:
class Solution {
public:
int CountOnes(int x)
{
int ones = 0;
while(x)
{
x &= (x-1);
ones++;
}
return ones;
}
vector<int> countBits(int num) {
vector<int> sums(num+1);
for(int i=0;i<=num;i++)
{
sums[i] = CountOnes(i);
}
return sums;
}
};
动态规划法:
十进制 二进制
0 0
1 1
————————————
2 10
3 11
————————————
4 100
5 101
6 110
7 111
n>=2开始 在其二进制数之后加上0,就得到2n的二进制数;加上1,就得到2n+1的二进制数。
class Solution {
public:
vector<int> countBits(int num) {
vector<int> res;
res.push_back(0);
if(num==0) return res;
res.push_back(1);
if(num==1) return res;
res.push_back(1);
if(num==2) return res;
// res.push_back(2);
// if(num==3) return res;
int n = 3;
while(n <= num)
{
if(n%2==0) res.push_back(res[n/2]);
else res.push_back(res[n/2]+1);
n++;
}
return res;
}
};
合并后改进得到
class Solution {
public:
vector<int> countBits(int num) {
vector<int>res(num+1);
for(int i = 1;i<=num;i++)
{
res[i] = res[i&(i-1)] + 1;
}
return res;
}
};
191. 位1的个数 E 3.22
编写一个函数,输入是一个无符号整数(以二进制串的形式),返回其二进制表达式中数字位数为 ‘1’ 的个数(也被称为汉明重量)。
例如:
输入:00000000000000000000000000001011
输出:3
解释:输入的二进制串 00000000000000000000000000001011 中,共有三位为 '1'。
输入:11111111111111111111111111111101
输出:31
解释:输入的二进制串 11111111111111111111111111111101 中,共有 31 位为 '1'。
代码:
class Solution {
public:
int hammingWeight(uint32_t n) {
int num = 0;
while(n)
{
n &= (n-1);
++num;
}
return num;
}
};
法二:循环检查二进制位
检查第 i 位时,可以让 n 与 2^i 进行与运算,当且仅当 n 的第 i 位为 1 时,运算结果不为 0。
class Solution {
public:
int hammingWeight(uint32_t n) {
int ret = 0;
for (int i = 0; i < 32; i++) {
if (n & (1 << i)) {
ret++;
}
}
return ret;
}
};
# bit操作
& 符号,x & y ,会将两个十进制数在二进制下进行与运算
| 符号,x | y ,会将两个十进制数在二进制下进行或运算
^ 符号,x ^ y ,会将两个十进制数在二进制下进行异或运算
<< 符号,x << y 左移操作,最右边用 0 填充
>> 符号,x >> y 右移操作,最左边用 0 填充
~ 符号,~x ,按位取反操作,将 x 在二进制下的每一位取反
# 整数集合set位运算
# 整数集合做标志时,比如回溯时的visited标志数组
vstd 访问 i :vstd | (1 << i)
vstd 离开 i :vstd & ~(1 << i)
vstd 不包含 i : not vstd & (1 << i)
并集 :A | B
交集 :A & B
全集 :(1 << n) - 1
补集 :((1 << n) - 1) ^ A
子集 :(A & B) == B
判断是否是 2 的幂 :A & (A - 1) == 0
最低位的 1 变为 0 :n &= (n - 1)
最低位的 1:A & (-A),最低位的 1 一般记为 lowbit(A)
190. 颠倒二进制位 E 3.29
输入: 00000010100101000001111010011100
输出: 00111001011110000010100101000000
解释: 输入的二进制串 00000010100101000001111010011100 表示无符号整数 43261596,
因此返回 964176192,其二进制表示形式为 00111001011110000010100101000000。
输入:11111111111111111111111111111101
输出:10111111111111111111111111111111
解释:输入的二进制串 11111111111111111111111111111101 表示无符号整数 4294967293,
因此返回 3221225471 其二进制表示形式为 10111111111111111111111111111111 。
逐位颠倒:(O(1),O(1))
class Solution {
public:
uint32_t reverseBits(uint32_t n) {
uint32_t res = 0;
int i = 32;
while(i)
{
res <<= 1;
res += n&1; //得末位
n >>= 1;
--i;
}
return res;
}
};
分治法:
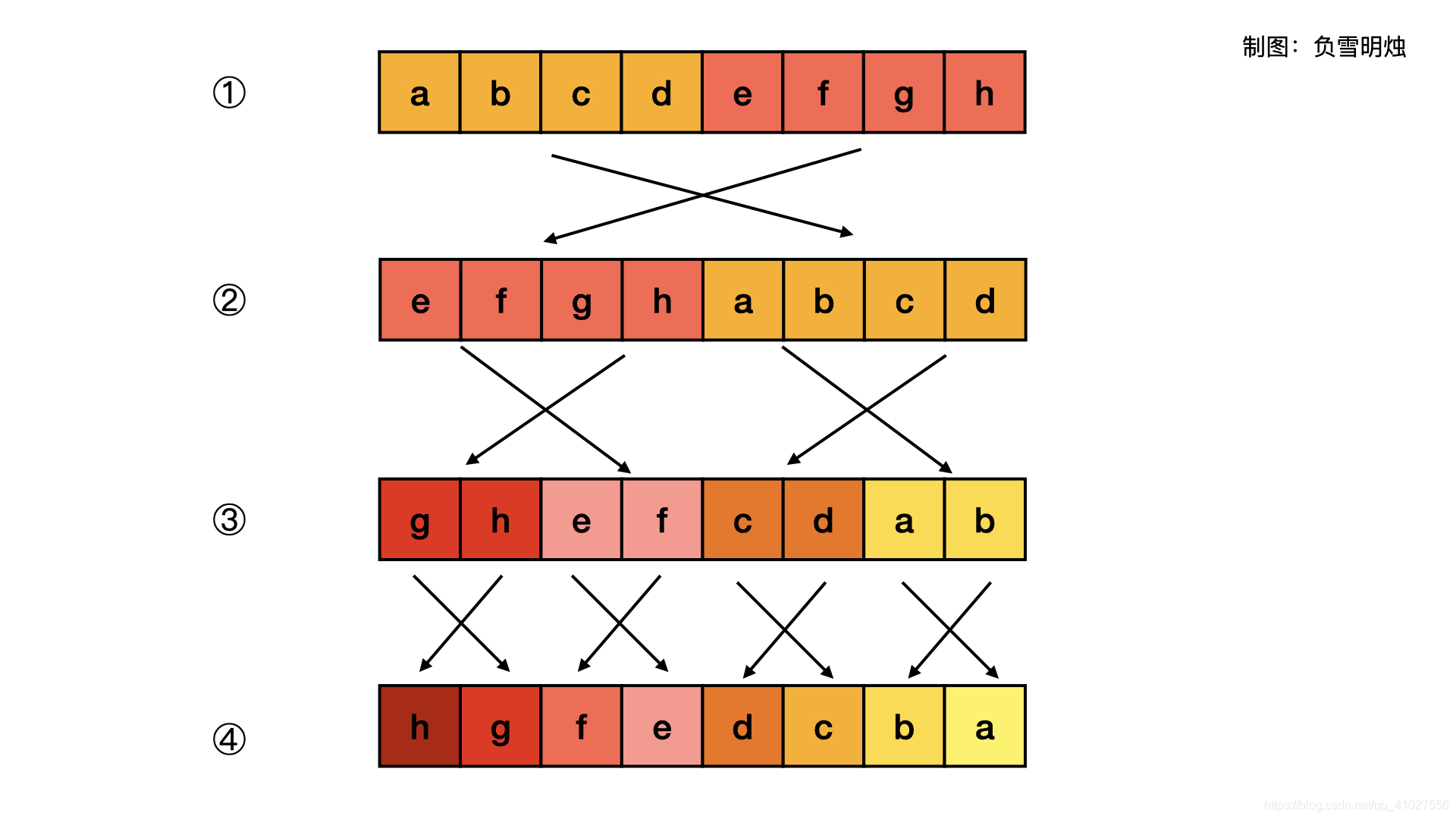
32位无符号整数,如 1111 1111 1111 1111 1111 1111 1111 1111
表示成16进制 f f f f f f f f
一个16进制的f代表二进制的4位
ffff ffff右移16位,变成 0000 ffff
ffff ffff左移16位,变成 ffff 0000
它们俩相或,就可以完成低16位与高16位的交换
之后的每次分治,都要先与上一个掩码,再进行交换
class Solution {
public:
uint32_t reverseBits(uint32_t n) {
n = (n >> 16) | (n << 16);
n = ((n&0xff00ff00) >> 8) | ((n&0x00ff00ff) << 8); //写成(n&0x00ff00ff << 8);错误
n = ((n&0xf0f0f0f0) >> 4) | ((n&0x0f0f0f0f) << 4);
n = ((n&0xcccccccc) >> 2) | ((n&0x33333333) << 2);
n = ((n&0xaaaaaaaa) >> 1) | ((n&0x55555555) << 1);
return n;
}
};














 332
332











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









