







二分查找
设数组a,其元素个数是n
①查找区间的下界用low表示,上界用high表示。初始时,查找区间是low=0,high=n-1
②设区间中点下标为mid,其中mid=(high+low)/2;将元素a[mid]的值与key进行比较,若key=a[mid],则表明查找成功,返回该元素的下标mid的值。
③若key<a[mid],则表明待查找元素key只可能落在该中点元素的左边区间a[low:mid-1]中,接着只需在a[low:mid-1]中继续进行二分查找即可,即新区间的下界不变,上界 high=mid-1.
④若key>a[mid],则表明待查找元素key只可能落在该中点元素的右边区间a[mid+1:n-1]中,接着只需在a[mid+1:n-1]中继续进行二分查找即可,即新区间的上界不变,下界low-mid+1
⑤这样经过一次比较后就使得查找区间缩小一半,如此进行下去,直到查找到对应的元素,返回其下标值,或者查找区间变为空(即区间下界low大于区间上界high),表明查找失败返回-1为止。
public static int binSearch(int a[], int key){
int n = a.length;
int low = 0, high = n-1, mid;
while(low <= high){
mid = (low + high)/2;
if(key == a[mid]) return mid;
if(key < a[mid]) high = mid - 1;
else low = mid + 1;
}
return -1;//查找失败返回-1
}
哈希查找
哈希技术是在记录的存储地址和他的关键字间建立一个确定的对应关系(哈希函数),不经过比较,一次存取就能得到所需查找元素的查找方法。
一个很常用的哈希函数的构造方法是除留余数法,即选某个合适的正整数,以关键字除以该正整数所得余数作为哈希地址
处理地址冲突的方法
1,开放地址法
线性探查 d = [h(key) + i]%m, i = 1, 2, 3, ...m-1,如果一个地址冲突就探寻下一个地址,直到找到空闲地址为止
平方探查 d = [h(key) + i]%m, i = 1^2, 2^2, 3^2, ...
随机探查 i为随机数
2,链地址法
将哈希地址相同的数据存储到同一个单链表中
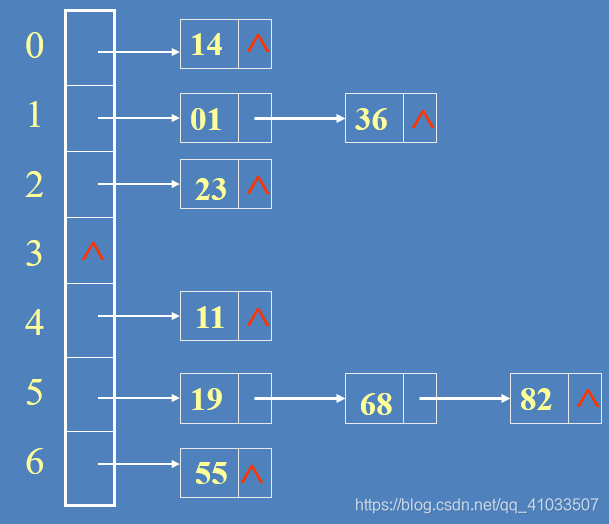
//基于链地址的哈希表程序
public class HashTable<T>{
LinkList<T> table[];//链表数组
public HashTable(int len){
//len是哈希表长度,如果len不是素数,取大于len的最小素数作为哈希表的长度(取素数是为了减小冲突)
int np;//大于len的最小素数
if(HashTable.isPrime(len)) np=len;
else{
if(len%2==0) len=len+1;
for(np=len;;np++)
if(HashTable.isPrime(np))
break;
}
table=new LinkList[np];
for(int i=0;i<table.length;i++){
table[i]=new LinkList<T>();
}
}
//哈希函数
public int hashCode( T key){
int hc=Math.abs(key.hashCode());
return hc%table.length;
}
public void add(T key){
int ha=hashCode(key);
table[ha].add(key);
}
public void remove(T key){
int ha=hashCode(key);
table[ha].remove(key);
}
public T search(T key){
int ha=hashCode(key);
return table[ha].search(key);
}
//判断n是否为素数
public static boolean isPrime(int n){
int m = (int) Math.sqrt(n);
if(n < 2) return false;
for(int i = 2; i < m; i++)
if(n%i == 0) return false;
return true;
}
public String toString(){
String str = "\n";
for(int i = 0; i < table.length; i++){
str = str + i + "|->" + table[i].toString() + "\n";
}
return str;
}
}
哈希映射
映射又称字典,由键(key)值(value)对构成
哈希映射首先定义一个表示键值对的类,然后对刚刚的HashTable进行封装
//表示(key,value)对的Pair类
class Pair<K,V>{
K key; //类型为K关键字
V value;//类型为V的值
public Pair(K k1,V v1){
key=k1; value=v1;
}
//重载Object的equals方法,注意真正比较的只是key,而忽略了value
public boolean equals(Object o){
Pair<K, V> pair = (Pair<K,V>)o;
return key.equals(pair.key);
}
//重载object的hashCode方法,注意我们只是简单地返回key的hashCode值
public int hashCode(){
return key.hashCode();
}
public String toString(){
return "("+key+","+value+")";
}
}
public class HashMap<K,V> {
HashTable<Pair<K,V>> ht;//定义pair<K,V>类型的哈希表,则是关键点
public HashMap(int len) {
ht=new HashTable<Pair<K,V>>(len);
}
//向哈希表中添加一个(key,value)对,同put,只为方便记忆
public void add(K key,V value){
ht.add(new Pair<K,V>(key,value));
}
//向哈希表中添加一个(key,value)对,Map的标准方法
public void put(K key,V value){
ht.add(new Pair<K, V>(key,value));
}
//根据关键字key,求的对应的value
public V get(K key){
Pair<K,V> p=ht.search(new Pair<K,V>(key,null));
if(p==null) return null;
else return p.value;
}
//判别Map中是否存在关键字key
boolean containsKey(K key){
Pair<K,V> p=ht.search(new Pair<K,V>(key,null));
if(p==null) return false;
else return true;
}
//删除关键字为key的(key,value) 对
public V remove(K key){
Pair<K,V> p=ht.remove(new Pair<K, V>(key,null));
if(p==null) return null;
else return p.value;
}
} HashMap的使用
public static void main(String[] args) {
int n=6; //请试着修改这个值,观察结果
HashMap<Integer,String> hm=new HashMap<Integer,String>(n);
hm.put(1, "北京");
hm.put(2, "上海");
hm.put(3, "古老历史");
hm.put(4, "现代风貌");
hm.put(5, "我喜欢");
System.out.print("输出哈希表表示的Map");
System.out.print(hm.ht);
System.out.println("==============");
System.out.print(hm.get(5));
System.out.print(hm.get(1));
System.out.println(hm.get(3));
System.out.print(hm.get(5));
System.out.print(hm.get(2));
System.out.println(hm.get(4));
}
运行结果:
输出哈希表表示的Map
0|->( )
1|->((1,北京))
2|->((2,上海))
3|->((3,古老历史))
4|->((4,现代风貌))
5|->((5,我喜欢))
6|->( )
==============
我喜欢北京古老历史
我喜欢上海现代风貌














 835
835











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









