







A Deep Relevance Matching Model for Ad-hoc Retrieval
(2016 CIKM)
模型细节
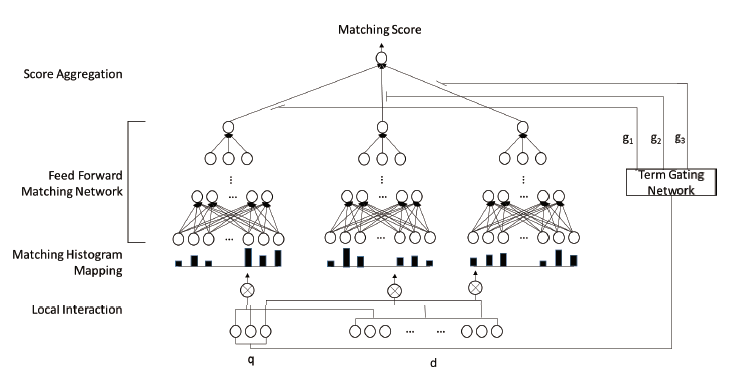
1.对于query中的每个词建立mapping直方图
输入:
query中的每个词和doc所有词产生term pair,对于每一个pair使用相似度计算(论文中使用了cos距离),考虑到位置对于匹配问题其实没有影响,此处不用位置信息,而是将每个pair的相似度进行分级(即文中说的直方图)- 例如:将余弦相似度[-1, 1]分为五个区间{[-1,-0.5), [-0.5,-0), [0,0.5), [0.5,1), [1,1]} 。给定query中的一个词“car”以及一篇文档(car, rent, truck, bump, injunction, runway), 得到对应的局部交互空间为(1, 0.2, 0.7, 0.3, -0.1, 0.1),最后我们用基于计数的直方图方法得到的直方图为[0,1, 3, 1, 1]。
对于直方图的生成有三种形式:

直方图相对于matching matrix的优点:
1.通过直方图,区别不同的匹配信号,而不像matching matrix所有匹配信号都混杂在一起
2.不需要zero padding,在matching matrix 中对于短文本需要进行padding,从而对其造成影响
2.输入到前馈神经网络
对于query的每个词形成的直方图输入到前馈神经网络
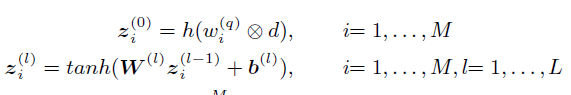
z0i
z
i
0
表示了对每个query生成直方图的过程
zli
z
i
l
表示输入前馈神经网络的过程
3.产生最后的匹配分数
对于每个query词产生的
zi
z
i
,最后通过一个gating network
gi
g
i
生成最后的分数,类似于注意力机制
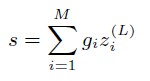
其中,

此处有两种方式:
(1)TV:
xi
x
i
为query embedding,
wg
w
g
为与embeding同等维度的weight vector
(2)IDF:
xi
x
i
为query的idf,
wg
w
g
为一个标量需要学习
结果分析
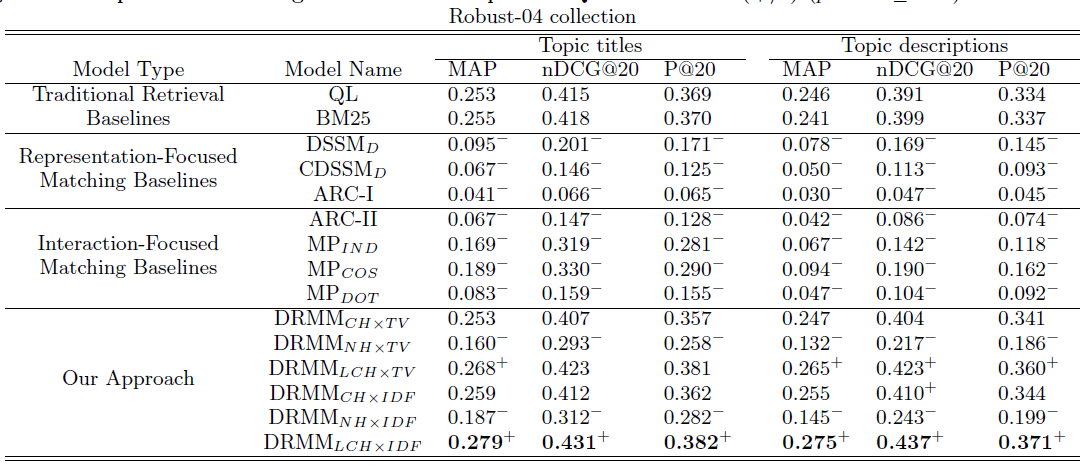
(1)加入idf非常有用
(2)NH方法效果很差,可能因为失去了doc长度,而doc长度在匹配问题中其实很有用














 1249
1249











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









