







文章目录
Ubuntu darknet(yolov4)标记、训练自己的数据流程记录
参考:https://github.com/AlexeyAB/darknet
记录以下流程和错误,之后再用到,查询起来也快些。
翻译了部分参照文档,并按照流程走的~
提前工作有:
1.克隆了darknet代码;
2.数据已经标注完毕。且生成了对应的标签数据集
0 数据准备
标注工具使用了labelme,生成的是json文件,需要转换为txt格式的。
将labelme标记的.json数据,转为yolov4训练用的.txt数据。
图片和json文件保存在obj文件夹里。
python代码:
from os import getcwd
import numpy as np
import os
import json
import glob
wd = getcwd()
"labelme标注的json数据集转为keras yolo的txt训练集"
classes = ["car","pedestrian","truck","bus"] #修改为待检测的类别名
image_ids = glob.glob(r"obj/*.jpg") #jpg和json文件都在文件夹obj/里
print(image_ids)
def convert_annotation(image_id):
jsonfile=open('%s.json' % (image_id))
in_file = json.load(jsonfile)
#print(in_file)
height=in_file["imageHeight"]
width=in_file["imageWidth"]
size=[width,height]
list_file = open('%s.txt'%(image_id.split('.')[0]), 'w')
for i in range(0,len(in_file["shapes"])):
object=in_file["shapes"][i]
cls=object["label"]
points=object["points"]
dw = 1./(size[0])
dh = 1./(size[1])
min_x=min_y= np.inf
max_x = max_y = 0
for x, y in points:
min_x = min(min_x, x)
min_y = min(min_y, y)
max_x = max(max_x, x)
max_y = max(max_y, y)
x=(min_x+max_x)/2.0
print(x)
y=(min_y+max_y)/2.0
print(y)
w=max_x-min_x
h=max_y-min_y
x = x*dw
w = w*dw
y = y*dh
h = h*dh
if cls not in classes:
print("cls not in classes")
continue
cls_id = classes.index(cls)
b = (x, y, w, h)
list_file.write(str(cls_id)+" "+" ".join([str(a) for a in b]) )
list_file.write('\n')
list_file.close()
jsonfile.close()
for image_id in image_ids:
# list_file.write('%s.jpg' % (image_id.split('.')[0]))
convert_annotation(image_id.split('.')[0])
该脚本程序会为每个
.jpg文件生成一个对应的.txt文件,而且都在obj目录下。一张图片,对应一个txt标注文件,它们同名但不同后缀。
得到图片和对应的txt标注文件之后,接下来需要生成train.txt和val.txt。
这两个txt文件保存图片的路径(可以是绝对路径,也可以是相对路径,相对路径是相对于darknet主目录而言)。本人使用了相对路径。
训练集和验证集的划分,按照一定的比例,在脚本gene_trainval.py中,比例使用变量ratio控制。
gene_trainval.py代码:
# 检验.txt 对应的.jpg或.jpeg或.png文件是否存在、是否可读(此处调用了cv2库)
# 按照训练集和验证机的比例,生成train.txt和val.txt
import os
import random
import cv2
# 默认img和txt在同一个文件夹
path='obj'
# 训练集:测试集 = 0.85:0.15
ratio=0.85
def check(img_path):
# 判断文件是否可读
image=cv2.imread(img_path)
if image is None:
return False
else:
return True
def main():
filenames=os.listdir(path)
# txt目标注释文件列表
annoList=[]
for file in filenames:
# 文件名
name=file.split('.')[0]
# 文件后缀
suffix=file.split('.')[-1]
# 是图片
if suffix in ['jpg','jpeg','png']:
# 如果没有安装python版cv2,且确定图片无损坏,则注释此行、import cv2、check()即可。
assert check(path + '/' + file)==True, '%s is unreadable'%(file)
# 图片对应的txt文件
anno= name + '.txt'
if os.path.isfile(path + '/'+ anno):
annoList.append(file)
else:
print('%s without annotation file' %(file) )
# 乱序
random.shuffle(annoList)
length=len(annoList)
# 训练集
f=open('./train.txt','w')
for anno in annoList[:int(ratio*length)]:
f.write('./data/' + path + '/' + anno + '\n')
f.close()
# 测试集
f=open('./val.txt','w')
for anno in annoList[int(ratio*length):]:
f.write('./data/' + path + '/' + anno + '\n')
f.close()
if __name__=='__main__':
main()
print('generate trainval.txt success')
现在,我们得到了obj文件夹,里面有图片和txt标注文件,得到了train.txt和val.txt文件,它们保存图片的路径。
当前目录结构如下:
darknet/
data/
obj/
train.txt
test.txt
gene_tainval.py
1 创建.data文件
在data目录里创建.data文件,tree:
darknet/
data/
obj.names # 物体类别名称
obj.data # 该文件夹保存数据集信息
obj/ # 存放图片以及标签信息
train.txt # 存放训练集地址
test.txt # 存放检测集地址
以下分别解释data/下5个文件(夹)的作用:
obj.name保存要检测物体的名称,一行写一个
例如:
car
truck
-
obj.data保存有五类信息:检测类别数量,训练集,验证集,类别名称,保存权重的文件夹,比如:classes= 2 # 目标物体的类别数量 train= ./data/train.txt # 训练数据集的路径 valid= ./data/test.txt # 验证数据集的路径 names= ./data/obj.names # 目标物体的类别名称 backup = ./backup # 保存训练权重文件 -
文件夹
obj/存放数据集图片和每张图片的标签信息,即:001.jpg 001.txt 002.jpg 002.txt其中,每个
.txt是对应.jpg的标签文件,其包含的信息有:<object-class> <x_center> <y_center> <width> <height>本人是将训练集和验证集的图片,都放在了obj文件夹里。
每个
.jpg文件,都有同名但.txt的文件相对应,且在obj文件夹里。001.txt文件中一行对应001.jpg中一个物体信息:类别 中心点x坐标 中心点y坐标 宽 高 ,可能有多行。
坐标计算方式如下:
<x_center> = <absolute_x> / <image_width> 即bounding box中心x实际坐标 / 图片实际宽度 <y_center> = <absolute_y> / <image_height> 即bounding box中心y实际坐标/图片实际高度 <width> = <absolute_width> / <image_width> 即bbox宽度/图片实际宽度 <height> = <absolute_width> / <image_width> 即bbox高度 /图片实际高度 -
train.txt保存所有训练集图片的相对地址,如:./data/obj/img001.jpg ./data/obj/img002.jpg ./data/obj/img003.jpg -
test.txt保存所有验证集图片的相对地址,如:./data/obj/img11.jpg ./data/obj/img21.jpg ./sdata/obj/img31.jpg
2 修改.cfg文件
cfg文件保存网络结构,darknet是实现该网络结构的一种框架,同pytorch框架一样,只是前者比较小众(c++语言写的)。
-
复制
cfg文件夹下yolov4.cfg为yolov4-obg.cfg(此处名字随意,所在文件夹也任意,但训练或测试,的时候,cfg文件的路径,是命令的参数之一) -
修改
yolov4-obj.cfg中的内容:# step1: 修改batch和subdivisions L2: batch=64 # 原来就是64,根据gpu自己选择,但必须是2的倍数 L3: subdivisions=16 # 根据自己的gpu选择,如果out of memory,则32或64,依次倍增。或者64,32,...,1,依次倍减batch值 # step2: 修改图片的尺寸 L7: width=608 # 这边我没有修改,该值必须被32整除。 L8: height=608 L19: max_batches=500500 #该值最少是classes*2000 L21:steps=400000,450000 #该值是 max_batches的80% 和 90% # step3: 修改classes(每个yolo层都需要修改一次,一共三次) L968: classes=2 # 和obj.data文件中classes值相同,=2表示只识别两类物体 L1056: classes=2 L1144: classes=2 # step4: 修改每个yolo相邻的上一个convolution层的filter,一共3个 L961: filters=21 # 因为我预测两类物体:21 = 3*(5+2),具体看下文解释 L1049: filters=21 L1137: filters=21L2,L3表示第2行,第3行。
filters=21 是3*(5+2)=21得来的。
如果一共检测4类物体,比如:car,pedestrian,truck,bus,则filters的值为3*(5+4)=27。
3 修改makefile文件
若无GPU,则不做任何修改,否则一些参数应修改为:
GPU=1: 表示在训练的时候使用CUDA进行加速训练(CUDA应该在 /usr/local/cuda文件夹下),若无,
CUDNN=1: 表示在训练的过程中使用CUDNN v5-v7进行加速(cuDNN应该在 /usr/local/cudnn文件夹下)
CUDNN_half=0: 为Tensor Cores (在Titan V / Tesla V100 / DGX-2等)上进行加速训练和推理。
OPENCV=1: 编译OpenCV 4.x/3.x/2.4.x等。OpenCV可以读取视频或者图片。
#L69 将NVCC=nvcc改为你自己的nvcc的路径
NVCC=/usr/local/cuda/bin/nvcc
注意L109和L121以下的3行:看一下cuda的默认路径,是否和自己的一致,不一致就需要修改。有的人是NVCC=/usr/local/cuda9.0/bin/nvcc,则需要修改。
以上就是开始训练前的准备。
4 开始训练
-
下载预训练权值
yolov4.conv.137,放在darknet/文件夹下。 -
执行命令
./darknet detector train data/obj.data cfg/yolov4-obj.cfg yolov4.conv.137 -map
这这里,如果opencv和cudnn没有装错的话,就开启正常训练了。如果batch和subdivision参数设置合理的话,基本不会出现内存不足而中途退出的情况。
启动训练一段时间之后,如果出现“out of memory,核心已转储” ,则调整yolov4-obj.cfg文件中的batch值(每次调小2倍),或subdivision值(每次调大2倍)。
然后,在backup文件夹内,找到最后的权重文件(.weights后缀)的文件名,比如:last.weights ,然后使用该参数替换上述训练命令中的weights路径参数,从中断处继续训练。示例:
./darknet detector train ./data/obj.data ./cfg/yolov4-obj.cfg ./backup/last.weights -map
迭代一定的次数后,会自动将训练的权重文件保存在backup文件夹下,且会以迭代次数作为名字。注意mAP图的变化,找到最优值所在的迭代次数,对应的权重文件,就是最适合的。
5 命令行参数:
1.指定GPU:
上述训练命令,如果没有指定GPU,则默认是0号卡。可以在命令后面加参数i- 指定。比如:
#如果想要指定具体的gpu进行训练,使用-i来指定,比如我想使用索引为2的gpu进行训练:
./darknet detector train data/obj.data cfg/yolov4-obj.cfg yolov4.conv.137 -i 2 -map
2.训练时不显示mAP和loss变化图:使用参数-dont_show
./darknet detector train data/obj.data cfg/yolo-obj.cfg yolov4.conv.137 -dont_show
3.在远程网页端,显示mAP&Loss图:
./darknet detector train data/obj.data cfg/yolo-obj.cfg yolov4.conv.137 -dont_show -mjpeg_port 8090 -map
然后使用浏览器打开链接:http://ip-address:8090
训练过程中,darknet自动保存权值文件到backup/
backup文件夹下的yolo-obj_last.weights文件会每隔1000个iterations保存一次,新的会替代旧的
darknet总的训练步长可以在yolov4-obj.cfg文件中修改max_batches的大小(默认max_batches = 500500)
-map表示可视化显示mAP&Loss 图表,每4Epochs
训练完成后,在backup/查看结果文件:yolo-obj_final.weights
每100次迭代,比如2000次迭代后,由于外因,你停止了检测,之后可以使用:
./darknet detector train data/obj.data yolo-obj.cfg backup/yolo-obj_2000.weights来继续训练。当avg-average loss (error)值达到最低时,你也可以提前停止训练。
6 提前终止训练
关于提前终止训练,官网是这样说的:
- 当loss 0.xxxxxx avg 不再变化的时候,可以提前停止训练。
- 训练结束后,在backup文件夹中选择最合适的权重。
如果你在9000 iterations停止训练,可能最好的模型在7000, 8000, 9000之间,不确定会不会产生过拟合,因此你需要找到提前停止训练的点(Early Stopping Point),如图所示:
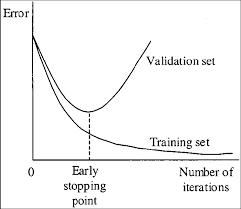
(官网的图)在Early Stopping Point处,权值文件是最佳的。
如果需要测试权重文件的mAP,则:
-
准备验证集。
你需要在 obj.data中将valid = data/test.txt 修改成 valid = data/valid.txt (valid.txt的格式和train.txt一样),如果你没有验证集,你可以直接将train.txt的内容直接复制到valid.txt文件中。
-
测试候选权重的mAP。
如果你是在9000 iterations停止训练的,你就需要对之前保存的权重进行测试:
测试mAP的命令如下:
step1.测试7000 iterations的mAP:
./darknet detector map data/obj.data cfg/yolov4-obj.cfg backup/yolo-obj_7000.weights
step2: 测试8000 iterations的mAP
./darknet detector map data/obj.data cfg/yolov4-obj.cfg backup/yolo-obj_8000.weights
step3: 测试9000 iterations的mAP
./darknet detector map data/obj.data cfg/yolov4-obj.cfg backup/yolo-obj_9000.weights
选择mAP值或者IOU值最高的权重文件,该文件就是最优的训练权重。
这样就可以显示训练时的mAP,根据训练过程图来选择最合适的权重了。
7 开始检测
训练好权重之后,我们可以使用权重进行检测,在终端中输入下面的命令检测图片:
./darknet detector test ./data/obj.data ./cfg/yolo-obj.cfg ./backup/yolo-obj_8000.weights ./data/test.jpg
检测视频:
# 只显示FPS,不显示图像
./darknet detector demo ./data/obj.data ./cfg/yolov4-obj.cfg ./backup/yolov4-obj_9000.weights ./demo3.mp4 -dont_show -out_filename res.mp4
# 显示FPS,显示图像,保存检测视频结果
./darknet detector demo data/obj.data cfg/yolov4-obj.cfg backup/yolov4-obj_9000.weights data/demo3.mp4 -ext_output -out_filename res.mp4
8 其它
AlexeyAB/darknet官网代码中有自带两个脚本:darknet_video.py和darknet_images.py,它们调用darknet编译生成的lib库(位于darknet主目录下)分别进行视频检测和图像检测。通过该脚本,可以进行相关的后处理。为了生成libdarknet,需设置Makefile文件第7行lIBSO=1 ,从新编译。
修改:
- 脚本中的parse()函数:添加
.data文件路径、.cfg文件路径、.weights文件路径。- args参数
相关:通过标注文件中的坐标信息,画出物体的标注框
import os
import cv2
obj_path='./image' # image + txt
out_path='./out' # after drow box,save to ./out
fileList=os.listdir(obj_path)
total=len(fileList)//2
def bbox2points(x,y,w,h):
# center point to corner point
xmin = int(round(x - (w / 2)))
xmax = int(round(x + (w / 2)))
ymin = int(round(y - (h / 2)))
ymax = int(round(y + (h / 2)))
return xmin, ymin, xmax, ymax
def draw_box(img,txt):
f=open(obj_path + '/' + txt)
image=cv2.imread(obj_path + '/'+ img)
output=image.copy()
height,width=image.shape[0],image.shape[1]
for line in f.readlines():
_,x,y,w,h=line.split(' ')
x,y,w,h=float(x),float(y),float(w),float(h)
x=x*width;y=y*height
w=w*width;h=h*height
xmin,ymin,xmax,ymax=bbox2points(x,y,w,h)
cv2.rectangle(output, (xmin, ymin),(xmax, ymax), (0,255,0), 1)
cv2.imwrite(out_path + '/' + img,output)
def main():
fail_list=[]
for i,file in enumerate(fileList):
print('[%d/%d]' % (i,total) )
suffix=file.split('.')[-1]
if suffix in ['jpg','jpeg','png']:
txt=file.split('.')[0] + '.txt'
if os.path.isfile(obj_path + '/'+ txt):
draw_box(file,txt)
print(file)
else:
print('%s is not find' % (txt) )
fail_list.append(txt)
if len(fail_list)==0:
print('all success')
else:
print('nof found txt')
for i in fail_list:
print(i)
if __name__=='__main__':
main()
Reference
[1] https://github.com/AlexeyAB/darknet
以上。














 758
758











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









