 MySQL索引深度解析与优化策略
MySQL索引深度解析与优化策略





 本文详细介绍了MySQL中不同类型的索引实现,包括哈希表、有序数组和B+树,强调了B+树在数据库中的优势。此外,讨论了索引策略,如前缀索引、联合索引、覆盖索引和唯一索引,以及如何避免索引失效。通过实例解释了如何选择合适的索引长度、创建联合索引以及理解索引下推优化。最后,分析了聚簇索引和非聚簇索引的工作原理及其对查询性能的影响。
本文详细介绍了MySQL中不同类型的索引实现,包括哈希表、有序数组和B+树,强调了B+树在数据库中的优势。此外,讨论了索引策略,如前缀索引、联合索引、覆盖索引和唯一索引,以及如何避免索引失效。通过实例解释了如何选择合适的索引长度、创建联合索引以及理解索引下推优化。最后,分析了聚簇索引和非聚簇索引的工作原理及其对查询性能的影响。
索引常用的实现
哈希表实现
哈希索引基于哈希表实现,只能用于等值查询,不适用于范围查询和索引排序
在MySQL中只有Memory引擎支持哈希索引,但是可以自定义创建哈希索引使用。
思路:在B-Tree的基础上创建一个伪哈希索引,使用哈希值而不是键值进行索引查找,使用时需要手动的指定哈希函数进行哈希化
例子:
根据url查找id
SELECT id FROM url WHERE url="http://www.mysql.com"
如果用B-Tree存储url索引可能会非常大,且长度变化区间很大
可以维护一个url_crc的哈希索引,通过哈希索引进行查询,为了避免哈希冲突,还应该加上原来的数据做一个校验
SELECT id FROM url WHERE url_crc=CRC32("http://www.mysql.com") AND url="http://www.mysql.com"
查询时会使用url_crc索引进行查询(索引值为:1560514994),如果没有冲突直接命中,如果冲突了再校验url
url_crc索引可以通过触发器或者手动进行维护
有序数组实现
有序数组实现的索引在等值查询和范围查询场景下性能非常高,但不适用于动态存储引擎,插入数据时会移动大量数据,性能差
等值查询时,通过二分查找可以O(log(N))的进行查询
范围查询时,通过二分查找到大于等于起始范围的最小值,然后向右进行遍历,直到查询完成
仅仅从查询效率来看,有序数组时最好的索引的数据结构
B+树实现
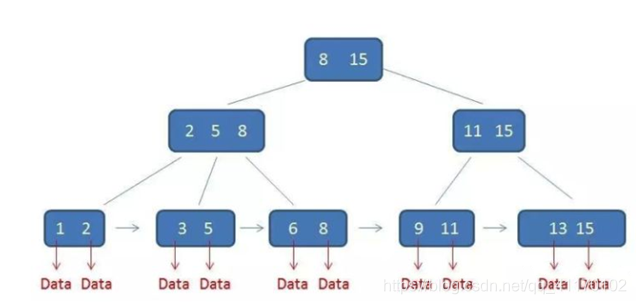
B+树是一种平衡多路查找树,属于N叉树,为了提升查询的效率,B+树的高度通常不会很高,所以分叉N就会很多,N也不是越大越好,操作系统都是按页读取,一次读取超过一页会触发多次IO,所以每个结点的大小尽量等于一个页的大小
B+树有以下特点(m叉树):
- 每个节点中子节点的个数不能超过m,也不能小于m/2
- 根结点的子节点个数可以不超过m/2
- m叉树只存储索引,不存储真实数据,真实数据都在叶子节点
- 通过双向链表将叶子节点串联起来,方便进行区间查找
B树(B-树)与B+树区别
B 树是一个每个节点的子节点个数不能小于 m/2 的 m 叉树
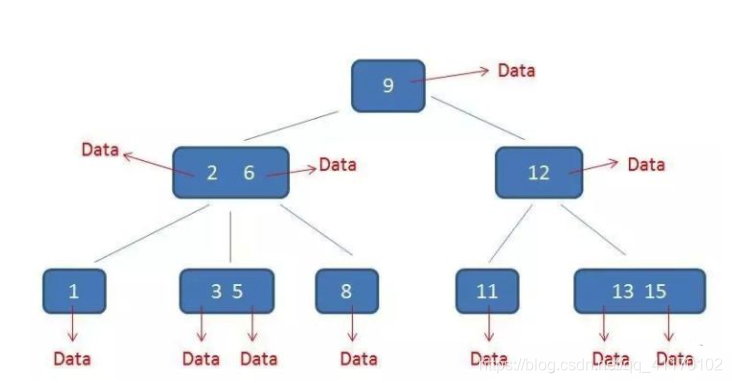
B树和B+树结构非常像,主要区别在于:
-
B+树的子节点不存储数据,只存索引,而B树中的子节点都要存储数据。内存一定时,索引加载入内存,B+树非叶子节点没有Data域可以加载更多,效率更高
-
B树的叶子节点没有双向链表进行串联,进行范围查询时,B+树只需要索引到边界值然后通过链表顺序获取,B树需要重新索引
索引策略
前缀索引
需要索引很长的字符串列时,索引会变得大且慢,
- 针对等值查询时,可以使用自定义哈希索引+二次校验缩短索引长度
- 针对范围查询时,可以使用前缀索引进行优化。
当索引字符串前缀比较有区分度时,通过前缀的部分字符就可以较为精准的定位行
给字符串创建前缀索引时,定义好长度,可以做到既节省空间,又不用额外增加太多的查询成本
- 当前缀索引较短时,查询到的符合的数据后会回表进行校验,直到不满足前缀索引了再退出
- 当前缀索引较长时,可以唯一的定位到一行数据,但是过长就不满足前缀索引的初衷了
确定前缀索引长度的方法
- 统计索引的列上有多少不同的值,作为参考标准:如计划在SUser表给email加上前缀索引
select count(distinct email) as L from SUser
- 选取不同长度的前缀再次进行不同值的统计
select
count(distinct left(email,4))as L4,
count(distinct left(email,5))as L5,
count(distinct left(email,6))as L6,
count(distinct left(email,7))as L7,
from SUser;
- 从结果进行分析
L:985
L4:695
L5:785
L6:975
L7:977
使用前缀索引很可能会损失区分度,所以需要预先设定一个可以接受的损失比例, 比如 5%。然后,在返回的 L4~L7 中,找出不小于 L * 95% 的值,假设这里 L6、L7 都满 足,就可以选择前缀长度为 6的
使用前缀索引会导致覆盖索引失效,查询后会有一个回表的操作进行校验,即使查询列满足覆盖索引,也会进行回表
后缀索引,MySQL不支持后缀索引,但是可以将字符串反转后进行存储,基于此建立前缀索引可以替代后缀索引
联合索引
当查询条件为多个列时,可以创建联合索引,以减少索引的个数
索引满足“最左前缀”规则,一个设计合理的“联合索引”通常可以复用多个查询的索引需求,从而减少维护的索引个数
“最左前缀”规则
如果表拥有一个联合索引, 任何一个索引的最左前缀都会被优化器用于查找列. 比如,如果创建了一个三列的联合索引包含(col1, col2, col3), 你的索引会生效于(col1),
(col1, col2), 以及(col1, col2, col3)
创建联合索引 idx_a_b_c (a,b,c)
查询使用idx_a_b_c:
select * from test where a = '333' and b = '333' and c = '333';
select * from test where a = '333' and b = '333';
select * from test where a = '333';
select * from test where c = '333' and b = '333' and a = '333';//与顺序无关
查询不使用idx_a_b_c:
select * from test where b = '333' and c = '333';
select * from test where b = '333';
select * from test where c = '333';
小结:
- 联合索引的最左前缀匹配指的是where条件字段是联合索引的前n个列
- 是否走联合索引与where条件的顺序无关,只与字段有关
联合索引部分失效情况
- 当索引中某个列使用了范围查询和后缀模糊查询时,后续的索引不会被使用
select * from test where a = `333` and b > `200` and c = 333
select * from test where a = `333` and b like `2%` and c = 333
索引只会走ab
联合索引使用时:
- 选择性低使用率高的列可以放在联合索引前面,不需要使用时通过IN()来使用上索引
- 范围查询使用到的列尽量放在最后面,避免范围查询的列之后的索引用不上
- 范围查询范围很小且可穷举时可以用IN()替代范围查询
索引下推
从MySQL5.6开始支持索引下推优化,索引下推是指将查询数据是否符合判断条件从MySQL服务器下推到存储引擎中。
- 不使用索引下推优化时,通过存储引擎索引到数据,返回给MySQL服务器进行判断是否符合
- 使用索引下推优化后,如果存在被索引列的判断条件时,MySQL会把这一部分条件传递给存储引擎进行判断,由存储引擎判断后再把符合的返回给MySQL数据库
索引条件下推优化可以减少存储引擎查询基础表的次数,也可以减少MySQL服务器从存储引擎接收数据的次数
应用:联合索引失效时优化
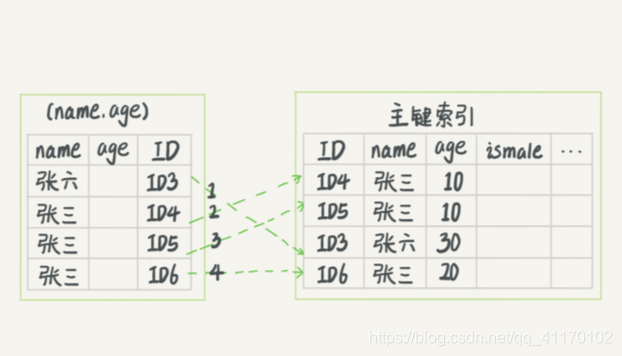
用户表存在联合索引idx_name_age(name, age)
需要查询姓为’张‘的年龄为10岁的所有男孩
select * from tuser where name like '张 %' and age=10 and ismale=1
根据前缀匹配规则和模糊查询前缀,只有name能走索引
-
没有索引下推优化:查询出所有姓‘张’的然后判断age和ismale,回表4次
-
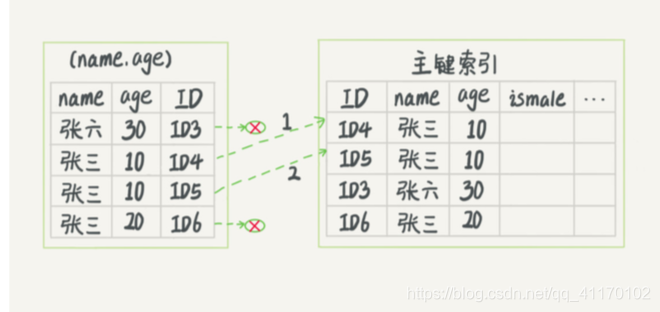
索引下推优化:查询时会一起判断age是否满足,回表两次
聚簇索引
聚簇索引是一种数据存储方式,InnoDB中的聚簇索引实际上是同一结构中保存B-Tree索引和数据行
和聚簇索引相对的还有二级索引
- 聚簇索引在InnoDB中也叫主键索引,叶子节点存放的是整行数据
- 二级索引在InnoDB中也叫非主键索引,叶子节点存放的是主键的值
查询时,如果使用主键索引,可以直接返回整行数据,如果使用非主键索引查询索引之外的列值,查询到的结果是索引和主键值,需要通过主键值回表查询整行数据获得索引列之外的列值
select * from T where k=5
其中k为二级索引,查询结果为主键值,需要查询所有列值就需要回表通过主键索引查询整行
覆盖索引
如果查询需要的列都已经在索引树上了,就可以直接提供查询结果而不需要回表,就是覆盖索引
覆盖索引可以减少树的搜索次数,显著提升查询性能,所以使用覆盖索引是一个常用的性能优化手段
为了实现覆盖索引,通常需要添加冗余索引,维护冗余索引字段有一定的代价,所以是否建立覆盖索引需要权衡覆盖索引带来的性能提升与维护代价
案例:

需求:根据 请求地址 查询(主键,请求地址,请求方法)

索引方案1:

通过url索引查询到对应主键的信息
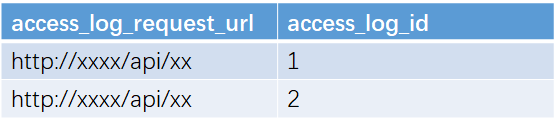
通过access_log_id进行回表查询完整行,并返回需求的字段

索引方案2:

索引查询结果

无需回表操作
唯一索引
当逻辑上已经能保证数据唯一后,应该选用普通索引而不是唯一索引
从查询和更新比较
查询过程
- 普通索引:查询到第一个不满足条件的记录后退出,如果逻辑上唯一,需要查两条
- 唯一索引:查询到满足的就直接退出,需要查一条
查询的过程在性能上差距微乎其微
更新过程
普通索引可以使用change buffer,性能有较大的差异
- 普通索引:更新一个数据时,如果数据所在数据页在内存中,直接进行更新,如果没在内存中,会讲更新操作缓存在change buffer中,需要查询到这个数据页将数据页加载到内存后再merge执行写入磁盘。merge执行时机:访问数据页,后台线程定期merge,数据正常关闭
- 唯一索引:更新一个数据时,如果数据所在页在内存中,直接进行更新,如果没在内存中,会把数据页加载到内存中,会校验是否唯一后再写入
唯一索引更新时如果数据页不在内存必须载入内存,而普通索引可以写入change buffer后根据merge策略进行批量写入,效率高很多
索引失效
-
在索引上做任何(计算/函数/隐式类型转换/隐式编码转换)操作
-
计算

-
函数

-
类型转换

-
编码转换
两个做关联查询的字段编码分别为utf8mb4 和utf8,索引会失效。
执行时编码类型不一致,utf8会隐式的通过CONVERT函数向超集utf8mb4进行转换
-
-
最左匹配中间索引使用范围查询(>/</between/like后缀匹配),此索引后的索引失效


-
索引字段使用 (or/!=/<>/is null/is not null/like前缀匹配),导致索引失效

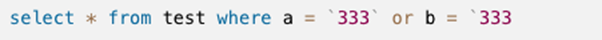
-
数据选择性低的独立索引
如对性别加单独的索引,性别只有两个选项 男/女,使用索引没有意义


















 351
351

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









