







字符串排序
对于许多排序应用,决定顺序的键都是字符串。
第一类方法会从右到左检查键中的字符。这种方法一般被称为低位优先(Least=Significant-Digit First,LSD)的字符串排序。使用数字(digit)代替字符(character)的原因要追溯到相同方法在各种数字类型中的应用。如果将一个字符串看作一个256进制的数字,那么从右向左检查字符串就等价于先检查数字的最低位。这种方法最适合用于键的长度都相同的字符串排序应用。
第二类方法会从左到右检查键中的字符,首先查看的是最高位的字符。这些方法通常称为高位优先(MSD)的字符串排序。高位优先的字符串排序的吸引人之处在于,它们不一定需要检查所有的输入就能够完成排序。高位优先的字符串排序和快速排序类似,因为它们都会将需要排序的数组切分为独立的部分并递归地用相同的方法处理子数组来完成排序。它们的区别之处在于高位优先的字符串排序算法在切分时仅使用键的第一个字符,而快速排序的比较则会涉及键的全部。要学习的第一种方法会为每个字符创建一个切分,第二种方法则总会产生三个切分,分别对应被搜索键的第一个字符小于、等于或大于切分键的第一个字符的情况。
键索引计数法
键索引计数的方法适用于小整数键的简单排序方法,它是下面三种字符串排序算法中两种的基础。
这种方法有以下4个步骤:
- 频率统计:第一步就是使用int数组count[]计算每个键出现的频率。对于数组中的每个元素,都使用它的键访问count[]中的相应元素并将其加1,如果键为r,则将count[r+1]加1。
- 将频率转换为索引:接下来,使用count[]来计算每个键在排序结果中的起始索引位置。一般来说,任意给定的键的起始索引均为所有较小的键所对应的出现频率之和。对于每个键值r,小于r+1的键的频率之和为小于r的键的频率之和加上count[r],因此从左向右将count[]转化为一张用于排序的索引表是很容易的。
- 数据分类:在将count[]数组转换为一张索引表之后,将所有元素移动到一个辅助数组aux[]中以进行排序。每个元素在aux[]中的位置是由它的键对应的count[]值决定,在移动之后将count[]中对应元素的值加1,以保证count[r]总是下一个键为r的元素在aux[]中的索引位置。这个过程只需遍历一遍数据即可产生排序结果。注意:在我们的一个应用中,这种实现方式的稳定性是很关键的——键相同的元素在排序后会被聚集到一起,但相对顺序没有变化。
- 回写:因为我们在将元素移动到辅助数组的过程中完成了排序,所以最后一步就是将排序的结果复制回原数组中。
键索引计数法排序N个键为0到R-1之间的整数的元素需要访问数组11N+4R+1次。只要当R在N的一个常数因子范围之内,它都是一个线性时间级别的排序方法。
代码:
package section5_1;
public class KeyIndexCount {
public static void main(String[] args) {
String[] a = {
"Anderson 2",
"Brown 3",
"Davis 3",
"Garcia 4",
"Harris 1",
"Jackson 3",
"Johnson 4",
"Jones 3",
"Martin 1",
"Martinez 2",
"Miller 2",
"Moore 1",
"Robinson 2",
"Smith 4",
"Taylor 3",
"Thomas 4",
"Thompson 4",
"White 2",
"Williams 3",
"Wilson 4"
};
int N = a.length;
int R = 5;
String[] aux = new String[N];
int[] auxidx = new int[N];
int[] count = new int[R + 1];
System.out.println("----------------------before sort:");
for (int i = 0;i < N;i++) {
System.out.println(a[i]);
}
//计算出现的频率
for (int i = 0;i < N;i++) {
String[] s = a[i].split(" ");
count[Integer.parseInt(s[1]) + 1]++;
}
System.out.println("---------------------count:");
for (int i = 0;i <= R;i++)
System.out.print(count[i] + " ");
System.out.println();
//将频率转换为索引
for (int r = 0;r < R;r++) {
count[r + 1] += count[r];
}
System.out.println("---------------------count:");
for (int i = 0;i <= R;i++)
System.out.print(count[i] + " ");
System.out.println();
//将元素分类
for (int i = 0;i < N;i++) {
String[] s = a[i].split(" ");
aux[count[Integer.parseInt(s[1])]] = s[0];
auxidx[count[Integer.parseInt(s[1])]++] = Integer.parseInt(s[1]);
}
//回写
for (int i = 0;i < N;i++) {
a[i] = aux[i] + " " + auxidx[i];
}
System.out.println("-------------------after sort:");
for (int i = 0;i < N;i++) {
System.out.println(a[i]);
}
}
}
输出:

低位优先的字符串排序
车牌号由数字和字母混合组成,因此一般都将它们表示为字符串。在最简单的情况中,这些字符串的长度都是相同的。将此类字符串排序可以通过键索引计数法来完成。如果字符串的长度均为W,那就从右向左以每个位置的字符作为键,用键索引计数法将字符串排序W遍。除非键索引计数法是稳定的,否则这种方法是行不通的。
命题:低位优先的字符串排序算法能够稳定地将定长字符串排序。
排序的稳定性:在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次序保持不变,则称排序算法是稳定的。
证明该命题的另一种方法是向前看:如果有两个键,它们中还没有被检查过的字符串是完全相同的,那么键的不同之处就仅限于已经被检查过的字符。因为两个键已经被排序过,所以出于稳定性它们将一直保持有序。另外,如果还没被检查过的部分是不同的,那么已经被检查过的字符对于两者的最终顺序没有意义,之后的某轮处理会根据更高位字符的不同修正这对键的顺序。
从理论上说,低位优先的字符串排序的意义重大,因为它是一种适用于一般应用的线性时间排序算法。无论N有多大,它都只遍历W次数据。
代码:
package section5_1;
public class LSD {
public static void sort(String[] a, int W) {
int N = a.length;
int R = 256;
String[] aux = new String[N];
for (int d = W - 1;d >= 0;d--) {
int[] count = new int[R + 1];
for (int i = 0;i < N;i++) {
count[a[i].charAt(d) + 1]++;
}
for (int r = 0;r < R;r++) {
count[r + 1] += count[r];
}
for (int i = 0;i < N;i++) {
aux[count[a[i].charAt(d)]++] = a[i];
}
for (int i = 0;i < N;i++) {
a[i] = aux[i];
}
}
}
public static void main(String[] args) {
String[] a = {
"4PGC938",
"2IYE230",
"3CIO720",
"1ICK750",
"1OHV845",
"4JZY524",
"1ICK750",
"3CIO720",
"1OHV845",
"1OHV845",
"2RLA629",
"2RLA629",
"3ATW723"
};
int w = 7;
sort(a,w);
for (int i = 0;i < a.length;i++) {
System.out.println(a[i]);
}
}
}
输出:
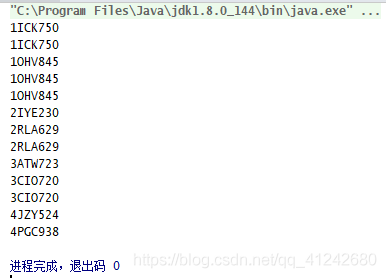














 6917
6917











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









