








code :https: //github.com/huawei-noah/ghostnet
paper :https://arxiv.org/pdf/1911.11907.pdf
摘要:

核心思想:
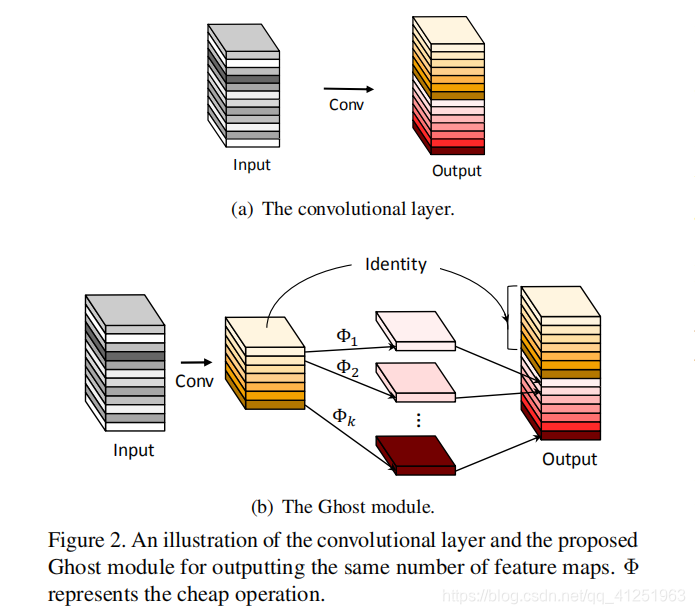
- 作者为了进一步压缩 CNN 网络结构,提出了一个 Ghost module,其核心是通过简单的线性变换,在内在特征图的基础上,生成更多可以完全揭示内在特征信息的 ghost feature map,从而以较小的计算代价生成更多特征;
- 作者提出的 Ghost module 可以看作一个即插即用组件,用于升级现有的卷积神经网络,其核心是在输出通道数不变的情况下,减小卷积层的通道数并采用一个线性变换来升维,以此减小参数;
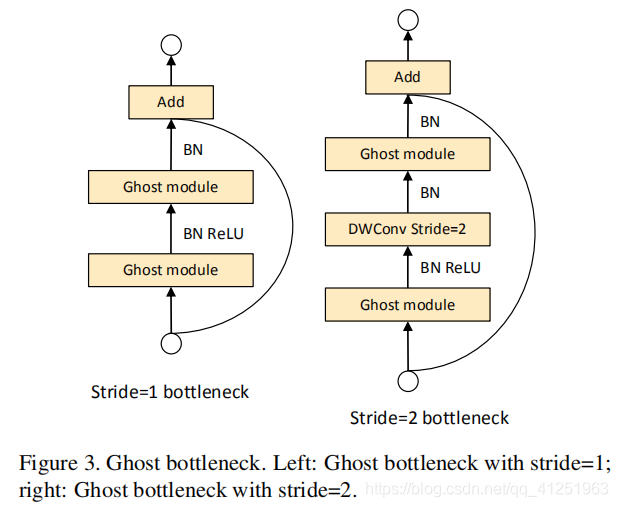
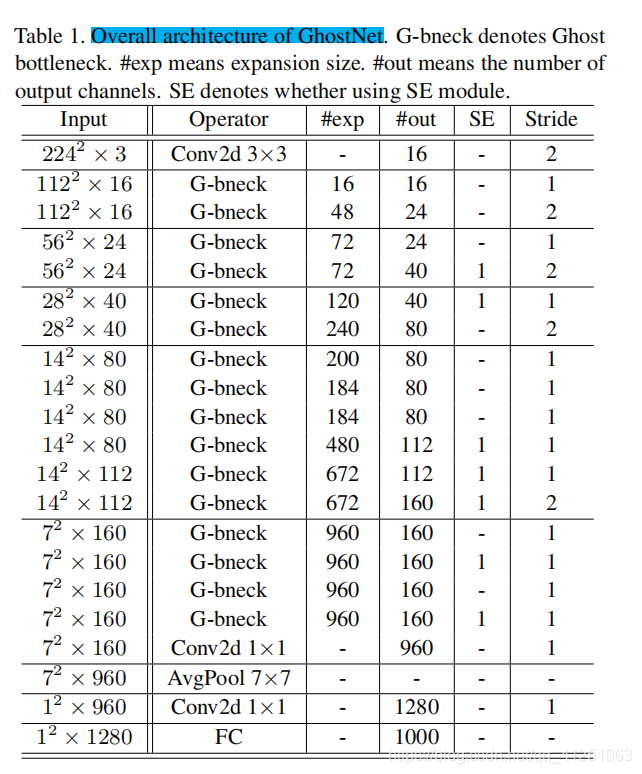
- 同时作者也提出了一个 Ghost Bottleneck 模块用来堆叠 Ghost module,并以此构建了一个新的网络 GhostNet,实现了 75.7% top-1 准确率,在比 MobileNetV3 准确率还高的基础上,进一步压缩了模型;
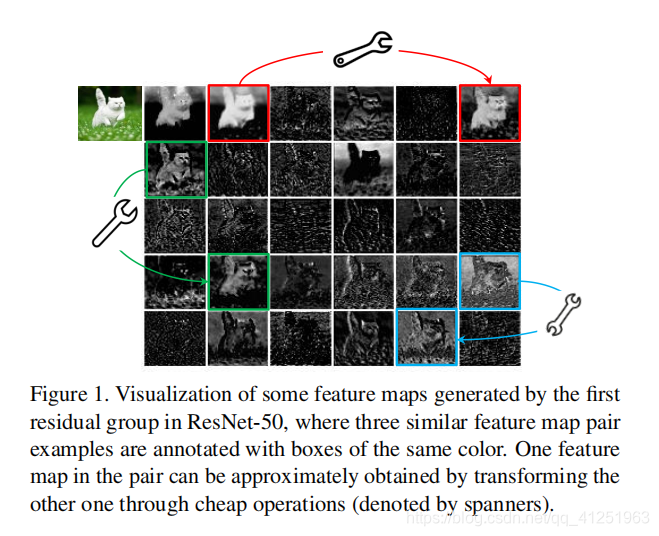
如图1所示,卷积层的输出特征映射通常包含许多冗余,其中一些可能彼此相似。 我们指出,没有必要用大量的FLOP和参数逐个生成这些冗余特征映射。



分析:



# 2020.06.09-Changed for building GhostNet
# Huawei Technologies Co., Ltd. <foss@huawei.com>
"""
Creates a GhostNet Model as defined in:
GhostNet: More Features from Cheap Operations By Kai Han, Yunhe Wang, Qi Tian, Jianyuan Guo, Chunjing Xu, Chang Xu.
https://arxiv.org/abs/1911.11907
Modified from https://github.com/d-li14/mobilenetv3.pytorch and https://github.com/rwightman/pytorch-image-models
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
__all__ = ['ghost_net']
def _make_divisible(v, divisor, min_value=None):
"""
This function is taken from the original tf repo.
It ensures that all layers have a channel number that is divisible by 8
It can be seen here:
https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py
"""
if min_value is None:
min_value = divisor
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
if new_v < 0.9 * v:
new_v += divisor
return new_v
def hard_sigmoid(x, inplace: bool = False):
if inplace:
return x.add_(3.).clamp_(0., 6.).div_(6.)
else:
return F.relu6(x + 3.) / 6.
class SqueezeExcite(nn.Module):
def __init__(self, in_chs, se_ratio=0.25, reduced_base_chs=None,
act_layer=nn.ReLU, gate_fn=hard_sigmoid, divisor=4, **_):
super(SqueezeExcite, self).__init__()
self.gate_fn = gate_fn
reduced_chs = _make_divisible((reduced_base_chs or in_chs) * se_ratio, divisor)
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv_reduce = nn.Conv2d(in_chs, reduced_chs, 1, bias=True)
self.act1 = act_layer(inplace=True)
self.conv_expand = nn.Conv2d(reduced_chs, in_chs, 1, bias=True)
def forward(self, x):
x_se = self.avg_pool(x)
x_se = self.conv_reduce(x_se)
x_se = self.act1(x_se)
x_se = self.conv_expand(x_se)
x = x * self.gate_fn(x_se)
return x
class ConvBnAct(nn.Module):
def __init__(self, in_chs, out_chs, kernel_size,
stride=1, act_layer=nn.ReLU):
super(ConvBnAct, self).__init__()
self.conv = nn.Conv2d(in_chs, out_chs, kernel_size, stride, kernel_size//2, bias=False)
self.bn1 = nn.BatchNorm2d(out_chs)
self.act1 = act_layer(inplace=True)
def forward(self, x):
x = self.conv(x)
x = self.bn1(x)
x = self.act1(x)
return x
class GhostModule(nn.Module):
def __init__(self, inp, oup, kernel_size=1, ratio=2, dw_size=3, stride=1, relu=True):
super(GhostModule, self).__init__()
self.oup = oup
init_channels = math.ceil(oup / ratio)
new_channels = init_channels*(ratio-1)
self.primary_conv = nn.Sequential(
nn.Conv2d(inp, init_channels, kernel_size, stride, kernel_size//2, bias=False),
nn.BatchNorm2d(init_channels),
nn.ReLU(inplace=True) if relu else nn.Sequential(),
)
self.cheap_operation = nn.Sequential(
nn.Conv2d(init_channels, new_channels, dw_size, 1, dw_size//2, groups=init_channels, bias=False),
nn.BatchNorm2d(new_channels),
nn.ReLU(inplace=True) if relu else nn.Sequential(),
)
def forward(self, x):
x1 = self.primary_conv(x)
x2 = self.cheap_operation(x1)
out = torch.cat([x1,x2], dim=1)
return out[:,:self.oup,:,:]
class GhostBottleneck(nn.Module):
""" Ghost bottleneck w/ optional SE"""
def __init__(self, in_chs, mid_chs, out_chs, dw_kernel_size=3,
stride=1, act_layer=nn.ReLU, se_ratio=0.):
super(GhostBottleneck, self).__init__()
has_se = se_ratio is not None and se_ratio > 0.
self.stride = stride
# Point-wise expansion
self.ghost1 = GhostModule(in_chs, mid_chs, relu=True)
# Depth-wise convolution
if self.stride > 1:
self.conv_dw = nn.Conv2d(mid_chs, mid_chs, dw_kernel_size, stride=stride,
padding=(dw_kernel_size-1)//2,
groups=mid_chs, bias=False)
self.bn_dw = nn.BatchNorm2d(mid_chs)
# Squeeze-and-excitation
if has_se:
self.se = SqueezeExcite(mid_chs, se_ratio=se_ratio)
else:
self.se = None
# Point-wise linear projection
self.ghost2 = GhostModule(mid_chs, out_chs, relu=False)
# shortcut
if (in_chs == out_chs and self.stride == 1):
self.shortcut = nn.Sequential()
else:
self.shortcut = nn.Sequential(
nn.Conv2d(in_chs, in_chs, dw_kernel_size, stride=stride,
padding=(dw_kernel_size-1)//2, groups=in_chs, bias=False),
nn.BatchNorm2d(in_chs),
nn.Conv2d(in_chs, out_chs, 1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(out_chs),
)
def forward(self, x):
residual = x
# 1st ghost bottleneck
x = self.ghost1(x)
# Depth-wise convolution
if self.stride > 1:
x = self.conv_dw(x)
x = self.bn_dw(x)
# Squeeze-and-excitation
if self.se is not None:
x = self.se(x)
# 2nd ghost bottleneck
x = self.ghost2(x)
x += self.shortcut(residual)
return x
class GhostNet(nn.Module):
def __init__(self, cfgs, num_classes=1000, width=1.0, dropout=0.2):
super(GhostNet, self).__init__()
# setting of inverted residual blocks
self.cfgs = cfgs
self.dropout = dropout
# building first layer
output_channel = _make_divisible(16 * width, 4)
self.conv_stem = nn.Conv2d(3, output_channel, 3, 2, 1, bias=False)
self.bn1 = nn.BatchNorm2d(output_channel)
self.act1 = nn.ReLU(inplace=True)
input_channel = output_channel
# building inverted residual blocks
stages = []
block = GhostBottleneck
for cfg in self.cfgs:
layers = []
for k, exp_size, c, se_ratio, s in cfg:
output_channel = _make_divisible(c * width, 4)
hidden_channel = _make_divisible(exp_size * width, 4)
layers.append(block(input_channel, hidden_channel, output_channel, k, s,
se_ratio=se_ratio))
input_channel = output_channel
stages.append(nn.Sequential(*layers))
output_channel = _make_divisible(exp_size * width, 4)
stages.append(nn.Sequential(ConvBnAct(input_channel, output_channel, 1)))
input_channel = output_channel
self.blocks = nn.Sequential(*stages)
# building last several layers
output_channel = 1280
self.global_pool = nn.AdaptiveAvgPool2d((1, 1))
self.conv_head = nn.Conv2d(input_channel, output_channel, 1, 1, 0, bias=True)
self.act2 = nn.ReLU(inplace=True)
self.classifier = nn.Linear(output_channel, num_classes)
def forward(self, x):
x = self.conv_stem(x)
x = self.bn1(x)
x = self.act1(x)
x = self.blocks(x)
x = self.global_pool(x)
x = self.conv_head(x)
x = self.act2(x)
x = x.view(x.size(0), -1)
if self.dropout > 0.:
x = F.dropout(x, p=self.dropout, training=self.training)
x = self.classifier(x)
return x
def ghostnet(**kwargs):
"""
Constructs a GhostNet model
"""
cfgs = [
# k, t, c, SE, s
# stage1
[[3, 16, 16, 0, 1]],
# stage2
[[3, 48, 24, 0, 2]],
[[3, 72, 24, 0, 1]],
# stage3
[[5, 72, 40, 0.25, 2]],
[[5, 120, 40, 0.25, 1]],
# stage4
[[3, 240, 80, 0, 2]],
[[3, 200, 80, 0, 1],
[3, 184, 80, 0, 1],
[3, 184, 80, 0, 1],
[3, 480, 112, 0.25, 1],
[3, 672, 112, 0.25, 1]
],
# stage5
[[5, 672, 160, 0.25, 2]],
[[5, 960, 160, 0, 1],
[5, 960, 160, 0.25, 1],
[5, 960, 160, 0, 1],
[5, 960, 160, 0.25, 1]
]
]
return GhostNet(cfgs, **kwargs)
if __name__=='__main__':
model = ghostnet()
model.eval()
print(model)
input = torch.randn(32,3,320,256)
y = model(input)
print(y.size())网络结构:
GhostNet(
(conv_stem): Conv2d(3, 16, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act1): ReLU(inplace=True)
(blocks): Sequential(
(0): Sequential(
(0): GhostBottleneck(
(ghost1): GhostModule(
(primary_conv): Sequential(
(0): Conv2d(16, 8, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(8, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(cheap_operation): Sequential(
(0): Conv2d(8, 8, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=8, bias=False)
(1): BatchNorm2d(8, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
)
(ghost2): GhostModule(
(primary_conv): Sequential(
(0): Conv2d(16, 8, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(8, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
(cheap_operation): Sequential(
(0): Conv2d(8, 8, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=8, bias=False)
(1): BatchNorm2d(8, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
)
(shortcut): Sequential()
)
)
(1): Sequential(
(0): GhostBottleneck(
(ghost1): GhostModule(
(primary_conv): Sequential(
(0): Conv2d(16, 24, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(24, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(cheap_operation): Sequential(
(0): Conv2d(24, 24, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=24, bias=False)
(1): BatchNorm2d(24, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
)
(conv_dw): Conv2d(48, 48, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=48, bias=False)
(bn_dw): BatchNorm2d(48, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(ghost2): GhostModule(
(primary_conv): Sequential(
(0): Conv2d(48, 12, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(12, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
(cheap_operation): Sequential(
(0): Conv2d(12, 12, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=12, bias=False)
(1): BatchNorm2d(12, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
)
(shortcut): Sequential(
(0): Conv2d(16, 16, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=16, bias=False)
(1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Conv2d(16, 24, kernel_size=(1, 1), stride=(1, 1), bias=False)
(3): BatchNorm2d(24, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(2): Sequential(
(0): GhostBottleneck(
(ghost1): GhostModule(
(primary_conv): Sequential(
(0): Conv2d(24, 36, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(36, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(cheap_operation): Sequential(
(0): Conv2d(36, 36, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=36, bias=False)
(1): BatchNorm2d(36, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
)
(ghost2): GhostModule(
(primary_conv): Sequential(
(0): Conv2d(72, 12, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(12, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
(cheap_operation): Sequential(
(0): Conv2d(12, 12, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=12, bias=False)
(1): BatchNorm2d(12, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
)
(shortcut): Sequential()
)
)
(3): Sequential(
(0): GhostBottleneck(
(ghost1): GhostModule(
(primary_conv): Sequential(
(0): Conv2d(24, 36, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(36, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(cheap_operation): Sequential(
(0): Conv2d(36, 36, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=36, bias=False)
(1): BatchNorm2d(36, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
)
(conv_dw): Conv2d(72, 72, kernel_size=(5, 5), stride=(2, 2), padding=(2, 2), groups=72, bias=False)
(bn_dw): BatchNorm2d(72, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(se): SqueezeExcite(
(avg_pool): AdaptiveAvgPool2d(output_size=1)
(conv_reduce): Conv2d(72, 20, kernel_size=(1, 1), stride=(1, 1))
(act1): ReLU(inplace=True)
(conv_expand): Conv2d(20, 72, kernel_size=(1, 1), stride=(1, 1))
)
(ghost2): GhostModule(
(primary_conv): Sequential(
(0): Conv2d(72, 20, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(20, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
(cheap_operation): Sequential(
(0): Conv2d(20, 20, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=20, bias=False)
(1): BatchNorm2d(20, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
)
(shortcut): Sequential(
(0): Conv2d(24, 24, kernel_size=(5, 5), stride=(2, 2), padding=(2, 2), groups=24, bias=False)
(1): BatchNorm2d(24, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Conv2d(24, 40, kernel_size=(1, 1), stride=(1, 1), bias=False)
(3): BatchNorm2d(40, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(4): Sequential(
(0): GhostBottleneck(
(ghost1): GhostModule(
(primary_conv): Sequential(
(0): Conv2d(40, 60, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(60, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(cheap_operation): Sequential(
(0): Conv2d(60, 60, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=60, bias=False)
(1): BatchNorm2d(60, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
)
(se): SqueezeExcite(
(avg_pool): AdaptiveAvgPool2d(output_size=1)
(conv_reduce): Conv2d(120, 32, kernel_size=(1, 1), stride=(1, 1))
(act1): ReLU(inplace=True)
(conv_expand): Conv2d(32, 120, kernel_size=(1, 1), stride=(1, 1))
)
(ghost2): GhostModule(
(primary_conv): Sequential(
(0): Conv2d(120, 20, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(20, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
(cheap_operation): Sequential(
(0): Conv2d(20, 20, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=20, bias=False)
(1): BatchNorm2d(20, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
)
(shortcut): Sequential()
)
)
(5): Sequential(
(0): GhostBottleneck(
(ghost1): GhostModule(
(primary_conv): Sequential(
(0): Conv2d(40, 120, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(120, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(cheap_operation): Sequential(
(0): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=120, bias=False)
(1): BatchNorm2d(120, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
)
(conv_dw): Conv2d(240, 240, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=240, bias=False)
(bn_dw): BatchNorm2d(240, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(ghost2): GhostModule(
(primary_conv): Sequential(
(0): Conv2d(240, 40, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(40, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
(cheap_operation): Sequential(
(0): Conv2d(40, 40, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=40, bias=False)
(1): BatchNorm2d(40, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
)
(shortcut): Sequential(
(0): Conv2d(40, 40, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=40, bias=False)
(1): BatchNorm2d(40, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Conv2d(40, 80, kernel_size=(1, 1), stride=(1, 1), bias=False)
(3): BatchNorm2d(80, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(6): Sequential(
(0): GhostBottleneck(
(ghost1): GhostModule(
(primary_conv): Sequential(
(0): Conv2d(80, 100, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(100, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(cheap_operation): Sequential(
(0): Conv2d(100, 100, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=100, bias=False)
(1): BatchNorm2d(100, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
)
(ghost2): GhostModule(
(primary_conv): Sequential(
(0): Conv2d(200, 40, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(40, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
(cheap_operation): Sequential(
(0): Conv2d(40, 40, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=40, bias=False)
(1): BatchNorm2d(40, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
)
(shortcut): Sequential()
)
(1): GhostBottleneck(
(ghost1): GhostModule(
(primary_conv): Sequential(
(0): Conv2d(80, 92, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(92, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(cheap_operation): Sequential(
(0): Conv2d(92, 92, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=92, bias=False)
(1): BatchNorm2d(92, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
)
(ghost2): GhostModule(
(primary_conv): Sequential(
(0): Conv2d(184, 40, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(40, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
(cheap_operation): Sequential(
(0): Conv2d(40, 40, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=40, bias=False)
(1): BatchNorm2d(40, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
)
(shortcut): Sequential()
)
(2): GhostBottleneck(
(ghost1): GhostModule(
(primary_conv): Sequential(
(0): Conv2d(80, 92, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(92, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(cheap_operation): Sequential(
(0): Conv2d(92, 92, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=92, bias=False)
(1): BatchNorm2d(92, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
)
(ghost2): GhostModule(
(primary_conv): Sequential(
(0): Conv2d(184, 40, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(40, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
(cheap_operation): Sequential(
(0): Conv2d(40, 40, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=40, bias=False)
(1): BatchNorm2d(40, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
)
(shortcut): Sequential()
)
(3): GhostBottleneck(
(ghost1): GhostModule(
(primary_conv): Sequential(
(0): Conv2d(80, 240, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(240, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(cheap_operation): Sequential(
(0): Conv2d(240, 240, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=240, bias=False)
(1): BatchNorm2d(240, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
)
(se): SqueezeExcite(
(avg_pool): AdaptiveAvgPool2d(output_size=1)
(conv_reduce): Conv2d(480, 120, kernel_size=(1, 1), stride=(1, 1))
(act1): ReLU(inplace=True)
(conv_expand): Conv2d(120, 480, kernel_size=(1, 1), stride=(1, 1))
)
(ghost2): GhostModule(
(primary_conv): Sequential(
(0): Conv2d(480, 56, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(56, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
(cheap_operation): Sequential(
(0): Conv2d(56, 56, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=56, bias=False)
(1): BatchNorm2d(56, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
)
(shortcut): Sequential(
(0): Conv2d(80, 80, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=80, bias=False)
(1): BatchNorm2d(80, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Conv2d(80, 112, kernel_size=(1, 1), stride=(1, 1), bias=False)
(3): BatchNorm2d(112, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(4): GhostBottleneck(
(ghost1): GhostModule(
(primary_conv): Sequential(
(0): Conv2d(112, 336, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(336, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(cheap_operation): Sequential(
(0): Conv2d(336, 336, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=336, bias=False)
(1): BatchNorm2d(336, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
)
(se): SqueezeExcite(
(avg_pool): AdaptiveAvgPool2d(output_size=1)
(conv_reduce): Conv2d(672, 168, kernel_size=(1, 1), stride=(1, 1))
(act1): ReLU(inplace=True)
(conv_expand): Conv2d(168, 672, kernel_size=(1, 1), stride=(1, 1))
)
(ghost2): GhostModule(
(primary_conv): Sequential(
(0): Conv2d(672, 56, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(56, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
(cheap_operation): Sequential(
(0): Conv2d(56, 56, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=56, bias=False)
(1): BatchNorm2d(56, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
)
(shortcut): Sequential()
)
)
(7): Sequential(
(0): GhostBottleneck(
(ghost1): GhostModule(
(primary_conv): Sequential(
(0): Conv2d(112, 336, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(336, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(cheap_operation): Sequential(
(0): Conv2d(336, 336, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=336, bias=False)
(1): BatchNorm2d(336, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
)
(conv_dw): Conv2d(672, 672, kernel_size=(5, 5), stride=(2, 2), padding=(2, 2), groups=672, bias=False)
(bn_dw): BatchNorm2d(672, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(se): SqueezeExcite(
(avg_pool): AdaptiveAvgPool2d(output_size=1)
(conv_reduce): Conv2d(672, 168, kernel_size=(1, 1), stride=(1, 1))
(act1): ReLU(inplace=True)
(conv_expand): Conv2d(168, 672, kernel_size=(1, 1), stride=(1, 1))
)
(ghost2): GhostModule(
(primary_conv): Sequential(
(0): Conv2d(672, 80, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(80, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
(cheap_operation): Sequential(
(0): Conv2d(80, 80, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=80, bias=False)
(1): BatchNorm2d(80, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
)
(shortcut): Sequential(
(0): Conv2d(112, 112, kernel_size=(5, 5), stride=(2, 2), padding=(2, 2), groups=112, bias=False)
(1): BatchNorm2d(112, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Conv2d(112, 160, kernel_size=(1, 1), stride=(1, 1), bias=False)
(3): BatchNorm2d(160, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(8): Sequential(
(0): GhostBottleneck(
(ghost1): GhostModule(
(primary_conv): Sequential(
(0): Conv2d(160, 480, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(480, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(cheap_operation): Sequential(
(0): Conv2d(480, 480, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=480, bias=False)
(1): BatchNorm2d(480, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
)
(ghost2): GhostModule(
(primary_conv): Sequential(
(0): Conv2d(960, 80, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(80, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
(cheap_operation): Sequential(
(0): Conv2d(80, 80, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=80, bias=False)
(1): BatchNorm2d(80, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
)
(shortcut): Sequential()
)
(1): GhostBottleneck(
(ghost1): GhostModule(
(primary_conv): Sequential(
(0): Conv2d(160, 480, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(480, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(cheap_operation): Sequential(
(0): Conv2d(480, 480, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=480, bias=False)
(1): BatchNorm2d(480, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
)
(se): SqueezeExcite(
(avg_pool): AdaptiveAvgPool2d(output_size=1)
(conv_reduce): Conv2d(960, 240, kernel_size=(1, 1), stride=(1, 1))
(act1): ReLU(inplace=True)
(conv_expand): Conv2d(240, 960, kernel_size=(1, 1), stride=(1, 1))
)
(ghost2): GhostModule(
(primary_conv): Sequential(
(0): Conv2d(960, 80, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(80, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
(cheap_operation): Sequential(
(0): Conv2d(80, 80, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=80, bias=False)
(1): BatchNorm2d(80, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
)
(shortcut): Sequential()
)
(2): GhostBottleneck(
(ghost1): GhostModule(
(primary_conv): Sequential(
(0): Conv2d(160, 480, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(480, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(cheap_operation): Sequential(
(0): Conv2d(480, 480, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=480, bias=False)
(1): BatchNorm2d(480, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
)
(ghost2): GhostModule(
(primary_conv): Sequential(
(0): Conv2d(960, 80, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(80, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
(cheap_operation): Sequential(
(0): Conv2d(80, 80, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=80, bias=False)
(1): BatchNorm2d(80, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
)
(shortcut): Sequential()
)
(3): GhostBottleneck(
(ghost1): GhostModule(
(primary_conv): Sequential(
(0): Conv2d(160, 480, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(480, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(cheap_operation): Sequential(
(0): Conv2d(480, 480, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=480, bias=False)
(1): BatchNorm2d(480, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
)
(se): SqueezeExcite(
(avg_pool): AdaptiveAvgPool2d(output_size=1)
(conv_reduce): Conv2d(960, 240, kernel_size=(1, 1), stride=(1, 1))
(act1): ReLU(inplace=True)
(conv_expand): Conv2d(240, 960, kernel_size=(1, 1), stride=(1, 1))
)
(ghost2): GhostModule(
(primary_conv): Sequential(
(0): Conv2d(960, 80, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(80, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
(cheap_operation): Sequential(
(0): Conv2d(80, 80, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=80, bias=False)
(1): BatchNorm2d(80, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Sequential()
)
)
(shortcut): Sequential()
)
)
(9): Sequential(
(0): ConvBnAct(
(conv): Conv2d(160, 960, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(960, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act1): ReLU(inplace=True)
)
)
)
(global_pool): AdaptiveAvgPool2d(output_size=(1, 1))
(conv_head): Conv2d(960, 1280, kernel_size=(1, 1), stride=(1, 1))
(act2): ReLU(inplace=True)
(classifier): Linear(in_features=1280, out_features=1000, bias=True)
)















 999
999











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











