







yolov5源码地址https://github.com/ultralytics/yolov5
在yolov5开发部署中遇到了一点坑,在这里分享一下,希望能帮助到大家
首先官方给出了onnx的部署文件,如何部署jit能,我们从源码中就可以看出,yolov5的权重是包含模型在内的,但是比葫芦画瓢还是可以可以的。
(1)onnx部署
import argparse
import onnx
from yolov5_ultralytics.models.common import *
from utils import google_utils
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default='D:/py/FaceRecognition/weights/last.pt', help='weights path')
parser.add_argument('--img-size', nargs='+', type=int, default=[640, 640], help='image size')
parser.add_argument('--batch-size', type=int, default=1, help='batch size')
opt = parser.parse_args()
# print(opt)
# Parameters
f = opt.weights.replace('.pt', '.onnx') # onnx filename
img = torch.zeros((opt.batch_size, 3, *opt.img_size)) # image size, (1, 3, 320, 192) iDetection
# Load pytorch model
google_utils.attempt_download(opt.weights)
model = torch.load(opt.weights, map_location=torch.device('cpu'))['model'].float()
model.eval()
model.fuse()
# Export to onnx
model.model[-1].export = True # set Detect() layer export=True
_ = model(img) # dry run
torch.onnx.export(model, img, f, verbose=False, opset_version=11, input_names=['images'],
output_names=['output']) # output_names=['classes', 'boxes']
# Check onnx model
model = onnx.load(f) # load onnx model
onnx.checker.check_model(model) # check onnx model
print(onnx.helper.printable_graph(model.graph)) # print a human readable representation of the graph
print('Export complete. ONNX model saved to %s\nView with https://github.com/lutzroeder/netron' % f)
(2)jit部署
import argparse
from torch import jit
import torch
from yolov5_ultralytics.models.common import *
from utils import google_utils
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default='weights/last.pt', help='weights path')
parser.add_argument('--img-size', nargs='+', type=int, default=[640, 640], help='image size')
parser.add_argument('--batch-size', type=int, default=1, help='batch size')
opt = parser.parse_args()
print(opt)
# Parameters
f = opt.weights.replace('.pt', '.jit') # jit filename
img = torch.zeros((opt.batch_size, 3, *opt.img_size)) # image size, (1, 3, 320, 192) iDetection
# Load pytorch model
google_utils.attempt_download(opt.weights)
model = torch.load(opt.weights, map_location=torch.device('cpu'))['model'].float()
model.eval()
# model.fuse()
model(img) #此处如果不加可能会报错,内部机制,具体问题不明
# Export to jit
# model.model[-1].export = True # set Detect() layer export=True
script_model = torch.jit.trace(model, img)
script_model.save(f)
# _ = model(img) # dry run
踩坑记录
部署onnx没什么问题,可是在生成jit部署的时候会报错
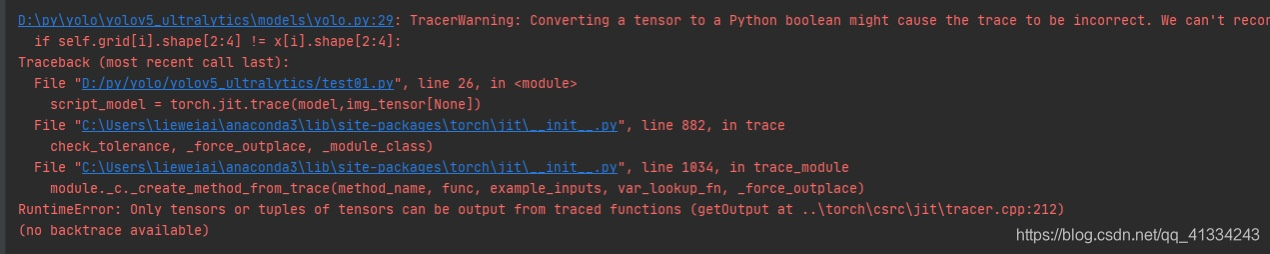
查看了输出类型,没啥问题呀,当碰到这种情况时,不妨试一下环境有没有问题,兼容性有没有问题,查了一下yolov5的环境要求,都是满足的,而且跑其他项目都是正常的,可问题就是出在了环境上,不试不知道,有些时候不能一味相信官方的要求,不同人的电脑、运行环境版本等都各有差异。
不多说了,直接上我的解决方案:
关于yolov5部署jit的问题(已解决):
提高pytorch版本>=1.5.0
提高torchversion版本>=0.6.0
提高scipy版本>=1.5.0
注意版本对应问题
我的版本信息如下:
cuda10.2、python3.7.6
选择pytorch版本:cu102/torch-1.5.1-cp37-cp37m-win_amd64.whl
选择torchversion版本:cu102/torchvision-0.6.1-cp37-cp37m-win_amd64.whl
选择scipy版本:scipy-1.5.1-cp37-cp37m-win_amd64.whl
yolov5部署pytorch环境建议在1.5版本以上,同时torchversion这些版本也要一一对应,其他版本的兼容性我没测试过,我原本pytorch1.4会报上述错误,我把版本升到1.5.1后成功解决.














 586
586











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









