






《Invariance Matters: Exemplar Memory for Domain Adaptive Person Re-identification》论文翻译
写在前面:最近读了一篇英文文献,读起来比较费力,就花了一点时间翻译了一下,在此共享一下。水平有限,其中有翻译错误,请大家指正!谢谢。
摘要:
本文研究了域自适应行人重识别(re_id)问题:从一个有标签的源域和一个无标签的目标域中学习了一个模型。传统的方法主要是减少源域和目标域之间的特征分布差距。然而,这些研究大多忽略了目标域的域内变化,这些变化包含了影响目标域测试性能的关键因素。本文全面研究了目标域的域内变化,提出了re-ID模型w.r.t的三种基本不变性,即样本不变性、相机不变性和邻域不变性。为了实现这一目标,引入了一个样本存储器来存储目标域的特征,并适应这三个不变性。存储器允许我们在全局训练批上强制执行不变性约束,而不会显著增加计算成本。实验证明,这三个不变性和所提出的存储器对于一个有效的域自适应系统是必不可少的。在三个re-ID域上的实验结果表明,我们的域自适应精度大大优于现有技术。代码位于:https://github.com/zhunzhong07/ECN
1、 简介
行人重识别 (re-ID)[38, 41, 31, 14]是一种跨相机图像检索任务,其目的是在数据库中找到给定查询的匹配人。尽管reid领域的监督学习取得了令人印象深刻的成就,但是学习一个能很好地推广到目标领域的reid模型仍然是一个挑战[7,29]。在目标域中获得足够的未标记数据相对容易,但是在没有注释的情况下学习深入的re-ID模型是困难的。本文研究了无监督域自适应问题(UDA),即有标记的源域和无标记的目标域。我们的目标是学习目标集的区别表示。
在传统的UDA设置中,大多数方法都是在封闭集的场景下开发的,假设源和目标域完全共享相同的类[27,10]。但是,这个假设不能应用于UDA中的行人重识别,因为来自这两个域的类是完全不同的。行人重识别是一个开放集问题[3],它比封闭集问题更具挑战性。在处理行人重识别过程中,不应该像现有的闭集UDA方法那样直接对齐源和目标域的分布。相反,我们应该学会将看不见的类与目标域很好地分离。
最近的先进方法主要通过在图像级[7,30,1]或属性特征级[29,16]上缩小源域和目标域之间的差距来解决行人重识别中的UDA问题。这些方法只考虑源域和目标域之间的整体域间差异,而忽略目标域的域内差异。事实上,目标的差异是影响行人重新识别的重要因素。在本研究中,我们明确地考虑了目标域内的差异,并研究了三个潜在的不变性,即样本不变性、相机不变性和邻域不变性,如下所述。
首先,给定一个在带标签的数据集上训练的深层re-ID模型,我们观察到排名最高的检索结果总是更可能在视觉上与待查询相关。在图像分类[33]中也观察到类似的现象。这说明深层re-ID模型从视觉数据中学习了表层相似性信息,而不是语义信息。在现实中,每个人的样本都可能与其他的样本有很大的不同,即使是属于同一身份。因此,通过学习区分个体样本,reid模型就有可能捕获人的表层表征。在此基础上,我们引入了样本不变性,通过强制每个人的样本离自己的自己的样本近,离他人的样本远的方法来学习未标记目标数据的表层相似性。其次,相机风格变化[44]作为行人重识别的关键影响因素,可能会显著改变人的外观。不过,摄像机转移所产生的人的形象仍然属于最初的身份。考虑到这一点,我们实施相机不变性[43],前提是一个人的图像和相应的相机风格的传输图像应该彼此接近。第三,假设我们得到了一个在源和目标域上训练过的适当的reID模型。目标范例和它在目标集中的近邻可能具有相同的标识。考虑到这一特点,我们通过鼓励范例与其对应的可靠邻居彼此接近来提出邻域不变性。这有助于我们学习一个更具鲁棒性的模型来克服目标域的图像变化,比如姿态、视图和背景变化。这三种不变量的例子如图1所示。

在此基础上,我们提出了一种新的无监督域自适应方法来解决行人重识别问题。在训练过程中,我们在网络中引入了一个样本存储器,来存储目标集中每个范例的最新表示。这种存储器使我们能够在整个/全局目标训练批处理上执行不变性约束,而不是在小批处理上。这有助于我们在网络优化过程中有效地执行目标域的不变性学习。
综上所述,本工作的贡献有三方面:
•我们全面地研究了目标域的三个基本不变量。实验表明,这些特性对于提高re-ID模型的可转移能力是必不可少的。
•我们提出了一个存储器模块来有效地在系统中执行这三个不变性属性。存储器可以帮助我们利用样本在全局训练集上的相似性。通过存储器,只需要非常有限的额外计算成本和GPU内存,就可以显著提高准确性。
•我们的方法在三个大型数据集上比最先进的UDA方法有更大的优势:market 1501, DukeMTMC-reID和MSMT17
2、 相关工作
**无监督域自适应。**一种有效的UDA寻址方法是通过对齐两个域之间的特征分布。这种对齐可以通过减少域之间的最大平均差异(MMD)[11]来实现[17,35],或者训练一个对抗的域分类器[2,27]来鼓励源域和目标域的特征变得不可区分。上述方法是在封闭集场景的假设下设计的,其中源域和目标域的类完全相同。然而,在实践中,有许多场景在目标域中存在未知的类。来自目标域的未知类样本不应该与源域对齐。该任务由Busto和Grall[3]引入,称为开放集域自适应。为了解决这个问题,Busto和Grall[3]开发了一种方法,通过丢弃未知类目标样本来学习从源域到目标域的映射。最近提出了一种对抗学习框架[22],用于在特征对齐时将目标样本分为已知类和未知类,并拒绝未知类。本文研究了基于目标域和源域类完全不同的UDA行人重识别问题。这是一个更具挑战性的开放集问题。
**无监督行人重识别。**依靠rich_lable数据和深度网络的成功,art监督方法在行人重识别方面取得了巨大的成就[14,26,39,25]。但是,在unseen dataset上测试时,性能可能会显著下降。为了解决这个问题,有几种方法使用带标记的源域来学习一个深层的re-ID模型作为初始化的特征提取器。然后,这些方法学习一个度量[36]或者在目标域上通过无监督聚类[9]来细化re-ID模型。然而,这些方法并没有利用带标签的源数据作为调节过程中有效的监督。为了克服以往的不足,提出了多种域自适应方法来同时适应带标记的源域和未带标记的目标域。这些方法主要是为了减少图像级[7,30,1]和属性特征级[29,16]数据集之间的域转移。尽管这些方法很有效,但在很大程度上忽略了目标域内的变化。最近,钟等[43]首先提出了一种学习目标域相机不变网络的HHL方法。然而,HHL忽略了靶区潜在的positive pairs。这可能导致reID模型对目标区域的其他变化很敏感,比如姿势和背景变化。
**与以往工作的区别。**事实上,这三种不变性和存储器模块已经在现有的工作中分别给出。然而,我们的工作与他们不同。样本不变性和存储器模块已经在自监督学习[33]、少镜头学习[23,28,32]和监督学习[34]中提出。然而,我们探讨了该思想在无监督域自适应和克服目标域变化方面的可行性。邻域不变性类似于深度关联学习(DAL)[4]。与DAL不同的是,我们设计了一个软分类损失来对齐top-k邻域,而不是计算相互的top-1邻域之间的triplet 损失。重要的是,与HHL[43]和DAL[4]相比,我们综合考虑了三个不变性约束。发现了这三种不变性之间的互利关系,这非常有意义。
3、 提出的方法
**准备。**在行人重识别的无监督域自适应(UDA)环境中,我们得到一个全标记的源域{Xs, Ys},包括Ns张人的图像。每个人的图像Xs,i与标识Ys,i相关联。源域的标识总数为M。此外,我们提供了一个不带标签的目标域Xt,包含Nt张人的图像。目标域的标签不可用。我们的目标是使用带标签的源域和不带标签的目标域学习可转移深层re-ID模型,使它在目标测试集上很好地推广。
3.1、框架概述
我们方法的框架如图2所示。在我们的模型中,使用ImageNet[6]上预训练的ResNet-50[12]作为主干。具体来说,我们将ResNet-50层保留到pool -5层作为基础网络,并在pool -5层之后增加一个4096维全卷积(FC)层。新的FC层命名为FC-4096,随后是批量正则化[13]、ReLU[19]、Dropout[24]和两个组件。第一个组件是一个分类模块,用于使用带标签的源数据进行监督学习。它有一个m维FC层(命名为FC-#id)和一个softmax激活函数。我们使用交叉熵损失来计算源域的损失。另一个组件是使用不带标签的目标数据进行不变性学习的样本存储器模块。样本存储器作为特征存储器,为每个目标图像保存FC-4096层的最新输出。通过估计小批目标样本与整批目标样本之间的相似性来计算目标域的不变性学习损失。
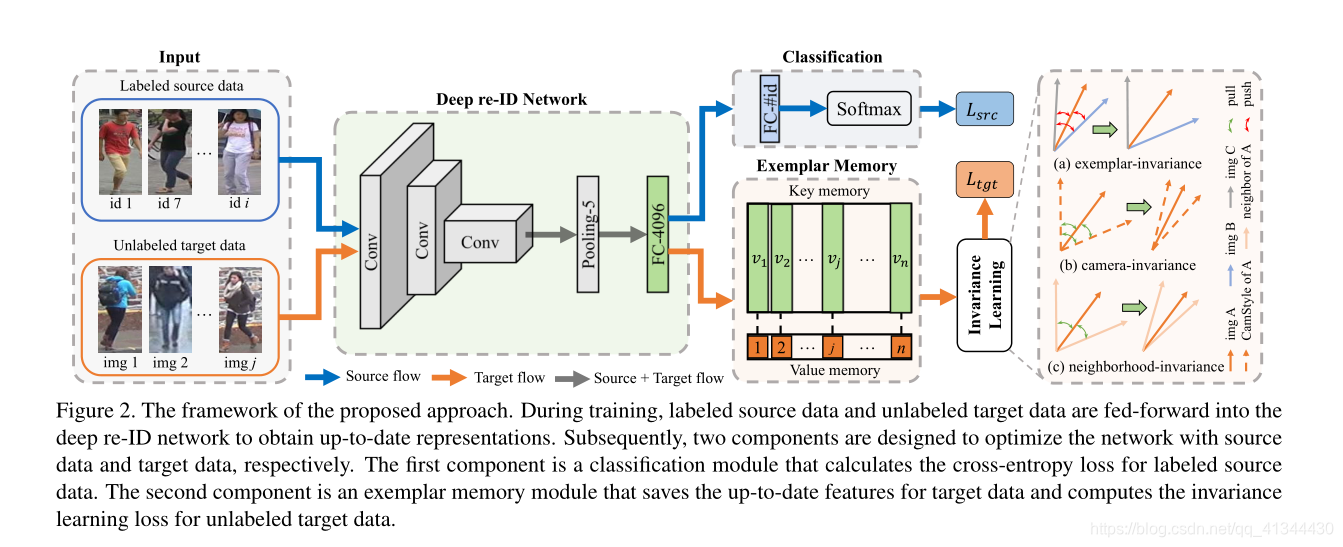
3.2、源域的监督学习
由于源图像的标识是可用的,我们将源域的训练过程视为一个分类问题[38]。交叉熵损失用于优化网络,公式为:
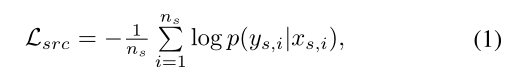
其中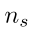 是一个训练批中的源图像的数量。
是一个训练批中的源图像的数量。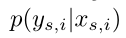 是源图像
是源图像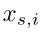 属于标识
属于标识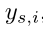 的预测概率,由分类模块得到。
的预测概率,由分类模块得到。
使用带标签的源数据训练的模型在相同的分布式测试集上可以获得较高的准确率,但当测试集与源域分布不同时,性能会严重下降。接下来,我们将介绍一种基于样本存储器的方法,通过在网络训练中考虑目标域的域内变化来克服这一问题。
3.3、样本存储器
为了提高网络对目标测试集的泛化能力,我们提出通过估计目标图像之间的相似性来对网络进行不变性学习。为了实现这一目标,我们首先构建一个样本存储器来存储所有目标图像的最新特征。样本存储器是一个键值结构[34],它具有键值存储器(K)和值存储器(V)。在样本存储器中,每个槽在K部分存储FC-4096的L2正则化特征,在V部分存储标签。对于包括Nt张图片的不带标签的目标数据,我们将每个图片实例视为一个单独的类别。因此,样本存储器包含Nt个槽,其中每个槽存储目标图像的特征和标签。在初始化过程中,我们将K存储器中所有特征的值初始化为零。为简单起见,我们将相应的索引指定为目标样本的标签,并将其存储在V存储器中。例如,将V存储器中第i个目标图片的类别赋值为![V[i] = i](https://img-blog.csdnimg.cn/20200611144600662.png) 。在整个训练过程中,V存储器中的标签是固定的。在每次训练迭代中,对于目标训练样本
。在整个训练过程中,V存储器中的标签是固定的。在每次训练迭代中,对于目标训练样本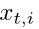 ,我们通过深度reID网络将其前馈,得到FC-4096的正则化特征
,我们通过深度reID网络将其前馈,得到FC-4096的正则化特征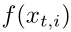 。在反向传播过程中,我们通过以下式子更新存储在K存储器中的训练样本
。在反向传播过程中,我们通过以下式子更新存储在K存储器中的训练样本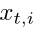 的特征。
的特征。
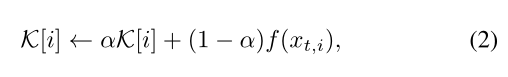
其中K[i]是图像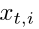 在第i个槽中的K存储器。超参数
在第i个槽中的K存储器。超参数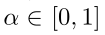 控制更新速率, K[i]通过
控制更新速率, K[i]通过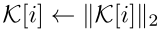 被L2正则化。
被L2正则化。
3.4、目标域的不变性学习
只用源域训练的深层re-ID模型通常对目标域的域内变化很敏感。这些变化是影响性能的关键因素。因此,在将knowledge从源域转移到目标域时,有必要考虑目标域的影像变化。在这项研究中,我们调查了UDA行人重识别目标数据的三个潜在不变性,即样本不变性,相机不变性,邻域不变性。
**样本不变性。**每个人的外表形象可能与他人非常不同,即使是同一个身份。换句话说,每个人的形象可以接近自己,而远离他人。因此,我们通过学习区分个体图像,在re-ID模型中增加了样本不变性。这允许re-ID模型捕获人的浅层表示。为了达到这个目的,我们将Nt张目标图片作为Nt个不同的类,并将每个图片划分为自己独特的类。对于给定的目标图像Xt,i, 我们首先计算存储在K存储器中的特征和Xt,i特征之间的余弦相似性。然后利用softmax函数计算Xt,i属于第i类的预测概率,
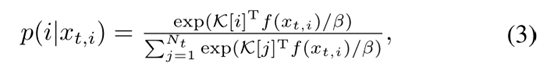
其中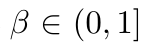 是平衡分布尺度的 temperature fact 。
是平衡分布尺度的 temperature fact 。
样本不变性的目标是最小化目标训练图像的negative log-likelihood,
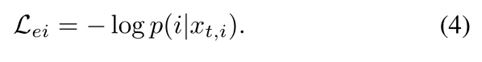
**相机不变性。**相机风格的变化是行人重识别的一个重要因素。在不同的摄像机下,一个人的形象可能会发生显著的变化。使用带标签的源数据训练的reid模型可以捕获源域的摄像机不变性,但可能会受到目标摄像机引起的图像变化的影响。因为这两个域的相机设置会有很大的不同。为了解决这一问题,我们提出在网络中设置目标域的相机不变性[43],前提是一幅图像和它的相机类型的传输对应图像应该是相近的。在本文中,由于在视频序列中采集人物图像时,容易获得相机id,因此我们假设每张图像的相机id是已知的。对于不带标签的目标数据,我们将每个摄像机视为一个风格域,采用StarGAN[5]训练目标域的相机风格(CamStyle)传输模型[44]。通过学习的CamStyle传输模型,每个从相机c采集的真实目标图像在保留原有身份的情况下,用其他相机风格的c - 1图像进行增强。C为目标域中的摄像机数量。
为了将相机不变性引入到模型中,我们认为每一个真实图像和它的风格转换副本共享相同的身份。因此,相机不变性的损失函数解释为:
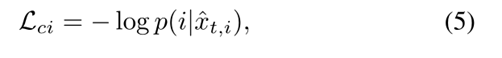
其中 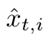 是从风格转换图像
是从风格转换图像 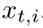 中随机选择的目标样本。这样就迫使同一样本的不同相机风格的图像相互靠近。
中随机选择的目标样本。这样就迫使同一样本的不同相机风格的图像相互靠近。
**邻域不变性。**对于每个目标图像,目标数据中可能存在多个正样本。如果我们能够在训练过程中利用这些正样本,就能够进一步提高reid模型在克服目标域变化时的鲁棒性。为了达到这个目标,我们首先计算f(Xt,i)和存储在键值存储器K中的特征之间的余弦相似度。然后,我们在K中找到Xt,i的k个最近邻,并定义他们的索引为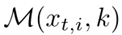 .k是
.k是 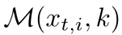 的大小,
的大小, 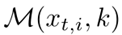 中最接近的一个是i。
中最接近的一个是i。
我们在假设目标图像Xt,i应该属于 中的候选类的前提下,将邻域不变性赋给网络,从而为Xt,i属于类j的概率赋权为,
中的候选类的前提下,将邻域不变性赋给网络,从而为Xt,i属于类j的概率赋权为,
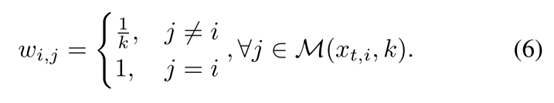
邻域不变性的目标表示为soft-label损失,
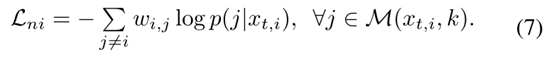
注意,为了区分样本不变性和邻域不变性,在等式7中Xt,i没有被分类到它自己的类中。
**不变性学习的整体损失。**综合考虑样本不变性、相机不变性和邻域不变性,不变性学习在目标训练图像上的整体损失可以写成:
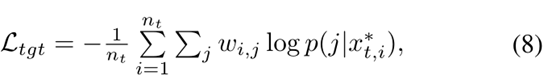
其中 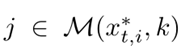 ,
,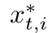 是从
是从  的集合中随机选择的图片。
的集合中随机选择的图片。 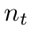 是训练批次中目标图像的数量。在等式8中,当i = j时,我们通过将
是训练批次中目标图像的数量。在等式8中,当i = j时,我们通过将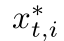 归类到它自己的类中,用样本不变学习和相机不变学习来优化网络。当i≠j时,通过引导
归类到它自己的类中,用样本不变学习和相机不变学习来优化网络。当i≠j时,通过引导 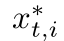 接近它在
接近它在 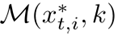 的邻居,用邻域不变学习优化网络。
的邻居,用邻域不变学习优化网络。
3.5、网络的最终损失
结合源域和目标域的损失,网络的最终损失为:
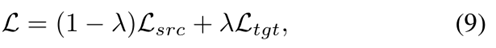
其中,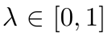 控制源损失和目标损失的重要性。为此,我们引入了一个用于UDA 行人重识别的损失函数,其中源域的损失旨在保持人的基本表示。此外,目标域的损失尝试从带标签的源域获取知识,并将目标域的不变性纳入到网络中。
控制源损失和目标损失的重要性。为此,我们引入了一个用于UDA 行人重识别的损失函数,其中源域的损失旨在保持人的基本表示。此外,目标域的损失尝试从带标签的源域获取知识,并将目标域的不变性纳入到网络中。
3.6、关于三个不变性的讨论
我们分析每种不变性的优缺点。样本不变性使每个样本彼此远离。扩大不同身份的样本之间的距离是有益的。然而,相同身份的样本也会因此相距很远,这对系统是有害的。相比之下,邻域不变性鼓励每个样本及其邻域彼此靠近。这有利于减少相同身份的样本之间的距离。然而,邻域不变性也可能拉近不同身份的图像,因为我们不能保证每个邻居与查询示例共享相同的标识。因此,在样本不变性和邻域不变性之间存在一个权衡,前者的目标是引导来自不同身份的范例远离,而后者鼓励相同身份的范例彼此靠近。相机不变性与样本不变性具有相似的效果,也导致样本及其相机样式的转移样本共享相同的表示。
剩下的部分以后有时间再翻译。















 494
494











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









