









数据驱动介绍
- 数据驱动即通过改变测试数据(即对测试数据进行参数化),来驱动测试的执行。在测试的过程中,我们经常会遇到这种场景:测试的步骤是一样的,只是使用数据不同,这种情况就可以使用数据驱动,从而实现了数据和代码的分离,减少了代码的冗余。
- 例如:
百度搜索的测试,我们需要执行以下测试用例
搜索电影
搜索热点新闻
DDT实现数据驱动
-
DDT介绍
ddt是“Data-Driven Tests”的缩写,是unittest中实现数据驱动的主要方式之一,它主要包括如下的装饰器:@ddt 标记测试类,支持DDT数据驱动 @data 标记测试用例,传递参数 @unpack 当@data中的参数是元组、列表时,用于分割序列中的元素 @file_data 标记测试用例,传递文件,支持yaml和json文件 -
DDT的使用前准备
安装ddt工具,并导包
安装ddt pip install ddt 导包 from unittest2 import ddt,data,unpack,file_data
3.使用DDT传递数据 — 直接传入参数
-
用例只有一个参数的情形:
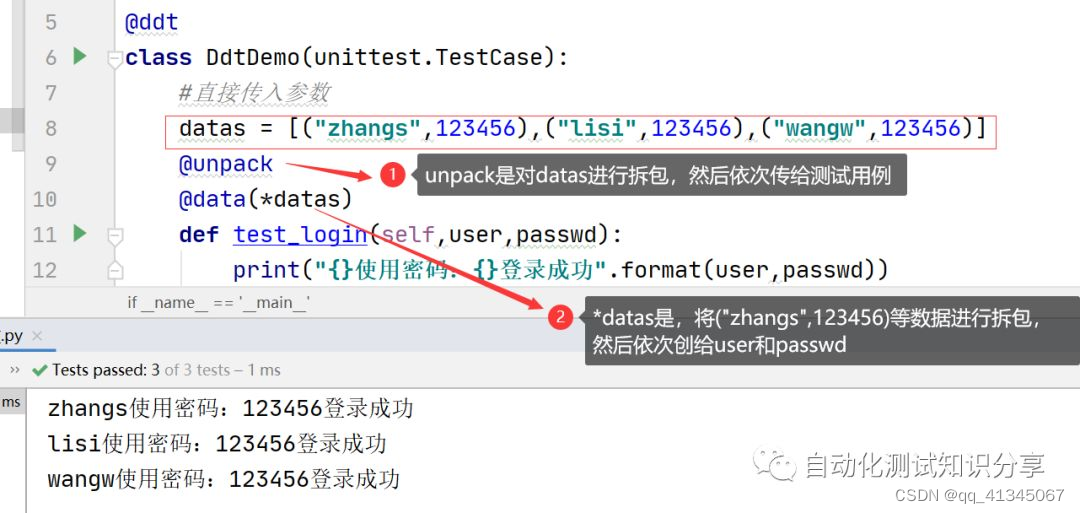
@ddt#在测试类前使用ddt修饰器class DdtDemo(unittest.TestCase):
直接传入参数@data(“zhangs”,“lisi”,“wangw”)
在用例前使用@data传参deftest_login(self,user):
用例只有一个参数:user print(“{}登录成功”.format(user))
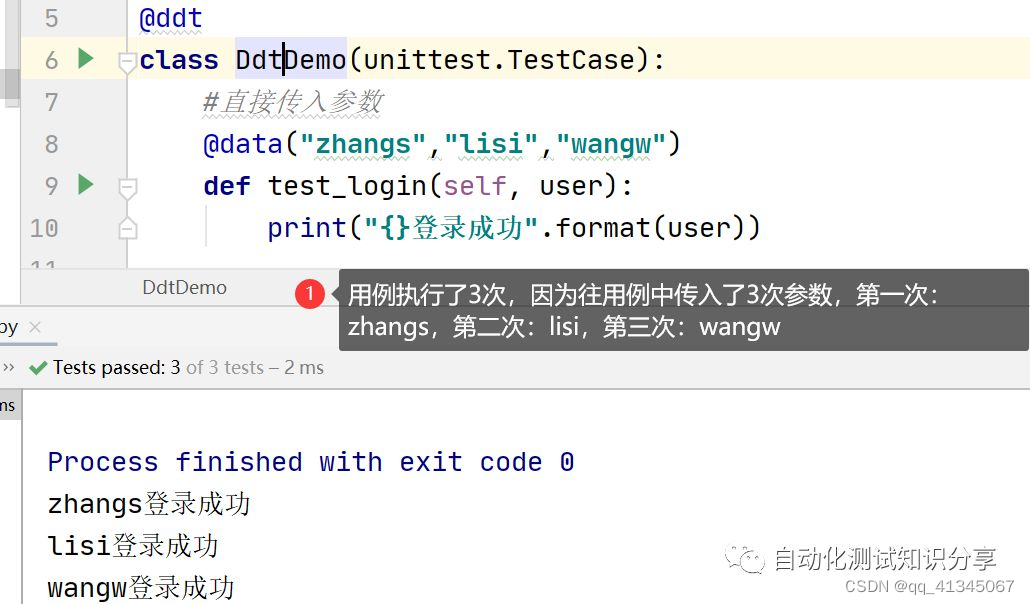
-
用例中有多个参数 — 必须使用@unpack
- 没有使用unpack的情形
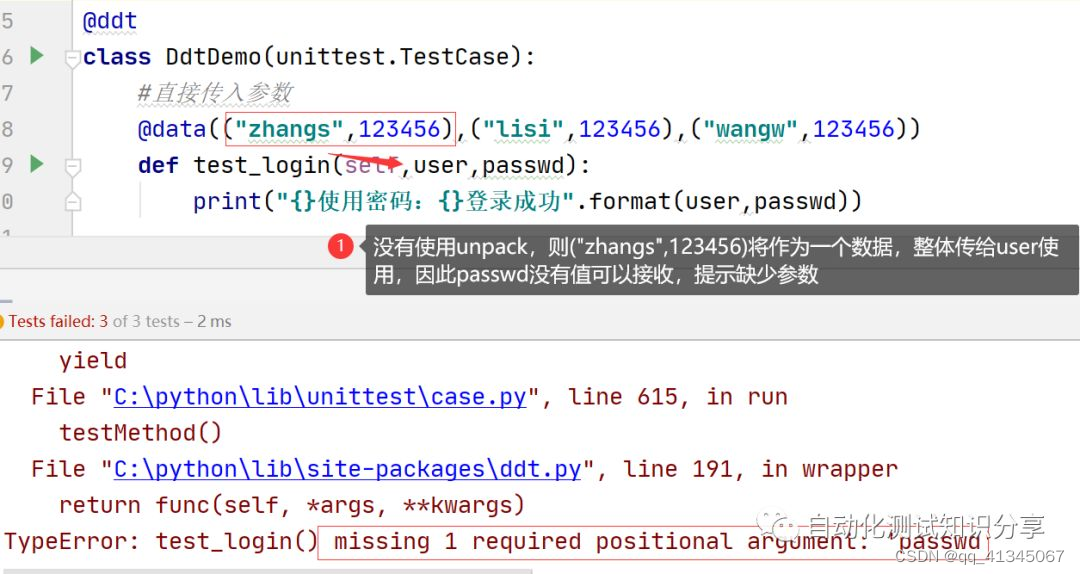
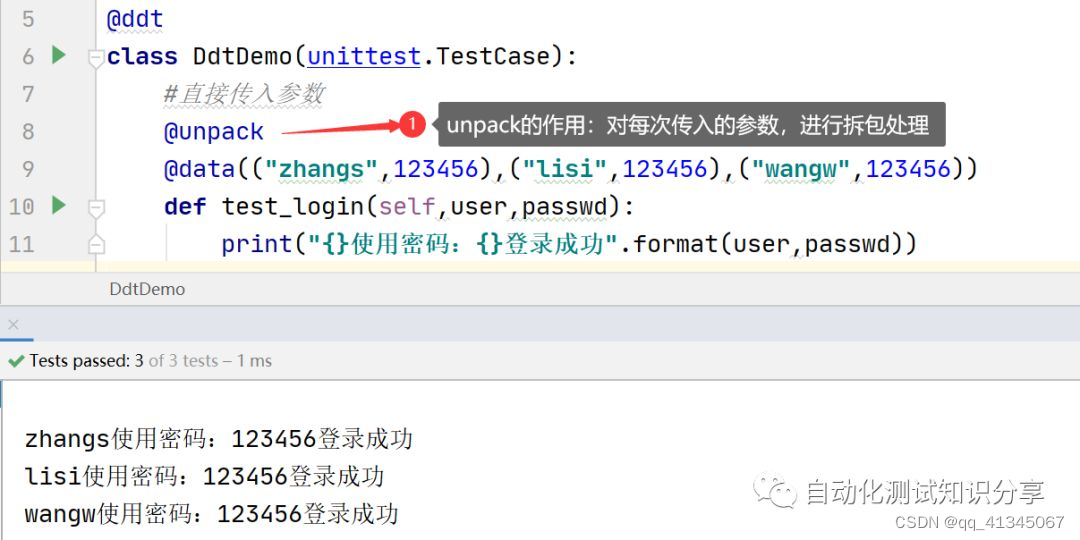
- 使用unpack对每次传入的参数(序列参数),进行拆包处理(即分割后在传给用例中对应的形参)
- 没有使用unpack的情形
-
传入一个序列(元组、列表)
- 传入序列时,必须使用*拆包,否则会将会整个数据作为一个整体传入
没有拆包时,如下:

- 传入时使用*拆包时,如下:
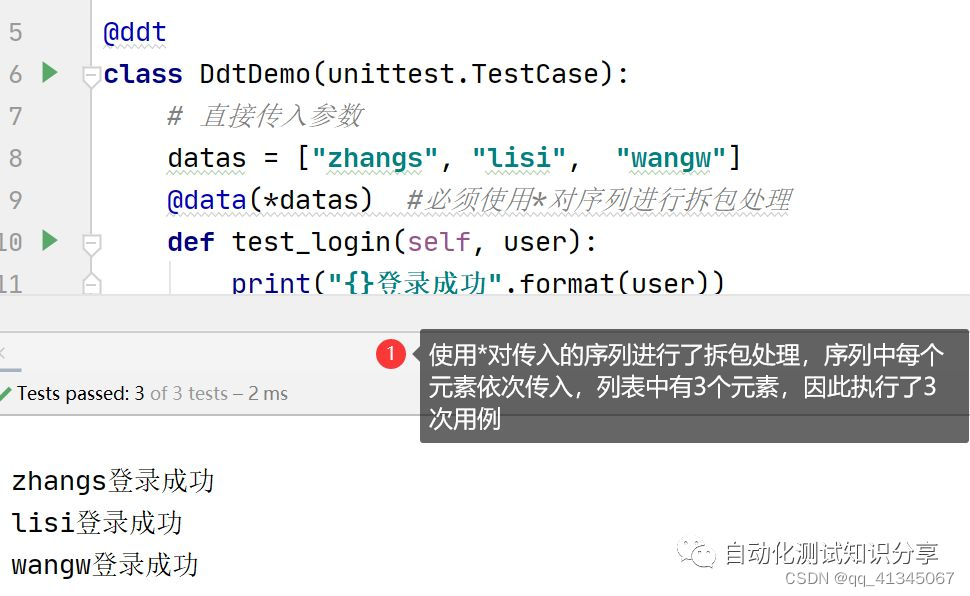
- 传入序列时,必须使用*拆包,否则会将会整个数据作为一个整体传入
-
@unpack和*的区别
很多初学者一直弄不清楚*和@unpack修饰器的区别,其实很简单: *是对传入的序列进行拆包,拆包后将元素依次传给测试用例,表示用例执行的次数 @unpack是对每次传入用例的参数进行拆包,拆包后将元素依次传给用例的每个参数,表示执行每次用例时的参数 -
举例
4.使用DDT传递数据— 传入文件
使用@file_data修饰器可以直接读取文件,支持yaml和json两种格式
-
一个形参的情形
yaml文件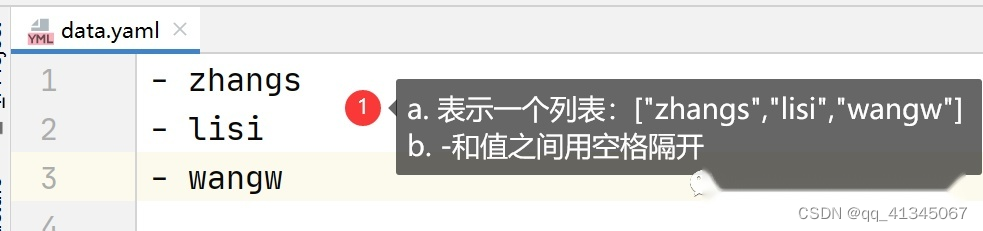
代码实例

-
多个形参的情形
注意事项:yaml文件中key和用例形参名必须保持一致
yaml文件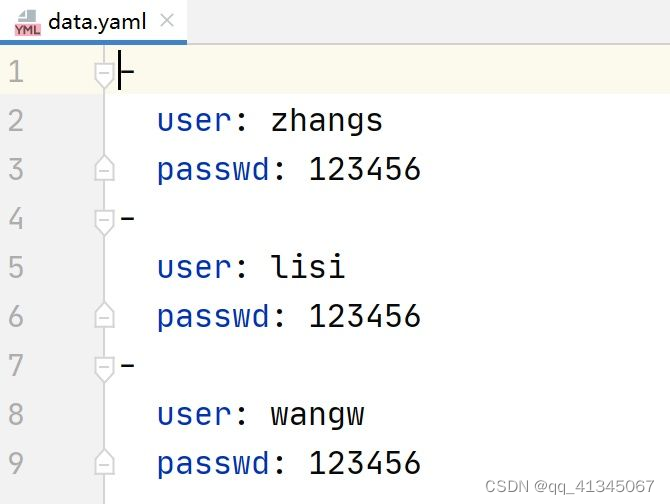
代码实例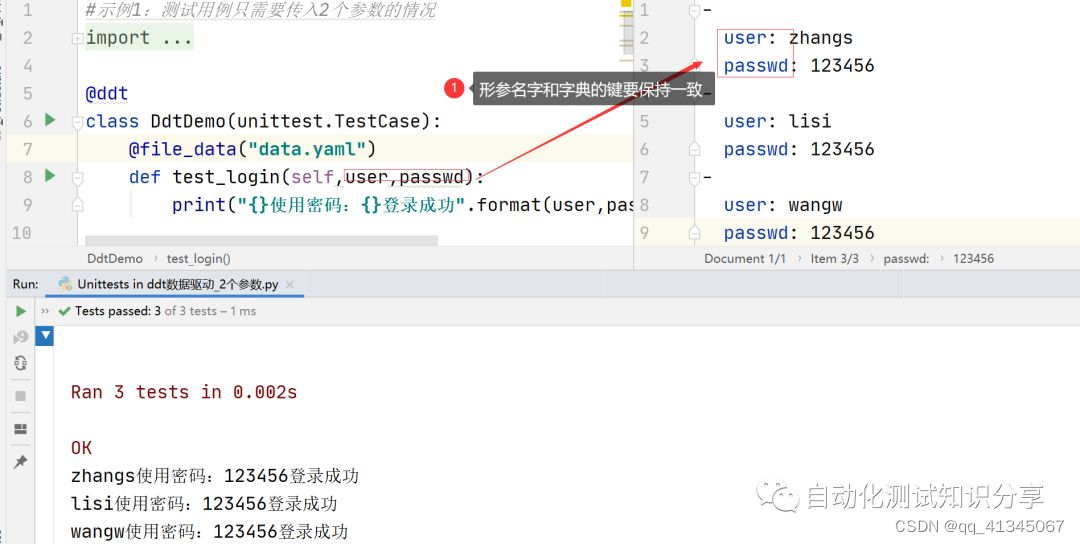














 1548
1548











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









