






在搜索鸢尾花数据集时看到一篇基于鸢尾花数据集的文章,其中数据可视化部分做的很好,所以自己在此复现一下,原文链接如下:https://www.jianshu.com/p/52b86c774b0b
一:导入需要的库
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
二:读取数据,查看数据集的基本信息
data = pd.read_csv('iris.data', header = None)
data.head()查看前5行数据:
0 1 2 3 4
0 5.1 3.5 1.4 0.2 Iris-setosa
1 4.9 3.0 1.4 0.2 Iris-setosa
2 4.7 3.2 1.3 0.2 Iris-setosa
3 4.6 3.1 1.5 0.2 Iris-setosa
4 5.0 3.6 1.4 0.2 Iris-setosa查看数据集的总体信息:
data.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 150 entries, 0 to 149
Data columns (total 5 columns):
0 150 non-null float64
1 150 non-null float64
2 150 non-null float64
3 150 non-null float64
4 150 non-null object
dtypes: float64(4), object(1)
memory usage: 5.9+ KB四个属性值,一个标签属性,没有缺失值
查看数据集的统计信息:
data.describe() 0 1 2 3
count 150.000000 150.000000 150.000000 150.000000
mean 5.843333 3.054000 3.758667 1.198667
std 0.828066 0.433594 1.764420 0.763161
min 4.300000 2.000000 1.000000 0.100000
25% 5.100000 2.800000 1.600000 0.300000
50% 5.800000 3.000000 4.350000 1.300000
75% 6.400000 3.300000 5.100000 1.800000
max 7.900000 4.400000 6.900000 2.500000
三:绘制小提琴图,观察数据分布
设置颜色
antV = ['#1890FF', '#2FC25B', '#FACC14', '#223273', '#8543E0', '#13C2C2', '#3436C7', '#F04864']以特征为单位分离数据:
分离SepalLengthCm数据
data_setosa0 = data[data[4]=='Iris-setosa'][0]
data_versicolor0 = data[data[4]=='Iris-versicolor'][0]
data_virginica0 = data[data[4]=='Iris-virginica'][0]data_SepalLengthCm = pd.DataFrame({'setosa':data_setosa0, 'versicolor':data_versicolor0, 'virginica':data_virginica0})分离SepalWidthCm数据
data_setosa1 = data[data[4]=='Iris-setosa'][1]
data_versicolor1 = data[data[4]=='Iris-versicolor'][1]
data_virginica1 = data[data[4]=='Iris-virginica'][1]data_SepalWidthCm = pd.DataFrame({'setosa':data_setosa1, 'versicolor':data_versicolor1, 'virginica':data_virginica1})分离PetalLengthCm数据
data_setosa2 = data[data[4]=='Iris-setosa'][2]
data_versicolor2 = data[data[4]=='Iris-versicolor'][2]
data_virginica2 = data[data[4]=='Iris-virginica'][2]data_PetalLengthCm = pd.DataFrame({'setosa':data_setosa2, 'versicolor':data_versicolor2, 'virginica':data_virginica2})分离PetalWidthCm数据
data_setosa3 = data[data[4]=='Iris-setosa'][3]
data_versicolor3 = data[data[4]=='Iris-versicolor'][3]
data_virginica3 = data[data[4]=='Iris-virginica'][3]data_PetalWidthCm = pd.DataFrame({'setosa':data_setosa3, 'versicolor':data_versicolor3, 'virginica':data_virginica3})
绘制小提琴图:
f, axes = plt.subplots(2, 2, figsize = (8, 8), sharex = True)
sns.despine(left = True)
sns.violinplot(data=data_SepalLengthCm, linewidth=1, width=0.8, palette=antV, ax=axes[0, 0])
axes[0, 0].set_xlabel('Kinds')
axes[0, 0].set_ylabel('SepalLengthCm')
sns.violinplot(data=data_SepalWidthCm, linewidth=1, width=0.8, palette=antV, ax=axes[0, 1])
axes[0, 1].set_xlabel('Kinds')
axes[0, 1].set_ylabel('SepalWidthCm')
sns.violinplot(data=data_PetalLengthCm, linewidth=1, width=0.8, palette=antV, ax=axes[1, 0])
axes[1, 0].set_xlabel('Kinds')
axes[1, 0].set_ylabel('PetalLengthCm')
sns.violinplot(data=data_PetalWidthCm, linewidth=1, width=0.8, palette=antV, ax=axes[1, 1])
axes[1, 1].set_xlabel('Kinds')
axes[1, 1].set_ylabel('PetalWidthCm')
plt.show()
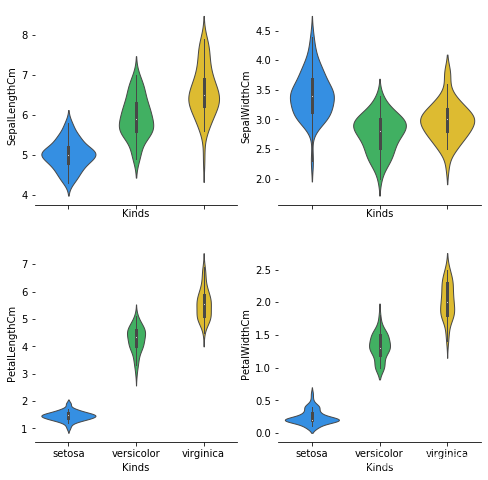
四:绘制 pointplot图
f, axes = plt.subplots(2, 2, figsize=(8, 8), sharex=True)
sns.despine(left = True)
sns.pointplot(data=data_SepalLengthCm, color=antV[2], ax=axes[0, 0])
axes[0, 0].set_xlabel('Kinds')
axes[0, 0].set_ylabel('SepalLengthCm')
sns.pointplot(data=data_SepalWidthCm, color=antV[2], ax=axes[0, 1])
axes[0, 1].set_xlabel('Kinds')
axes[0, 1].set_ylabel('SepalWidthCm')
sns.pointplot(data=data_PetalLengthCm, color=antV[2], ax=axes[1, 0])
axes[1, 0].set_xlabel('Kinds')
axes[1, 0].set_ylabel('PetalLengthCm')
sns.pointplot(data=data_PetalWidthCm, color=antV[2], ax=axes[1, 1])
axes[1, 1].set_xlabel('Kinds')
axes[1, 1].set_ylabel('PetalWidthCm')
plt.show()
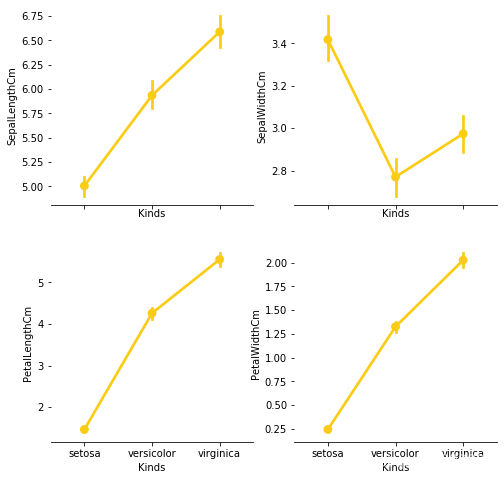
五:绘制各个特征之间的关系矩阵
g = sns.pairplot(data=data, palette=antV, hue=4)
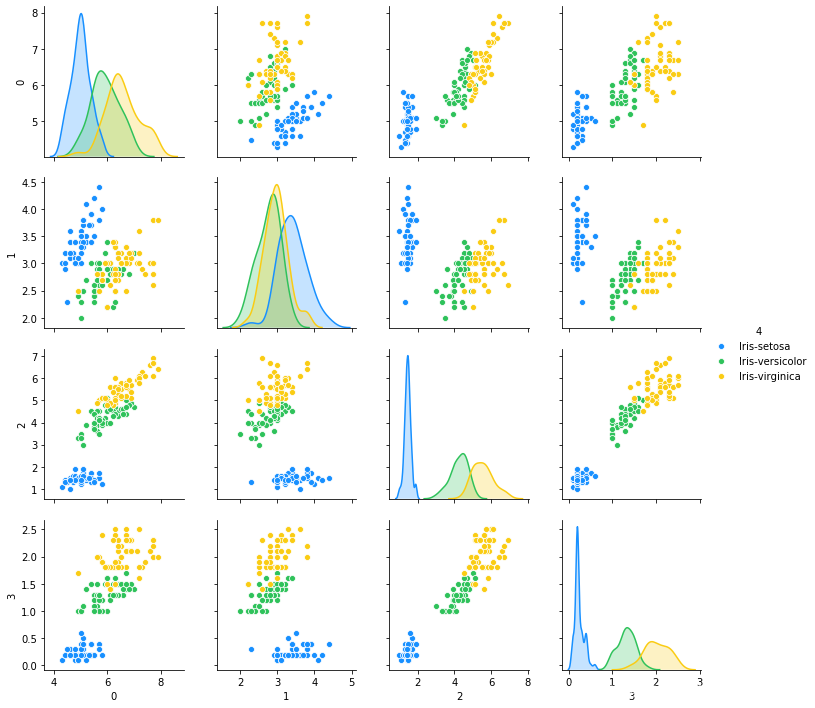
六:绘制Andrews Curves
使用 Andrews Curves 将每个多变量观测值转换为曲线并表示傅立叶级数的系数,这对于检测时间序列数据中的异常值很有用。
plt.subplots(figsize = (10, 8))
pd.plotting.andrews_curves(data, 4, colormap = 'cool')
plt.show()
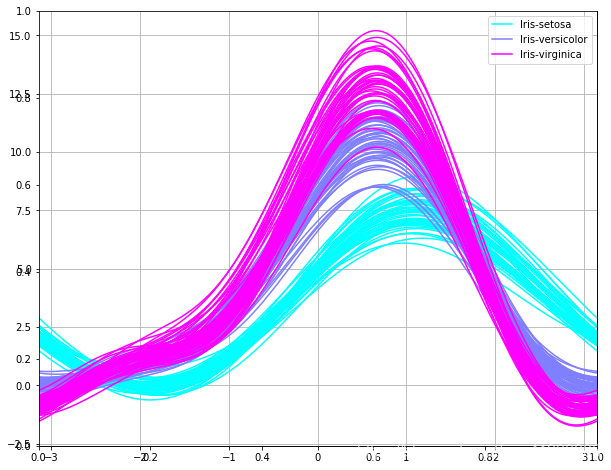
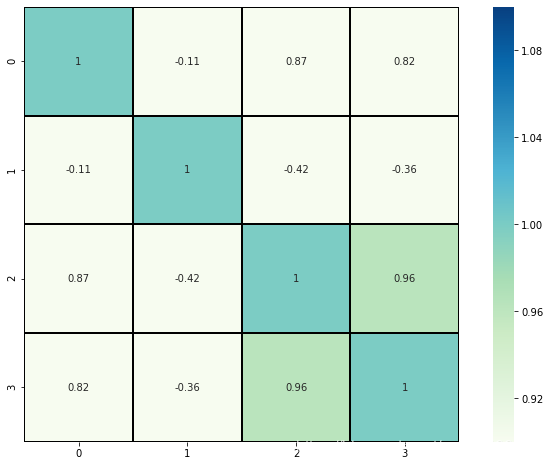
七: 绘制热图,观察数据特征之间的先关性
fig = plt.gcf()
fig.set_size_inches(12, 8)
fig = sns.heatmap(data.corr(), annot=True, cmap='GnBu', linewidths=1,
linecolor='k', square=True, mask=False, vmin=1,
cbar_kws={"orientation":"vertical"}, cbar=True)















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











