




引入
上一篇我们回顾了JMM,标题中的主内存和工作内存是JMM的核心部分,下面就跟着我一起,进一步深入JMM。
CPU 有多级缓存,导致读的数据过期
由于 CPU 的处理速度很快,相比之下,内存的速度就显得很慢,所以为了提高 CPU 的整体运行效率,减少空闲时间,在 CPU 和内存之间会有 cache 层,也就是缓存层的存在。虽然缓存的容量比内存小,但是缓存的速度却比内存的速度要快得多,其中 L1 缓存的速度仅次于寄存器的速度。结构示意图如下所示:
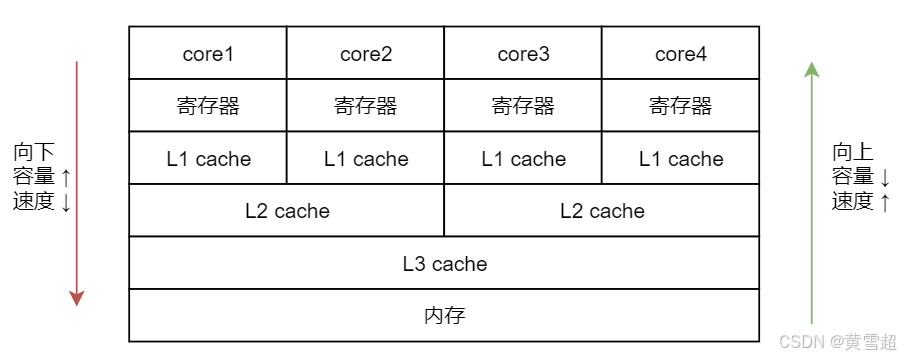 在图中,从下往上分别是内存,L3 缓存、L2 缓存、L1 缓存,寄存器,然后最上层是 CPU 的 4个核心。
在图中,从下往上分别是内存,L3 缓存、L2 缓存、L1 缓存,寄存器,然后最上层是 CPU 的 4个核心。
从内存,到 L3 缓存,再到 L2 和 L1 缓存,它们距离 CPU 的核心越来越近了,越靠近核心,其容量就越小,但是速度也越快。正是由于缓存层的存在,才让我们的 CPU 能发挥出更好的性能。
其实,线程间对于共享变量的可见性问题,并不是直接由多核引起的,而是由我们刚才讲到的这些 L3 缓存、L2 缓存、L1 缓存,也就是多级缓存引起的:每个核心在获取数据时,都会将数据从内存一层层往上读取,同样,后续对于数据的修改也是先写入到自己的 L1 缓存中,然后等待时机再逐层往下同步,直到最终刷回内存。
假设 core 1 修改了变量 a 的值,并写入到了 core 1 的 L1 缓存里,但是还没来得及继续往下同步,由于 core 1 有它自己的的 L1 缓存,core 4 是无法直接读取 core 1 的 L1 缓存的值的,那么此时对于 core 4 而言,变量 a 的值就不是 core 1 修改后的最新的值,core 4 读取到的值可能是一个过期的值,从而引起多线程时可见性问题的发生。
JMM的抽象:主内存和工作内存
在 JMM 中,主内存主要存储 Java 实例对象,包括成员变量等数据。所有的线程都可以访问主内存,它是共享的内存区域。而工作内存是每个线程私有的内存区域,它存储了该线程从主内存中读取到的变量副本,以及线程执行过程中的中间变量等。
什么是主内存和工作内存
Java 作为高级语言,屏蔽了 L1 缓存、L2 缓存、L3 缓存,也就是多层缓存的这些底层细节,用 JMM 定义了一套读写数据的规范。我们不再需要关心 L1 缓存、L2 缓存、L3 缓存等多层缓存的问题,我们只需要关心 JMM 抽象出来的主内存和工作内存的概念。
可参考下图:
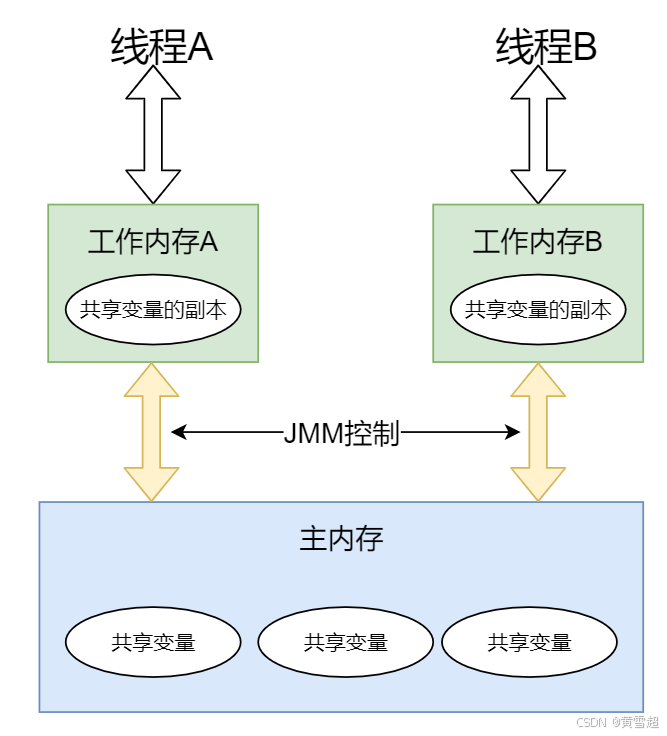
每个线程只能够直接接触到工作内存,无法直接操作主内存,而工作内存中所保存的正是主内存的共享变量的副本,主内存和工作内存之间的通信是由 JMM 控制的。
主内存
主内存是 Java 虚拟机(JVM)中所有线程共享的一块内存区域。它存储了 Java 实例对象、共享的类信息、常量、静态变量等。主内存中的数据是线程间共享和交互的基础。
工作内存
每个线程都有自己的工作内存,它是线程私有的,用于存储该线程所访问的变量的副本。工作内存使得每个线程能够独立地操作数据,而不需要与其他线程直接交互。线程对共享变量的操作(如读取和写入)都在自己的工作内存中进行,而不是直接在主内存中进行。
主内存和工作内存的关系
JMM 有以下规定:
- 所有的变量都存储在主内存中,同时每个线程拥有自己独立的工作内存,而工作内存中的变量的内容是主内存中该变量的拷贝;
- 线程不能直接读 / 写主内存中的变量,但可以操作自己工作内存中的变量,然后再同步到主内存中,这样,其他线程就可以看到本次修改;
- 主内存是由多个线程所共享的,但线程间不共享各自的工作内存,如果线程间需要通信,则必须借助主内存中转来完成。
听到这里,你对上图的理解可能会更深刻一些,从图中可以看出,每个工作内存中的变量都是对主内存变量的一个拷贝,相当于是一个副本。而且图中没有一条线是可以直接连接各个工作内存的,因为工作内存之间的通信,都需要通过主内存来中转。
正是由于所有的共享变量都存在于主内存中,每个线程有自己的工作内存,其中存储的是变量的副本,所以这个副本就有可能是过期的,我们来举个例子:如果一个变量 x 被线程 A 修改了,只要还没同步到主内存中,线程 B 就看不到,所以此时线程 B 读取到的 x 值就是一个过期的值,这就导致了可见性问题。
拓展
在并发编程中,缓存行对齐和伪共享是两个重要的概念,它们对程序的性能有显著影响。
缓存行对齐可以提高缓存命中率和内存访问效率,而伪共享会导致缓存行频繁失效,从而影响性能。通过使用填充(Padding)和@Contended注解,可以有效地避免伪共享问题,从而提高程序的性能。
缓存行对齐
缓存行(Cache Line)是缓存存储的基本单位,通常为64字节。缓存行对齐是指将数据按照缓存行的大小进行排列,以确保数据能够被高效地加载到缓存中。通过将数据对齐到缓存行的边界,可以减少缓存行之间的竞争,从而提高缓存命中率和内存访问效率。
为什么需要缓存行对齐?
提高缓存命中率:对齐的数据结构可以减少缓存行的数量,从而提高缓存命中率。
减少缓存行填充:对齐的数据结构可以减少缓存行填充(Cache Line Fill),即从主存加载数据到缓存行的次数,从而提高内存访问效率。
如何实现缓存行对齐?
在Java中,直接控制缓存行对齐比较困难,因为Java没有提供直接的内存管理功能。但是,可以通过一些技巧来间接实现缓存行对齐。例如,可以使用填充(Padding)来确保数据结构的起始地址对齐到缓存行边界。
/**
* 该类用于实现缓存行对齐,通过填充字段避免伪共享问题。
* 伪共享是指多个线程同时访问位于同一缓存行中的不同变量,
* 导致缓存行频繁失效,从而影响性能。
*/
public class CacheLineAligned {
// 假设缓存行大小为64字节,这些字段用于填充缓存行,避免与其他变量共享同一缓存行
private long p1, p2, p3, p4, p5, p6, p7;
// 该字段是实际需要操作的值,使用volatile关键字保证可见性
private volatile long value;
// 这些字段用于填充缓存行,确保value字段独占一个缓存行
private long p9, p10, p11, p12, p13, p14, p15;
}
伪共享
伪共享(False Sharing)是指多个线程访问不同变量,但这些变量恰好位于同一个缓存行中,导致缓存行频繁失效,从而影响性能。
这种现象被称为伪共享,因为它共享的是缓存行,而不是变量本身。
为什么会发生伪共享?
当多个线程访问不同的变量时,如果这些变量位于同一个缓存行中,尽管这些变量之间没有直接关系,但由于缓存一致性协议(如MESI协议)的存在,导致缓存行频繁失效,从而影响性能。
如何避免伪共享?
-
缓存行填充:通过在变量之间添加填充变量,使得每个变量都独占一个缓存行,从而避免伪共享。例如,在Java中,可以在变量前后添加足够的填充变量,使得变量之间的距离超过缓存行的大小。
-
使用@Contended注解:在Java 8中,引入了@Contended注解,它可以自动为被注解的类或字段添加缓存行填充,从而避免伪共享。需要注意的是,此注解默认是无效的,需要在JVM启动时设置-XX:-RestrictContended参数才能生效。
import java.util.concurrent.CountDownLatch;
import sun.misc.Contended;
/**
* 该类用于演示缓存行填充的效果,通过多线程并发修改数组元素的值来观察性能差异。
*/
public class CacheLineExample {
/**
* 使用 @Contended 注解的静态内部类,确保每个实例都在独立的缓存行中。
*/
@Contended
public static class VolatileLong {
// 声明一个 volatile 类型的长整型变量,用于存储值
public volatile long value = 0L;
// 使用 @Contended 注解自动添加缓存行填充,避免伪共享问题
}
/**
* 程序的入口点,通过创建两个线程并发修改数组元素的值,并测量执行时间。
*
* @param args 命令行参数
* @throws InterruptedException 如果线程在等待过程中被中断
*/
public static void main(String[] args) throws InterruptedException {
// 创建一个 CountDownLatch 对象,用于同步两个线程的完成
CountDownLatch countDownLatch = new CountDownLatch(2);
// 创建一个包含两个 VolatileLong 实例的数组
VolatileLong[] arr = new VolatileLong[2];
// 初始化数组的第一个元素
arr[0] = new VolatileLong();
// 初始化数组的第二个元素
arr[1] = new VolatileLong();
// 创建第一个线程,用于修改数组的第一个元素的值
Thread threadA = new Thread(() -> {
// 循环 10 亿次,每次更新数组第一个元素的值
for (long i = 0; i < 1_000_000_000L; i++) {
arr[0].value = i;
}
// 线程完成后,将 CountDownLatch 的计数器减 1
countDownLatch.countDown();
}, "ThreadA");
// 创建第二个线程,用于修改数组的第二个元素的值
Thread threadB = new Thread(() -> {
// 循环 10 亿次,每次更新数组第二个元素的值
for (long i = 0; i < 1_000_000_000L; i++) {
arr[1].value = i;
}
// 线程完成后,将 CountDownLatch 的计数器减 1
countDownLatch.countDown();
}, "ThreadB");
// 记录开始时间
final long start = System.nanoTime();
// 启动第一个线程
threadA.start();
// 启动第二个线程
threadB.start();
// 等待两个线程完成
countDownLatch.await();
// 记录结束时间
final long end = System.nanoTime();
// 输出执行时间(毫秒)
System.out.println("耗时:" + (end - start) / 1_000_000 + "毫秒");
}
}


















 3406
3406

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











