







</div>
<!--一个博主专栏付费入口-->
<!--一个博主专栏付费入口结束-->
<link rel="stylesheet" href="https://csdnimg.cn/release/phoenix/template/css/ck_htmledit_views-4a3473df85.css">
<div id="content_views" class="markdown_views prism-atom-one-dark">
<!-- flowchart 箭头图标 勿删 -->
<svg xmlns="http://www.w3.org/2000/svg" style="display: none;">
<path stroke-linecap="round" d="M5,0 0,2.5 5,5z" id="raphael-marker-block" style="-webkit-tap-highlight-color: rgba(0, 0, 0, 0);"></path>
</svg>
<p>根据MxNet深度学习框架官方文档 (<a href="https://mxnet.incubator.apache.org/versions/master/architecture/program_model.html#symbolic-vs-imperative-programs" rel="nofollow">https://mxnet.incubator.apache.org/versions/master/architecture/program_model.html#symbolic-vs-imperative-programs</a> ), 从命令式编程和符号式编程的角度分析动态图和静态图深度学习框架的实现方式和特点。</p>
- 动态图框架对应的是 命令式编程
- 静态图框架对应的是 符号式编程
什么是symblic/imperative style编程
使用过python或C++对imperative programs比较了解。imperative-stype programs在运行时计算,大部分python代码都是imperative。比如下面的例子:
import numpy as np
a = np.ones(10)
b = np.ones(10) * 2
c = b * a
d = c + 1
- 1
- 2
- 3
- 4
- 5
当程序执行到 c = b ∗ a c = b ∗ a c = b ∗ a c=b∗ac=b∗a c=b∗a c=b∗ac=b∗ac=b∗aC=B∗A 并不会触发真正的数值计算,但会生成一个计算图(也称symbolic graph)描述这个计算。下图时计算D的计算图
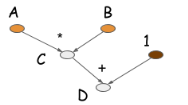
大部分symbolic-style program都显性或隐性的包含一个编译的步骤,把计算转换成可以调用的函数。上面的例子中,数值计算仅仅在代码最后一行进行,symbolic program一个重要特点是其明确有构建计算图和生成可执行代码两个步骤。对于神经网络,一般会用一个就算图描述整个模型。
其他流行深度学习框架中,PyTorch/Chainer/Minerva使用imperative style。symbolic-styple的框架包括Theano/CGT/TensorFlow。 CXXNet/Caffe这一类依赖配置文件的框架也看作symbolic-style库。此时配置文件被当作计算图的定义。下面我们对比一下二者的优劣:
命令式编程更加灵活
用python调用imperative-style库十分简单,编写方式和普通的python代码一样,在合适的位置调用库的代码实现加速。如果用python调用symbolic-style库,代码结构将出现一些变化,比如iteration可能无法使用。尝试把下面的例子转换成symbolic-style
a = 2
b = a + 1
d = np.zeros(10)
for i in range(d):
d += np.zeros(10)
- 1
- 2
- 3
- 4
- 5
如果symblic-style API不支持for循环,转换就没那个直接。不能用python的编码思路调用symblic-style库。需要利用symblic API定义的domain-specific-language(DSL)。深度学习框架会提供功能强大的DSL,把神经网络转化成可被调用的计算图。
感觉上imperative program更加符合习惯,使用更加简单。例如,可以在任何位置打印出变量的值,轻松使用符合习惯的流程控制语句和循环语句。
符号式编程更加高效
既然imperative pragrams更加灵活,和计算机原生语言更加贴合,那么为什么很多深度学习框架使用symbolic风格? 最主要的原因式效率,内存效率和计算效率都很高。比如下面的例子:
import numpy as np
a = np.ones(10)
b = np.ones(10) * 2
c = b * a
d = c + 1
...
- 1
- 2
- 3
- 4
- 5
- 6
如果数组每个元素内存中占据8字节,在python中需要多少内存?
对于imperative programs中,需要在每一行上都分配必要的内存。一共4个数组,每个数组10个元素,一共4∗10∗8=320字节。 如果事先知道只有d是需要的结果,构造计算图时可以重复利用一些中间变量的空间。比如利用原址计算,我们可以把b的内存借给c使用,同样c的内存可以给d用,如此可以节省一半内存,仅仅需要2∗10∗8=160字节。
symbolic programs限制更多,因为只需要d,构建计算图后,一些中间量,比如c,的值将无法看到。
通过symbolic program,使用原址计算可以安全的重用内存,但牺牲了对c的访问可能。 imperative program可以处理各种访问可能,如果在python执行上述例子,任何中间量都可以方便访问。
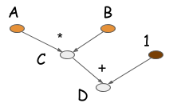
symbolic program还可以通过operation folding优化计算。在上述的例子中,乘法和加法可以展成一个操作,如下图所示:
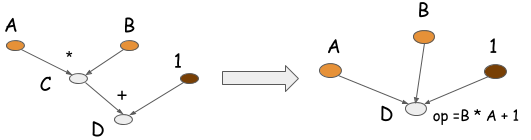
如果在GPU上运算,计算图只需要一个kernel,节省了一个kernel。在很多优化库,比如caffe/CXXNet,人工编码进行此类优化操作。 operation folding可以提高计算效率。
imperative program中不能自动operation folding,因为不知道中间变量是否会被访问到。symbolic program中可以做operation folding,因为获得了完整的计算图,而且明确哪些量以后会被访问,哪些量以后都不会被访问。
Backprop和AutoDiff的案例分析
在这一节,我们将基于自动微分或是反向传播的问题对比两种编程模式。梯度计算几乎是所有深度学习库所要解决的问题。使用命令式程序和符号式程序都能实现梯度计算。
我们先看命令式程序。下面这段代码实现自动微分运算,我们之前讨论过这个例子。
class array(object) : """Simple Array object that support autodiff.""" def __init__(self, value, name=None): self.value = value if name: self.grad = lambda g : {name : g}<span class="token keyword">def</span> <span class="token function">__add__</span><span class="token punctuation">(</span>self<span class="token punctuation">,</span> other<span class="token punctuation">)</span><span class="token punctuation">:</span> <span class="token keyword">assert</span> <span class="token builtin">isinstance</span><span class="token punctuation">(</span>other<span class="token punctuation">,</span> <span class="token builtin">int</span><span class="token punctuation">)</span> ret <span class="token operator">=</span> array<span class="token punctuation">(</span>self<span class="token punctuation">.</span>value <span class="token operator">+</span> other<span class="token punctuation">)</span> ret<span class="token punctuation">.</span>grad <span class="token operator">=</span> <span class="token keyword">lambda</span> g <span class="token punctuation">:</span> self<span class="token punctuation">.</span>grad<span class="token punctuation">(</span>g<span class="token punctuation">)</span> <span class="token keyword">return</span> ret <span class="token keyword">def</span> <span class="token function">__mul__</span><span class="token punctuation">(</span>self<span class="token punctuation">,</span> other<span class="token punctuation">)</span><span class="token punctuation">:</span> <span class="token keyword">assert</span> <span class="token builtin">isinstance</span><span class="token punctuation">(</span>other<span class="token punctuation">,</span> array<span class="token punctuation">)</span> ret <span class="token operator">=</span> array<span class="token punctuation">(</span>self<span class="token punctuation">.</span>value <span class="token operator">*</span> other<span class="token punctuation">.</span>value<span class="token punctuation">)</span> <span class="token keyword">def</span> <span class="token function">grad</span><span class="token punctuation">(</span>g<span class="token punctuation">)</span><span class="token punctuation">:</span> x <span class="token operator">=</span> self<span class="token punctuation">.</span>grad<span class="token punctuation">(</span>g <span class="token operator">*</span> other<span class="token punctuation">.</span>value<span class="token punctuation">)</span> x<span class="token punctuation">.</span>update<span class="token punctuation">(</span>other<span class="token punctuation">.</span>grad<span class="token punctuation">(</span>g <span class="token operator">*</span> self<span class="token punctuation">.</span>value<span class="token punctuation">)</span><span class="token punctuation">)</span> <span class="token keyword">return</span> x ret<span class="token punctuation">.</span>grad <span class="token operator">=</span> grad <span class="token keyword">return</span> ret <span class="token comment"># some examples</span> a <span class="token operator">=</span> array<span class="token punctuation">(</span><span class="token number">1</span><span class="token punctuation">,</span> <span class="token string">'a'</span><span class="token punctuation">)</span> b <span class="token operator">=</span> array<span class="token punctuation">(</span><span class="token number">2</span><span class="token punctuation">,</span> <span class="token string">'b'</span><span class="token punctuation">)</span> c <span class="token operator">=</span> b <span class="token operator">*</span> a d <span class="token operator">=</span> c <span class="token operator">+</span> <span class="token number">1</span> <span class="token keyword">print</span> d<span class="token punctuation">.</span>value <span class="token keyword">print</span> d<span class="token punctuation">.</span>grad<span class="token punctuation">(</span><span class="token number">1</span><span class="token punctuation">)</span> <span class="token comment"># Results</span> <span class="token comment"># 3</span> <span class="token comment"># {'a': 2, 'b': 1}</span>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
在上述程序里,每个数组对象都含有grad函数(事实上是闭包-closure)。当我们执行d.grad时,它递归地调用grad函数,把梯度值反向传播回来,返回每个输入值的梯度值。看起来似乎有些复杂。让我们思考一下符号式程序的梯度计算过程。下面这段代码是符号式的梯度计算过程。
A = Variable('A')
B = Variable('B')
C = B * A
D = C + Constant(1)
# get gradient node.
gA, gB = D.grad(wrt=[A, B])
# compiles the gradient function.
f = compile([gA, gB])
grad_a, grad_b = f(A=np.ones(10), B=np.ones(10)*2)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
D的grad函数生成一幅反向计算图,并且返回梯度节点gA和gB。它们对应于下图的红点。

命令式程序做的事和符号式的完全一致。它隐式地在grad闭包里存储了一张反向计算图。当执行d.grad时,我们从d(D)开始计算,按照图回溯计算梯度并存储结果。
因此我们发现无论符号式还是命令式程序,它们计算梯度的模式都一致。那么两者的差异又在何处?再回忆一下命令式程序“未雨绸缪”的要求。如果我们准备一个支持自动微分的数组库,需要保存计算过程中的grad闭包。这就意味着所有历史变量不能被垃圾回收,因为它们通过函数闭包被变量d所引用。那么,若我们只想计算d的值,而不想要梯度值该怎么办呢?
在符号式程序中,我们声明f=compiled([D>)来替换。它也声明了计算的边界,告诉系统我只想计算正向通路的结果。那么,系统就能释放之前结果的存储空间,并且共享输入和输出的内存。
假设现在我们运行的不是简单的示例,而是一个n层的深度神经网络。如果我们只计算正向通路,而不用反向(梯度)通路,我们只需分配两份临时空间存放中间层的结果,而不是n份。由于命令式程序需要为今后可能用到的梯度值做准备,中间结果不得不保存,就需要用到n份临时空间。
正如我们所见,优化的程度取决于对用户行为的约束。符号式程序的思路就是让用户通过编译明确地指定计算的边界。而命令式程序为之后所有情况做准备。符号式程序更充分地了解用户需要什么和不想要什么,这是它的天然优势。
当然,我们也能对命令式程序施加约束条件。例如,上述问题的解决方案之一是引入一个上下文变量。我们可以引入一个没有梯度的上下文变量,来避免梯度值的计算。这给命令式程序带来了更多的约束条件,以换取性能上的改善。
with context.NoGradient():
a = array(1, 'a')
b = array(2, 'b')
c = b * a
d = c + 1
- 1
- 2
- 3
- 4
- 5
然而,上述的例子还是有许多可能的未来,也就是说不能在正向通路中做同址计算来重复利用内存(一种减少GPU内存的普遍方法)。这一节介绍的技术产生了显式的反向通路。在Caffe和cxxnet等工具包里,反向传播是在同一幅计算图内隐式完成的。这一节的讨论同样也适用于这些例子。
大多数基于函数库(如cxxnet和caffe)的配置文件,都是为了一两个通用需求而设计的。计算每一层的激活函数,或是计算所有权重的梯度。这些库也面临同样的问题,若一个库能支持的通用计算操作越多,我们能做的优化(内存共享)就越少,假设都是基于相同的数据结构。
因此经常能看到一些例子在约束性和灵活性之间取舍。
模型检查点
支持对配置文件设置检查点是符号式程序的加分项。因为符号式的模型构建阶段并不包含计算步骤,我们可以直接序列化计算图,之后再重新加载它,无需引入附加层就解决了保存配置文件的问题。
A = Variable('A')
B = Variable('B')
C = B * A
D = C + Constant(1)
D.save('mygraph')
...
D2 = load('mygraph')
f = compile([D2])
# more operations
...
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
因为命令式程序逐行执行计算。我们不得不把整块代码当做配置文件来存储,或是在命令式语言的顶部再添加额外的配置层。
参数更新
大多数符号式编程属于数据流(计算)图。数据流图能方便地描述计算过程。然而,它对参数更新的描述并不方便,因为参数的更新会引起变异(mutation),这不属于数据流的概念。大多数符号式编程的做法是引入一个特殊的更新语句来更新程序的某些持续状态。
用命令式风格写参数更新往往容易的多,尤其是当需要相互关联地更新时。对于符号式编程,更新语句也是被我们调用并执行。在某种意义上来讲,目前大部分符号式深度学习库也是退回命令式方法进行更新操作,用符号式方法计算梯度。
没有严格的边界
我们已经比较了两种编程风格。之前的一些说法未必完全准确,两种编程风格之间也没有明显的边界。例如,我们可以用Python的(JIT)编译器来编译命令式程序,使我们获得一些符号式编程对全局信息掌握的优势。但是,之前讨论中大部分说法还是正确的,并且当我们开发深度学习库时这些约束同样适用。
参考
- https://blog.csdn.net/z0n1l2/article/details/80873608
- https://mxnet.incubator.apache.org/versions/master/architecture/program_model.html#symbolic-vs-imperative-programs
- https://blog.csdn.net/daslab/article/details/50434145
- https://www.jianshu.com/p/1c7ef1ce5540 (MXNet的动态图接口Gluon
)
</div>
<link href="https://csdnimg.cn/release/phoenix/mdeditor/markdown_views-b6c3c6d139.css" rel="stylesheet">
</div>















 2514
2514











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









