







开发工具与关键技术:Python IDEL、Python
作者:曾浩源
撰写时间:2019年08月07日
写一个小功能来模拟搜狗翻译发送请求,让这个小功能拥有翻译的功能。
首先打开搜狗翻译,然后F12或右键选择检查,找到Network,再搜狗翻译内进行一次翻译,之后Name下就出现一堆东西,如:
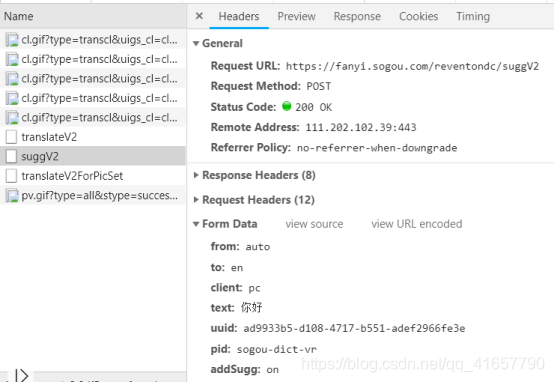
看着大概也知道,出来translateV2、suggV2和translateV2ForPicSet其余都是一些图片,以上三个都是post请求,这里选择的是suggV2,它是释义而且传的数据也少所以选它了,至于其他两个,到时候自己试试吧。
从这里就可以知道了请求url地址(Requset URL),和所要传输的数据(From Data)
接下来就是将所要的内容赋予我们Python里的变量:
url="https://fanyi.sogou.com/reventondc/suggV2"
data={}
data["from"]="auto"
data["to"]="zh-CHS"
data["client"]="pc"
data["text"]=content
data["uuid"]="a494de6c-0c2c-4e1d-a6be-be70df3c2dfa"
data["pid"]="sogou-dict-vr"
data["addSugg"]="on"
之后就是发送数据,但这是post请求,不是get请求,get请求直接拼接所要传输的数据就行了,而post请求要被编码为字节数据,所以我们要转编码。
发送数据就是请求,和转编码它们需要我们在python内引用urllib模块.
请求要urllib内的request(urllib.request 用于打开网址的可扩展库。)、转编码需要urllib内的parse(urllib.parse URL解析组件)
所以在最前面引入需要的模块
import urllib.request
import urllib.parse
在data赋值完成后,将data转码为utf-8,这要看别人网页的请求头是啥了,现在一般都是utf-8。
在Python中,我们通常使用urllib中的urlencode方法将字典编码,所以:
data = urllib.parse.urlencode(data).encode('utf-8')
编码完成后就可以直接使用urllib.request.urlopen()方法向要打开的url链接发送我们的数据data 了:
response = urllib.request.urlopen(url,data)
响应后,我们需要读取响应,再把它转码为utf-8
html = response.read().decode('utf-8')
读取到之后,但它是字符串形式:
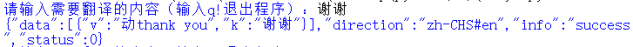
发现它很像是一个字典,其实就是字典的字符串格式,我们现在就需要把它从字符串转为字典,这里需要引用一个模块,json模块。
在代码最上面的引用代码后加入
import json
获取到响应回来的内容赋值给html后,转为字典如下:
target=json.loads(html)
输出:
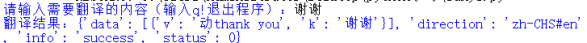
我们需要的是 键:data的值,它的值是一个列表,需要第一个也就是索引0,列表里又是字典,需要的是 键:v的值
所以:
target=target['data'][0]["v"]
print("翻译结果:%s" % target)
完整的一些小修改后的代码:
import urllib.request
import urllib.parse
import json
import time
import random
while True:
content=input("请输入需要翻译的内容(输入q!退出程序):")
if content == 'q!':
break
url="https://fanyi.sogou.com/reventondc/suggV2"
data={}
data["from"]="auto"
data["to"]="zh-CHS"
data["client"]="pc"
data["text"]=content
data["uuid"]="a494de6c-0c2c-4e1d-a6be-be70df3c2dfa"
data["pid"]="sogou-dict-vr"
data["addSugg"]="on"
data = urllib.parse.urlencode(data).encode('utf-8')
req =urllib.request.Request(url,data)
req.add_header("User-Agent","Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3704.400 QQBrowser/10.4.3587.400")
response=urllib.request.urlopen(req)
html=response.read().decode('utf-8')
target=json.loads(html)
if not 'data' in target:
print('没有该翻译!')
else:
target=target['data'][0]["v"]
print("翻译结果:%s" % target)
time.sleep(2)














 965
965











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









