






什么是决策树算法?
决策树(Decision tree) 是一种特殊的树结构,由一个决策图和可能的结果(例如成本和风险)组成,用来辅助决策。决策树仅有单一输出,通常该算法用于解决回归和分类问题。
决策树原理
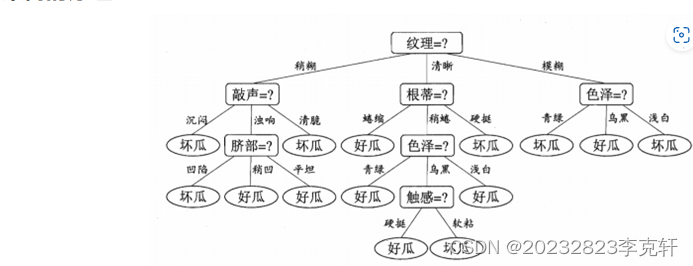
机器学习中,决策树是一个预测模型,树中每个节点表示某个对象,而每个分叉路径则代表某个可能的属性值,而每个叶节点则对应从根节点到该叶节点所经历的路径所表示的对象的值。在每个节点上,我们根据可用的特征询问有关数据的问题。左右分支代表可能的答案。最终节点(即叶节点)对应于一个预测值。每个特征的重要性是通过自顶向下方法确定的。节点越高,其属性就越重要。
决策树的基本组成部分:
根节点(Root Node):决策树的起点,通常是整个数据集。
内部节点(Internal Nodes):代表决策规则,通常是数据特征的某个属性。
分支(Branches):代表决策规则的输出结果,即属性值的不同选项。
叶节点(Leaf Nodes):代表决策结果,通常是分类标签。
决策树的构建过程:
特征选择:选择最合适的特征作为节点,常用的方法有信息增益、信息增益率等。
树的生成:根据特征选择,递归地分割数据集,直到满足停止条件(如所有数据点都属于同一类别,或达到预设的最大深度)。
剪枝:为了防止过拟合,对生成的树进行剪枝,减少树的复杂度。
决策树的优点:
可解释性:决策树的结构清晰,容易理解模型的决策过程。
处理非线性问题:可以处理特征与目标变量之间的非线性关系。
不需要太多数据预处理:对数据的格式和类型要求不高。
决策树的缺点:
容易过拟合:在数据特征较多或数据量较小的情况下,决策树容易过拟合。
对噪声数据敏感:噪声数据可能会影响树的构建,导致模型性能下降。
对缺失值不友好:在处理缺失值时,需要额外的处理方法。
解决问题
用Python和scikit-learn库实现的机器学习流程,主要目的是使用决策树分类器对泰坦尼克号乘客数据集(通常存储在train.csv文件中)进行生存预测
去阿里官网下载文件

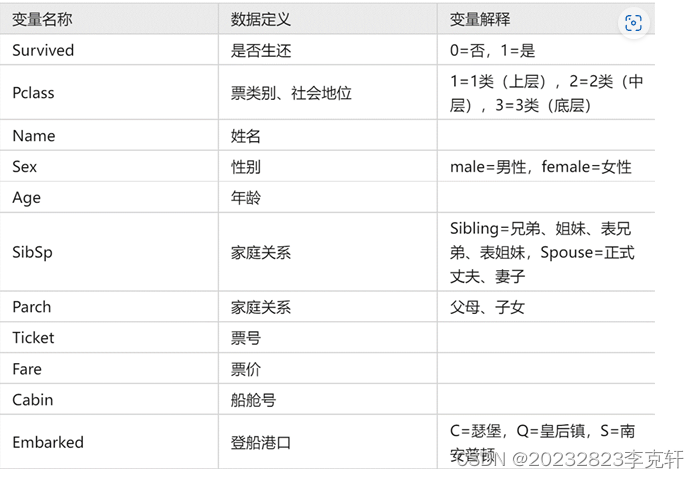
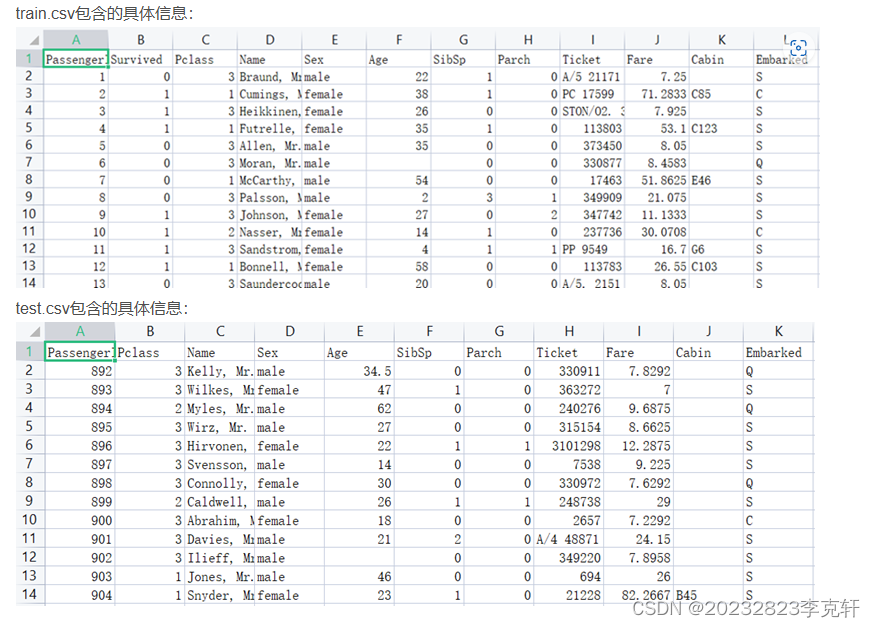
数据集格式
代码
// An highlighted block
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import cross_val_score
from sklearn import tree
from sklearn.feature_extraction import DictVectorizer
from sklearn.tree import export_graphviz
data = pd.read_csv(r"train.csv")
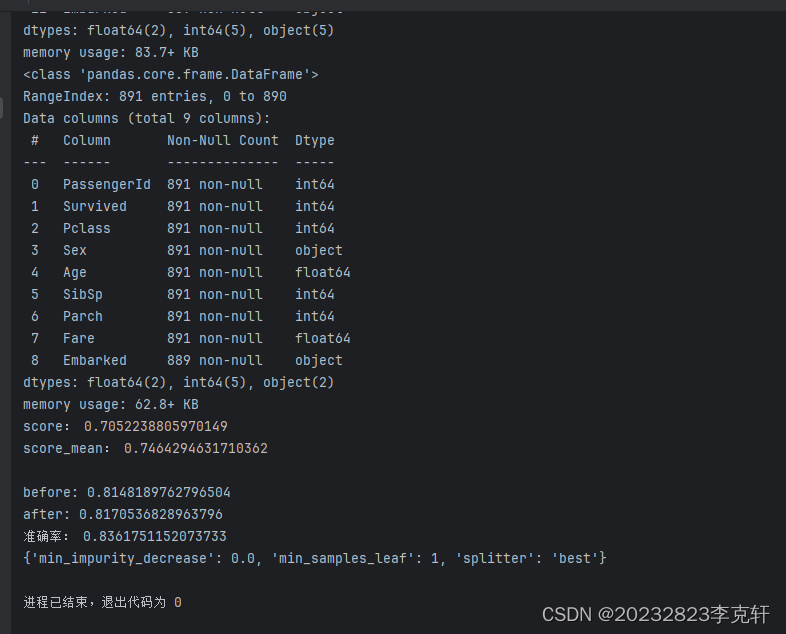
data.info()
#删除冗余字段
data_new = data.drop(["Name","Ticket","Cabin"],axis=1)
#axis=1,轴向=1即对列进行操作
#使用年龄字段的均值填补缺失值
data_new["Age"] = data_new["Age"].fillna(data_new["Age"].mean())
#将embarked字段中含有缺失值的行删除
data_new.dropna(axis=0)
data_new.info()
#将sex、embarked字段转换为字段属性,可有两种不同的方法
labels = data_new["Embarked"].unique().tolist()
data_new["Embarked"] = data_new["Embarked"].apply(lambda x:labels.index(x))
data_new["Sex"] = (data_new["Sex"]=="male").astype("int")
#至此数据的基本处理已经结束
x = data_new.iloc[:,data_new.columns!="Survived"]
y = data_new.iloc[:,data_new.columns=="Survived"]
xtrain,xtest,ytrain,ytest = train_test_split(x,y,test_size=0.3)
for i in [xtrain,xtest,ytrain,ytest]:
i.index = range(i.shape[0])
clf = DecisionTreeClassifier(random_state=25)
clf = clf.fit(xtrain,ytrain)
score = clf.score(xtest,ytest)
print('score:',score)
clf = DecisionTreeClassifier(random_state=25)
clf = clf.fit(xtrain,ytrain)
score_mean = cross_val_score(clf,x,y,cv=10).mean()
print('score_mean:',score_mean)
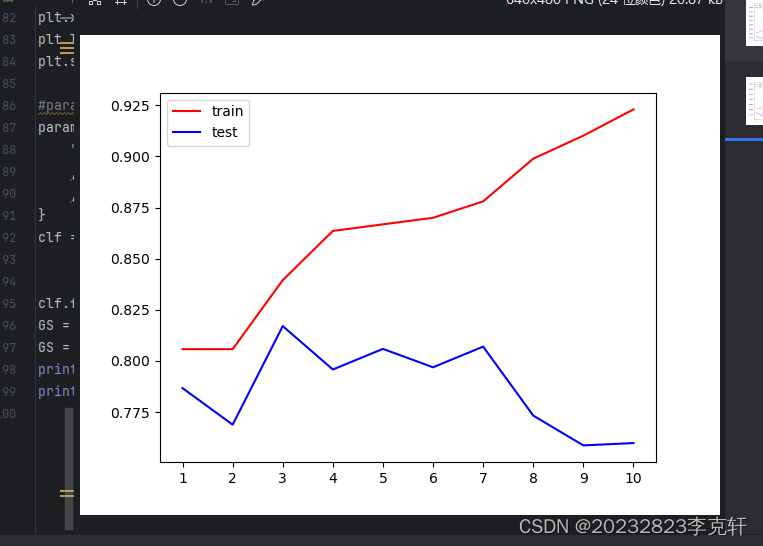
#交叉验证的结果比单个的结果更低,因此要来调整参数,首先想到的是max_depth,因此绘制超参数曲线
score_test=[]
score_train=[]
for i in range(10):
clf = DecisionTreeClassifier(random_state=25
,max_depth=i+1)
clf = clf.fit(xtrain,ytrain)
score_tr = clf.score(xtrain,ytrain)
score_te = cross_val_score(clf,x,y,cv=10).mean()
score_train.append(score_tr)
score_test.append(score_te)
print("\nbefore:",max(score_test))
#绘制超参数图像
plt.plot(range(1,11),score_train,color="red",label="train")
plt.plot(range(1,11),score_test,color="blue",label="test")
plt.legend()
plt.xticks(range(1,11))
plt.show()
#调整参数criterion,观察图像变化
score_test =[]
score_train = []
for i in range(10):
clf = DecisionTreeClassifier(random_state=25
,max_depth=i+1
,criterion="entropy")
clf = clf.fit(xtrain,ytrain)
score_tr = clf.score(xtrain,ytrain)
score_te = cross_val_score(clf,x,y,cv=10).mean()
score_train.append(score_tr)
score_test.append(score_te)
print("after:",max(score_test))
#绘制图像
plt.plot(range(1,11),score_train,color="red",label="train")
plt.plot(range(1,11),score_test,color="blue",label="test")
plt.xticks(range(1,11))
plt.legend()
plt.show()
#parameters:本质是一串参数和这串参数对应的,我们希望网格搜索来搜索的参数的取值范围
parameters = {
"splitter":("best","random")
,"min_samples_leaf":[*range(1,20,5)]
,"min_impurity_decrease":[*np.linspace(0,0.5,20)]
}
clf = DecisionTreeClassifier(random_state=25
,max_depth=3
,criterion="entropy")
clf.fit(xtrain,ytrain)
GS = GridSearchCV(clf,parameters,cv=10)
GS = GS.fit(xtrain,ytrain)
print('准确率:',GS.best_score_)
print(GS.best_params_)
结果
绘制超参数曲线,根据函数图像可以看到,当max_depth>3之后,训练集上的得分远远高于测试集上的得分,存在过拟合的现象,因此max_depth=3为较为合适的取值。
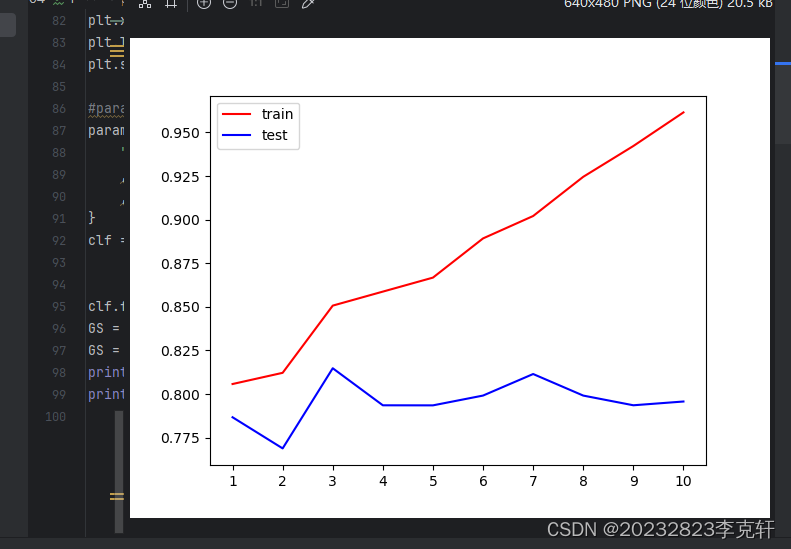
调节参数之后,由图像观察可知,criterion="entropy"使得max_depth=3时两点更加接近,并且得分有所提高,如下图的0.8181730















 1222
1222

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









