






数据处理|加入数据库|报错与解决
acm数据处理
1.将articles.txt文件的【SUCC】去掉,只保留论文的id

with open('./articles.txt', 'r',encoding='utf-8') as f:
for line in f.readlines():
line=line.strip('[SUCC]')
with open('./articles2.txt', 'a',encoding='utf-8') as ff:
ff.write(line.strip()) # 把末尾的'\n'删掉
ff.write("\n")
2.inlink.txt 里面的形式原本是 被引用论文id 引用论文id:
//这个效率慢,不好!
with open('./articles.txt', 'r', encoding='utf-8') as a:
for id in a.readlines():
print(id.strip())
with open('./inlinks.txt', 'r', encoding='utf-8') as f:
with open('./inlinks2.txt', 'a', encoding='utf-8') as ff:
for line in f.readlines():
line = line.strip()
line = line.split()
# print(line[1])
if(id.strip() == line[1]):
ff.write(line[0])
ff.write(" ")
ff.write("\n")
# with open('./articles2.txt', 'a',encoding='utf-8') as ff:
# ff.write(line.strip()) # 把末尾的'\n'删掉
# ff.write("\n")
现在处理过后表示为每一行代表一篇论文引用的其他论文id,如下图所示(没有的则是一个空行)
3.处理outlinks.txt 同理inlinks.txt:
#这个比较快捷
start=0
with open('./articles.txt', 'r', encoding='utf-8') as a:
for id in a.readlines():
# print(id.strip())
with open('./outlinks.txt', 'r', encoding='utf-8') as f:
with open('./outlinks2.txt', 'a', encoding='utf-8') as ff:
lines=f.readlines()
for i in range(start,len(lines)):
line = lines[i].strip()
line = line.split()
print(line[0])
if(id.strip() == line[0]):
ff.write(line[1])
ff.write(" ")
start+=1
if(id.strip() < line[0]):
break
ff.write("\n")
# with open('./articles2.txt', 'a',encoding='utf-8') as ff:
# ff.write(line.strip()) # 把末尾的'\n'删掉
# ff.write("\n")
4.nodes.txt 文件处理:
start=0
with open('./articles.txt', 'r', encoding='utf-8') as a:
for id in a.readlines():
print(id.strip())
with open('./nodes.txt', 'r', encoding='utf-8') as f:
with open('./nodes2.txt', 'a', encoding='utf-8') as ff:
lines=f.readlines()
# print(start)
for i in range(start,len(lines)):
line = lines[i].strip()
line = line.split()
if(id.strip() == line[0]):
for m in range(1,len(line)):
ff.write(line[m])
ff.write(" ")
start+=1
if(id.strip() < line[0]):
break
ff.write("\n")
# with open('./articles2.txt', 'a',encoding='utf-8') as ff:
# ff.write(line.strip()) # 把末尾的'\n'删掉
# ff.write("\n")
通过django将数据添加到数据库中:
1.django目录结构:
建立choose_paper APP,在此处进行model的建立,以及对应url和view逻辑,建立paper数据库,并且将现有数据上传到数据库中
2.model模型建立表结构:(model.py)
from django.db import models
# Create your models here.
"""
该类是用来生成数据库的 必须要继承models.Model
"""
class Paper(models.Model):
"""
创建如下几个表的字段
"""
# 论文id primary_key=True: 该字段为主键
articals = models.CharField('id', primary_key=True, max_length=15)
# 论文作者
authors = models.TextField('作者')
# 论文摘要
abstracts= models.TextField('摘要')
# 论文作者单位
affiliations= models.TextField('作者单位')
# 论文标签
IndexTerms= models.TextField('标签')
# 论文关键字
keywords= models.TextField('关键字')
# 论文题目
nodes= models.TextField('题目')
# 论文作者单位
affiliations= models.TextField('作者单位')
# 论文引用关系,前面引用后面的
inlinks= models.TextField('inlinks')
# 论文引用关系,前面引用后面的
outlinks= models.TextField('outlinks')
GeneralTerms=models.TextField('GeneralTerms')
# 指定表名 不指定默认APP名字——类名(app_demo_Student)
class Meta:
db_table = 'paper'
3.view视图进行数据上传:(view.py)
from django.shortcuts import render
from django.http import HttpResponse
# Create your views here.
from choose_paper.models import Paper
import random
"""
插入数据
"""
def insert(request):
with open('choose_paper/data/articles.txt', 'r', encoding='utf-8') as f1:
with open('choose_paper/data/abstracts.txt', 'r', encoding='utf-8') as f2:
with open('choose_paper/data/authors.txt', 'r', encoding='utf-8') as f3:
with open('choose_paper/data/affiliations.txt', 'r', encoding='utf-8') as f4:
with open('choose_paper/data/GeneralTerms.txt', 'r', encoding='utf-8') as f5:
with open('choose_paper/data/indexTerms.txt', 'r', encoding='utf-8') as f6:
with open('choose_paper/data/inlinks.txt', 'r', encoding='utf-8') as f7:
with open('choose_paper/data/keywords.txt', 'r', encoding='utf-8') as f8:
with open('choose_paper/data/nodes.txt', 'r', encoding='utf-8') as f9:
with open('choose_paper/data/outlinks.txt', 'r', encoding='utf-8') as f10:
articles = f1.readlines()
abstracts = f2.readlines()
authors = f3.readlines()
affiliations = f4.readlines()
GeneralTerms = f5.readlines()
indexTerms= f6.readlines()
inlinks = f7.readlines()
keywords = f8.readlines()
nodes = f9.readlines()
outlinks = f10.readlines()
for i in range(len(articles)):
paper=Paper()
paper.articals=articles[i]
paper.abstracts=abstracts[i]
paper.affiliations=affiliations[i]
paper.authors=authors[i]
paper.GeneralTerms=GeneralTerms[i]
paper.inlinks=inlinks[i]
paper.IndexTerms=indexTerms[i]
paper.keywords=keywords[i]
paper.nodes=nodes[i]
paper.outlinks=outlinks[i]
paper.save()
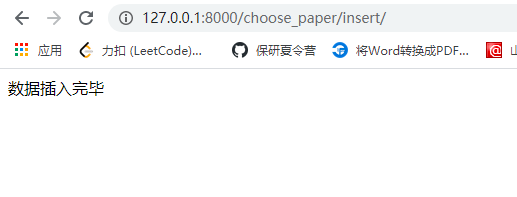
return HttpResponse('数据插入完毕')
4.url 设置,实现打开网页进行数据上传到数据库中:(url.py)
from django.urls import path
from . import views
urlpatterns = [
path('insert/',views.insert, name='insert'),
]
结果:
报错&解决:
1. 报错:InternalError at /choose_paper/insert/ (1366, "Incorrect string value: '\xE7\x94\xA8\xE6…)
解决办法:
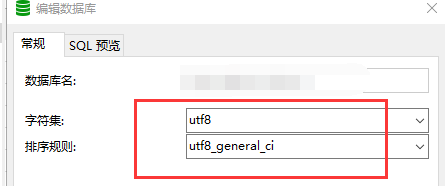
- 首先修改django中的数据库配置信息,修改settings.py配置信息中的TEST
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
# 'NAME': os.path.join(BASE_DIR, 'db.sqlite3'),
'HOST':'127.0.0.1',
'PORT':'3306',
'NAME':'guest',
'USER':'root',
'PASSWORD':'111111',
'TEST': {
'CHARSET' : 'utf8',
'COLLATION':'utf8_general_ci'
}
}
- 然后删掉建好的数据库,重新建库,并且设置数据库
2.报错如下:(index超界)
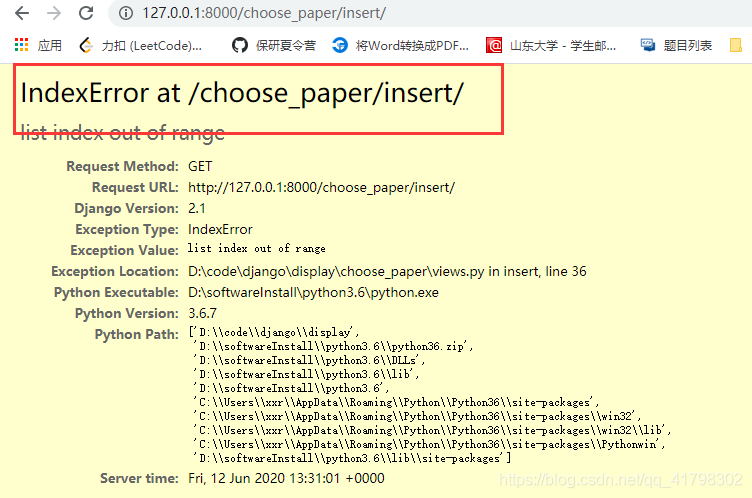
此时发现有的文件种数据和论文id数据长度不一样(比论文id的数目少)
解决办法:将缺少的数据用None(空数据)填充
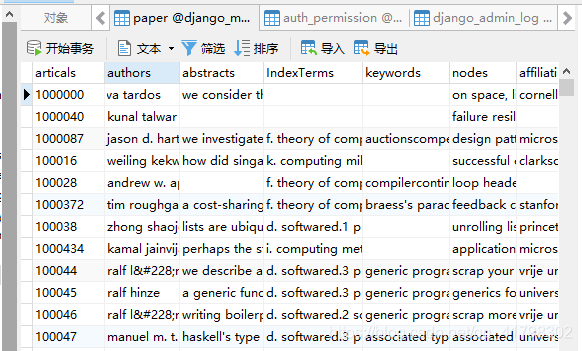
3.数据库的一张表中大小有限,即使传输成功,表中也只有1000行数据,但是我们有几万行的数据,所以最后不得不放弃在数据库中存储,所以采用在本地存储:
参考博客:
https://blog.csdn.net/weixin_43499626/article/details/84351572














 704
704











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









