










在大数据领域里,主要的技术点是数据挖掘、大数据、OLAP、数据统计这几个方面,下面我们来具体看一看。

大数据
大数据是一个大概念,是指用单台计算机软硬件设施难以采集、存储、管理、分析和使用的超大规模的数据集。大数据具有规模大、种类杂、快速化、价值密度低等特点。大数据的“大”是一个相对概念,没有具体标准,如果一定要给一个标准,那么10-100TB通常称为大数据的门槛。
大数据主要就是数据分析,我们可以把数据分析分为以下5个层次:数据统计,OLAP,数据挖掘、数学建模、维度分解。
数据统计
数据统计是最基本、最传统的数据分析,自古有之。是指通过统计学方法对数据进行排序、筛选、运算、统计等处理,从而得出一些有意义的结论。
OLAP
联机分析处理(On-Line Analytical Processing,OLAP)是指基于数据仓库的在线多维统计分析。它允许用户在线地从多个维度观察某个度量值,从而为决策提供支持。
数据挖掘
数据挖掘是指从海量数据中找到人们未知的、可能有用的、隐藏的规则,可以通过关联分析、聚类分析、时序分析等各种算法发现一些无法通过观察图表得出的深层次原因。
数字和趋势
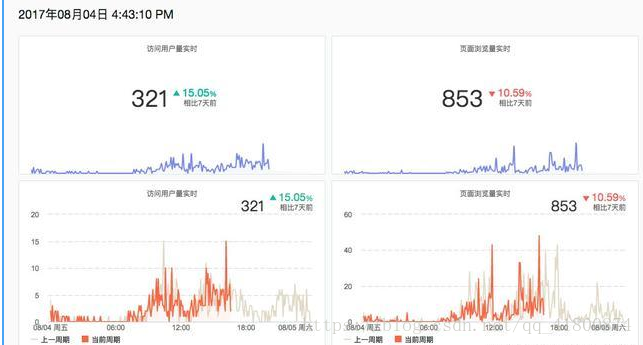
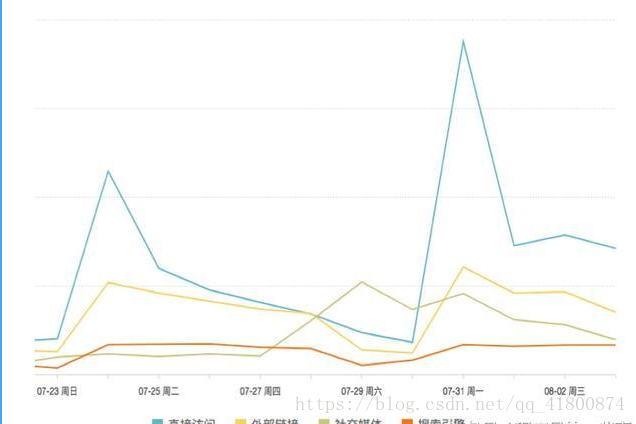
看数字、看趋势是最基础展示数据信息的方式。在数据分析中,我们可以通过直观的数字或趋势图表,迅速了解例如市场的走势、订单的数量、业绩完成的情况等等,从而直观的吸收数据信息,有助于决策的准确性和实时性。
维度分解
当单一的数字或趋势过于宏观时,我们需要通过不同的维度对于数据进行分解,以获取更加精细的数据洞察。在选择维度时,需要仔细思考其对于分析结果的影响。
数学建模
当一个商业目标与多种行为、画像等信息有关联性时,我们通常会使用数学建模、数据挖掘的手段进行建模,预测该商业结果的产生。
总结
大数据是属于科学研究领域,你想成长大数据大牛必须对上面提到的点进行实际的项目实施和思维的培养,对数据敏感。
比较能用的方案: spark+hbase+hvie+hadoop的实用方案。而最基础的hadoop分布式方案需要5台机器。如果你本身有相当功底,要成为熟手需要3~6个月,如果是工作外尝试的情况,时间可能要x2,而且缺少实际项目经验。准备好接受大数据了吗?开始学习吧,提高技能,提高核心竞争力。也给自己的未来一个机会。大数据学习资料分享群119599574 不管你是小白还是大牛,小编我都挺欢迎,今天的源码已经上传到群文件,不定期分享干货,包括我自己整理的一份最新的适合2018年学习的大数据开发和零基础入门教程,欢迎初学和进阶中的小伙伴。














 2167
2167











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









