






简单爬取wallpaper heaven高清壁纸
2021年1月30日更新
由于网站架构更改,以下内容已经并不能再实现爬取
思路大体不变,仅供参考思路
前言:wallpaper heaven是一个拥有百万高清壁纸的网站,其壁纸质量极佳,像我这种懒得用壁纸软件的人,便决定从该网站爬些图片,用来动态切换当作壁纸
URL分析
首先看页面

我们随意点击后查看网址
https://alpha.wallhaven.cc/search?q=&categories=111&purity=100&sorting=random&order=desc
随机尝试对比后发现,q=后面加关键词即可达到搜索效果,
categories=111后面的三个数字即对应了General Anime People三个选项,选中为1,不选为0,
purity=100后面虽然有三个数字,但是只有前两个有用,对应SFW Sketchy,这里的SFW是safe for work(如果你主要想看福利图片,不勾选这个选项即可),选中出现的是可以在工作时浏览的图片(不选中出现的图片,你懂的),Skectchy是写真的意思
sorting指结果相关度,参数有random、toplist等
order指结果排序,有升序和降序两个参数
当然远不止这些参数,还有分辨率,颜色,比例等等,我这里就不赘述了,可以自行尝试
还有非常重要的一点,就是翻页
该网址的翻页很方便,网址后面加一个page参数即可(&page=2即第二页)
程序设计
右击查看元素之后,我们即可获取到该图片的定位,但是定位到的url仅仅只是图片的缩略图,如果要爬取高清大图,我们还需要再进入一层链接
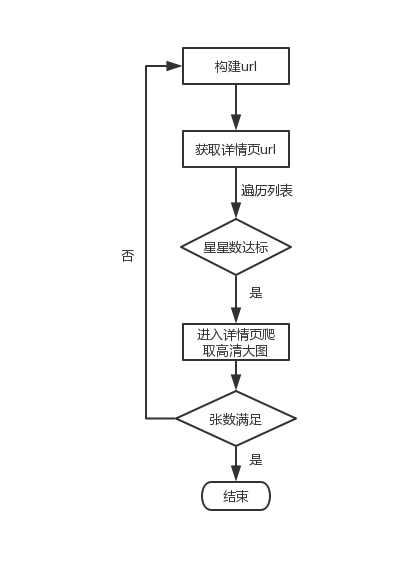
于是整体思路就出来了,先构建url,爬取每页的图片的详情页的网址,获取详情页的网址后进入详情页并获取高清大图的链接,进行爬取
因为并不是所有的图片都是符合我们预期的,为了能让结果更加贴合我们的心意,我们再设置两个参数,一个是星星数量(如下图),每张图片都是有人点赞的,其体现就在于星星的数量,我们只爬取高于一定数量的星星
我们只是为了爬取一定量的图片,并非是全网爬取,所以我们还需要设置一个数量参数,进行限制

程序的流程图大概是这样
代码实现
有了如上的思路之后,代码实现就相对简单了,因为是想实现一个小工具,所以代码里面添加了许多交互的内容,这样也便于封装
代码实现相对简单,这里便不再细讲代码了,可能有写的累赘的地方,且并未太注意细节,代码的鲁棒性不是太强,正在写UI界面,会在新版本中增强鲁棒性
利用pyinstaller这个库可以实现代码的封装,生成exe
对您有些帮助的话记得点个赞哦~
以下是代码
import requests
from lxml import etree
import re
import os
import time
def get_pictures(url,folder_name,dest_count,c):
html = requests.get(url)
res = etree.HTML(html.content)
img_url = res.xpath('//img[@id="wallpaper"]/@src')[0]
img_name = img_url.split('/')[-1]
try:
img_html = requests.get("https:"+img_url)
if not os.path.exists(folder_name):
os.mkdir(folder_name)
with open('./'+folder_name+'/'+img_name,'wb') as f:
f.write(img_html.content)
print("正在下载第 {} 张图片=====> ".format(c+1)+img_name+' -----success!')
return 1
except:
print("正在下载第 {} 张图片=====> ".format(c+1)+img_name+' -----failure!')
return 0
def get_next_url(url,folder_name,stars_num,dest_count,all):
html = requests.get(url)
res = etree.HTML(html.content)
next_urls = res.xpath("//a[@class='preview']/@href")
stars = res.xpath("//div[@class='thumb-info']/a[1]/text()")
res_url = []
sum = all
for i in range(0,len(stars)):
if int(stars[i])>=int(stars_num):
res_url.append(next_urls[i])
for i in res_url:
sum += get_pictures(i,folder_name,dest_count,sum)
if sum >= dest_count:
exit("目标已达成!")
if len(next_urls) == 0:
print("无更多图片!")
time.sleep(3)
exit("0")
return sum
if __name__ == "__main__":
print("请选择获取方式:1.范围选择 2.关键词搜索 3.二者结合")
style = input()
categories = ['0','0','0']
purity = ['0','0','0']
url = ""
keyword = ""
sort_list = ['https://alpha.wallhaven.cc/search?q={}&categories={}&purity={}&sorting=date_added&order=desc&page={}',
'https://alpha.wallhaven.cc/search?q={}&categories={}&purity={}&resolutions=1920x1080&topRange=1M&sorting=toplist&order=desc&page={}',
'https://alpha.wallhaven.cc/search?q={}&categories={}&purity={}&resolutions=1920x1080&sorting=random&order=desc&page={}',
'https://alpha.wallhaven.cc/search?q={}&search_image=&page={}']
if style == '1' or style == '3':
if style == '3':
print("请输入搜索关键词(建议英文):")
keyword = input().replace(' ','+')
print("请选择图片类型:1.General 2.Anime 3.People (可多选,默认全选,空格分割选项)")
selection_str = input()
selection = selection_str.split()
for i in selection:
try:
categories[int(i)-1] = '1'
except:
categories = ['1','1','1']
print("图片附加选项:1.SFW 2.Sketchy (可多选,默认选择1,空格分隔选项,建议选择SFW)")
selection_str = input()
selection = selection_str.split()
for i in selection:
try:
purity[int(i)-1] = '1'
except:
purity = ['1','0','0']
purity[2] = '0'
if selection_str == "":
purity = ['1','0','0']
print("请选择排序方式:1.Latest 2.Toplist 3.Random (单选,默认Random)")
selection_str = input()
count = 1
while selection_str != '1' and selection_str != '2' and selection_str != '3' and count <= 3 and selection_str != "":
print("请正确选择(多次错误则默认选择)")
selection_str = input()
count += 1
if count == 4:
url = sort_list[2]
elif selection_str == "":
url = sort_list[2]
else:
url = sort_list[int(selection_str)-1]
elif style == '2':
print("请输入搜索关键词(建议英文):")
keyword = input().replace(' ','+')
url = sort_list[3]
print("请输入文件夹的名称:")
folder_name = input()
while folder_name == "":
folder_name = input()
print("请输入最低的点赞数:")
stars_num = input()
print("请输入目标图片数量:")
dest_count = input()
all = 0 # 目前爬取的张数,用来控制下载张数
for i in range(1,999):
print('get the page: {}'.format(i))
if style != '2':
print("getting from " + url.format(keyword,"".join(categories),"".join(purity),i))
all = get_next_url(url.format(keyword,"".join(categories),"".join(purity),i),folder_name,stars_num,int(dest_count),all)
else:
print("getting from " + url.format(keyword,i))
all = get_next_url(url.format(keyword,i),folder_name,stars_num,int(dest_count),all)














 7500
7500











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









