




大家好,我是摇光~
本文主要讲解 4种窗口函数(非聚合窗口函数、聚合窗口函数、窗口函数的重命名、动态窗口函数),为了让大家都懂得,我尽量用通俗易懂的讲法讲给大家。
零、前言
一、非聚合窗口函数
非聚合函数有以下函数(注:我只列举了常用的。)
看不明白没关系,我下面会一一对这些进行讲解。
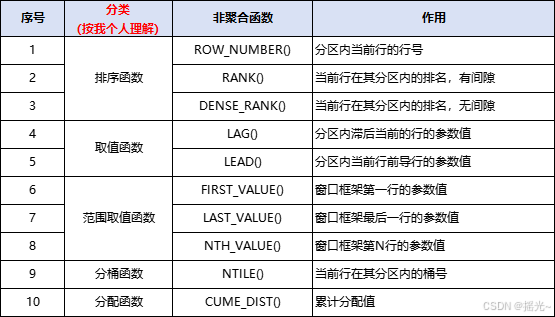
1、排序函数
- 先举个例子:
比如现在有一张公司各部门的工资表,如果你想知道每个部门中工资最高的人,那么就可以用
ROW_NUMBER()、RANK()、DENSE_RANK()函数进行计算。
排序函数作用就是: 在一个区间内(比如将部门分类,一个部门为一个区间),再进行排序(就可以对工资从大到小进行排序),返回排序的序号;那么序号为 1 的就是各个部门中工资最高的人。
如果区间内不存在重复值,计算结果就会一致。,如果有重复值,三个的结果不一样。
- ROW_NUMBER(): 不考虑重复值,会给两个相同值分配不同的编号。
- RANK(): 重复值会生成相同的编号,不过重复值的下一项编号和重复值编号不连续
- DENSE_RANK(): 重复值会生成相同的编号,不过重复值的下一项编号和重复值编号连续
实际案例
- 现有数据:
employee_id | name | department | salary
------------|-------|------------|-------
1 | Alice | HR | 60000
2 | Bob | HR | 60000
3 | Carol | HR | 50000
4 | Dave | IT | 80000
5 | Eve | IT | 75000
6 | Frank | IT | 75000
- SQL语句:
SELECT
employee_id, -- 员工id
name, -- 员工名字
department, -- 员工所属部门
salary, -- 员工工资
ROW_NUMBER() OVER (PARTITION BY department ORDER BY salary DESC) AS row_num,
RANK() OVER (PARTITION BY department ORDER BY salary DESC) AS rank,
DENSE_RANK() OVER (PARTITION BY department ORDER BY salary DESC) AS dense_rank
FROM
employees;
- 解析 SQL:
ROW_NUMBER() OVER (PARTITION BY department ORDER BY salary DESC) AS row_num
ROW_NUMBER() OVER ():是固定写法- 在OVER()里面的
PARTITION BY department:是针对部门进行分区,一个部门一个区间- 在OVER()里面的
ORDER BY salary DESC:是对每个分区内的数据进行从大到小排序AS row_num:别名(row_num)
- 结果展示:
employee_id | name | department | salary | row_num | rank | dense_rank
------------|-------|------------|--------|---------|------|----------
1 | Alice | HR | 60000 | 1 | 1 | 1
2 | Bob | HR | 60000 | 2 | 1 | 1
3 | Carol | HR | 50000 | 3 | 3 | 2
4 | Dave | IT | 80000 | 1 | 1 | 1
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 751
751

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









