







在工作开发中一直会用到Map集合进行业务逻辑的构建,但是只知道使用方法对于一个想要长期发展的程序员来说是远远不够的,我们要在熟练掌握使用方法的基础上多去查看其底层源码,长期下来自己的代码技术水平才会有所提高,这里健超总结归纳了HashMap的底层实现原理,如有遗漏的地方还请大家多多补充。
HashMap存储数据采用的是哈希表结构,存储的元素没有顺序,但是保证元素不重复。
HashMap的底层是由数组+链表+哈希表组成
- 数组:存储区间连续,时间复杂度为O(1),随机读取效率很高,插入和删除效率低,大小固定不易拓展
- 链表:区间离散,时间复杂度为O(N),插入删除速度快,查询效率低
- 哈希表:结合了数组和链表的有点,实现查询效率和插入删除效率都很高
工作原理
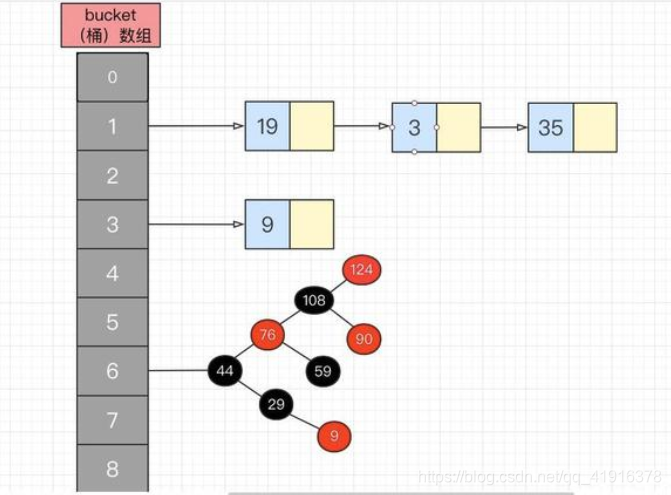
HashMap基于hashing原理,我们通过put()和get()方法储存和获取对象。当我们将键值对传递给put()方法时,它调用键对象的hashCode()方法来计算hashcode,让后找到bucket位置来储存值对象,来放entry键值对。当获取对象时,通过键对象的equals()方法找到正确的键值对,然后返回值对象。HashMap使用链表来解决碰撞问题,当发生碰撞了,对象将会储存在链表的下一个节点中。 HashMap在每个链表节点中储存键值对对象。
Map.put实现原理
第一步首先将k,v封装到Node对象当中(节点)。第二步它的底层会调用K的hashCode()方法得出hash值。第三步通过哈希表函数/哈希算法,将hash值转换成数组的下标,下标位置上如果没有任何元素,就把Node添加到这个位置上。如果说下标对应的位置上有链表。此时,就会拿着k和链表上每个节点的k进行equal。如果所有的equals方法返回都是false,那么这个新的节点将被添加到链表的末尾。如其中有一个equals返回了true,那么这个节点的value将会被覆盖。
Map.get实现原理
第一步:先调用k的hashCode()方法得出哈希值,并通过哈希算法转换成数组的下标。第二步:通过上一步哈希算法转换成数组的下标之后,在通过数组下标快速定位到某个位置上。重点理解如果这个位置上什么都没有,则返回null。如果这个位置上有单向链表,那么它就会拿着参数K和单向链表上的每一个节点的K进行equals,如果所有equals方法都返回false,则get方法返回null。如果其中一个节点的K和参数K进行equals返回true,那么此时该节点的value就是我们要找的value了,get方法最终返回这个要找的value。
HashMap集合key部分的元素需要重写equals方法,因为equals默认比较是两个对象内存地址
注意JDK8之后
JDK8之后,如果哈希表单向链表中元素超过8个,那么单向链表这种数据结构会变成红黑树数据结构。当红黑树上的节点数量小于6个,会重新把红黑树变成单向链表数据结构。














 8154
8154











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









