







ETL,是英文 Extract-Transform-Load 的缩写,用来描述将数据从来源端经过抽取(extract)、交互转换(transform)、加载(load)至目的端的过程。ETL是将业务系统的数据经过抽取、清洗转换之后加载到数据仓库的过程,因而也称为数据仓库技术。其目的是将分散、零乱、标准不统一的数据整合到一起,为企业的决策提供分析依据。
可以看出,ETL要做三部分工作,数据抽取、数据的清洗转换和数据的加载。数据抽取一般是通过工具从各个不同的数据源抽取到一个中间层中,其中可以做一些数据的清洗和转换,这个过程要注意抽取效率。数据清洗是指将不符合要求的数据除掉,包括错误数据、不完整数据、重复数据。数据转换要做的工作是把所有数据的模板、标准、计算规则等进行统一,如存储结构、数据编码等。清洗转换好的数据按着标准的ETL架构存储到数据仓库中,以备进行数据分析和决策。
实例:
比如我们有一份这样的数据:
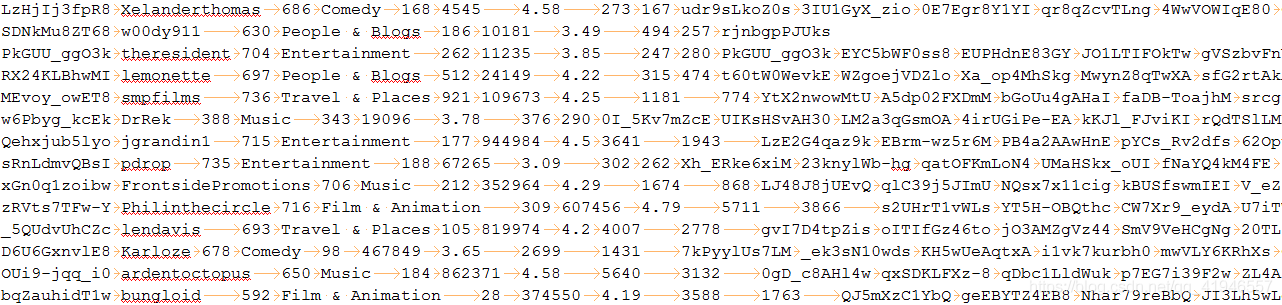
相信大家都写过mapreduce的wordcount
在wc中。你进行了每行数据的处理,split(“ ”),等到每个数据,然后进行组合kv然后reduce合并。
但是如果我们拿到的数据不符合进入数据表中的格式呢。
所以我们要进行,数据的数据抽取、数据的清洗转换和数据的加载。
所就拿上面的数据我们做出分析:首先给出数据的数据结构:
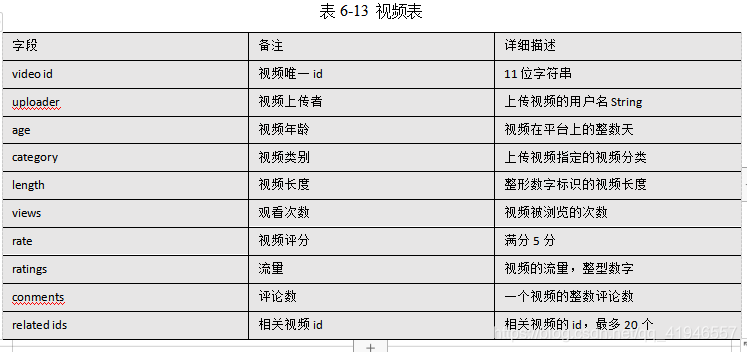
可以看出10个字段:
根据这些字段做出表的结构:
create table gulivideo_ori(
videoId string,
uploader string,
age int,
category array<string>,
length int,
views int,
rate float,
ratings int,
comments int,
relatedId array<string>)
row format delimited
fields terminated by "\t"
collection items terminated by "&"
stored as textfile;但对于这些原始数据呢?
肯定是插入失败的。
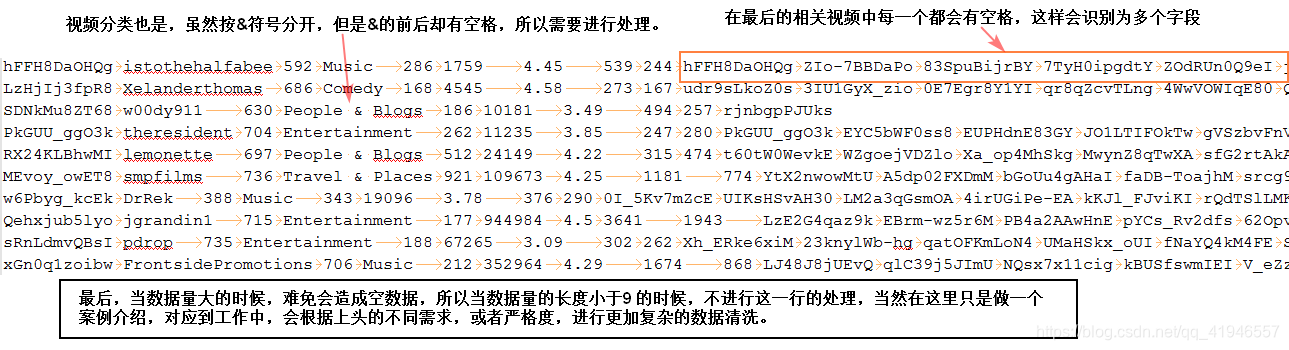
那么API怎么写呢?在这里我是用java。
共有三个类:【注使用的idea maven项目】
首先pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.henu</groupId>
<artifactId>ETL</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-yarn-common</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-yarn-client</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-yarn-server-common</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-yarn-server-resourcemanager</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-yarn-server-nodemanager</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-yarn-server-applicationhistoryservice</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-shuffle</artifactId>
<version>2.6.0</version>
</dependency>
</dependencies>
</project>ETLUtilpackage com.henu;
/**
* @author George
* @description
**/
public class ETLUtil {
public static String oriString2ETLString(String ori){
StringBuilder etlString = new StringBuilder();
String[] splits = ori.split("\t");
if(splits.length < 9) return null;
splits[3] = splits[3].replace(" ", "");
for(int i = 0; i < splits.length; i++){
if(i < 9){
if(i == splits.length - 1){
etlString.append(splits[i]);
}else{
etlString.append(splits[i] + "\t");
}
}else{
if(i == splits.length - 1){
etlString.append(splits[i]);
}else{
etlString.append(splits[i] + "&");
}
}
}
return etlString.toString();
}
}
VideoETLMapperpackage com.henu;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* @author George
* @description
**/
public class VideoETLMapper extends Mapper<Object, Text, NullWritable, Text> {
Text text = new Text();
@Override
protected void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String etlString = ETLUtil.oriString2ETLString(value.toString());
if(StringUtils.isBlank(etlString)) return;
text.set(etlString);
context.write(NullWritable.get(), text);
}
}
VideoETLRunnerpackage com.henu;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.IOException;
/**
* @author George
* @description
**/
public class VideoETLRunner implements Tool {
private Configuration conf = null;
public void setConf(Configuration conf) {
this.conf = conf;
}
public Configuration getConf() {
return this.conf;
}
public int run(String[] args) throws Exception {
conf = this.getConf();
conf.set("inpath", args[0]);
conf.set("outpath", args[1]);
Job job = Job.getInstance(conf);
job.setJarByClass(VideoETLRunner.class);
job.setMapperClass(VideoETLMapper.class);
job.setMapOutputKeyClass(NullWritable.class);
job.setMapOutputValueClass(Text.class);
job.setNumReduceTasks(0);
this.initJobInputPath(job);
this.initJobOutputPath(job);
return job.waitForCompletion(true) ? 0 : 1;
}
private void initJobOutputPath(Job job) throws IOException {
Configuration conf = job.getConfiguration();
String outPathString = conf.get("outpath");
FileSystem fs = FileSystem.get(conf);
Path outPath = new Path(outPathString);
if(fs.exists(outPath)){
fs.delete(outPath, true);
}
FileOutputFormat.setOutputPath(job, outPath);
}
private void initJobInputPath(Job job) throws IOException {
Configuration conf = job.getConfiguration();
String inPathString = conf.get("inpath");
FileSystem fs = FileSystem.get(conf);
Path inPath = new Path(inPathString);
if(fs.exists(inPath)){
FileInputFormat.addInputPath(job, inPath);
}else{
throw new RuntimeException("HDFS中该文件目录不存在:" + inPathString);
}
}
public static void main(String[] args) {
try {
int resultCode = ToolRunner.run(new VideoETLRunner(), args);
if(resultCode == 0){
System.out.println("Success!");
}else{
System.out.println("Fail!");
}
System.exit(resultCode);
} catch (Exception e) {
e.printStackTrace();
System.exit(1);
}
}
}
下一步就是对项目进行打包,然后放在linux上运行了。
将原始的数据上传到hdfs上,然后运行jar包对数据进行处理。
执行命令:
[root@henu2 ~]# hadoop jar ETL-1.0-SNAPSHOT.jar com.henu.VideoETLRunner /guiliVideo/video/2008/0222 /guiliVideo/output/video/2008/022
2运行:
具体操作类似:https://blog.csdn.net/qq_41946557/article/details/102785927
清洗后的数据展示:

ok!!!数据清洗好的,下一步就是导入数据,分析数据了》》》
且听下回分解!!!














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









