









今天这一节内容是关于Keras应用分析的最后一节,在熟悉了Keras的基础知识之后,下面几节我们就可以正式接触Tensorflow2.0。根据博主多处查阅,最终还是发现Tensorflow的官方教程好一点,但是官方的代码很多没有注释,不方便初学者理解,因此下几节的内容会主要会针对Tensorflow2.0的官方文档的代码进行讲解和运行,在之后当我们对Tensorflow2.0有了一定了解,我会详细的用Tensorflow2.0带大家搭建许多经典模型比如Alexnet、Googlenet和U-Net等等,对一些经典论文进行复现,并分享我曾经做的一些小项目的代码。如果对这些内容有不大清楚的朋友们,可以观看前面几节的代码,希望大家多多支持。
其它话不多说,先分享这节的内容。我们将在这节分别构建MLP对IMDb电影集做情感分析。IMDb全称为网络电影数据库,里面包含各种电影数据,我们这次主要的任务是从IMDb中摘取影评文字(一共50000项),里面分别有25000项正面评价及25000项负面评价,我们将用Keras搭建模型进行训练,预测出新影评文字是正面评价还是负面的评价。
一.IMDb数据集的加载和读取
1.导入相关库。其中sequence库用于修正数据的长度,Tokenizer库用于建立字典(后续需要将文字映射为数字),re库为正则表达式处理(影评很多是爬虫下载的,含有html标签,可以用正则表达式去除),tarfile库用于解压缩下载的数据集文件。
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras.preprocessing import sequence #修正数据长度
from tensorflow.keras.preprocessing.text import Tokenizer #建立字典
import urllib.request #下载远程数据
import os #判断文件是否存在
import tarfile #解压缩文件
import re #正则表达式
import numpy as np2.文件下载。和上一节一样,我们可以用request库进行下载,但是直接代码运行下载可能速度很慢,大家可以把url链接里的内容复制到迅雷里下载,速度会快一些,之后把压缩包黏贴在自己的keras数据目录下即可。
url="http://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz"
filepath = "aclImdb_v1.tar.gz"
if not os.path.isfile(filepath): #判断数据文件是否存在,如果不存在则下载
result = urllib.request.urlretrieve(url,filepath) #下载数据
print("download")3.文件解压缩。aclImdb_v1.tar.gz里包含的文件夹名是aclImdb,因此我们解压缩判断的时候是判断aclImdb这个名字。
if not os.path.exists("aclImdb"):
tfile = tarfile.open("aclImdb_v1.tar.gz",'r:gz') #创建压缩包名
result=tfile.extractall("") #进行解压缩,提取文件
4.定义正则表达式。影评很多是爬虫下载的,含有html标签的代码信息,我们需要用正则表达式去除这部分我们不需要的内容。正则表达式的语法大家可以查看下其它博客,有更详细的介绍。
def rm_tags(text):
re_tag = re.compile(r'<[^>]+>') #匹配HTML标签
return re_tag.sub('',text) #将html标签替换为空白值
5.定义函数,读取文件里的所有数据,并保存到列表里。这里展示一下文件夹里面的东西,方便大家理解。因为数据集没有提供标签,所以我们人为进行创建1(正面)和0(反面)代表二分类的结果。


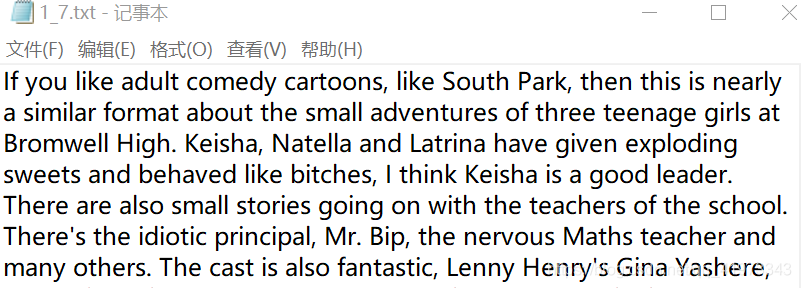
其中我们的影评内容都保存在这些txt文档里。
def read_files(filetype):
path = "aclImdb/" #数据集路径
file_list = []
positive_path = path+filetype+"/pos/" #正面评论数据集路径,这里读到的是文件名
for i in os.listdir(positive_path):
file_list+=[positive_path+i]
negative_path = path+filetype+"/neg/" #反面评论数据集路径,这里读到的是文件名
for i in os.listdir(negative_path):
file_list+=[negative_path+i]
print("read:",filetype,"file_len:",len(file_list))
all_labels=([1]*12500+[0]*12500) #人为制作标签,1代表正面,0代表反面
all_labels=np.array(all_labels) #列表转为数组,不然无法训练
all_texts = []
for i in file_list:
with open(i,encoding='utf8') as file_input: #根据列表的文件名打开所有文件
all_texts +=[rm_tags(" ".join(file_input.readlines()))] #逐行读入正则化后的文件内容
return all_labels,all_texts6.调用该函数,制作训练集、测试集并打印长度。
y_train,x_train = read_files("train")
y_test,x_test = read_files("test")![]()
二.IMDb数据集的预处理
1.建立文字转数字字典。我们都知道深度学习模型只能训练数字数据,因此我们需要将影评文字转化为数字列表。那么如何转换?当我们要将一种语言翻译成另一种语言时需要字典,因此文字转数字也是一样。我们可以使用keras的Tokenizer模块完成这个功能。在这里我们只选取了排序前2000名的英文单词加入字典,因为2000名后的单词出现概率小,对我们的模型影响不大,当然选取多一点也是可以的。下图即是我们影评文字中对应的出现频率最高的2000词字典。
token = Tokenizer(num_words=2000)
token.fit_on_texts(x_train)
print(token.word_index) #打印单词对印的数字列表

2.将token应用在我们的数据集上,使每段话转换为数字。
x_train_seq = token.texts_to_sequences(x_train)
x_test_seq = token.texts_to_sequences(x_test)3.打印其中一个影评,查看结果。
print(x_train_seq[0])
我们发现原本的一段文字已经变成了数字。
4.利用Sequence库设置每个数据大小。大家都知道神经网络输入层是要求所有数据都要有固定统一大小的,但我们的影评数据大小不一,因此我们可以用这个库对所有影评数据截长补短,长的影评截掉,短的影评补充上去,使他们大小相等。
x_train_digit = sequence.pad_sequences(x_train_seq,maxlen=100) #maxlen代表你想要的数据长度
x_test_digit = sequence.pad_sequences(x_test_seq,maxlen=100)x_train_digit[0].shape![]()
我们发现数据长度已经被修改到了100。
三.搭建模型
1.创建Sequential线性堆叠模型。
model = tf.keras.models.Sequential()2.添加模型层。在这里注意的是我们添加了一层Embedding层,这个层的名字为嵌入层,为什么需要这个层呢?我们都知道我们虽然前面把文字转化成了数字,但是它们之间却是没有关联的。然而正常生活中,我们说的话很多是带有逻辑,前后相关的,因此我们需要把文字间的联系考虑进去。而Embedding层的作用就是将数字映射为多维几何空间的向量,而向量空间有个特征就是相似的值在空间内会比较接近,因此就可以起到一定的前后联系作用,增加我们模型的准确率。
#input_dim为2000因为我们有2000个词字典,input_length为100是我们的数据长度设置成了统一100
model.add(layers.Embedding(input_dim=2000,output_dim=32,input_length=100))
model.add(layers.Dropout(0.2))
model.add(layers.Flatten())
model.add(layers.Dense(units=256,activation='relu'))
model.add(layers.Dropout(0.2))
model.add(layers.Dense(units=1,activation='sigmoid'))3.打印模型概要。
print(model.summary())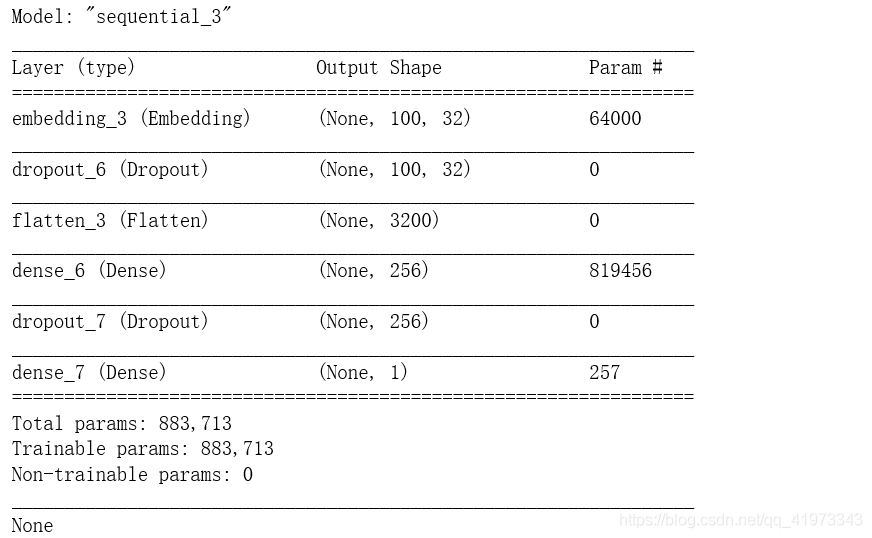
四.模型设置及训练
1.设置模型参数。因为是二分类任务,因此损失函数为binary。
model.compile(optimizer='adam',loss='binary_crossentropy',metrics=['accuracy'])2.训练模型。
train_history = model.fit(x_train_digit,y_train,batch_size=100,epochs=10,verbose=2,validation_split=0.2)
五.模型测试及预测
1.模型测试。
scores = model.evaluate(x_test_digit,y_test,verbose=2)
print(scores[1])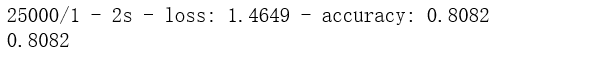
2.模型预测,并将结果转化为一维值。
predict = model.predict_classes(x_test_digit).reshape(-1)
predict[:10] #预测前10个值![]()
3.定义函数,显示影评和预测结果。
sentimenDict={1:"正面的",0:"负面的"}
def display_test_sentiment(i):
print(x_test[i])
print("label:",sentimenDict[y_test[i]],"predict",sentimenDict[predict[i]]) #预测的数字映射成字典的值显示
display_test_sentiment(3)
这是本节的所有内容,谢谢大家的支持和观看,有疑问探讨的地方欢迎留言。














 463
463











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









