




前言
MySQL作为最流行的关系型数据库管理系统之一,其强大的查询功能可以帮助用户高效地获取和管理数据。除了基础的增删改查操作外,MySQL还提供了许多高级查询功能,能够处理复杂的业务场景和数据需求。
本文旨在系统介绍MySQL的高阶查询语句,包括排序、分组、限制结果、别名设置、子查询、视图应用等,帮助读者全面提升数据库查询技能。
一、常用查询进阶
1.1 按关键字排序
在使用SELECT语句从MySQL数据库中查询数据时,经常需要对结果集进行排序。ORDER BY语句可用于实现这一功能,支持单字段或多字段排序。
1.1.1 排序语法
SELECT column1, column2, ...
FROM table_name
ORDER BY column1, column2, ... ASC|DESC;
ASC表示升序排列,为默认排序方式,可省略DESC表示降序排列- ORDER BY可与WHERE子句联用,对查询结果进一步过滤
1.1.2 排序示例
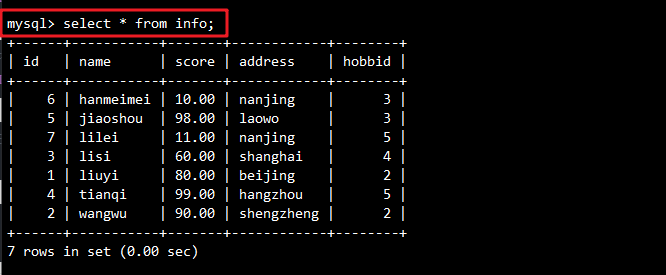
示例数据表结构:数据库有一张info表,记录了学生的id,姓名,分数,地址和爱好。
CREATE TABLE info (
id INT,
name VARCHAR(10) PRIMARY KEY NOT NULL,
score DECIMAL(5,2),
address VARCHAR(20),
hobbid INT(5)
);
insert into info values(1,'liuyi',80,'beijing',2);
insert into info values(2,'wangwu',90,'shengzheng',2);
insert into info values(3,'lisi',60,'shanghai',4);
insert into info values(4,'tianqi',99,'hangzhou',5);
insert into info values(5,'jiaoshou',98,'laowo',3);
insert into info values(6,'hanmeimei',10,'nanjing',3);
insert into info values(7,'lilei',11,'nanjing',5);
单字段排序
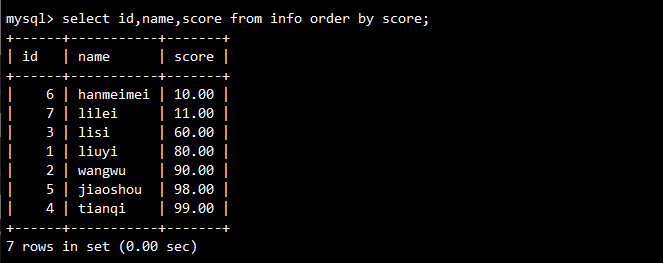
-- 按分数升序排列(默认)
SELECT id, name, score FROM info ORDER BY score;
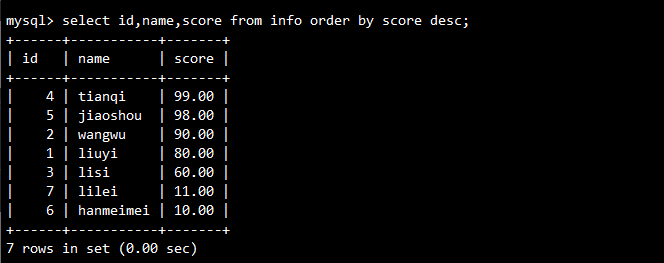
-- 按分数降序排列
SELECT id, name, score FROM info ORDER BY score DESC;
带条件排序
-- 筛选南京学生并按分数降序排列
SELECT name, score
FROM info
WHERE address='nanjing'
ORDER BY score DESC;

多字段排序
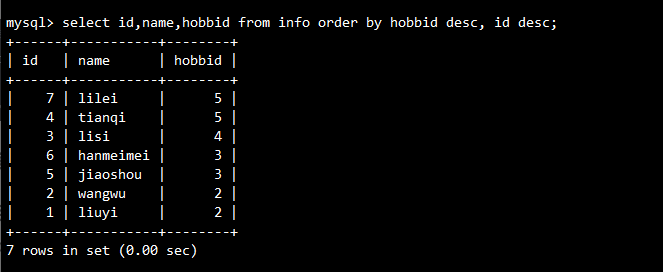
-- 先按兴趣ID降序,相同兴趣ID再按ID降序
SELECT id, name, hobbid
FROM info
ORDER BY hobbid DESC, id DESC;
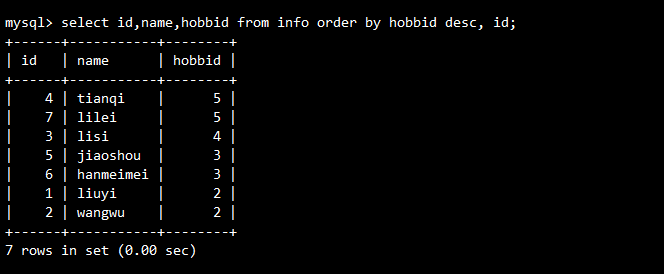
-- 先按兴趣ID降序,相同兴趣ID再按ID升序
SELECT id, name, hobbid
FROM info
ORDER BY hobbid DESC, id ASC;
1.2 区间判断及查询不重复记录
1.2.1 逻辑运算符应用
MySQL支持使用AND/OR进行多条件查询:
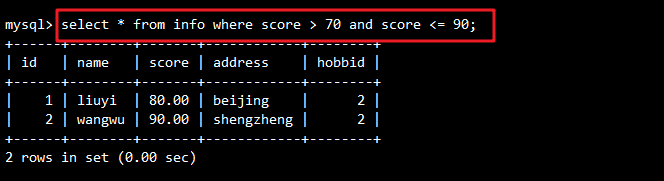
-- 查询分数在70到 90之间的记录
SELECT * FROM info WHERE score > 70 AND score <= 90;
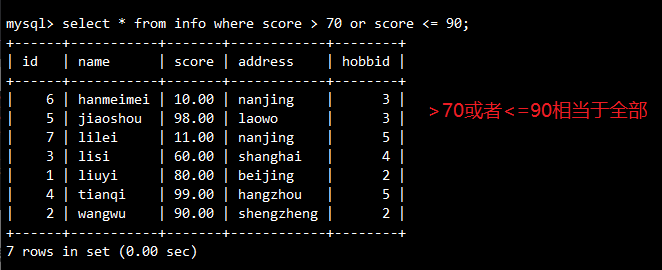
-- 查询分数大于70或小于等于90的记录
SELECT * FROM info WHERE score > 70 OR score <= 90;
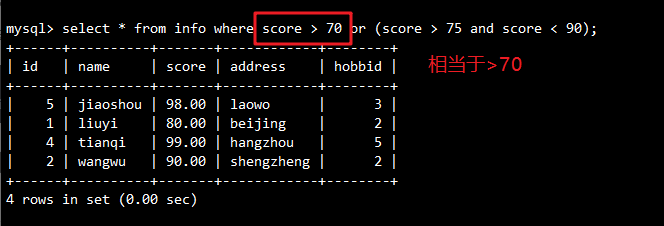
-- 复杂条件查询
SELECT * FROM info WHERE score > 70 OR (score > 75 AND score < 90);
1.2.2 查询不重复记录
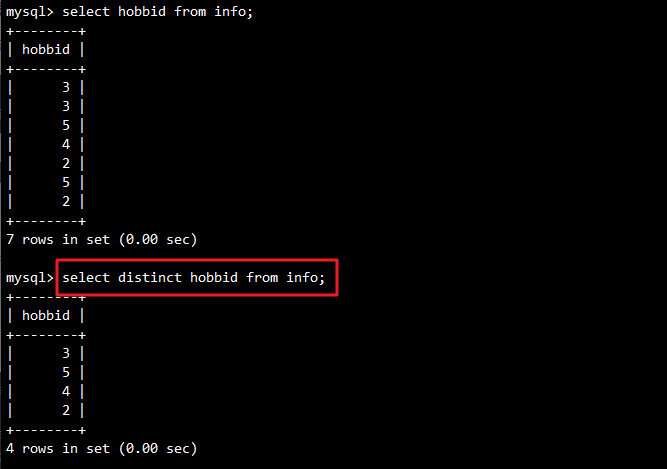
使用DISTINCT关键字去除重复记录:
-- 查询不重复的兴趣ID
SELECT DISTINCT hobbid FROM info;
二、高级查询技术
2.1 结果分组处理
GROUP BY语句可将查询结果按指定字段分组,常与聚合函数配合使用。
常用的聚合函数包括:计数(COUNT)、 求和(SUM)、求平均数(AVG)、最大值(MAX)、最小值(MIN),GROUP BY 分组的时候可以按一个或多个字段对结果进行分组处理。
2.1.1 分组语法
SELECT column_name, aggregate_function(column_name)
FROM table_name
WHERE column_name operator value
GROUP BY column_name;
2.1.2 分组示例
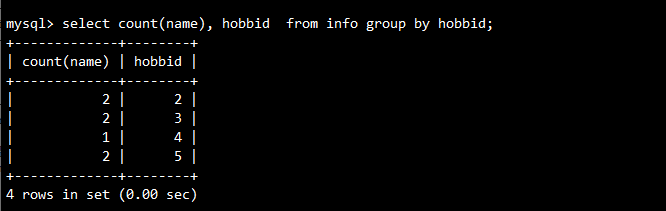
-- 按兴趣进行分组,计算相同分数的学生个数(基于name个数进行计数)
SELECT COUNT(name), hobbid FROM info GROUP BY hobbid;
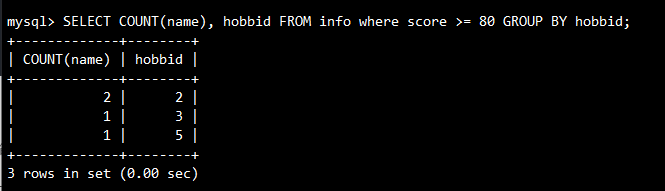
-- 结合where语句,筛选分数大于等于80的分组,计算学生个数
SELECT COUNT(name), hobbid
FROM info
WHERE score >= 80
GROUP BY hobbid;
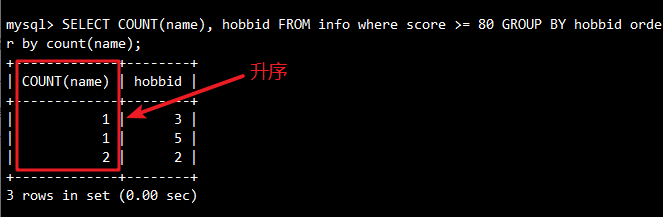
-- 分组后排序,结合order by把计算出的学生个数按升序排列
SELECT COUNT(name), hobbid
FROM info
WHERE score >= 80
GROUP BY hobbid
ORDER BY COUNT(name) ASC;
2.2 限制结果条目
LIMIT子句用于限制查询结果返回的记录数。
在使用 MySQL SELECT 语句进行查询时,结果集返回的是所有匹配的记录(行)。有时候仅需要返回第一行或者前几行,这时候就需要用到LIMIT子句。
2.2.1 限制语法
SELECT column1, column2, ...
FROM table_name
LIMIT [offset,] number;
- offset:位置偏移量,从0开始计数
- number:返回记录行的最大数目
2.2.2 限制示例
-- 查询前3行记录
SELECT * FROM info LIMIT 3;
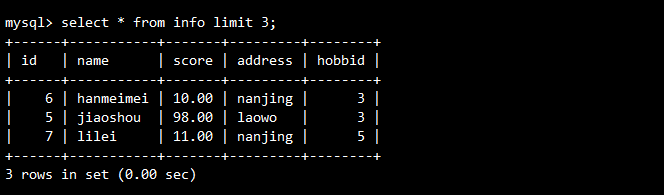
-- 从第4行开始显示3行内容
SELECT * FROM info LIMIT 3,3;
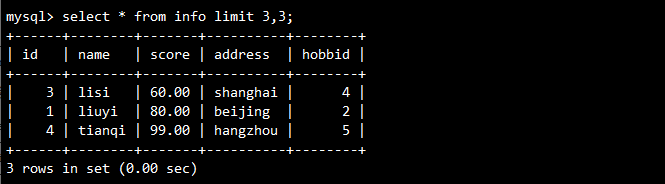
-- 按ID升序排列显示前三行
SELECT id, name FROM info ORDER BY id LIMIT 3;
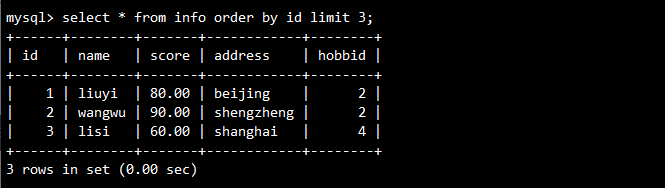
-- 按ID升序排列时,输出最后三行记录
SELECT id, name FROM info ORDER BY id DESC LIMIT 3;
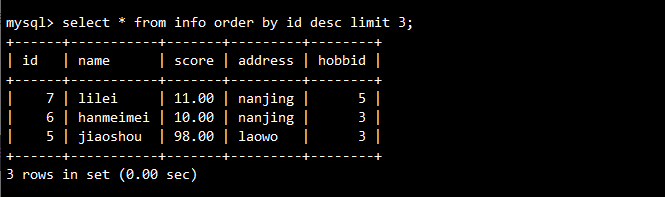
2.3 设置别名
当表的名字比较长或者表内某些字段比较长时,可以使用别名(Alias)简化长表名或字段名,提高查询可读性。
2.3.1 别名语法
列别名
SELECT column_name AS alias_name FROM table_name;
在使用 AS 关键字后,可以通过 alias_name 替代 table_name,其中 AS 关键字是可选的。它为表或列提供临时名称,仅在查询过程中有效,不会改变数据库中实际的表名或字段名。
表别名
SELECT column_name(s) FROM table_name AS alias_name;
如果表的长度比较长,可以使用 AS 给表设置别名,在查询的过程中直接使用别名
2.3.2 别名示例
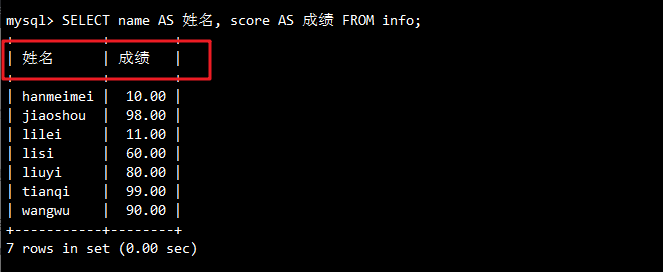
-- 列别名设置
SELECT name AS 姓名, score AS 成绩 FROM info;
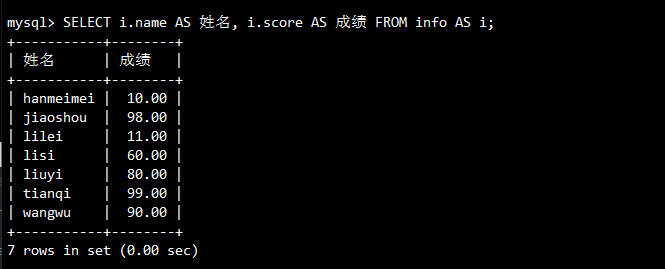
-- 表别名设置
SELECT i.name AS 姓名, i.score AS 成绩 FROM info AS i;
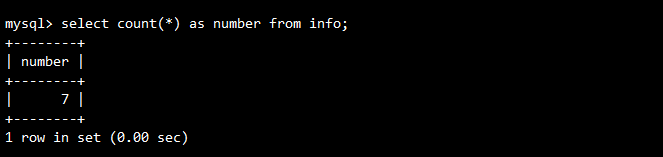
-- 统计表记录数并使用别名
SELECT COUNT(*) AS number FROM info;
-- 或者
SELECT COUNT(*) number FROM info;
使用场景:
- 对复杂的表进行查询的时候,别名可以缩短查询语句的长度
- 多表相连查询的时候(通俗易懂、减短sql语句)
此外,AS 还可以作为连接语句的操作符。
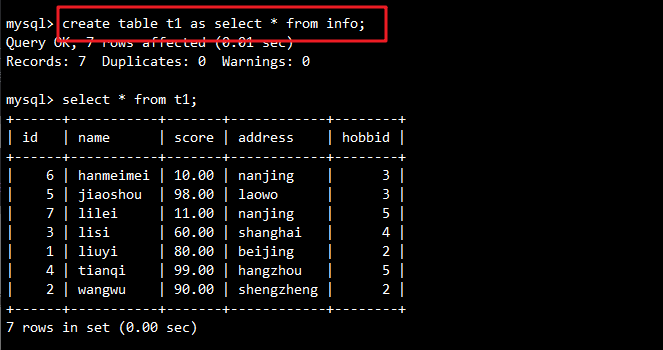
例如:创建t1表,将info表的查询记录全部插入t1表:
-- 使用AS创建新表
CREATE TABLE t1 AS SELECT * FROM info;
-- 此处AS起到的作用:
1、创建了一个新表t1 并定义表结构,插入表数据(与info表相同)
2、但是”约束“没有被完全”复制“过来,如果原表设置了主键,那么附表的default字段会默认设置一个0
3、与create table t1 (select * from info);作用类似
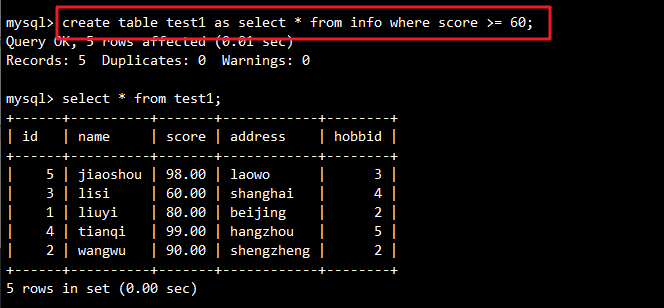
-- 带条件的表创建
CREATE TABLE test1 AS SELECT * FROM info WHERE score >= 60;
注意事项:
- 设置表别名时,需确保该别名不与数据库中其他表名发生冲突。
- 列别名会显示在查询结果中,而表别名仅用于查询执行过程,不会在最终结果里显示。
2.4 通配符应用
通配符主要用于替换字符串中的部分字符,通过部分字符的匹配将相关结果查询出来。
通配符与LIKE运算符配合使用,并协同WHERE子句共同来完成查询任务,实现模糊查询。
2.4.1 通配符类型
常用的通配符有两个,分别是:
- %:匹配零个、一个或多个字符
- _:匹配单个字符
2.4.2 通配符示例
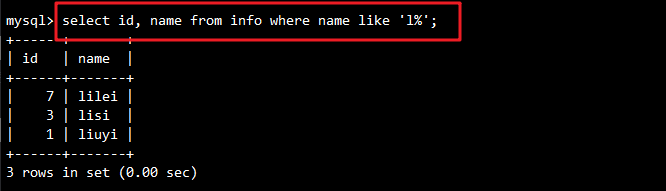
-- 查询名字以l开头的记录
SELECT id, name FROM info WHERE name LIKE 'l%';
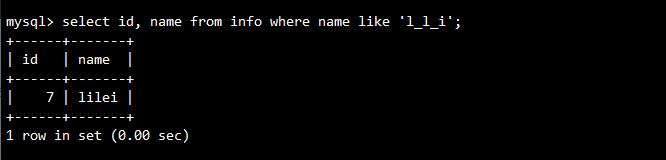
-- 查询名字中l和i中间有一个字符的记录
SELECT id, name FROM info WHERE name LIKE 'l_l_i';
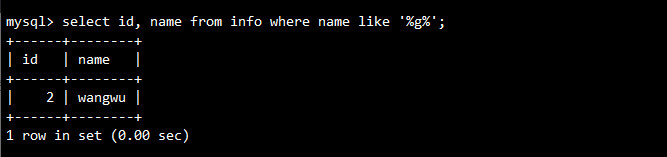
-- 查询名字中包含g的记录
SELECT id, name FROM info WHERE name LIKE '%g%';
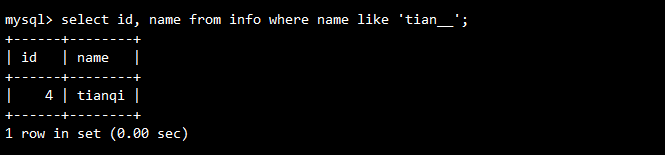
-- 查询tian后面跟二个字符的名字
SELECT id, name FROM info WHERE name LIKE 'tian__';
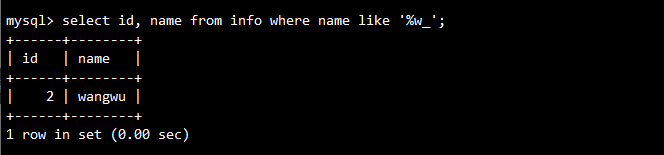
-- 组合使用通配符
SELECT id, name FROM info WHERE name LIKE '%w_';
2.5 子查询
2.5.1 子查询概述
子查询,也称为内查询或嵌套查询,是指在一个查询语句中嵌套另一个查询语句。子查询先于主查询执行,其返回的结果作为外层主查询的条件,用于进一步的查询过滤。
子查询可以与主查询操作同一张表,也可以操作不同的表。
同表示例:
SELECT name, score FROM info WHERE id IN (SELECT id FROM info WHERE score > 80);
- 主查询:
SELECT name, score FROM info WHERE id - 子查询:
SELECT id FROM info WHERE score > 80
子查询的作用是通过内部 SQL 语句过滤出一个结果集,作为主查询的判断条件。关键字 IN 用于关联主查询和子查询的结果。
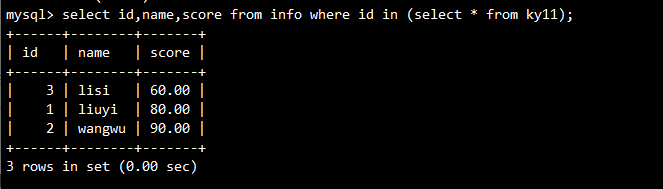
多表子查询示例:
-- 创建新表 ky11
CREATE TABLE ky11 (id INT);
INSERT INTO ky11 VALUES (1), (2), (3);
-- 多表子查询
SELECT id, name, score
FROM info
WHERE id IN (SELECT * FROM ky11);
返回结果:
子查询不仅可用于 SELECT 语句,还可用于 INSERT、UPDATE、DELETE 语句,并支持多层嵌套。
2.5.2 子查询语法与 IN 关键字
语法:
<表达式> [NOT] IN <子查询>
- 若表达式与子查询返回结果中的某个值匹配,返回
TRUE,否则返回FALSE。 - 使用
NOT时逻辑相反。 - 子查询只能返回一列数据(若需多列需使用多层嵌套)。
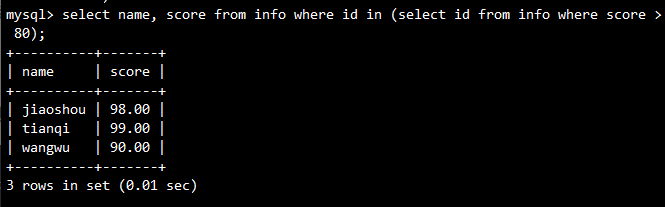
示例:查询分数大于80的记录
SELECT name, score
FROM info
WHERE id IN (SELECT id FROM info WHERE score > 80);
2.5.2.1 IN在 INSERT 语句中的应用
子查询的结果集可通过 INSERT 语句插入到其他表中。
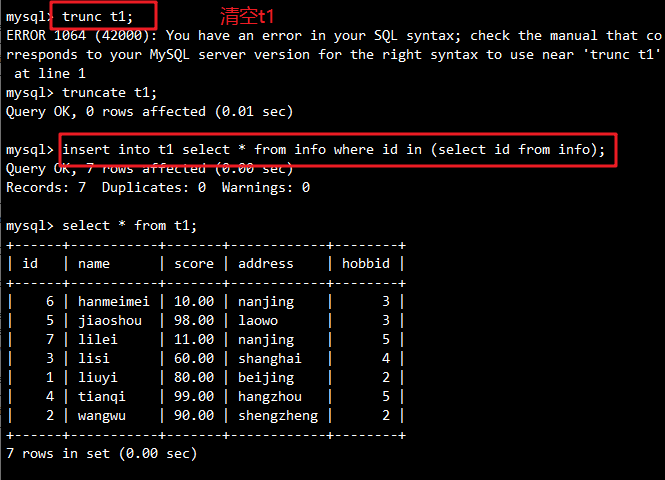
示例:将 info 表中所有记录插入到 t1 表
INSERT INTO t1
SELECT * FROM info
WHERE id IN (SELECT id FROM info);
2.5.2.2 IN在 UPDATE 语句中的应用
UPDATE 语句中的子查询可用于更新单列或多列数据。
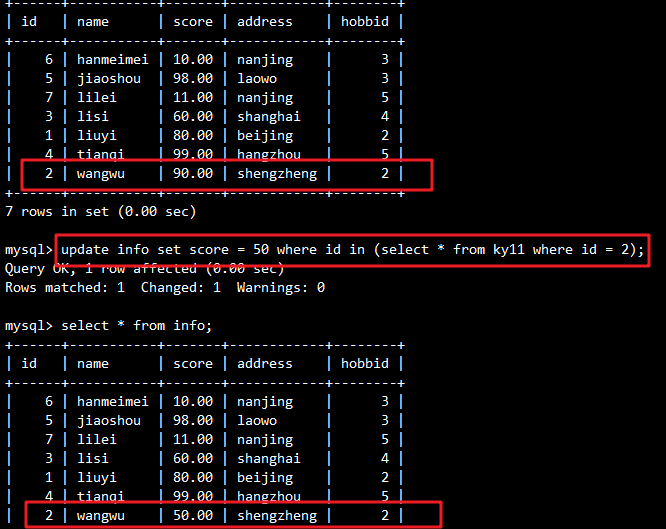
示例:将ky11表中id=2 的记录的分数改为50
UPDATE info
SET score = 50
WHERE id IN (SELECT * FROM ky11 WHERE id = 2);
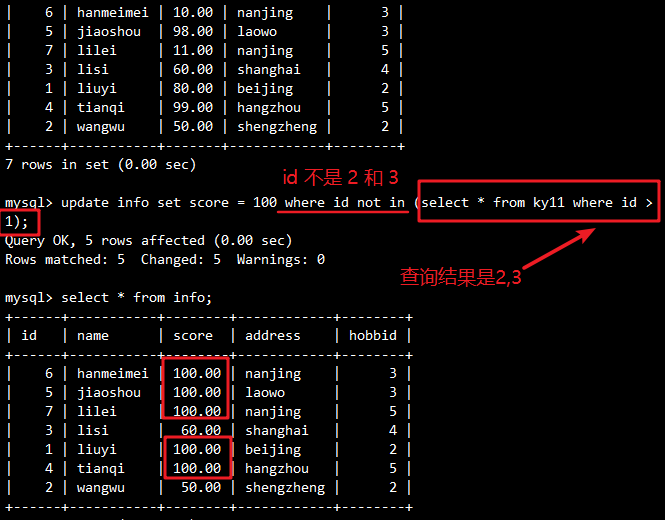
示例:将 info表中所有 id不在 ky11表的 id>1记录中的行,其 score字段更新为100
UPDATE info
SET score = 100
WHERE id NOT IN (SELECT * FROM ky11 WHERE id > 1);
2.5.2.3 IN在 DELETE 语句中的应用
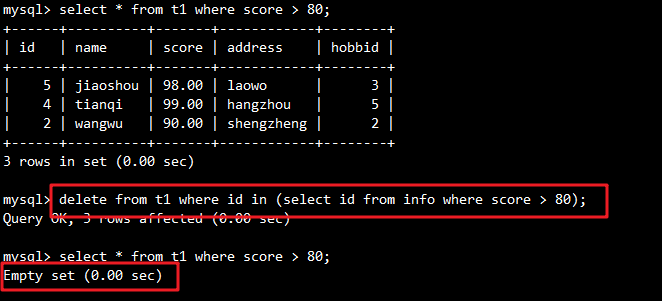
示例:删除分数大于80的记录
DELETE FROM t1
WHERE id IN (SELECT id FROM info WHERE score > 80);
在IN 前面还可以添加 NOT,其作用与 IN 相反,表示否定(即不在子查询的结果集里面)
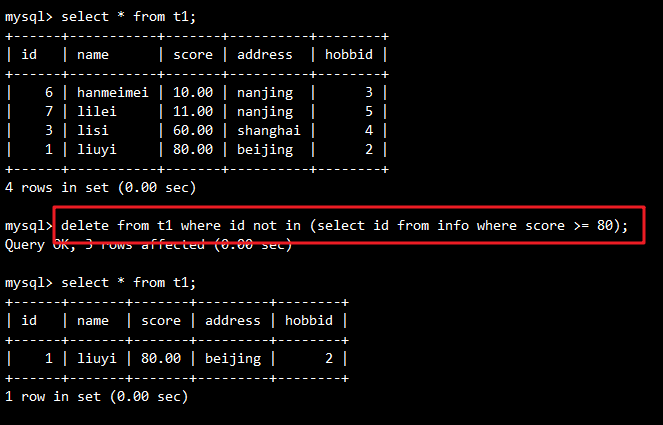
示例:删除分数小于80的记录(使用 NOT IN)
DELETE FROM t1
WHERE id NOT IN (SELECT id FROM info WHERE score >= 80);
2.5.3 EXISTS 关键字
EXISTS 用于判断子查询结果是否为空:
- 结果非空 → 返回
TRUE - 结果为空 → 返回
FALSE
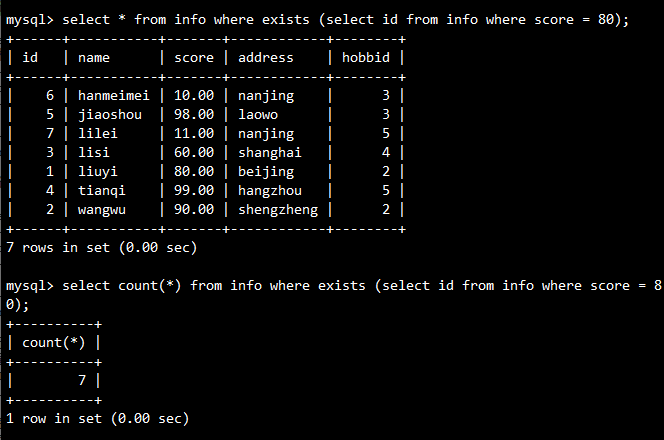
示例:查询如果存在分数等于80的记录则计算info的字段数
SELECT COUNT(*)
FROM info
WHERE EXISTS (SELECT id FROM info WHERE score = 80);
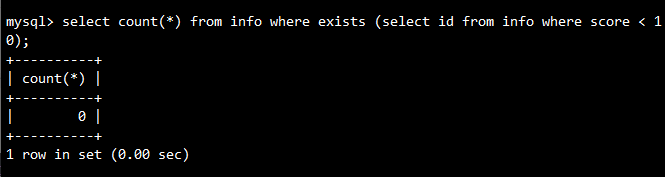
示例:检查是否存在分数小于10的记录,info表没有小于10的,所以返回0
SELECT COUNT(*)
FROM info
WHERE EXISTS (SELECT id FROM info WHERE score < 10);
2.5.4 别名as关键字
当子查询的结果集作为临时表使用时,必须为其指定别名。
错误示例:
SELECT id FROM (SELECT id, name FROM info);
-- 报错:Every derived table must have its own alias
SELECT * FROM 表名 是标准查询格式。但上述查询中,“表名"位置实际上是一个完整结果集,MySQL无法直接识别。此时,通过为结果集设置别名(如 SELECT a.id FROM a),将这个结果集视为一张"表”,就能正常查询数据了。示例如下:

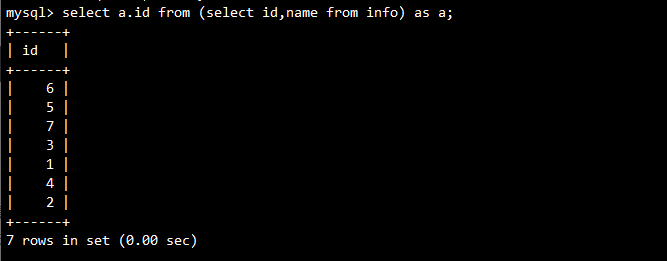
正确示例(使用别名):
SELECT a.id
FROM (SELECT id, name FROM info) as a;
等价于:
SELECT info.id, name FROM info;
三、视图的应用
3.1 视图概述
视图是虚拟表,不存储真实数据,仅保存查询定义,提供了一种数据抽象和安全控制机制。
3.1.1 视图特点
- 简化复杂查询
- 提供数据安全性(隐藏敏感数据)
- 逻辑数据独立性
- 适用于多表连接查询场景
3.1.2 视图与表的区别
| 对比维度 | 表 (Table) | 视图 (View) |
|---|---|---|
| 本质 | 存储实际数据的数据库对象 | 虚拟表,是编译好的SQL查询语句的逻辑表示 |
| 数据存储 | 占用物理存储空间,有实际的物理记录(数据文件) | 不占用物理存储空间,没有实际的物理记录 |
| 数据构成 | 实表,包含完整的、独立存储的数据 | 虚表,其数据来源于一个或多个基表(或其他视图)的查询结果 |
| 作用与安全性 | 存储数据的核心对象,直接操作和修改 | 1. 简化复杂查询 2. 增强安全性(隐藏表结构、限制访问特定行/列) 3. 提供一种逻辑上的数据抽象 |
| 修改影响 | 对表的结构(如增删列)或数据的修改会直接影响存储的数据 | 视图的建立和删除只影响视图本身,不影响基表。 但通过视图更新数据(增删改),会影响其对应的基表中的数据。 |
| 所属模式 | 属于全局模式 | 属于局部模式 |
核心总结与建议:
- 表是数据的存储容器,是基础。
- 视图是数据的展示窗口,是基于表的逻辑抽象。它常用于简化权限管理(让用户通过视图访问数据而非直接操作表)和封装复杂的查询逻辑。
3.2 视图操作
以下是为你的博客整理的 3.2 视图操作 章节内容,结合示例代码和说明,以技术教程的形式呈现:
3.2.1 创建视图(单表)
需求:筛选 info 表中成绩 ≥80 的学生,并动态更新。
-- 创建视图
CREATE VIEW v_score AS
SELECT * FROM info WHERE score >= 80;
-- 查看视图数据
SELECT * FROM v_score;
输出:
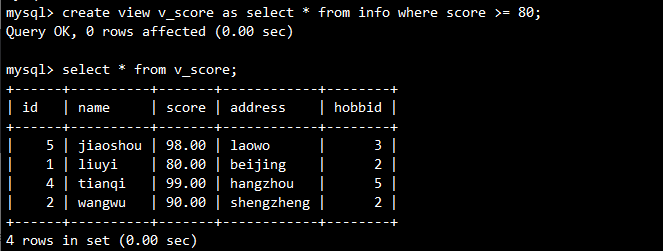
视图结构对比
视图继承源表结构,但不包含约束(如主键):
-- 查看视图结构
DESC v_score;
-- 查看源表结构
DESC info;
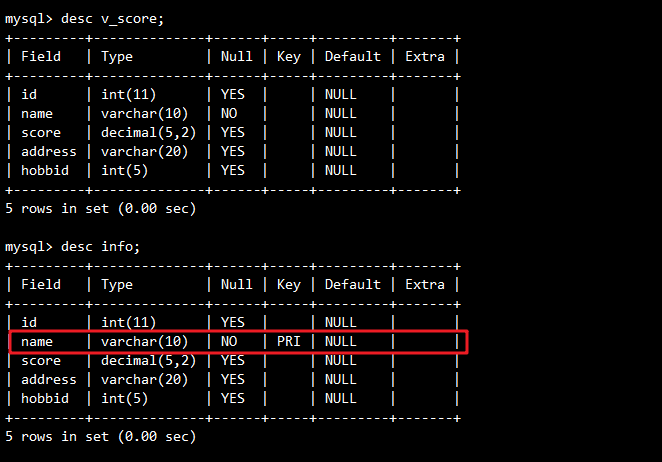
对比结果:
v_score的name字段无PRI(主键)约束,其他字段与info一致。
3.2.2 多表视图创建
需求:联合 info 和 test01 表,输出学生 ID、姓名、分数及年龄。
-- 创建测试表
CREATE TABLE test01 (id INT, name VARCHAR(10), age CHAR(10));
insert into test01 values(1,'zhangsan',20);
insert into test01 values(2,'lisi',30);
insert into test01 values(3,'wangwu',29);

-- 创建多表视图
CREATE VIEW v_info(id, name, score, age) AS
SELECT info.id, info.name, info.score, test01.age
FROM info, test01
WHERE info.name = test01.name;
-- 查看视图
SELECT * FROM v_info;
输出:
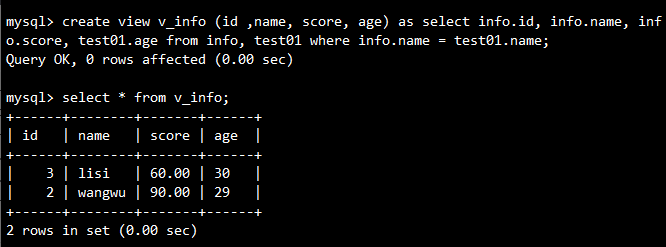
3.2.3 视图的动态性与可更新性
动态性:修改源表数据后,视图自动更新。
-- 修改源表数据(将 liuyi 的分数改为 60)
UPDATE info SET score = '60' WHERE name = 'liuyi';
-- 视图自动过滤不符合条件(score>=80)的数据
SELECT * FROM v_score;
输出(liuyi 从视图中消失):
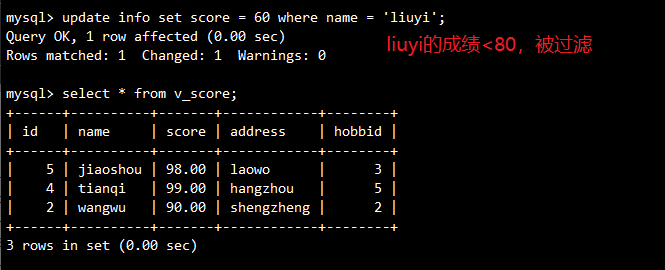
可更新性:通过视图直接修改源表数据。
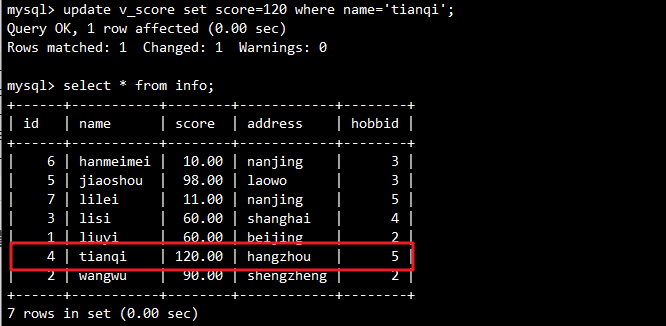
-- 通过视图修改 tianqi 的分数
UPDATE v_score SET score = '120' WHERE name = 'tianqi';
-- 验证源表数据更新
SELECT * FROM info WHERE name = 'tianqi';
输出:
3.2.4 视图的核心价值
-
查询简化
- 封装复杂查询(如多表 JOIN),减少重复 SQL 编写。
- 结合索引提升查询效率(视图本身无索引,但可复用基表索引)。
-
数据安全
- 为不同用户创建视图,限制其访问的数据范围(如隐藏敏感字段)。
-- 示例:为普通用户创建仅公开姓名和分数的视图 CREATE VIEW v_public AS SELECT name, score FROM info;- 通过权限控制,避免直接暴露基表结构(如主键、约束)。
-
动态结果集
- 视图数据随基表实时更新,确保结果始终符合最新业务状态。
3.2.5 注意事项
- 不可更新场景:
若视图包含聚合函数(如SUM())、GROUP BY、DISTINCT等,则不可直接更新。 - 权限分离:
用户需拥有CREATE VIEW权限才能创建视图,且仅能访问视图授权字段。
总结:视图是数据库层的“虚拟筛选器”,兼顾动态数据整合与安全管控。通过合理设计视图,可显著提升查询效率,并为不同角色提供定制化数据视角,是权限管理和复杂查询优化的利器。
四、NULL值处理
4.1 NULL值的概念
在SQL语句使用过程中,NULL用于表示表中字段的数据缺失或未定义。当创建表时,如果未使用NOT NULL关键字限制字段,该字段默认允许为空。在插入或更新记录时,若未给此类字段赋值,它们将被自动保存为NULL。
需要注意的是,NULL值与数字0或空字符串(‘’)完全不同:NULL表示该字段完全没有值,而0和空字符串都是具体的值。在SQL中,需要使用IS NULL或IS NOT NULL来判断字段是否为NULL。
4.2 NULL值与空值的区别
| 特性 | NULL值 | 空值(‘’) |
|---|---|---|
| 长度 | NULL | 0 |
| 占用空间 | 是 | 否 |
| 判断方式 | IS NULL/IS NOT NULL | = ‘’ 或 <> ‘’ |
| COUNT统计 | 忽略 | 计入 |
比喻理解:空值如同空气(存在但无内容),NULL值如同真空(完全不存在)
4.3 实际案例演示
4.3.1 表结构分析
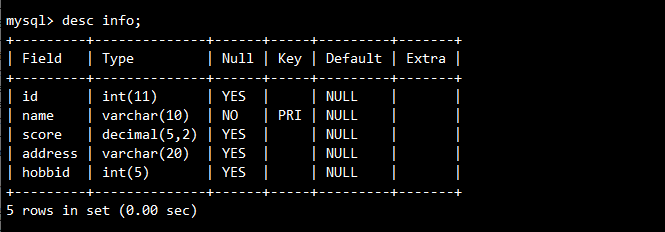
4.3.2 操作示例
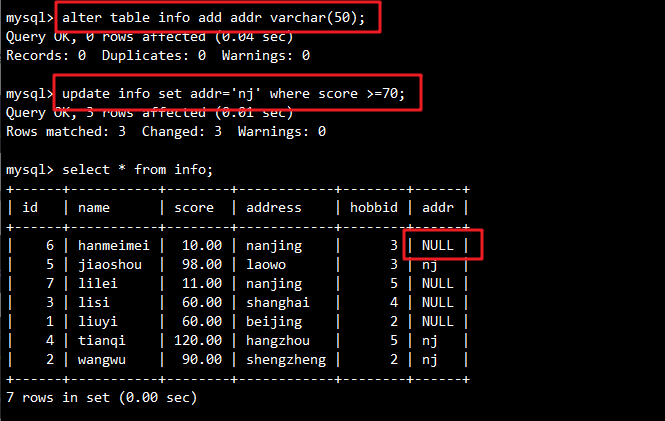
- 添加新字段并更新数据:
ALTER TABLE info ADD COLUMN addr VARCHAR(50);
UPDATE info SET addr='nj' WHERE score >=70;
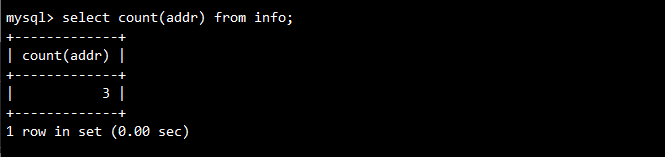
- 统计测试(验证NULL与空值的统计差异):
-- 统计addr字段值数量(NULL值不被统计)
SELECT COUNT(addr) FROM info;
-- 将一条记录的addr字段设置为空值
UPDATE info SET addr='' WHERE name='hanmeimei';
-- 再次统计(空值会被统计)
SELECT COUNT(addr) FROM info;
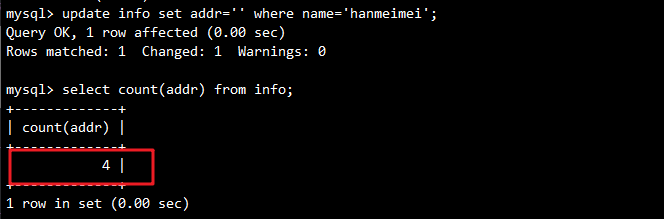
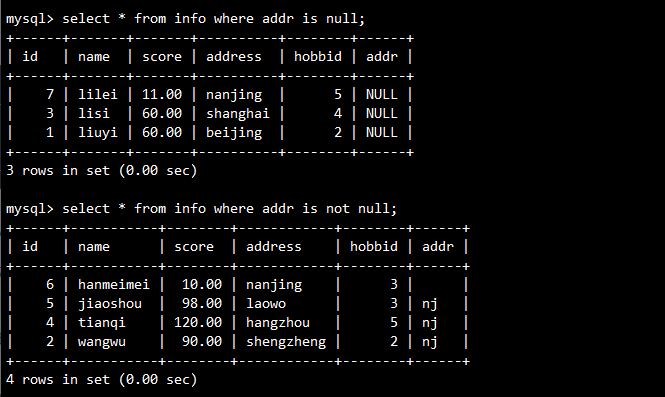
- 查询示例:
-- 查询NULL值
SELECT * FROM info WHERE addr IS NULL;
-- 查询非NULL值
SELECT * FROM info WHERE addr IS NOT NULL;
4.4 NULL值处理总结
- NULL值表示字段数据缺失,与0或空字符串有本质区别
- 使用
IS NULL和IS NOT NULL进行NULL值判断 - COUNT()函数统计时会自动忽略NULL值,但会计入空值
- 在实际数据处理中,需要根据业务需求合理处理NULL值,避免造成统计偏差或逻辑错误
正确处理NULL值是保证SQL查询准确性的重要环节,需要在数据库设计和查询编写时给予充分重视。
总结
MySQL的高阶查询语句为数据处理提供了强大而灵活的工具。通过掌握排序、分组、限制结果、别名设置、通配符使用、子查询和视图等技术,可以大幅提高数据库查询的效率和复杂性处理能力。
同时,正确理解NULL值的特性和处理方法,有助于保证数据查询的准确性和完整性。这些高级特性使得MySQL能够满足各种复杂业务场景的数据处理需求,是每位数据库开发和管理人员必须掌握的核心技能。

















 1124
1124

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









