







光流特征:
光流(optical flow)是空间运动物体在观察成像平面上的像素运动的瞬时速度。光流法是利用图像序列中像素在时间域上的变化以及相邻帧之间的相关性来找到上一帧跟当前帧之间存在的对应关系,从而计算出相邻帧之间物体的运动信息的一种方法。通常将二维图像平面特定坐标点上的灰度瞬时变化率定义为光流矢量。一言以概之:所谓光流就是瞬时速率,在时间间隔很小(比如视频的连续前后两帧之间)时,也等同于目标点的位移。
光流法用于目标跟踪的原理:
(1)对一个连续的视频帧序列进行处理;
(2)针对每一个视频序列,利用一定的目标检测方法,检测可能出现的前景目标;
(3)如果某一帧出现了前景目标,找到其具有代表性的关键特征点(可以随机产生,也可以利用角点来做特征点);
(4)对之后的任意两个相邻视频帧而言,寻找上一帧中出现的关键特征点在当前帧中的最佳位置,从而得到前景目标在当前帧中的位置坐标;
(5)如此迭代进行,便可实现目标的跟踪;
1.基本假设条件
(1)亮度恒定不变。即同一目标在不同帧间运动时,其亮度不会发生改变。这是基本光流法的假定(所有光流法变种都必须满足),用于得到光流法基本方程;
(2)时间连续或运动是“小运动”。即时间的变化不会引起目标位置的剧烈变化,相邻帧之间位移要比较小。同样也是光流法不可或缺的假定。
2.基本约束方程
考虑一个像素I(x,y,t)在第一帧的光强度(其中t代表其所在的时间维度)。它移动了 (dx,dy)的距离到下一帧,用了dt时间。因为是同一个像素点,依据上文提到的第一个假设我们认为该像素在运动前后的光强度是不变的,即:
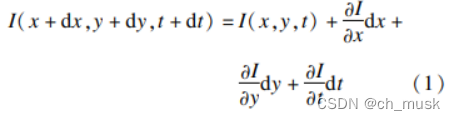
步骤:
a.首先,对每一帧建立一个高斯金字塔,最低分辨率图像在最顶层,原始图片在底层。
b.计算光流。从顶层(Lm层)开始,通过最小化每个点的邻域范围内的匹配误差和,得到顶层图像中每个点的光流。
c.顶层的光流计算结果(位移情况)反馈到第Lm-1层,作为该层初始时的光流值的估计g。
d.这样沿着金字塔向下反馈,重复估计动作,直到到达金字塔的底层(即原图像)。(准确值=估计值+残差) “残差”即本算法的关键对于每一层L,每个点的光流的计算都是基于邻域内所有点的匹配误差和最小化。
Hog特征
方向梯度直方图(Histogram of Oriented Gradient, HOG)特征是一种在计算机视觉和图像处理中用来进行物体检测的特征描述子。它通过计算和统计图像局部区域的梯度方向直方图来构成特征。Hog特征结合SVM分类器已经被广泛应用于图像识别中,尤其在行人检测中获得了极大的成功。
1)主要思想:
在一副图像中,局部目标的表象和形状(appearance and shape)能够被梯度或边缘的方向密度分布很好地描述。(本质:梯度的统计信息,而梯度主要存在于边缘的地方)。
2)具体的实现方法是:
首先将图像分成小的连通区域,我们把它叫细胞单元。然后采集细胞单元中各像素点的梯度的或边缘的方向直方图。最后把这些直方图组合起来就可以构成特征描述器。之所以统计每一个小单元的方向走直方图,是因为,一般来说,只有图像区域比较小的情况,基于统计原理的直方图对于该区域才有表达能力,如果图像区域比较大,那么两个完全不同的图像的HOG特征,也可能很相似。但是如果区域较小,这种可能性就很小。
3)优点:
与其他的特征描述方法相比,HOG有很多优点。首先,由于HOG是在图像的局部方格单元上操作,所以它对图像几何的和光学的形变都能保持很好的不变性,这两种形变只会出现在更大的空间领域上。其次,在粗的空域抽样、精细的方向抽样以及较强的局部光学归一化等条件下,只要行人大体上能够保持直立的姿势,可以容许行人有一些细微的肢体动作,这些细微的动作可以被忽略而不影响检测效果。因此HOG特征是特别适合于做图像中的人体检测的。
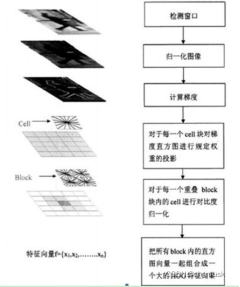
过程:
HOG特征提取方法就是将一个image(你要检测的目标或者扫描窗口):
1)灰度化(将图像看做一个x,y,z(灰度)的三维图像);
2)采用Gamma校正法对输入图像进行颜色空间的标准化(归一化);目的是调节图像的对比度,降低图像局部的阴影和光照变化所造成的影响,同时可以抑制噪音的干扰;
3)计算图像每个像素的梯度(包括大小和方向);主要是为了捕获轮廓信息,同时进一步弱化光照的干扰。
4)将图像划分成小cells(例如6*6像素/cell);
5)统计每个cell的梯度直方图(不同梯度的个数),即可形成每个cell的descriptor;
6)将每几个cell组成一个block(例如3*3个cell/block),一个block内所有cell的特征descriptor串联起来便得到该block的HOG特征descriptor。
7)将图像image内的所有block的HOG特征descriptor串联起来就可以得到该image(你要检测的目标)的HOG特征descriptor了。这个就是最终的可供分类使用的特征向量了。
LBP特征:
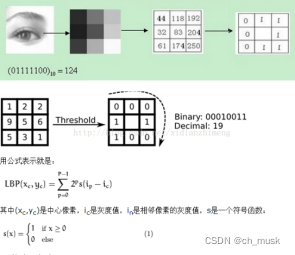
LBP(Local Binary Pattern,局部二值模式)是一种用来描述图像局部纹理特征的算子;它具有旋转不变性和灰度不变性等显著的优点。它是首先由T. Ojala, M.Pietikäinen, 和D. Harwood 在1994年提出,用于纹理特征提取。而且,提取的特征是图像的局部的纹理特征;原始的LBP算子定义为在3*3的窗口内,以窗口中心像素为阈值,将相邻的8个像素的灰度值与其进行比较,若周围像素值大于中心像素值,则该像素点的位置被标记为1,否则为0。这样,3*3邻域内的8个点经比较可产生8位二进制数(通常转换为十进制数即LBP码,共256种),即得到该窗口中心像素点的LBP值,并用这个值来反映该区域的纹理信息。
一个LBP算子可以产生不同的二进制模式,对于半径为R的圆形区域内含有P个采样点的LBP算子将会产生P2 种模式。很显然,随着邻域集内采样点数的增加,二进制模式的种类是急剧增加的。例如:5×5邻域内20个采样点,有220=1,048,576种二进制模式。如此多的二值模式无论对于纹理的提取还是对于纹理的识别、分类及信息的存取都是不利的。同时,过多的模式种类对于纹理的表达是不利的。例如,将LBP算子用于纹理分类或人脸识别时,常采用LBP模式的统计直方图来表达图像的信息,而较多的模式种类将使得数据量过大,且直方图过于稀疏。因此,需要对原始的LBP模式进行降维,使得数据量减少的情况下能最好的代表图像的信息。
步骤
(1)首先将检测窗口划分为16×16的小区域(cell);
(2)对于每个cell中的一个像素,将相邻的8个像素的灰度值与其进行比较,若周围像素值大于中心像素值,则该像素点的位置被标记为1,否则为0。这样,3*3邻域内的8个点经比较可产生8位二进制数,即得到该窗口中心像素点的LBP值;
(3)然后计算每个cell的直方图,即每个数字(假定是十进制数LBP值)出现的频率;然后对该直方图进行归一化处理。
(4)最后将得到的每个cell的统计直方图进行连接成为一个特征向量,也就是整幅图的LBP纹理特征向量;
SIFT特征
1、算法简介
尺度不变特征转换即SIFT (Scale-invariant feature transform)是一种计算机视觉的算法。它用来侦测与描述影像中的局部性特征,它在空间尺度中寻找极值点,并提取出其位置、尺度、旋转不变量,此算法由 David Lowe在1999年所发表,2004年完善总结。
其应用范围包含物体辨识、机器人地图感知与导航、影像缝合、3D模型建立、手势辨识、影像追踪和动作比对。局部影像特征的描述与侦测可以帮助辨识物体,SIFT特征是基于物体上的一些局部外观的兴趣点而与影像的大小和旋转无关。对于光线、噪声、些微视角改变的容忍度也相当高。基于这些特性,它们是高度显著而且相对容易撷取,在母数庞大的特征数据库中,很容易辨识物体而且鲜有误认。使用 SIFT特征描述对于部分物体遮蔽的侦测率也相当高,甚至只需要3个以上的SIFT物体特征就足以计算出位置与方位。在现今的电脑硬件速度下和小型的特征数据库条件下,辨识速度可接近即时运算。SIFT特征的信息量大,适合在海量数据库中快速准确匹配。SIFT算法的实质是在不同的尺度空间上查找关键点(特征点),并计算出关键点的方向。SIFT所查找到的关键点是一些十分突出,不会因光照,仿射变换和噪音等因素而变化的点,如角点、边缘点、暗区的亮点及亮区的暗点等。
过程如下:
1)以兴趣点为中心,从视频序列中抽取时空立方体并将其划分为大小相同且固定的cell立方体;
2)统计每个cell立方体的时空梯度直方图;
3)联合所有 cell立方体,构成该兴趣点的3Dsift特征.
将四种特征等权拼接并作降维处理放入svm中做分类。
Svm(支持向量机)
SVM是由模式识别中广义肖像算法(generalized portrait algorithm)发展而来的分类器,其早期工作来自前苏联学者Vladimir N. Vapnik和Alexander Y. Lerner在1963年发表的研究。1964年,Vapnik和Alexey Y. Chervonenkis对广义肖像算法进行了进一步讨论并建立了硬边距的线性SVM。此后在二十世纪70-80年代,随着模式识别中最大边距决策边界的理论研究、基于松弛变量(slack variable)的规划问题求解技术的出现,和VC维(Vapnik-Chervonenkis dimension, VC dimension)的提出,SVM被逐步理论化并成为统计学习理论的一部分。1992年,Bernhard E. Boser、Isabelle M. Guyon和Vapnik通过核方法得到了非线性SVM。1995年,Corinna Cortes和Vapnik提出了软边距的非线性SVM并将其应用于手写字符识别问题,这份研究在发表后得到了关注和引用,为SVM在各领域的应用提供了参考。
算法步骤
a.假设现在存在这么一个超平面wx+b=0可以完全把训练数据集分开。
思考这个超平面需要满足什么样的条件时才能够将数据完全分开。
b.如果距离超平面最近的点都能够被正确分类,那么其他距离较远的点肯定都能够被正确分类。
c.所以我们现在需要做的是找到距离超平面最近的样本点(前面几何间隔与函数间隔区别中有说)。
d.找到最小值以后还不够,因为我们前面提到过,样本点到超平面的距离越大,分类的准确性越高,所以我们要尽可能的让求取的极小值尽可能的大。依据这个条件取求取满足调价的最佳分割超平面。
全局实现步骤:
- 提取视频光流特征,Hog特征,LBP特征以及SIFT特征
- 有效将四种特征等权拼接,作为视频的特征
- 对特征进行降维处理,提升模型的效率
- 使用svm对特征进行训练并预测最终结果。
PCA(主成分分析):一种无监督降维方法,将一个矩阵中的样本数据,投影到一个新的空间中,将原来多个变量的复杂因素归结成为几个主要成分,使问题简单化,得到的结果更加科学高效。
对一堆数据利用PCA进行降维,通俗的说就是类似于线性代数中给定一组线性相关的向量,所谓线性相关就是一个向量可以用其余向量进行线性表示,也就是说这个向量在这组向量中是多余的,PCA的功能就是去掉这部分多余的向量,然后把线性相关的向量组变成线性无关,这样实际上就大大降低了数据量,也保留了关键的数据















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











