




PDF导出服务
在前端开发中,经常遇到pdf导出的需求,处理这类需求能实现的方式也很多,包括前端导出,服务端导出。
由于有的内容过多,导出时间过长,不适宜前端导出,所以一般还是选择服务端导出,然后通知客户端导出结果。
一、前端导出
前端导出的话,适用于导出内容少,导出内容简单。这里就简单介绍下,主角不是他:
- jsPDF
jsPDF 结合 html2canvas 来将 HTML 页面或其部分转换为画布,然后将该画布作为图像添加到 PDF 中
import { jsPDF } from "jspdf";
import html2canvas from 'html2canvas';
function exportPDF() {
const element = document.getElementById('content-to-print'); // 要导出的HTML元素
html2canvas(element).then(canvas => {
const imgData = canvas.toDataURL('image/png');
const pdf = new jsPDF();
const imgProps = pdf.getImageProperties(imgData);
const pdfWidth = pdf.internal.pageSize.getWidth();
const pdfHeight = (imgProps.height * pdfWidth) / imgProps.width;
pdf.addImage(imgData, 'PNG', 0, 0, pdfWidth, pdfHeight);
pdf.save("download.pdf");
});
}
- PDFMake
PDFMake 用来创建复杂的 PDF 文档,包括表格、列表、字体样式等。基本是定制PDF每一项内容,适用于需要精细化配置到每一项的场景,使用不便利
import pdfMake from 'pdfmake/build/pdfmake';
import pdfFonts from 'pdfmake/build/vfs_fonts';
pdfMake.vfs = pdfFonts.pdfMake.vfs;
function createPdf() {
const docDefinition = {
content: [
'First paragraph',
'Another paragraph, this time a little bit longer to make sure, this line will be divided into at least two lines'
]
};
pdfMake.createPdf(docDefinition).download('document.pdf');
}
二、Puppeteer + Node
Puppeteer 是一个 Node.js 库,它提供了一个高级 API 来控制无头 Chrome 或 Chromium 浏览器。你可以用它来加载网页并直接导出为 PDF。
本文案例就是使用这种方式实现一个通用的PDF导出方案,下面介绍一些优点,解决了传统服务端导出PDF的哪些痛点:
- 优点:
1. 需要导出的内容只需提供一个可访问的链接,这样能由前端维护导出模板,可利用前端项目中封装的公用组件,主题等
2. 服务可独立部署,与API接口服务分离开,不会影响其运行
3. 可直接预览导出效果,和导出效果一致
......
- 解决了传统服务端导出PDF的缺陷:
前端写html模板给后端,后端套数据,CSS3的很多特性无法使用,Echarts还得用node版本的,会让pdf导出的内容主题风格与客户端不一致,组件风格也不一致,开发周期还长
1. 对接困难,后端拿到html后无法快速接入数据
2. 需求无法完全实现,本身后端去写样式这些就难为他们
3. 一个服务下,运行时可能吃内存占用,CPU计算之类,影响API服务质量
......
- 路由
我设计PDF导出服务包含2个路由,一个预览,一个生成:
/**
* @description: pdf生成
* @author: mySkey
*/
router.get("/pdf/create", async (ctx) => {
const query = ctx.request.query || {};
const pdf_url = query?.pdf_url;
const pdfRes = await getPdf(pdf_url);
ctx.body = pdfRes;
});
/**
* @description: pdf预览
* @author: mySkey
*/
router.get("/pdf/preview", async (ctx) => {
const query = ctx.request.query || {};
const pdf_url = query?.pdf_url;
const pdfRes = await getPdf(pdf_url);
if (pdfRes["code"] === 200) {
ctx.set("content-type", "application/pdf");
ctx.body = pdfRes?.file;
}
if (pdfRes["code"] === 500) {
ctx.body = pdfRes;
}
});
- 利用 Puppeteer 生成PDF的逻辑
内置一些类名,当html中的dom带上(如:pdf-header)类名时,算内置的页眉、页脚、成功、失败之类的捕获,用于回调给API服务
const puppeteer = require("puppeteer");
const lodash = require("lodash");
/** 类名前缀 */
const prefix = "pdf-";
const pdfTemplateClassEnum = {
/** 页眉 */
header: `${prefix}header`,
/** 页脚 */
footer: `${prefix}footer`,
/** 页面加载接口成功 */
success: `${prefix}success`,
/** 页面加载接口失败 */
error: `${prefix}error`,
/** 页面加载接口失败信息 */
errorText: `${prefix}error-text`,
};
/**
* @description: 页眉页脚
* @author: mySkey
* @param {*} page
* @param {*} className
*/
async function getTemplate(page, className) {
let element = {
outerHTML: undefined,
offsetHeight: 0,
innerText: "",
};
try {
element = await page.$eval(`.${className}`, (element) => {
const outerHTML = element?.outerHTML;
const offsetHeight = element?.offsetHeight;
const innerText = element?.innerText;
element.style.display = "none";
return {
outerHTML,
offsetHeight,
innerText,
};
});
} catch (e) {}
return element;
}
/**
* @description: 获取pdf状态
* @author: mySkey
* @param {*} page
*/
async function getPdfStatusRes(page) {
const response = {
code: 200,
message: "success",
};
const pdfError = await getTemplate(page, pdfTemplateClassEnum.error);
if (!lodash.isEmpty(pdfError?.outerHTML)) {
const pdfErrorText = await getTemplate(
page,
pdfTemplateClassEnum.errorText
);
const { innerText = "" } = pdfErrorText;
response["code"] = 500;
response["message"] = innerText;
}
return response;
}
/**
* @description: 生成pdf文件二进制流
* @author: mySkey
* @param {*} pdf_url
*/
async function getPdf(pdf_url) {
let response = {};
const browser = await puppeteer.launch({
timeout: 0,
args: ["--no-sandbox", "--disable-setuid-sandbox"],
});
const page = await browser.newPage();
await page.goto(pdf_url, {
waitUntil: [
"load", //等待 “load” 事件触发
"domcontentloaded", //等待 “domcontentloaded” 事件触发
"networkidle0", //在 500ms 内没有任何网络连接
"networkidle2", //在 500ms 内网络连接个数不超过 2 个
],
timeout: 0,
});
const pdfStatusRes = await getPdfStatusRes(page);
if (pdfStatusRes["code"] === 500) {
response = pdfStatusRes;
}
if (pdfStatusRes["code"] === 200) {
const file = await getPdfFile(page);
response = {
...pdfStatusRes,
file,
};
}
await browser.close();
return response;
}
/**
* @description: 获取pdf文件
* @author: mySkey
* @param {*} pdf_url
*/
async function getPdfFile(page) {
const { outerHTML: headerTemplate, offsetHeight: headerHeight } = await getTemplate(page, pdfTemplateClassEnum.header);
const { outerHTML: footerTemplate, offsetHeight: footerHeight } = await getTemplate(page, pdfTemplateClassEnum.footer);
const pdf = await page.pdf({
timeout: 0,
format: "A4",
scale: 0.9,
printBackground: true,
margin: {
top: `${20 + headerHeight}px`,
bottom: `${30 + footerHeight}px`,
},
displayHeaderFooter: true,
headerTemplate,
footerTemplate,
});
return pdf;
}
module.exports = { getPdf: getPdf };
三、docker服务部署
- 部署到docker
https://github.com/puppeteer/puppeteer/blob/main/docs/guides/docker.md
现在puppeteer的镜像已经包含了Chrome,所以我们只需要这个镜像,再把Node服务融合在一起就ok了
以下文件可参考,具体按实际情况:
# 构建阶段
FROM node:20-slim AS builder
WORKDIR /app
COPY package*.json ./
RUN npm ci
COPY . .
RUN npm run build
# 生产阶段
FROM ghcr.io/puppeteer/puppeteer:latest AS production
WORKDIR /app
ENV NODE_ENV production
- 字体文件
由于字体是有版权的,还是放置字体文件在镜像中,导出时都使用自己的字体
四、书写导出pdf模板
要想PDF导出的文件优雅,还是要注意一些东西。
模板中第一个类名为 pdf-header (页眉)、pdf-footer(页脚),在页眉、页脚中,你可以使用一些变量,使用类名即可如下面使用日期 ,页眉页脚上请使用内联样式
- 1、页眉
请使用内联样式,即style上写,插入图片请使用base64地址
<div class="pdf-header" style="width: 100vw; padding: 0 10px; display: flex; justify-content: space-between; font-size: 16px;">
<div>
<img style="width: 20px; height: 20px;" src="data:image/png;base64," >
</div>
<div><span class="date"></span></div>
</div>
页眉参数
date 格式化的日期
title 网页标题
url 网页地址
pageNumber 当前页码
totalPages 总页数
- 2、页脚
请使用内联样式,即style上写
<div class="pdf-footer" style="width: 100vw; padding: 0 10px; display: flex; justify-content: space-between; font-size: 16px;">
<div></div>
<div><span class="pageNumber"></span>/<span class="totalPages"></span></div>
</div>
- 3、插入分页符
.page-break-after {
page-break-after: always;
}
// 需要插入分页符的地方
<div class="page-break-after"></div>
- 4、某版块不分页隔断
.page-break-inside {
page-break-inside: avoid;
}
- 5、超链接
超链接请使用a标签,onCLick跳转的无法在pdf上跳转
<a href="">超链接</a>
五、导出流程
客户端发起导出请求 -> API服务接收后生成导出记录,导出记录包含请求参数,向PDF导出服务发起导出请求 -> PDF导出服务接收到导出请求后,开始导出,根据结果回调给API服务。
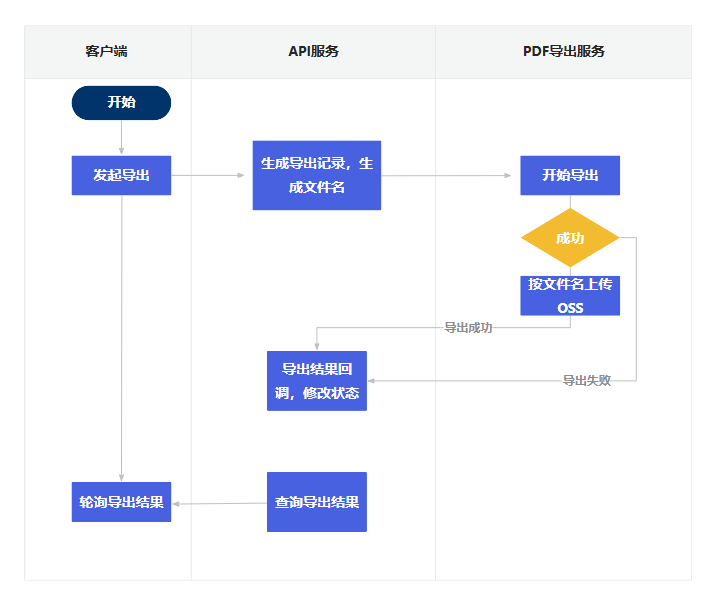
- 为什么用轮询?
导出任务还是很轻量级的,选择轮询其实对服务器是压力最小的方式,尤其是服务端有索引优化,有redis缓存的话,轮询是优于长连接的。
- 注意轮询开启与关闭
开启轮询的时机:
开始导出 -> 开启轮询
为应对刷新浏览器,初始化时获取通知消息列表,通知消息中存在导出中的数据 -> 开启轮询
关闭轮询的时机:
通知消息队列中全部导出状态:成功或失败 -> 关闭轮询
甚至通知消息有已读、未读状态,那么就根据自己的业务调整逻辑

















 2526
2526

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









