 数据结构精讲
数据结构精讲





 本文深入讲解数据结构,包括数组、链表、栈、队列、树等基本概念和操作,探讨了二叉搜索树和红黑树的特性和实现方法。
本文深入讲解数据结构,包括数组、链表、栈、队列、树等基本概念和操作,探讨了二叉搜索树和红黑树的特性和实现方法。
什么是数据结构?
一组数据的存储结构。
常见数据结构:
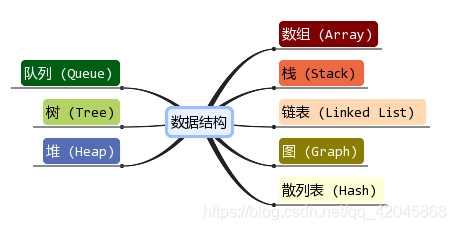
每一种数据结构都有其对应的应用场景, 不同的数据结构的不同操作性能是不同的。
什么是算法?(Algorithm)
操作数据的一组方法。
数据结构——数组
1.数组是一种线性结构, 并且可以在数组的任意位置插入和删除数据.
2.有时候为了实现某些功能, 必须对这种任意性加以限制,而栈和队列就是比较常见的受限的线性结构。
数据结构——栈
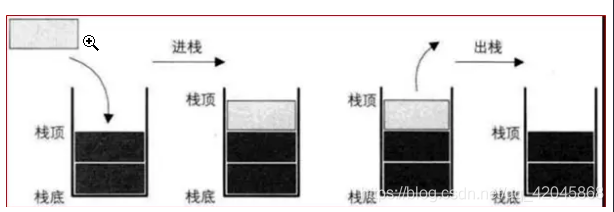
1.一种运算受限的线性表,后进先出(LIFO)
2.LIFO(last in first out)表示就是后进入的元素, 第一个弹出栈空间.。
3.其限制是仅允许在表的一端进行插入和删除运算。这一端被称为栈顶,相对地,把另一端称为栈底。
4.向一个栈插入新元素又称作进栈、入栈或压栈,它是把新元素放到栈顶元素的上面,使之成为新的栈顶元素;
5.从一个栈删除元素又称作出栈或退栈,它是把栈顶元素删除掉,使其相邻的元素成为新的栈顶元素。
举例:
1.自助餐的托盘, 最新放上去的, 最先被客人拿走使用.
2.收到很多的邮件(实体的), 从上往下依次处理这些邮件. (最新到的邮件, 最先处理)
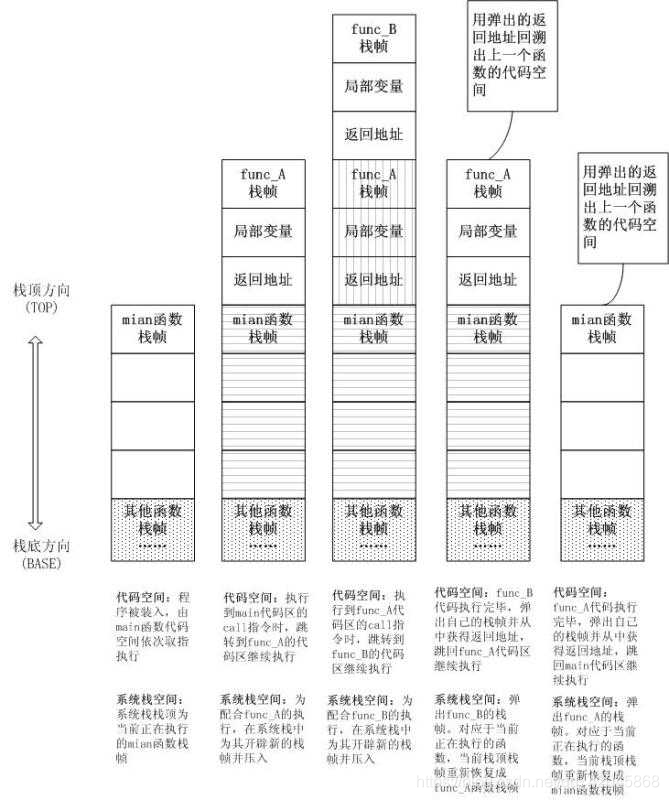
程序中什么是使用栈实现的呢?
1.函数调用栈呢?
2.函数之间和相互调用: A调用B, B中又调用C, C中又调用D.
3.在执行的过程中, 会先将A压入栈, A没有执行完, 所有不会弹出栈.
4.在A执行的过程中调用了B, 会将B压入到栈, 这个时候B在栈顶, A在栈底.
5.如果这个时候B可以执行完, 那么B会弹出栈. 但是B有执行完吗? 没有, 它调用了C.
6.所以C会压栈, 并且在栈顶. 而C调用了D, D会压入到栈顶.
7.所以当前的栈顺序是: 栈顶A->B->C->D栈顶
8.D执行完, 弹出栈. C/B/A依次弹出栈.
9.所以有函数调用栈的称呼, 就来自于它们内部的实现机制. (通过栈来实现的)

答案为C。先进后出。
A答案: 65进栈, 5出栈, 4进栈出栈, 3进栈出栈, 6出栈, 21进栈,1出栈, 2出栈
B答案: 654进栈, 4出栈, 5出栈, 3进栈出栈, 2进栈出栈, 1进栈出栈, 6出栈
D答案: 65432进栈, 2出栈, 3出栈, 4出栈, 1进栈出栈, 5出栈, 6出栈
栈结构实现
// 栈类
function Stack() {
// 栈中的属性
var items = []
// 栈相关的方法
}
栈的操作
栈通常包括的三种操作:push、peek、pop。
push – 向栈中添加元素。
peek – 返回栈顶元素。(取出)
pop – 返回并删除栈顶元素的操作。(删除)
C++的STL中本身就包含了stack类,基本上该stack类就能满足我们的需求,所以很少需要我们自己来实现。本部分介绍2种C++实现。
1.C++实现一:数组实现的栈,能存储任意类型的数据。
//数组实现的栈,能存储任意类型的数据
#ifndef ARRAY_STACK_HXX
#define ARRAY_STACK_HXX
#include <iostream>
#include "ArrayStack.h"
using namespace std;
//模板类
template<class T>
class ArrayStack{
public:
ArrayStack(); //构造函数
~ArrayStack(); //析构函数
void push(T t);//向栈中添加一个t元素
T peek();//向栈中取出一个元素
T pop();//在栈中删除一个元素
int size();//大小
int isEmpty();//判断是否为空
private:
T *arr;//数组?
int count;
};
// 创建“栈”,默认大小是12
template<class T>
ArrayStack<T>::ArrayStack() //构造函数
{
arr = new T[12];
if (!arr)
{
cout<<"arr malloc error!"<<endl;
}
}
// 销毁“栈”,析构函数
template<class T>
ArrayStack<T>::~ArrayStack()
{
if (arr)
{
delete[] arr;
arr = NULL;
}
}
// 将val添加到栈中
//向栈中添加一个元素
template<class T>
void ArrayStack<T>::push(T t)
{
//arr[count++] = val;
arr[count++] = t;
}
// 返回“栈顶元素值”
template<class T>
T ArrayStack<T>::peek()
{
return arr[count-1];
}
// 返回“栈顶元素值”,并删除“栈顶元素”
template<class T>
T ArrayStack<T>::pop()
{
int ret = arr[count-1];
count--;
return ret;
}
// 返回“栈”的大小
template<class T>
int ArrayStack<T>::size()
{
return count;
}
// 返回“栈”是否为空
template<class T>
int ArrayStack<T>::isEmpty()
{
return size()==0;
}
#endif
//主函数部分
#include <iostream>
#include "ArrayStack.h"
using namespace std;
int main()
{
int tmp=0;
ArrayStack<int> *astack = new ArrayStack<int>();
cout<<"main"<<endl;
// 将10, 20, 30 依次推入栈中
astack->push(10);
astack->push(20);
astack->push(30);
// 将“栈顶元素”赋值给tmp,并删除“栈顶元素”
tmp = astack->pop();
cout<<"tmp="<<tmp<<endl;
// 只将“栈顶”赋值给tmp,不删除该元素.
tmp = astack->peek();
astack->push(40);
while (!astack->isEmpty())
{
tmp = astack->pop();
cout<<tmp<<endl;
}
system("pause");
return 0;
}
2.C++实现二:C++的 STL 中自带的"栈"(stack)的示例。
#include <iostream>
#include <stack>
using namespace std;
/*
* C++ 语言: STL 自带的“栈”(stack)的示例。
*/
int main ()
{
int tmp=0;
stack<int> istack;//定义为int类型的函数
// 将10, 20, 30 依次推入栈中
istack.push(10);
istack.push(20);
istack.push(30);
// 将“栈顶元素”赋值给tmp,并删除“栈顶元素”
istack.pop();
// 只将“栈顶”赋值给tmp,不删除该元素.
tmp = istack.top();
istack.push(40);
while (!istack.empty())
{
tmp = istack.top();
istack.pop();
cout<<tmp<<endl;
}
system("pause");
return 0;
}
数据结构——队列
队列(Queue),一种运算受限的线性表,先进先出(FIFO First In First Out)
受限之处在于它只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作
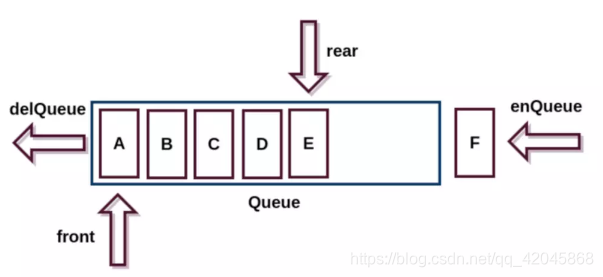
队列举例:
1.生活中类似队列的场景就是非常多了, 比如在电影院, 商场, 甚至是厕所排队.
2.优先排队的人, 优先处理. (买票, 结账, WC)
队列应用:
1.打印队列:
有五份文档需要打印, 这些文档会按照次序放入到打印队列中.
打印机会依次从队列中取出文档, 优先放入的文档, 优先被取出, 并且对该文档进行打印.
以此类推, 直到队列中不再有新的文档.
2.线程队列:
在进行多线程开发时, 不可能无限制的开启新的线程.
这个时候, 如果有需要开启线程处理任务的情况, 我们就会使用线程队列.
线程队列会依照次序来启动线程, 并且处理对应的任务.
队列的操作
top 访问队头元素
empty 队列是否为空
size 返回队列内元素个数
push 插入元素到队尾 (并排序)
emplace 原地构造一个元素并插入队列
pop 弹出队头元素
swap 交换内容
队列实现
队列通常包括的两种操作:入队列 和 出队列。
C++的STL中本身就包含了list类,基本上该list类就能满足我们的需求,所以很少需要我们自己来实现。本部分介绍2种C++实现。
1.C++实现一:数组实现的队列,能存储任意类型的数据。
#ifndef ARRAY_QUEUE_HXX
#define ARRAY_QUEUE_HXX
#include <iostream>
using namespace std;
template<class T> class ArrayQueue{
public:
ArrayQueue();
~ArrayQueue();
void add(T t);
T front();
T pop();
int size();
int is_empty();
private:
T *arr;
int count;
};
// 创建“队列”,默认大小是12
template<class T>
ArrayQueue<T>::ArrayQueue()
{
arr = new T[12];
if (!arr)
{
cout<<"arr malloc error!"<<endl;
}
}
// 销毁“队列”
template<class T>
ArrayQueue<T>::~ArrayQueue()
{
if (arr)
{
delete[] arr;
arr = NULL;
}
}
// 将val添加到队列的末尾
template<class T>
void ArrayQueue<T>::add(T t)
{
arr[count++] = t;
}
// 返回“队列开头元素”
template<class T>
T ArrayQueue<T>::front()
{
return arr[0];
}
// 返回并删除“队列末尾的元素”
template<class T>
T ArrayQueue<T>::pop()
{
int i = 0;;
T ret = arr[0];
count--;
while (i++<count)
arr[i-1] = arr[i];
return ret;
}
// 返回“队列”的大小
template<class T>
int ArrayQueue<T>::size()
{
return count;
}
// 返回“队列”是否为空
template<class T>
int ArrayQueue<T>::is_empty()
{
return count==0;
}
#endif
//主函数部分
#include <iostream>
#include "ArrayQueue.h"
using namespace std;
/**
* C++ : 数组实现“队列”,能存储任意数据。
*/
int main()
{
int tmp=0;
ArrayQueue<int> *astack = new ArrayQueue<int>();
// 将10, 20, 30 依次推入队列中
astack->add(10);
astack->add(20);
astack->add(30);
// 将“队列开头元素”赋值给tmp,并删除“该元素”
tmp = astack->pop();
cout<<"tmp="<<tmp<<endl;
// 只将“队列开头的元素”赋值给tmp,不删除该元素.
tmp = astack->front();
cout<<"tmp="<<tmp<<endl;
astack->add(40);
cout<<"is_empty()="<<astack->is_empty()<<endl;
cout<<"size()="<<astack->size()<<endl;
while (!astack->is_empty())
{
tmp = astack->pop();
cout<<tmp<<endl;
}
return 0;
}
2.C++实现二:C++的 STL 中自带的"队列"(list)的示例。
#include <iostream>
#include <queue>
using namespace std;
/**
* C++ : STL中的队列(queue)的演示程序。
*/
int main ()
{
int tmp=0;
queue<int> iqueue;
// 将10, 20, 30 依次加入队列的末尾
iqueue.push(10);
iqueue.push(20);
iqueue.push(30);
// 删除队列开头的元素
iqueue.pop();
// 将“队列开头的元素”赋值给tmp,不删除该元素.
tmp = iqueue.front();
cout<<"tmp="<<tmp<<endl;
// 将40加入到队列的末尾
iqueue.push(40);
cout << "empty()=" << iqueue.empty() <<endl;
cout << "size()=" << iqueue.size() <<endl;
while (!iqueue.empty())
{
tmp = iqueue.front();
cout<<tmp<<endl;
iqueue.pop();
}
return 0;
}
优先级队列
与插入顺序无关, 而和元素本身的优先级有关系的队列。这种队列就是优先级队列.。
优先级队列的特点:
普通的队列插入一个元素, 数据会被放在后端. 并且需要前面所有的元素都处理完成后才会处理后面的数据.
但是优先级队列, 在插入一个元素的时候会考虑该数据的优先级.(和其他数据优先级进行比较)
比较完成后, 可以得出这个元素正确的队列中的位置. 其他处理方式, 和队列的处理方式一样.
也就是说, 如果我们要实现优先级队列, 最主要是要修改添加方法. (当然, 还需要以某种方式来保存元素的优先级)
优先级队列应用
1.头等舱和商务舱乘客的优先级要高于经济舱乘客。
2.医生会优先处理病情比较严重的患者
3.每个线程处理的任务重要性不同, 通过优先级的大小, 来决定该线程在队列中被处理的次序.
队列面试题
击鼓传花:使用队列可以非常方便的实现最终的结果。
数据结构之链表
链表和数组
数组:
要存储多个元素,数组(或列表)可能是最常用的数据结构。
几乎每一种编程语言都有默认实现数组结构,提供了一个便利的[]语法来访问它的元素。
缺点:
数组的创建通常需要申请一段连续的内存空间(一整块的内存), 并且大小是固定的(大多数编程语言数组都是固定的), 当当前数组不能满足容量需求时, 需要扩容. (一般情况下是申请一个更大的数组, 比如2倍. 然后将原数组中的元素复制过去)
而且在数组开头或中间位置插入数据的成本很高, 需要进行大量元素的位移.
链表
要存储多个元素, 另外一个选择就是使用链表.
链表中的元素在内存中不必是连续的空间.
链表的每个元素由一个存储元素本身的节点和一个指向下一个元素的引用(有些语言称为指针或者链接)组成.
优点:
内存空间不是连续的. 可以充分利用计算机的内存. 实现灵活的内存动态管理.
链表不必在创建时就确定大小, 并且大小可以无限的延伸下去.
链表在插入和删除数据时, 时间复杂度可以达到O(1). 相对数组效率高很多.
缺点:
链表访问任何一个位置的元素时, 都需要从头开始访问.(无法跳过第一个元素访问任何一个元素).
无法通过下标直接访问元素, 需要从头一个个访问, 直到找到对应的问题.
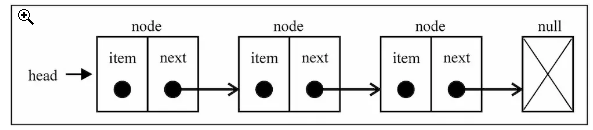
链表常见操作
C++单链表的操作
2017-12-25
// 单链表.cpp: 定义控制台应用程序的入口点。
#include "stdafx.h"
#include<iostream>
using namespace std;
typedef int DataType;
#define Node ElemType
#define ERROR NULL
//构建一个节点类
class Node
{
public:
int data; //数据域
Node * next; //指针域
};
//构建一个单链表类
class LinkList
{
public:
LinkList(); //构建一个单链表;
~LinkList(); //销毁一个单链表;
void CreateLinkList(int n); //创建一个单链表
void TravalLinkList(); //遍历线性表
int GetLength(); //获取线性表长度
bool IsEmpty(); //判断单链表是否为空
ElemType * Find(DataType data); //查找节点
void InsertElemAtEnd(DataType data); //在尾部插入指定的元素
void InsertElemAtIndex(DataType data,int n); //在指定位置插入指定元素
void InsertElemAtHead(DataType data); //在头部插入指定元素
void DeleteElemAtEnd(); //在尾部删除元素
void DeleteAll(); //删除所有数据
void DeleteElemAtPoint(DataType data); //删除指定的数据
void DeleteElemAtHead(); //在头部删除节点
private:
ElemType * head; //头结点
};
//初始化单链表
LinkList::LinkList()
{
head = new ElemType;
head->data = 0; //将头结点的数据域定义为0
head->next = NULL; //头结点的下一个定义为NULL
}
//销毁单链表
LinkList::~LinkList()
{
delete head; //删除头结点
}
//创建一个单链表
void LinkList::CreateLinkList(int n)
{
ElemType *pnew, *ptemp;
ptemp = head;
if (n < 0) { //当输入的值有误时,处理异常
cout << "输入的节点个数有误" << endl;
exit(EXIT_FAILURE);
}
for (int i = 0; i < n;i++) { //将值一个一个插入单链表中
pnew = new ElemType;
cout << "请输入第" << i + 1 << "个值: " ;
cin >> pnew->data;
pnew->next = NULL; //新节点的下一个地址为NULL
ptemp->next = pnew; //当前结点的下一个地址设为新节点
ptemp = pnew; //将当前结点设为新节点
}
}
//遍历单链表
void LinkList::TravalLinkList()
{
if (head == NULL || head->next ==NULL) {
cout << "链表为空表" << endl;
}
ElemType *p = head; //另指针指向头结点
while (p->next != NULL) //当指针的下一个地址不为空时,循环输出p的数据域
{
p = p->next; //p指向p的下一个地址
cout << p->data << " ";
}
}
//获取单链表的长度
int LinkList::GetLength()
{
int count = 0; //定义count计数
ElemType *p = head->next; //定义p指向头结点
while (p != NULL) //当指针的下一个地址不为空时,count+1
{
count++;
p = p->next; //p指向p的下一个地址
}
return count; //返回count的数据
}
//判断单链表是否为空
bool LinkList::IsEmpty()
{
if (head->next == NULL) {
return true;
}
return false;
}
//查找节点
ElemType * LinkList::Find(DataType data)
{
ElemType * p = head;
if (p == NULL) { //当为空表时,报异常
cout << "此链表为空链表" << endl;
return ERROR;
}
else
{
while (p->next != NULL) //循环每一个节点
{
if (p->data == data) {
return p; //返回指针域
}
p = p->next;
}
return NULL; //未查询到结果
}
}
//在尾部插入指定的元素
void LinkList::InsertElemAtEnd(DataType data)
{
ElemType * newNode = new ElemType; //定义一个Node结点指针newNode
newNode->next = NULL; //定义newNode的数据域和指针域
newNode->data = data;
ElemType * p = head; //定义指针p指向头结点
if (head == NULL) { //当头结点为空时,设置newNode为头结点
head = newNode;
}
else //循环知道最后一个节点,将newNode放置在最后
{
while (p->next != NULL)
{
p = p->next;
}
p->next = newNode;
}
}
//在指定位置插入指定元素
void LinkList::InsertElemAtIndex(DataType data,int n)
{
if (n<1 || n>GetLength()) //输入有误报异常
cout << "输入的值错误" << endl;
else
{
ElemType * ptemp = new ElemType; //创建一个新的节点
ptemp->data = data; //定义数据域
ElemType * p = head; //创建一个指针指向头结点
int i = 1;
while (n > i) //遍历到指定的位置
{
p = p->next;
i++;
}
ptemp->next = p->next; //将新节点插入到指定位置
p->next = ptemp;
}
}
//在头部插入指定元素
void LinkList::InsertElemAtHead(DataType data)
{
ElemType * newNode = new ElemType; //定义一个Node结点指针newNode
newNode->data = data;
ElemType * p = head; //定义指针p指向头结点
if (head == NULL) { //当头结点为空时,设置newNode为头结点
head = newNode;
}
newNode->next = p->next; //将新节点插入到指定位置
p->next = newNode;
}
//在尾部删除元素
void LinkList::DeleteElemAtEnd()
{
ElemType * p = head; //创建一个指针指向头结点
ElemType * ptemp = NULL; //创建一个占位节点
if (p->next == NULL) { //判断链表是否为空
cout << "单链表空" << endl;
}
else
{
while (p->next != NULL) //循环到尾部的前一个
{
ptemp = p; //将ptemp指向尾部的前一个节点
p = p->next; //p指向最后一个节点
}
delete p; //删除尾部节点
p = NULL;
ptemp->next = NULL;
}
}
//删除所有数据
void LinkList::DeleteAll()
{
ElemType * p = head->next;
ElemType * ptemp = new ElemType;
while (p != NULL) //在头结点的下一个节点逐个删除节点
{
ptemp = p;
p = p->next;
head->next = p;
ptemp->next = NULL;
delete ptemp;
}
head->next = NULL; //头结点的下一个节点指向NULL
}
//删除指定的数据
void LinkList::DeleteElemAtPoint(DataType data)
{
ElemType * ptemp = Find(data); //查找到指定数据的节点位置
if (ptemp == head->next) { //判断是不是头结点的下一个节点,如果是就从头部删了它
DeleteElemAtHead();
}
else
{
ElemType * p = head; //p指向头结点
while (p->next != ptemp) //p循环到指定位置的前一个节点
{
p = p->next;
}
p->next = ptemp->next; //删除指定位置的节点
delete ptemp;
ptemp = NULL;
}
}
//在头部删除节点
void LinkList::DeleteElemAtHead()
{
ElemType * p = head;
if (p == NULL || p->next == NULL) { //判断是否为空表,报异常
cout << "该链表为空表" << endl;
}
else
{
ElemType * ptemp = NULL; //创建一个占位节点
p = p->next;
ptemp = p->next; //将头结点的下下个节点指向占位节点
delete p; //删除头结点的下一个节点
p = NULL;
head->next = ptemp; //头结点的指针更换
}
}
//测试函数
int main()
{
LinkList l;
int i;
cout << "1.创建单链表 2.遍历单链表 3.获取单链表的长度 4.判断单链表是否为空 5.获取节点\n";
cout << "6.在尾部插入指定元素 7.在指定位置插入指定元素 8.在头部插入指定元素\n";
cout<<"9.在尾部删除元素 10.删除所有元素 11.删除指定元素 12.在头部删除元素 0.退出" << endl;
do
{
cout << "请输入要执行的操作: ";
cin >> i;
switch (i)
{
case 1:
int n;
cout << "请输入单链表的长度: ";
cin >> n;
l.CreateLinkList(n);
break;
case 2:
l.TravalLinkList();
break;
case 3:
cout << "该单链表的长度为" << l.GetLength() << endl;
break;
case 4:
if (l.IsEmpty() == 1)
cout << "该单链表是空表" << endl;
else
{
cout << "该单链表不是空表" << endl;
}
break;
case 5:
DataType data;
cout << "请输入要获取节点的值: ";
cin >> data;
cout << "该节点的值为" << l.Find(data)->data << endl;
break;
case 6:
DataType endData;
cout << "请输入要在尾部插入的值: ";
cin >> endData;
l.InsertElemAtEnd(endData);
break;
case 7:
DataType pointData;
int index;
cout << "请输入要插入的数据: ";
cin >> pointData;
cout << "请输入要插入数据的位置: ";
cin >> index;
l.InsertElemAtIndex(pointData, index);
break;
case 8:
DataType headData;
cout << "请输入要在头部插入的值: ";
cin >> headData;
l.InsertElemAtHead(headData);
break;
case 9:
l.DeleteElemAtEnd();
break;
case 10:
l.DeleteAll();
break;
case 11:
DataType pointDeleteData;
cout << "请输入要删除的数据: ";
cin >> pointDeleteData;
l.DeleteElemAtPoint(pointDeleteData);
break;
case 12:
l.DeleteElemAtHead();
break;
default:
break;
}
}while (i != 0);
system("pause");
return 0;
}
数据结构之树
树也是一种非常常用的数据结构, 特别是二叉树,是程序中一种非常重要的数据结构。
树的特点
树通常有一个根. 连接着根的是树干.
树干到上面之后会进行分叉成树枝, 树枝还会分叉成更小的树枝.
在树枝的最后是叶子.
树结构
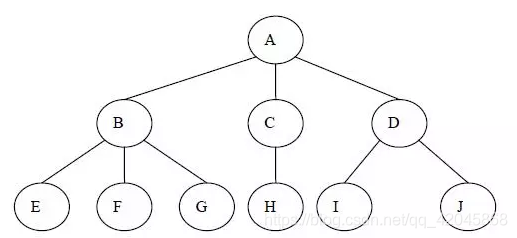
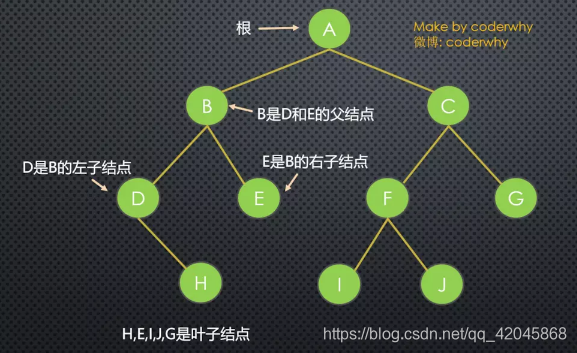
树(Tree): n(n≥0)个结点构成的有限集合。
当n=0时,称为空树;
对于任一棵非空树(n> 0),它具备以下性质:
树中有一个称为“根(Root)”的特殊结点,用 r 表示;
其余结点可分为m(m>0)个互不相交的有限集T1,T2,… ,Tm,其中每个集合本身又是一棵树,称为原来树的“子树(SubTree)”
子树之间不可以相交
除了根结点外,每个结点有且仅有一个父结点;
一棵N个结点的树有N-1条边。
树的术语:
1**.结点的度**(Degree):结点的子树个数.
2.树的度:树的所有结点中最大的度数. (树的度通常为结点的个数N-1)
3.叶结点(Leaf):度为0的结点. (也称为叶子结点)
4.父结点(Parent):有子树的结点是其子树的根结点的父结点
5.子结点(Child):若A结点是B结点的父结点,则称B结点是A结点的子结点;子结点也称孩子结点。
6.兄弟结点(Sibling):具有同一父结点的各结点彼此是兄弟结点。
7.路径和路径长度:从结点n1到nk的路径为一个结点序列n1 , n2,… , nk, ni是 ni+1的父结点。路径所包含边的个数为路径的长度。
8.结点的层次(Level):规定根结点在1层,其它任一结点的层数是其父结点的层数加1。
9.树的深度(Depth):树中所有结点中的最大层次是这棵树的深度
二叉树
树中每个节点最多只能有两个子节点, 这样的树就成为"二叉树".
二叉树可以为空, 也就是没有结点.
若不为空,则它是由根结点和称为其左子树TL和右子树TR的两个不相交的二叉树组成。
二叉树是有左右之分的.
二叉树的特性
一个二叉树第 i 层的最大结点数为:2^(i-1), i >= 1
深度为k的二叉树有最大结点总数为: 2^k - 1, k >= 1;
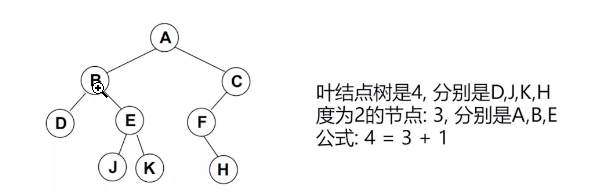
对任何非空二叉树 T,若n0表示叶结点的个数、n2是度为2的非叶结点个数,那么两者满足关系n0 = n2 + 1。
完美二叉树(Perfect Binary Tree) , 也称为满二叉树(Full Binary Tree)
在二叉树中, 除了最下一层的叶结点外, 每层节点都有2个子结点, 就构成了满二叉树.
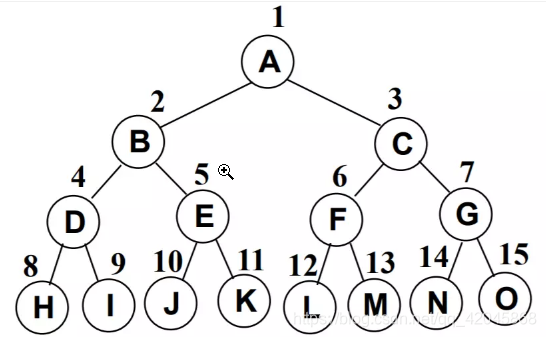
完全二叉树(Complete Binary Tree)
除二叉树最后一层外, 其他各层的节点数都达到最大个数.
且最后一层从左向右的叶结点连续存在, 只缺右侧若干节点.
完美二叉树是特殊的完全二叉树.
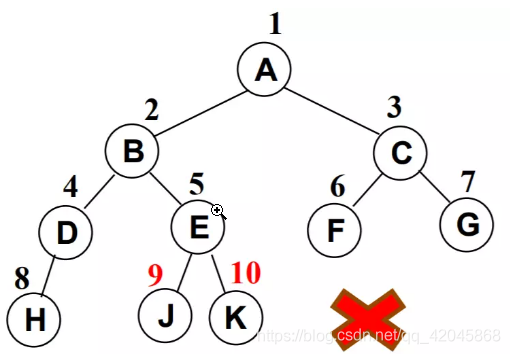
下面不是完全二叉树, 因为D节点还没有右结点,E节点就有了左右节点.
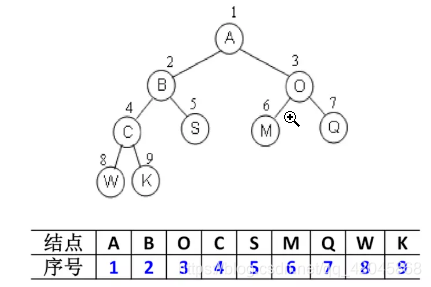
二叉树的存储常见的方式是数组和链表.
1.使用数组存储:
完全二叉树: 按从上至下、从左到右顺序存储
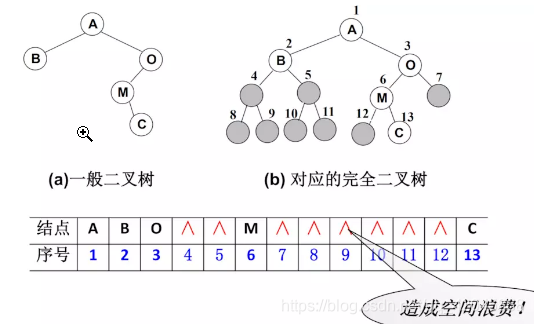
非完全二叉树:要转成完全二叉树才可以按照上面的方案存储,但是会造成很大的空间浪费
2.链表存储:
二叉树最常见的方式还是使用链表存储.
每个结点封装成一个Node, Node中包含存储的数据, 左结点的引用, 右结点的引用.
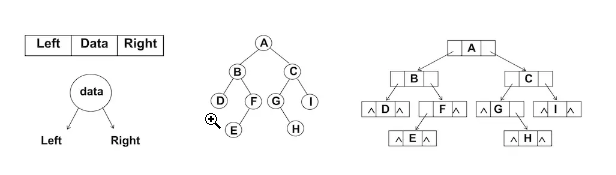
数据结构——二叉搜索树
为二叉树再增加一个限制, 那么就可以形成一个二叉搜索树.
二叉搜索树(BST,Binary Search Tree),也称二叉排序树或二叉查找树
二叉搜索树是一颗二叉树, 可以为空;如果不为空,满足以下性质:
非空左子树的所有键值小于其根结点的键值。
非空右子树的所有键值大于其根结点的键值。
左、右子树本身也都是二叉搜索树。
哪些是二叉搜索树, 哪些不是
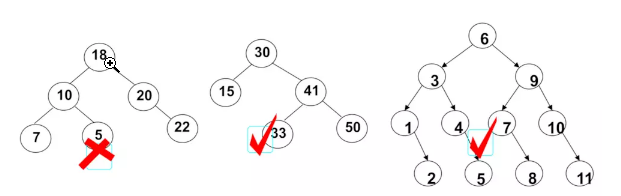
二叉搜索树的特点:
相对较小的值总是保存在左结点上, 相对较大的值总是保存在右结点上.
那么利用这个特点,查找效率非常高, 这也是二叉搜索树中, 搜索的来源。
二叉搜索树的操作
insert(key):向树中插入一个新的键。
search(key):在树中查找一个键,如果结点存在,则返回true;如果不存在,则返回false。
inOrderTraverse:通过中序遍历方式遍历所有结点。
preOrderTraverse:通过先序遍历方式遍历所有结点。
postOrderTraverse:通过后序遍历方式遍历所有结点。
min:返回树中最小的值/键。
max:返回树中最大的值/键。
remove(key):从树中移除某个键。
二叉搜索树的实现
遍历二叉搜索树
树的遍历:
遍历一棵树是指访问树的每个结点,也可以对每个结点进行某些操作
但是树和线性结构不太一样, 线性结构通常按照从前到后的顺序遍历,
二叉树的遍历常见的有三种方式: 先序遍历/中序遍历/后续遍历. (还有程序遍历, 使用较少, 可以使用队列来完成)
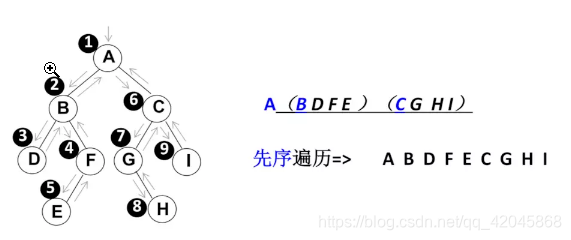
先序遍历
遍历过程为:①访问根结点;②先序遍历其左子树;③先序遍历其右子树。
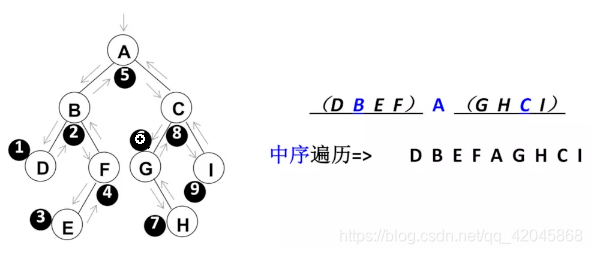
中序遍历
遍历过程为:①中序遍历其左子树;②访问根结点;③中序遍历其右子树。
后序遍历
遍历过程为:①后序遍历其左子树;②后序遍历其右子树;③访问根结点。
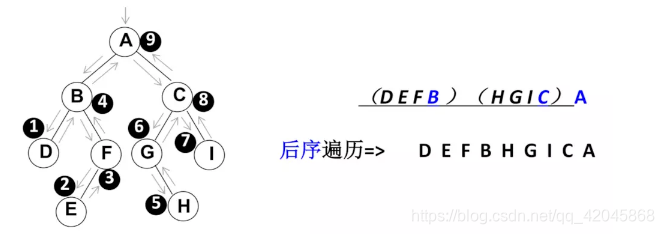
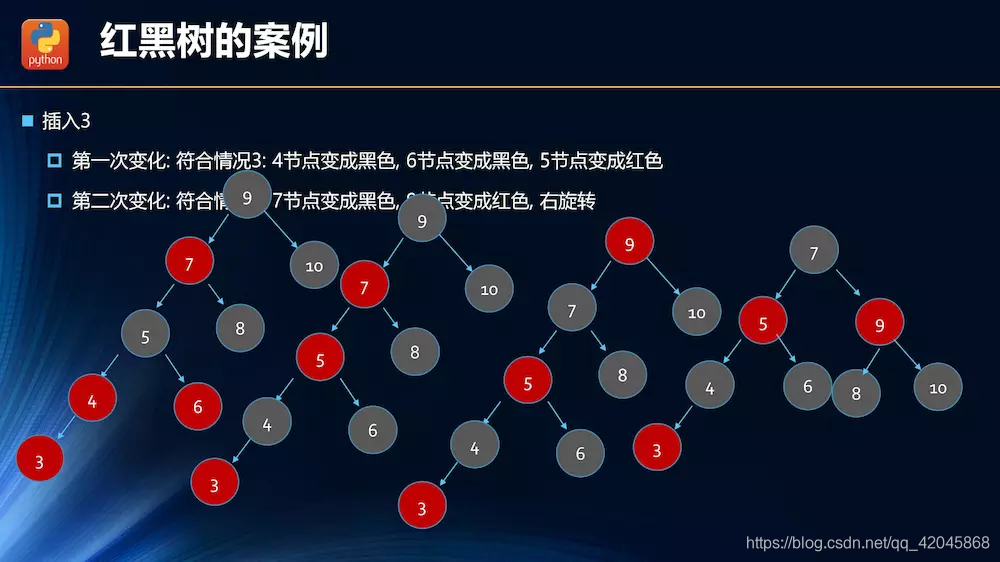
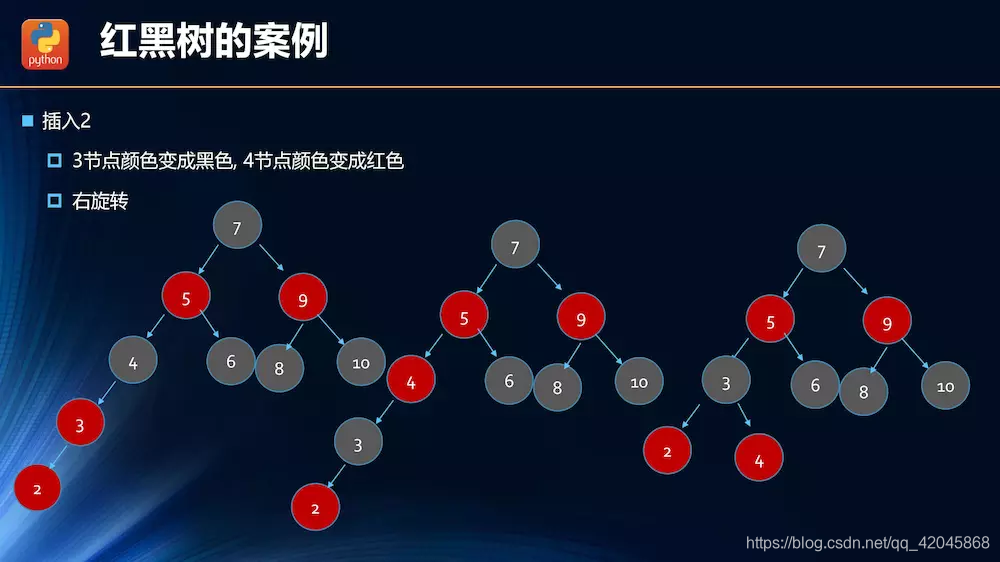
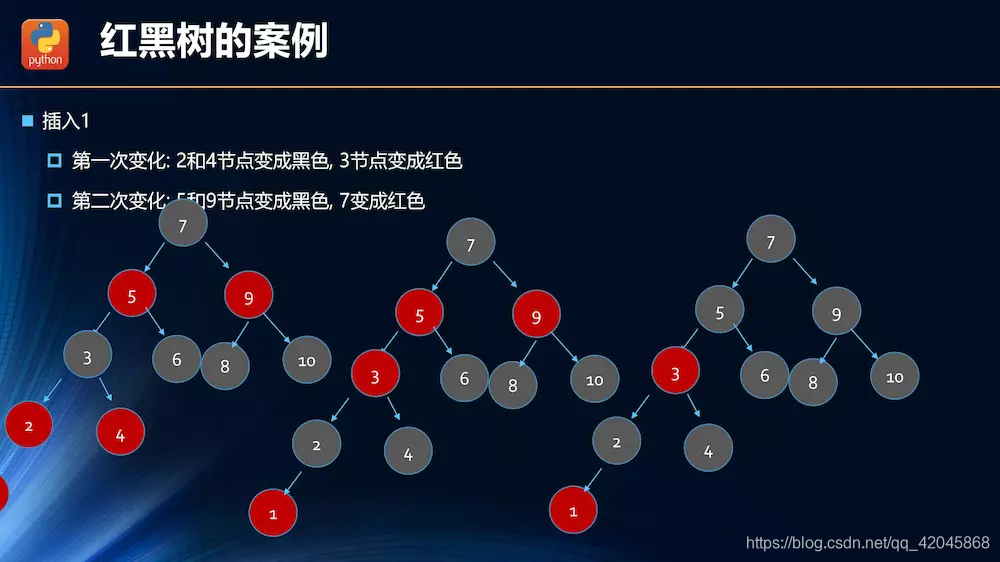
数据结构——红黑树
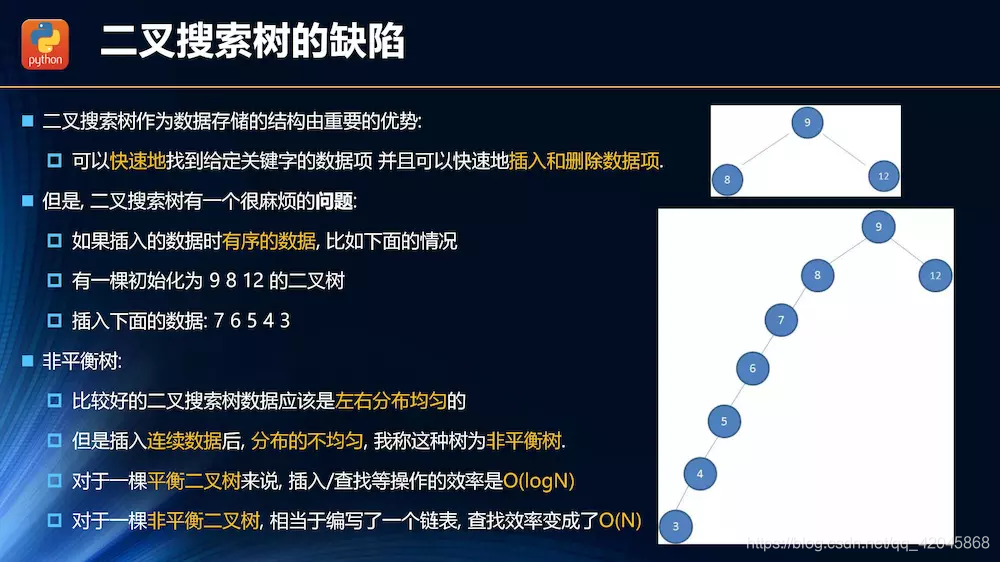
非平衡树降低了查找效率。
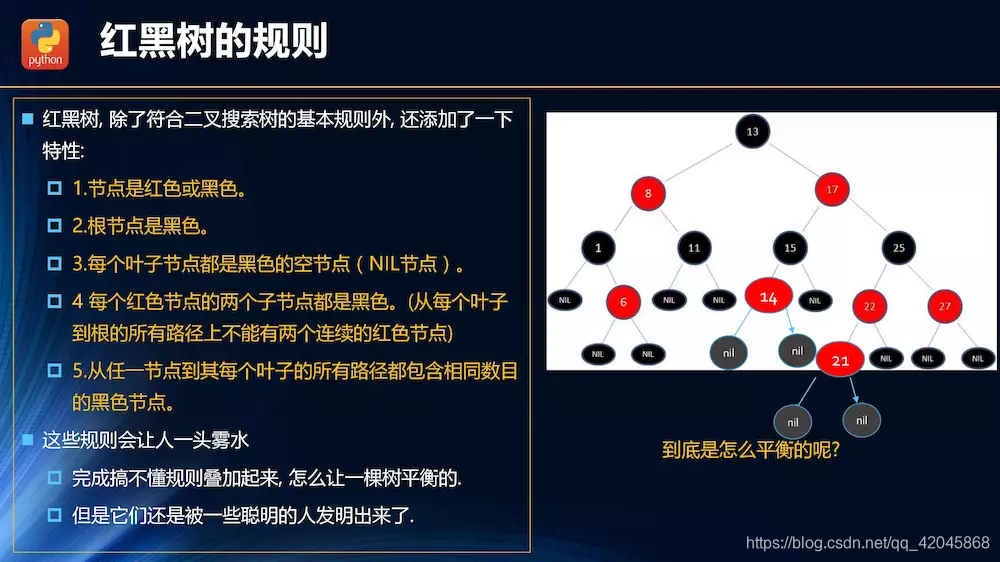
红黑树性能更优越,一般平衡树都是用红黑树。


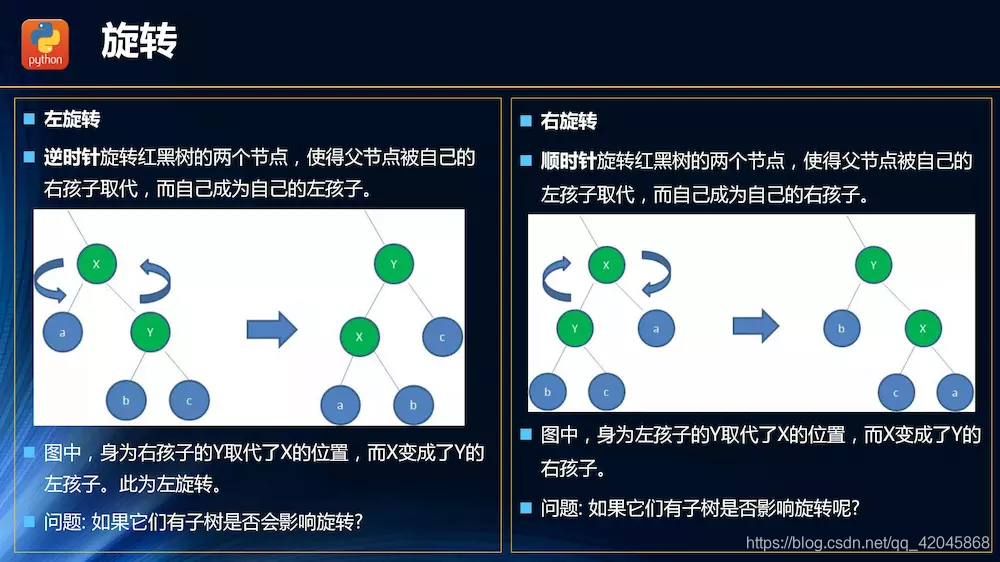
红黑树的变换

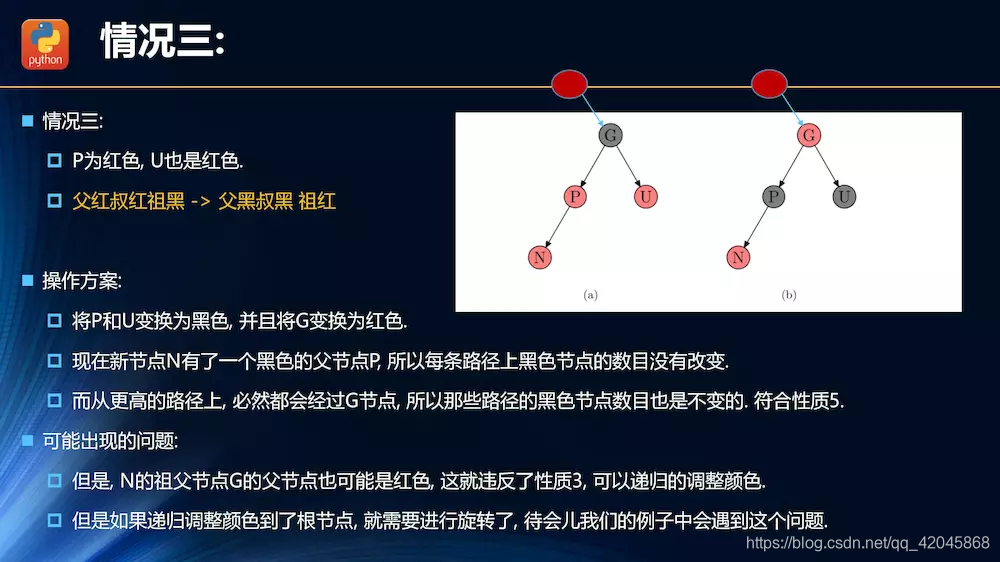
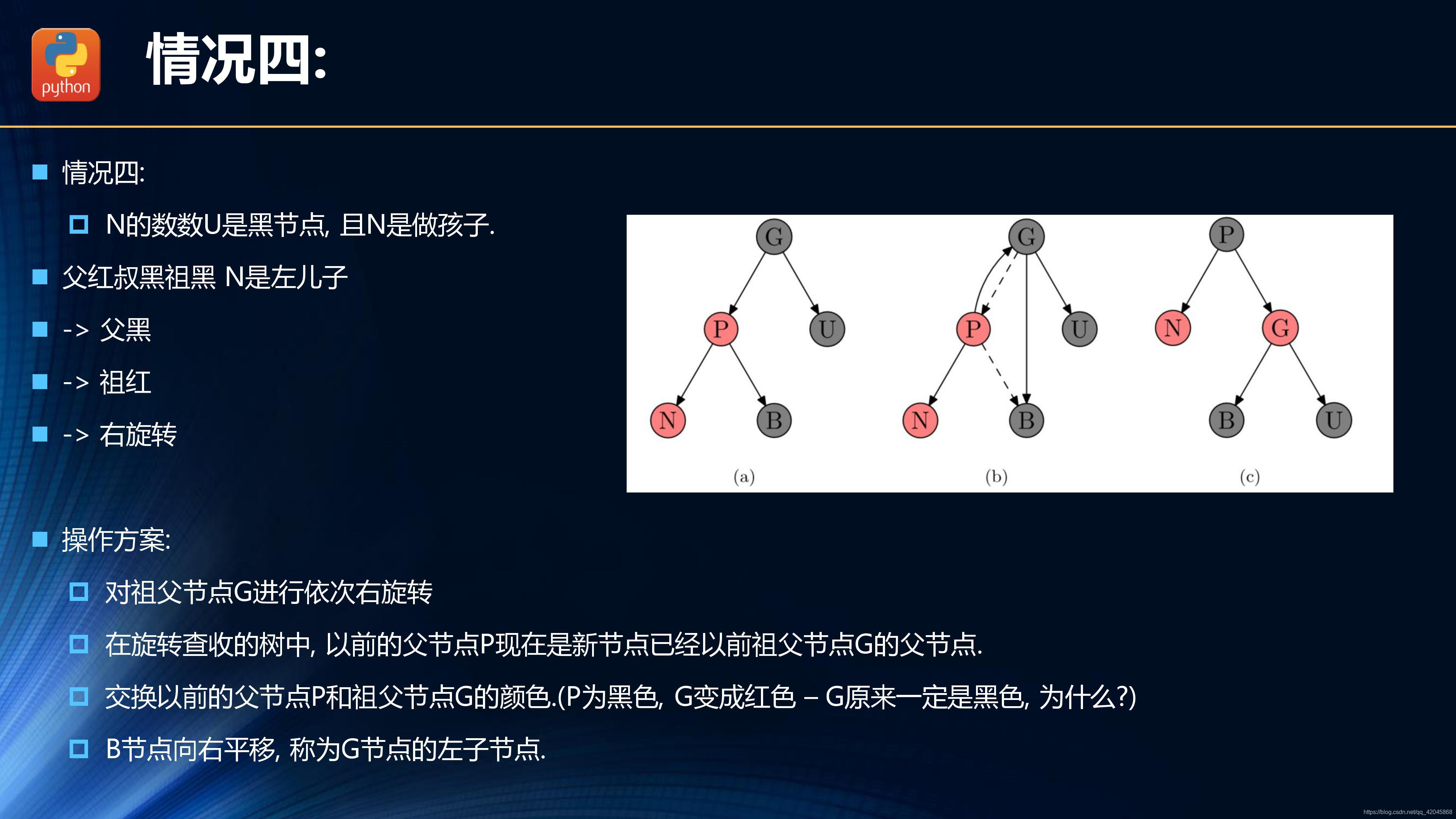
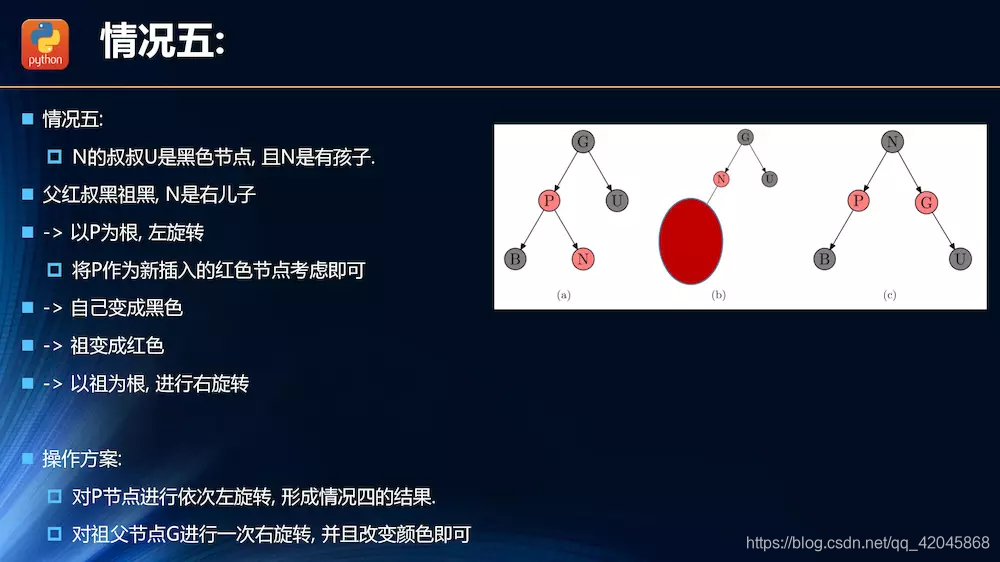
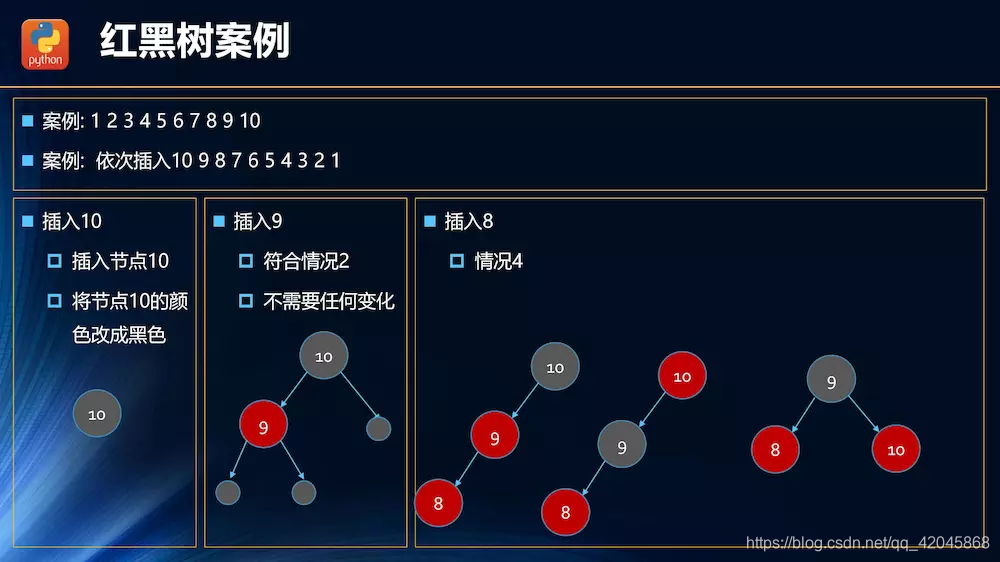
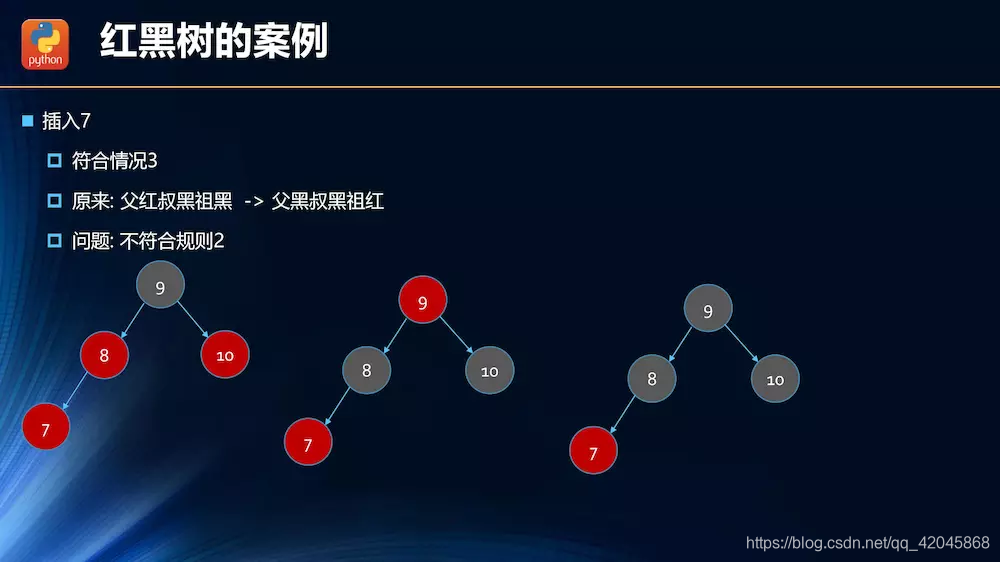
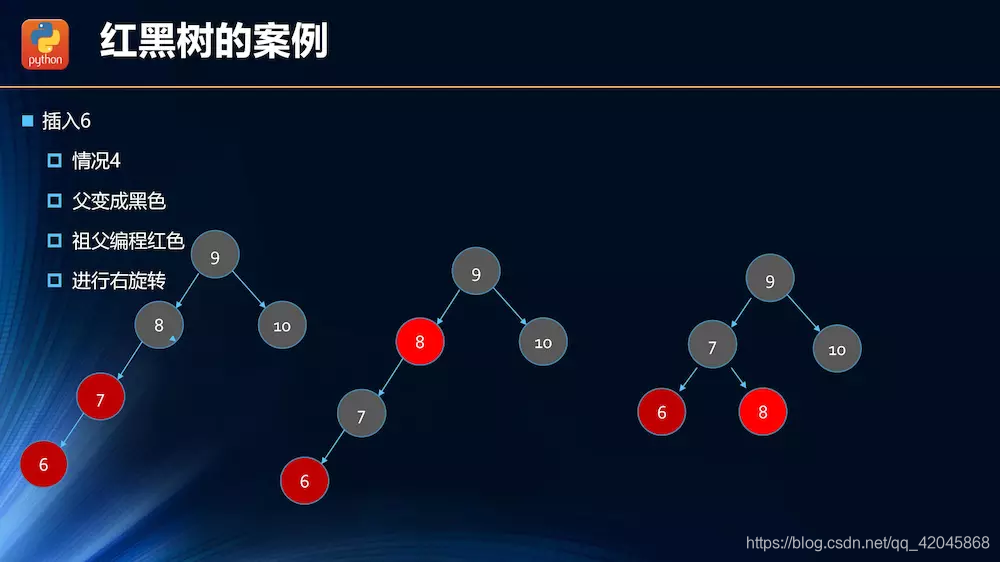
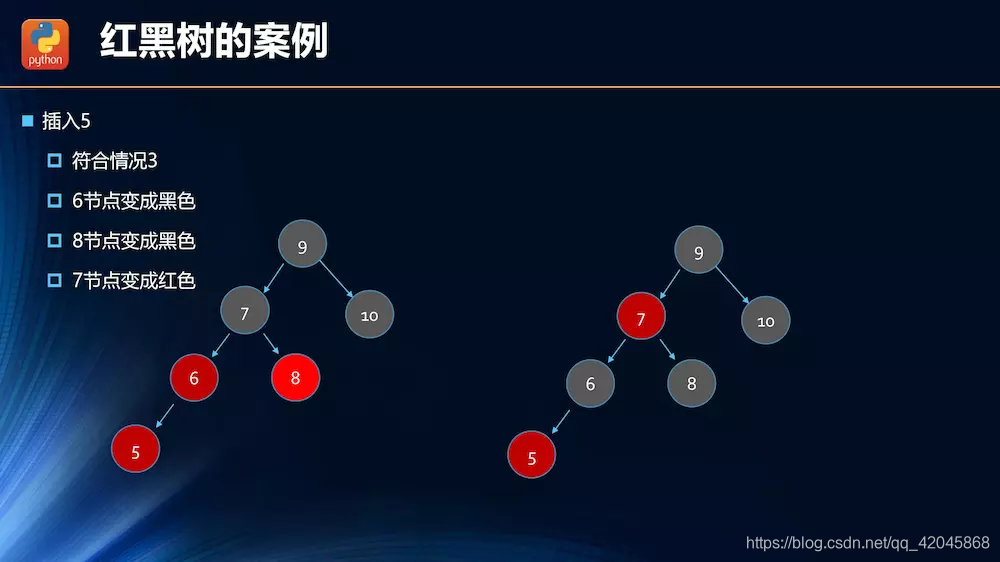
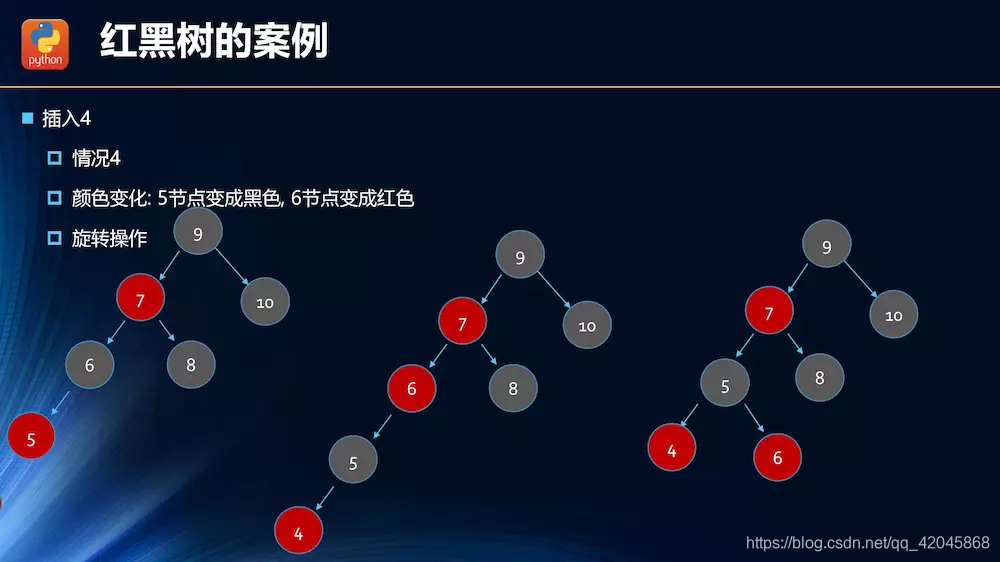
插入操作的情况分析

 .
.


















 2407
2407

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









