









一、前言
“分库分表”这一词大家都基本都知道,无非就是数据量过于庞大,几百万,几千万,甚至过亿的数据,在查询的时候特别地耗性能且查询等待时间过长,如果是碰上多张表关联的情况,那后果可想而知。之前在一次工作中,项目组长要我优化一句SQL,这句SQL关联了10多张表,数据量在500百万左右,而且没有建索引,在SQL里面还用到了模糊查询,我直接当场裂开,优化了老半天,勉勉强强从原来的3分多中优化到了2分多钟,老实说,尽力了,按他现在的数据库表结构,这已经是极限了。归咎到底还是在数据量太庞大的原因上,一条数据有很多个字段,且字段里掺杂了josn函数,还得去解析json的内容。当然,这个数据库结构原本也是设计不合理(吐槽中)。
备注:这篇文章主要讲解Sharing-JDBC的水平分库分表,关于Sharding-JDBC的垂直分库分表和Sharding-Proxy的讲解,以后有空的时候进行更新。
二、什么是ShardingSphere
ShardingSphere现在已经发展成了一个生态圈,有JDBC、Proxy、Sidecar三款组成,目前Sidecar还在规划中。这篇文章主要讲JDBC、Proxy的原理和使用。关于ShardingSphere的介绍,可以到官网查看:http://shardingsphere.apache.org/index_zh.html,目前它已经由apache进行管理,发展到5.x版本。
三、ShardingSphere的作用
ShardingSphere的作用当然是用来分库分表的。它的分库分表方式分为逻辑层和代理层。
逻辑层用ShardingSphere-JDBC实现,说白了,就是用Java代码去控制,只要在配置文件里写好了分库分表的策略,那么在执行SQL语句的时候,它就会解析SQL语句,然后对数据执行持久化操作。比如:当你执行插入insert语句的时候,通过在配置文件里面写好的分库分表策略,SpringSphere-JDBC解析你的insert语句,然后将数据分别插入到各自的库和各自的表中去。
代理层用ShardingSphere-Proxy实现,这时候它就与Java代码无关了。可以理解为ShardingSphere-Proxy就是一个数据库,在代码里你只需要对这一个数据库进行操作,ShardingSphere-Proxy这个数据库它就会自动将数据分发到真实的数据库和表之中去,当然,前提是已经对ShardingSphere-Proxy配置好了分库分表策略。
四、分库分表策略
分库分表分为水平拆分和垂直拆分。
水平拆分,就是有多个相同的库和表,结构完全相同,数据不同。
垂直拆分,就是专库专表,或者是可以理解为将原本的库和表进行拆分,比如将库分为用户库,订单库等。
五、Sharding-JDBC使用
新建工程,引入依赖,我这里使用springboot+mybatis-plus进行整合sharding-jdbc。
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.2.1.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.chen</groupId>
<artifactId>chen</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>ShardingSphereTest</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.20</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.0.5</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
1、水平分表
先设置两个相同的表,user_1,user_2,如图:


在application.properties中配置数据源 test_db_1 ,取别名为 t1 ,并申明要来分表的两个表 user_1 和 user_2 ,接下来利用Sharding-JDBC的雪花随机数 SNOWFLAKE ,随机生成主键,如果生成的数是偶数,那就将数据插入到 user_1 表,如果是奇数,则插入到 user_2 表。同理,如果是查询,uid 为偶数时,则查询 user_1 表,如果为奇数时,则查询 user_2 表。
# 配置真实数据源
spring.shardingsphere.datasource.names=t1
# 配置 t1 数据源
spring.shardingsphere.datasource.t1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.t1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.t1.url=jdbc:mysql://localhost:3306/test_db_1?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.t1.username=root
spring.shardingsphere.datasource.t1.password=123456
#指定数据库分布情况,数据库里面表分布情况
# t1
spring.shardingsphere.sharding.tables.user.actual-data-nodes=t1.user_$->{1..2}
# 指定user表里面主键uid 生成策略SNOWFLAKE(雪花随机数)
spring.shardingsphere.sharding.tables.user.key-generator.column=uid
spring.shardingsphere.sharding.tables.user.key-generator.type=SNOWFLAKE
# 指定表分片策略 约定uid值偶数添加到user_1表,如果uid是奇数添加到user_2表
spring.shardingsphere.sharding.tables.user.table-strategy.inline.sharding-column=uid
spring.shardingsphere.sharding.tables.user.table-strategy.inline.algorithm-expression=user_$->{uid % 2 + 1}
# 打开sql输出日志
spring.shardingsphere.props.sql.show=true
# 解决bean重复定义报错
spring.main.allow-bean-definition-overriding=true
User实体类
package com.chen.entity;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
@Data
@TableName(value = "user") //指定对应表
public class User {
private Long uid;
private String username;
private String sex;
}Mapper持久层
package com.chen.mapper;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.chen.entity.User;
import org.springframework.stereotype.Repository;
@Repository
public interface UserMapper extends BaseMapper<User> {
}
测试
package com.chen;
import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper;
import com.chen.entity.User;
import com.chen.mapper.UserMapper;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
@RunWith(SpringRunner.class)
@SpringBootTest
public class ShardingSphereTest {
@Autowired
private UserMapper userMapper;
/* #################### 水平分表 #################### */
// 添加操作
@Test
public void addUser() {
User user = new User();
user.setUsername("小明");
user.setSex("男");
userMapper.insert(user);
}
// 查询操作
@Test
public void findUser() {
QueryWrapper<User> wrapper = new QueryWrapper<>();
wrapper.eq("uid",557526901044805633L);
User user = userMapper.selectOne(wrapper);
System.out.println(user);
}
}
通过插入测试,可以看到向 user_2 表中插入了数据,且生成的随机数为奇数。

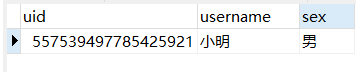
通过查询测试,向 user_2 表查询数据。
2、水平分库
水平分库和水平分表原理相同,同样是根据预先设定好的分片策略进行分库,接下来玩一个稍微比较刺激一点的,同时进行分库分表。
在原来的结构上,我们再加一个字段 status ,然后将数据库 test_db_1 复制一份,命名为 test_db_2 ,结构如图:



接下来肯定就是编写分片策略了,如果 status 为0,那就操作 test_db_1 库,如果为1,那就操作 test_db_2 库,然后,如果 uid 为偶数,则操作 user_1 表,如果为奇数,则操作 user_2 表
# 配置数据源,给数据源起名称
# 水平分库,配置两个数据源
spring.shardingsphere.datasource.names=t1,t2
# 一个实体类对应两张表,覆盖
spring.main.allow-bean-definition-overriding=true
# 配置第一个数据源具体内容,包含连接池,驱动,地址,用户名和密码
spring.shardingsphere.datasource.t1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.t1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.t1.url=jdbc:mysql://localhost:3306/test_db_1?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.t1.username=root
spring.shardingsphere.datasource.t1.password=123456
# 配置第二个数据源具体内容,包含连接池,驱动,地址,用户名和密码
spring.shardingsphere.datasource.t2.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.t2.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.t2.url=jdbc:mysql://localhost:3306/test_db_2?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.t2.username=root
spring.shardingsphere.datasource.t2.password=123456
# 指定数据库分布情况,数据库里面表分布情况
# t1 t2 user_1 user_2
spring.shardingsphere.sharding.tables.user.actual-data-nodes=t$->{1..2}.user_$->{1..2}
# 指定user表里面主键uid 生成策略 SNOWFLAKE
spring.shardingsphere.sharding.tables.user.key-generator.column=uid
spring.shardingsphere.sharding.tables.user.key-generator.type=SNOWFLAKE
# 指定表分片策略 约定uid值偶数添加到user_1表,如果uid是奇数添加到user_2表
spring.shardingsphere.sharding.tables.user.table-strategy.inline.sharding-column=uid
spring.shardingsphere.sharding.tables.user.table-strategy.inline.algorithm-expression=user_$->{uid % 2 + 1}
# 指定数据库分片策略 约定status是0添加到test_db_1库,status是1添加到test_db_2库
spring.shardingsphere.sharding.tables.user.database-strategy.inline..sharding-column=status
spring.shardingsphere.sharding.tables.user.database-strategy.inline.algorithm-expression=t$->{status % 2 + 1}
# 打开sql输出日志
spring.shardingsphere.props.sql.show=true为了玩出点花火,在依赖中加入HuTool工具包,方便我这里更好的演示出效果
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.5.7</version>
</dependency>我这里利用HuTool的两个随机数工具类,来插入一百条数据看效果
/* #################### 水平分库 #################### */
//添加操作
@Test
public void addUserDb() {
for (int i = 0; i < 100; i++) {
User user = new User();
user.setUsername(RandomUtil.randomString("陈刘李周王白", 3));
user.setSex(RandomUtil.randomString("男女", 1));
user.setStatus(RandomUtil.randomInt(0, 2));
userMapper.insert(user);
}
}
//查询操作
@Test
public void findUserDb() {
QueryWrapper<User> wrapper = new QueryWrapper<>();
wrapper.eq("status",1);
wrapper.eq("uid", 557594708629520384L);
User user = userMapper.selectOne(wrapper);
System.out.println(user);
}测试插入,可以发现两个库四个表都插入了数据,而且分片方式都达到了我们预期的期望
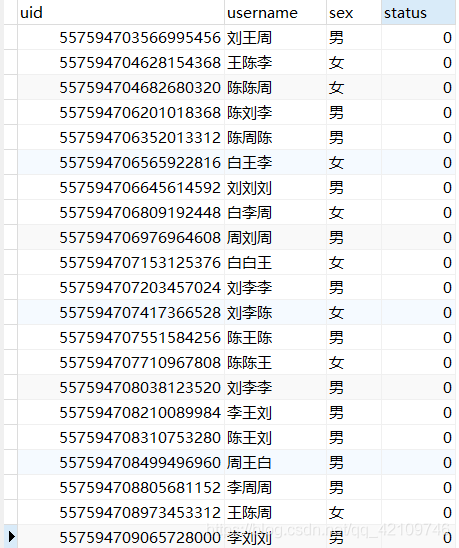
查询测试,可以发现也是按分片的策略进行查询
















 1155
1155











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











