






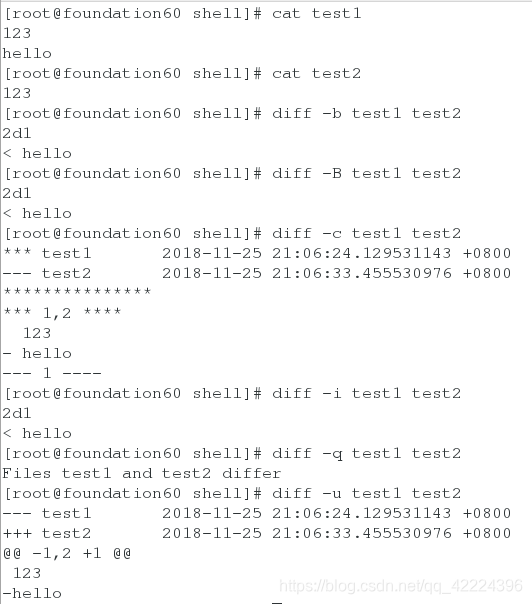
1.diff:
含义:用来比较两个文件的不同
用法:diff test1 test2

上图的结果含义为:删除第一个文件的第二行,内容为hello。
显示结果的含义:
[num1,num2][a|b|c][num3,num4]
num1,num2:表示在第一个文件中的行数,
a:表示添加add
c:表示更改change,
d:表示删除delete
num3,num4:表示第二个文件的行数
< :表示第一个文件的内容
> :表示第二个文件的内容
常用的参数:
-b:不检查空格字符的不同
-B:不检查空白行
-c:显示全部内容,并标出不同
-i:不检查大小写的不同
-p:显示差异所在的函数名称(比较的是c语言的程序码文件)
-q:仅显示有无差异,不显示详细信息
-r:比较子目录中的文件
-u:以合并的方式来显示文件内容的不同
2.patch
含义:用来打补丁
产生补丁文件:
查找patch安装包:

安装查找到的安装包:
-b:指保留源文件

3.cut
含义:多用于字符截取
常用参数:
-d :指定分割符
-f :指定截取的列
-c :指定截取的字符位置

cut -d : -f 1 passwd #以冒号为分割符,截取第一列
cut -d : -f 1,2 passwd #以冒号为分割符,截取第1,2列
cut -d : -f 1-4 passwd #以冒号为分割符,截取第1-4列
cut -c 2,6 passwd #截取第2,6个字符
cut -c 2-6 passwd #截取第2-6的字符

4.sort
常用参数:
-n :纯数字排序number
-r :倒序排序
-u :去掉重复数字
-o :输出到指定文件中 output
-t :指定分隔符
-k :指定要排序的列
sort -n test #纯数字排序
sort -rn test #纯数字倒序排序
sort -rnu test #纯数字倒序去重
sort -rnu test -o test1 #纯数字倒序去重,将结果输出到文件test1中
sort -t : -k 2 test #指定冒号为分隔符,以第二列排序
5.uniq
含义:对重复字符做相应处理
常用参数:
-u :显示唯一的行unique 独一无二
-d :显示重复的行都有哪些
-c :每行显示一次并统计重复次数 count
sort -n test | uniq -c #纯数字排序并且每行显示一次并统计重复次数
sort -n test | uniq -d #纯数字排序显示重复的行
sort -n test | uniq -u #纯数字排序显示唯一的行
6.&&与||
&&:如果正确输出后面内容
||:如果错误输出后面内容
[root@localhost mnt]# ping -c1 -w1 172.25.254.111 &> /dev/null && echo yes || echo no #ping通此网络就输出yes,ping不通就输出no
7.test命令
含义:用来做判断,与[]等同
格式:
test "$a" == "$b" 等同于 [ "$a" == "$b"]
[ "$a" = "$b" ] 等同于 [ "$a" -eq "$b" ] #a等于b
[ "$a" != "$b" ] 等同于 [ "$a" -ne "$b" ] #a不等于b
[ "$a" -le "$b" ] #a小于等于b
[ "$a" -lt "$b" ] #a小于b
[ "$a" -ge "$b" ] #a大于等于b
[ "$a" -gt "$b" ] #a大于b
-a: and的意思,也就是与
-o: or的意思,也就是或
[ -z "$c" ]: 判断c为空值
[ -n "$c" ]:判断c不为空值
[ "file1" -ef "file2" ] #两个文件是否相同
[ "file1" -nt "file2" ] #第一个文件是否比第二个文件新new
[ "file1" -ot "file2" ] #第一个文件是否比第二个文件旧old
例:
[root@localhost mnt]# [ "file" -ot "file1" ] && echo yes || echo no #比较file是否比file1旧,若旧输出yes,若不旧输出no
[root@localhost mnt]# [ "file" -ef "file1" ] && echo yes || echo no #比较file是否和file1相同,若相同输出yes,若不同输出no
[root@localhost mnt]# [ "file" -nt "file1" ] && echo yes || echo no #比较file是否比file1新,若新输出yes,若不新输出no
[root@localhost mnt]# [ "$a" -gt "$b" ] && echo yes || echo no #判断a是否大于b
[root@localhost mnt]# [ "$a" -ge "$b" ] && echo yes || echo no #判断a是否大于等于b
[root@localhost mnt]# [ -z "$c" ] && echo yes || echo no #判断c是否为空,若是空,则输出yes
[root@localhost mnt]# [ -n "$c" ] && echo yes || echo no #判断c是否不为空,若不为空输出yes
test命令对文件的判断:
[ -e "file" ] :判断是否存在 exit
[ -L "file" ] :判断是否为软连接
[ -S "file" ] :判断是否为套接字socket
[ -f "file" ] :判断是否是一个文件file
[ -b "file" ] :判断是否是一个块设备block
[ -d "file" ] :判断是否是一个目录direct
[ -c "file" ] :判断是否是一个字符设备
例:
[root@localhost mnt]# [ -e 'file' ] && echo yes || echo no #判断file是否存在
[root@localhost mnt]# [ -f 'file' ] && echo yes || echo no #判断file是否是文件
[root@localhost mnt]# [ -b '/dev/vdb' ] && echo yes || echo no #判断/dev/vdb是否为块设备
[root@localhost mnt]# [ -d '/mnt/' ] && echo yes || echo no #判断/mnt是否为目录
[root@localhost mnt]# [ -L 'fileq' ] && echo yes || echo no #判断fileq是否为软链接
[root@localhost mnt]# [ -c '/dev/pts/0' ] && echo yes || echo no #判断/dev/pts/0是否为字符设备
[root@localhost mnt]# [ -S '/var/lib/mysql/mysql.sock' ] && echo yes || echo no #判断是否为套接字
8.grep命令
含义:全面搜索研究正则表达式并显示出来,强大的文本搜索工具,根据用户指定的“模式”对目标文本进行匹配检查,打印匹配到的行,由正则表达式或者字符及基本文本字符所编写的过滤条件
格式:grep 匹配条件 处理文件
例:
grep root passwd
grep ^root passwd #以root开头的句子
grep root$ passwd #以root结尾的句子
grep -i root passwd #筛选root不区分大小写
grep -E "^root|root$" passwd #因为有|,所以需要扩展 等同于 egrep "^root|root$" passwd
grep -v ^root passwd #不以root开头的句子
正则表达式:对于特殊字符需要转义\,并且加上双引号
^westos :以westos开头
westos$:以westos结尾
w....s :以w开头,以s结尾,中间间隔四个字符(几个点就是几个字符)
”w.....\>“ 以w开头,后面有五个字符
"\<.....s" 以s结尾,前面有五个字符
* :字符出现0-任意次
?:字符出现0-1次
+:字符出现1-任意次
{n}:字符出现n次
{m,n}:字符最少出现m次,最多出现n次
{0,n} :0-n次
{m,}:至少m次
(xy){n} :xy出现n次
.*:任意字符
例:
[root@localhost mnt]# grep -E "(xy){3,}" file #xy出现最少三次的字符
[root@localhost mnt]# grep -E "(xy){4}" file #xy出现4次的字符
[root@localhost mnt]# grep -E "(xy)?" file #xy出现0-1次的字符
[root@localhost mnt]# grep -E "\<(xy)?\>" file #xy出现0-1次,并且必须用x开头,y结尾
[root@localhost mnt]# grep -E "\<x{1,4}y\>" file #以x开头,以y结尾,中间字符个数大于等于1,小于等于4
[root@localhost mnt]# grep x.*y file #筛选出x和y中间有任意字符的句子
[root@localhost mnt]# grep x*y file #x和y中间x y出现的次数是0-任意次
[root@localhost mnt]# grep -E "x*y\>" file #以y结尾并且x和y中间有0-任意个字符
[root@localhost mnt]# grep -E x*y file #x和y有0-任意个字符
9.sed
含义:行编辑器,
用法:用来操作纯ASCII码的文本,处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”,可以指定仅仅处理哪些行。符合模式条件的处理,不符合条件的不予处理,处理完成之后把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。
命令格式:
sed [options] 'command' file(s)
sed [options] -f scripts file(s)
常用参数:
p:显示
[root@localhost mnt]# sed -n '/^\#/p' fstab 显示以#开头的行
[root@localhost mnt]# sed -n '/^\#/!p' fstab 显示不以#开头的行
[root@localhost mnt]# sed -n '/^UUID/p' fstab 显示以UUID开头的行
[root@localhost mnt]# sed -n '/1$/p' fstab 显示以1结尾的行
[root@localhost mnt]# sed -n '2,6p' fstab 显示2-6行
[root@localhost mnt]# sed -n '2,6!p' fstab 显示除了2-6的几行
[root@localhost mnt]# sed -n '2p;6p' fstab 显示第二行和第六行
[root@localhost mnt]# sed -n '/^$/p' fstab 显示空行
[root@localhost mnt]# sed -n '/^$/!p' fstab 显示除了空行的行
[root@localhost mnt]# sed -n '/^$/!p' fstab | sed -n '/^\#/!p' 不显示空行和#开头的行,只显示剩余的行
d:删除
[root@localhost mnt]# sed '/^#/d' fstab 删除以#开头的行
[root@localhost mnt]# sed '/^#/d;/^$/d' fstab 删除以#开头,含有空格的行
[root@localhost mnt]# sed '1d;4d' fstab 删除1,4行
a:添加
[root@localhost mnt]# sed '/^$/ahello world' fstab 给空格下一行添加hello world
c:替换
[root@localhost mnt]# sed '/\/etc/chello world!!' fstab 将/etc这行替换成hello world!!
w:写入
[root@localhost mnt]# sed '/\/etc/wfile' fstab 将/etc这一行写入到file文件中
i:插入
[root@localhost mnt]# sed '/\/etc/ihello world!!' fstab 给/etc上一行插入hello world!!
=:显示行数
[root@localhost mnt]# sed -n '/\/etc/=' fstab 显示/etc所在行的行数
[root@localhost mnt]# sed '6r /mnt/file' fstab 将file文件添加到fstab的第六行下面
例:
[root@localhost mnt]# sed -n '/^UUID/p;/^UUID/=' fstab 显示uuid这一行,并且显示行号
[root@localhost mnt]# sed -nf file fstab 通过文件执行‘显示uuid这一行并且显示行号’
[root@localhost mnt]# cat file 文件内容为此
/UUID/=
/UUID/p
[root@localhost mnt]# sed '$!G' fstab 每行间隔一个空行显示,最后一行后面没有空行,第一行前面有空
[root@localhost mnt]# sed 'G' fstab 每行前面加一个空行,最后一行后面也添加一个空行
[root@localhost mnt]# sed '=' fstab 给每一行前一行添加一个行号
[root@localhost mnt]# sed -n '$p' fstab 显示最后一行
[root@localhost mnt]# sed 's/sbin/hello/g' passwd 全文的sbin替换成hello
[root@localhost mnt]# sed '3s/sbin/hello/g' passwd 旧第三行的sbin替换成hello
[root@localhost mnt]# sed 's/\// /g' passwd 将所有的/替换成空格
[root@localhost mnt]# sed 's@/@ @g' passwd 将所有/替换成空格
[root@localhost mnt]# sed '/daemon/,/sync/s/sbin/hello/g' passwd 将daemon-sync行所有的sbin替换成hello
[root@localhost mnt]# sed '=' passwd | sed 'N;s/\n//g' 给每一行前面添加行号
10.awk
含义:报告生成器
用法:处理机制,会逐行处理文本,支持在处理第一行之前做些准备工作,以及在处理完最后一行做一些总结性质的工作
命令格式:
BEGIN{}:读入第一行文本之前执行,一般用来初始化操作
{}:逐行处理,逐行读入文本执行相应的处理,是最常见的编辑指令块
END{}:处理完最后一行文本之后执行,一般用来输出处理结果
基本命令:
[root@localhost mnt]# awk '{print FILENAME}' passwd 逐行输出文件名称,有几行输出几遍名称
[root@localhost mnt]# awk '{print NR}' passwd 逐行输出文件行号
[root@localhost mnt]# awk -F : '{print NF}' passwd 以:为分隔符,逐行输出每行的列数
[root@localhost mnt]# awk -F : 'BEGIN{NAME=1}{print NAME}' passwd 逐行输出变量NAME的值
[root@localhost mnt]# awk -F : '{print $1}' passwd 以:分隔,逐行输出,每一行的第一列
[root@localhost mnt]# awk -F : 'BEGIN{print "username:"}{print $1}' passwd 首先输出username:,再逐行输出每一行的第一列,以:分隔
[root@localhost mnt]# awk -F : 'BEGIN{print "username:"}{print $1}END{print "end"}' passwd 首先输出username:,再逐行输出每一行的第一列,以:分隔,最后输出end
[root@localhost mnt]# awk -F : 'BEGIN{print "username:"}/bash$/{print $1}END{print "end"}' passwd 首先输出username:,再逐行输出每一行的第一列,以:分隔,最后输出end,筛选条件是以bash结尾
[root@localhost mnt]# awk 'BEGIN{N=1;print N+2}'
[root@localhost mnt]# ifconfig eth0 | awk '/inet\>/{print $2}' 抓取eth0网卡中的ip
[root@localhost mnt]# awk '/^[a-d]/{print}' passwd 输出以a b c开头的行
[root@localhost mnt]# awk -F : '/^[a-d]/{print $2,$6}' passwd 输出第二六列,输出以a b c开头的行














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









