




 本文介绍了一种用于图像动画的先进一阶运动模型,该模型无需对象注释即可实现高质量的图像动画,通过自监督学习解耦外观与运动信息,适用于人脸、人体等类别对象的动画生成。模型使用自学习关键点和局部仿射变换表示复杂运动,引入遮挡感知生成器优化遮挡处理,扩展关键点检测损失以改善变换估计,显著提升图像动画效果。
本文介绍了一种用于图像动画的先进一阶运动模型,该模型无需对象注释即可实现高质量的图像动画,通过自监督学习解耦外观与运动信息,适用于人脸、人体等类别对象的动画生成。模型使用自学习关键点和局部仿射变换表示复杂运动,引入遮挡感知生成器优化遮挡处理,扩展关键点检测损失以改善变换估计,显著提升图像动画效果。
First Order Motion Model for Image Animation(图像动画的一阶运动模型)阅读笔记
Abstract
图像动画包括生成视频序列,以便根据驱动视频的运动对源图像中的对象进行动画。论文提出的框架解决了这个问题,而不使用任何注释或关于特定对象的先验信息来设置动画。一旦训练了一组描述同一类别对象(如人脸、人体)的视频,就可以应用于此类的任何对象。为了实现这一点,使用一个自监督公式来解耦外观和运动信息。为了支持复杂的运动,使用由一组学习的关键点及其局部仿射变换组成的表示。生成网络对目标运动过程中产生的遮挡进行建模,并将从源图像中提取的外观和从驱动视频中提取的运动相结合。
Improvement
- 针对Monkey-Net在假设零阶模型的情况下,对关键点邻域中的对象外观转换建模不佳,导致在大对象姿态变化的情况下生成质量差的问题,使用了一组自学习的关键点和局部仿射变换来模拟复杂的运动,称为一阶运动模型。
- 使用了一个遮挡感知生成器,它采用一个自动估计的遮挡掩模来表示源图像中不可见的、应该从上下文中推断出来的对象部分,当驾驶视频包含大的运动模式和典型的遮挡时,这一点尤其需要。
- 扩展了关键点检测器训练中常用的等方差损失,以改进局部仿射变换的估计。
- 论文方法明显优于最先进的图像动画方法,并且可以处理其他方法通常失败的高分辨率数据集。
- 发布了一个新的高分辨率数据集Thai-Chi-HD,可以成为评估图像动画和视频生成框架的参考基准。
Method
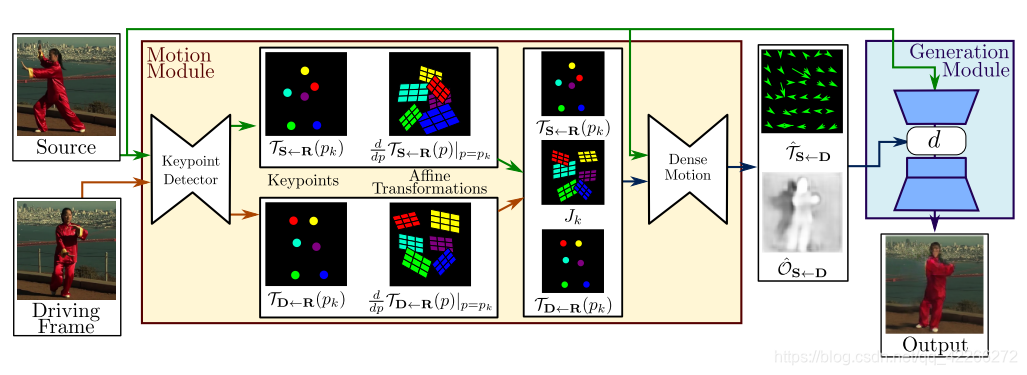
这篇文章完成的任务是Image Animation,给定一张源图片,给定一个驱动视频,生成一段视频,其中主角是源图片,动作是驱动视频中的动作。方法的概述如图所示,使用一个包含相同对象类别的对象的大量视频序列集合来训练模型。通过合并一个单一的帧和一个学习到的运动在视频中的潜在表现来训练模型,通过观察从同一视频中提取的帧对,它学习将运动编码为特定于运动的关键点位移和局部仿射变换的组合。在测试时,将模型应用于由源图像和驱动视频的每一帧组成的对,并对源对象执行图像动画。
该框架由两个主要模块组成:运动估计模块和图像生成模块。
运动估计模块的目的是预测从驱动视频 D D D的维数为 H × W H \times W H×W的 D ∈ R 3 × H × W D \in R^{3 \times H \times W} D∈R3×H×W到源帧 S ∈ R 3 × H × W S \in R^{3 \times H \times W} S∈R3×H×W的密集运动场,然后利用稠密运动场将 S S S计算的特征映射与 D D D中的目标姿态对齐,运动场由函数 T S ← D : R 2 → R 2 T_{S \gets D}:R^2 \to R^2 TS←D:R2→R2将每个像素在 D D D中的位置映射到 S S S。 T S ← D T_{S \gets D} TS←D通常被称为反向光流。我们使用反向光流,而不是前向光流,因为使用双线性采样可以以可微的方式有效地实现后向翘曲。假设存在一个抽象参考系 R R R,我们独立地估计了从 R R R到 S S S ( T S ← R T_{S \gets R} TS←R)和从 R R R到 D D D( T D ← R T_{D \gets R} TD←R)的两个变换。这个选择允许我们独立地处理 D D D和 S S S。这是理想的,因为在测试时,模型接收到从不同视频采样的成对的源图像和驱动帧,它们在视觉上可能有很大的不同。运动估计器模块不是直接预测 T D ← R T_{D \gets R} TD←R和 T S ← R T_{S \gets R} TS←R,而是分两步进行。
在第一步中,从稀疏轨迹集合中近似两个变换,这些轨迹集是通过使用自监督方式学习的关键点获得的。通过编解码网络分别预测D和S中关键点的位置。关键点表示作为一个瓶颈,导致紧凑的运动表示。这种稀疏运动表示非常适合于动画,因为在测试时,可以使用驱动视频中的关键点轨迹来移动源图像的关键点。使用局部仿射变换在每个关键点附近建立运动模型。与仅使用关键点位移相比,局部仿射变换允许我们对更大的变换族进行建模。我们使用泰勒展开来表示 T D ← R T_{D \gets R} TD←R,通过一组关键点位置和仿射变换。为此,关键点检测器网络输出关键点位置以及每个仿射变换的参数。
在第二步中,密集运动网络结合局部近似来获得密集运动场 T ^ S ← D \hat{T}_{S \gets D} T^S←D。此外,除了密集运动场之外,该网络还输出遮挡掩模 O ^ S ← D \hat{O}_{S \gets D} O^S←D,表示 D D D的哪些图像部分可以通过源图像的扭曲来重建,哪些部分应该被修复,即根据上下文推断。
最后,生成模块呈现驱动视频中提供的源对象运动的图像。在这里,我们使用一个生成网络 G G G,它根据 T ^ S ← D \hat{T}_{S \gets D} T^S←D对源图像进行扭曲,并修复被遮挡在源图像中的图像部分。
因为训练过程是一个图像重建的过程,所以引入了重建损失,具体形式为感知损失,将两幅图片分别过VGG19,取其中5层的特征值分别做差,平均然后求和。此外,感知损失采用了金字塔模式,即在4个不同的尺度上进行计算(256、128、64、32)。
Summary
这篇文章实现了姿态迁移,舍弃了在数据预处理阶段检测关键点,而是融合到网络中,自监督对关键点进行预测;而且训练好的模型不是object specific的,扩充了应用场景.



















 1134
1134

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











