






任务1---线性回归算法梳理
机器学习的一些概念
机器学习致力于研究如何通过计算的手段,利用经验来改善系统自身的性能在计算机系统中,“经验"通常以"数据"形式存在,因此,机器学习所研究的主要内容,是关于在计算机上从数据中产生"模型” (model) 的算法,即"学习算法" (learning algorithm). 有了学习算法,我们把经验数据提供给它,它就能基于这些数据产生模型;在面对新的情况时,模型会给我们提供相应的判断(例如好瓜) .如果说计算机科学是研究关于"算法"的学问,那么类似的,可以说机器学习是研究关于"学习算法"的学问。
有监督学习
监督学习这个想法是指,我们将教计算机如何去完成任务,而在无监督学习中,我们打算让它自己进行学习。
分类和回归是监督学习的代表。
监督学习指的就是我们给学习算法一个数据集。这个数据集由“正确答案”组成。比如房价问题,我们给了一系列房子的数据,我们给定数据集中每个样本的正确价格,即它们实际的售价,然后运用学习算法,算出更多的正确答案。以此预估出售新房子的价格,用术语来讲,就叫做回归问题。我们试着推测出一个连续值的结果,即房子的价格。
回归这个词的意思是,我们在试着推测出这一系列连续值属性。根据一个限度,给它赋值为0或1.这就变成了房价是低或高的二分类问题。
无监督学习
聚类是无监督学习的代表。
对于监督学习里的每条数据,我们已经清楚地知道,训练集对应的正确答案。在无监督学习中,我们已知的数据。看上去有点不一样,不同于监督学习的数据的样子,即无监督学习中没有任何的标签或者是有相同的标签或者就是没标签。所以我们已知数据集,却不知如何处理,也未告知每个数据点是什么。别的都不知道,就是一个数据集。你能从数据中找到某种结构吗?针对数据集,无监督学习就能判断出数据有两个不同的聚集簇。这是一个,那是另一个,二者不同。是的,无监督学习算法可能会把这些数据分成两个不同的簇。所以叫做聚类算法。
泛化能力
机器学习的目标是使学得的模型能很好地适用于"新样本",而不是仅仅在训练样本上工作得很好;即便对聚类这样的无监督学习任务,我们也希望学得的簇划分能适用于没在训练集中出现的样本.学得模型适用于新样本的能力,称为"泛化" (generalization)能力.具有强泛化能力的模型能很好地适用于整个样本空间。
过拟合欠拟合(方差和偏差以及各自解决办法)
1、过拟合
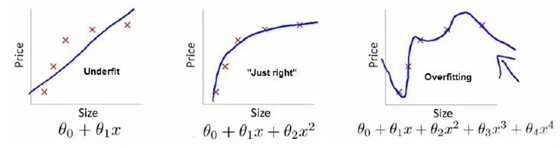
第一个模型是一个线性模型,欠拟合,不能很好地适应我们的训练集;第三个模型是一个四次方的模型,过于强调拟合原始数据,而丢失了算法的本质:预测新数据。我们可以看出,若给出一个新的值使之预测,它将表现的很差,是过拟合,虽然能非常好地适应我们的训练集但在新输入变量进行预测时可能会效果不好;而中间的模型似乎最合适。
处理方法
(1)丢弃一些不能帮助我们正确预测的特征。可以是手工选择保留哪些特征,或者使用一些模型选择的算法来帮忙(例如PCA)
(2)正则化。 保留所有的特征,但是减少参数的大小(magnitude)。
2.欠拟合
当学习器把训练样本学得"太好"了的时候,很可能巳经把训练样本自身的一些特点当作了所有潜在样本都会具有的一般性质,这样就会导致泛化性能下降这种现象在机器学习中称为"过拟合" (overfitting). 与"过拟合"相对的是"欠拟合" (underfitting) ,这是指对训练样本的一般性质尚未学好.有多种因素可能导致过拟合,其中最常见的情况是由于学习能力过于强大,以至于把训练样本所包含的不太一般的特性都学到了,而欠拟合则通常是由
于学习能力低下而造成的欠拟合比较容易克服,例如在决策树学习中扩展分支、在神经网络学习中增加训练轮数等。
偏差 (2.40)度量了学习算法的期望预测与真实结果的偏离程度,即刻画了学习算法本身的拟合能力;方差 (2.38)度量了同样大小的训练集的变动所导致的学习性能的变化,即刻画了数据扰动所造成的影响。
以回归任务为例,学习算法的期望预测为
交叉验证
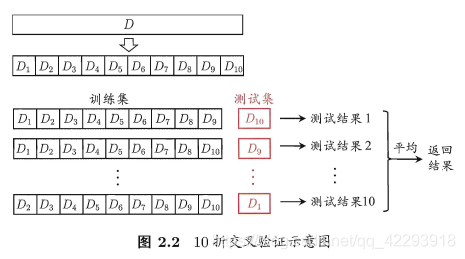
“交叉验证法” (cross validation)先将数据集 D 划分为 k 个大小相似的
互斥子集, 即 D = D1 ∪ D2 ∪… ∪ Dk , Di ∩ Dj = ∅ (i ≠ j ) . 每个子集 Di 都
尽可 能保持数据分布的一致性,即从 D 中 通过分层采样得到. 然后,每次用
k-1 个子集的并集作为训练集,余下的那个子集作为测试集;这样就可获得 k
组训练/测试集,从而可进行 k 次训练和测试, 最终返回的是这 k 个测试结果
的均值。显然,交叉验证法评估结果的稳定性和保真性在很大程度上取决于 k
的取值,为强调这一点,通常把交叉验证法称为 " k 折交叉验证" (k-fold cross
validat ion). k 最常用 的取值是 10,此时称为 1 0 折交叉验 证 ; 其他常用 的 k 值
有 5、 20 等.
线性回归的原理
线性回归(Linear Regression)是一种通过属性的线性组合来进行预测的线性模型,其目的是找到一条直线或者一个平面或者更高维的超平面,使得预测值与真实值之间的误差最小化。

线性回归损失函数、代价函数、目标函数
损失函数(Loss Function )是定义在单个样本上的,算的是一个样本的误差。
代价函数(Cost Function )是定义在整个训练集上的,是所有样本误差的平均,也就是损失函数的平均。
目标函数(Object Function)定义为:最终需要优化的函数。等于经验风险+结构风险(也就是Cost Function + 正则化项)。
优化方法(梯度下降法、牛顿法、拟牛顿法等)
1. 梯度下降法
当∥∥取做欧几里得范数时,可见v就是沿着负梯度方向,所以该方法称作梯度下降法。在采用精确直线搜索方法的情况下,梯度下降发每一步搜索的方向都是沿着当前位置的负梯度方向∇f(xk),而搜索步长的选择都使得在该方向上目标函数达到最小值,即沿着搜索方向上的方向导数为0,有∇f(xk+1)Tvk=0。所以下一步的搜索方向vk+1=∇f(xk+1)与当前搜索方向vk垂直。在二维情况下,采用精确直线搜索的梯度下降法的搜索路径会呈现出台阶形状,参考[2]的图9.2和[3]的图3.7。当采取非精确直线搜索时,连续两次搜索方向不一定垂直,但还是会呈现出锯齿状。出现这种锯齿状路径的原因是每次搜索方向不能保证互相“独立”,沿着vk+1方向上的极小值不一定是(基本上都不会是)沿着vk方向上的极小值,所以下一次搜索时又要重复进行计算。
梯度下降法因为只用到了目标函数的一阶导数,涉及到的计算较为简单,而且梯度下降方法选择的搜索方向可以保证是收敛的。其缺点就是收敛速度非常的慢,尤其是目标函数下水平集的条件数很大的时候。
2. 牛顿法
从收敛性分析可知,最速下降法的收敛速度与待优化函数f(x)在极值点的黑塞矩阵H条件数有很大关系,H越接近单位矩阵I,收敛性越好。牛顿法相比梯度下降法,采用2−H范数来替代梯度下降法中的欧几里得范数。这相当于对原始变量x做了个线性变换x¯=H12x。在此变换下,可以发现黑塞矩阵H¯=H−1H=I,因此可以期望牛顿法具有更好的收敛性(当距离极值点较近的时候,牛顿法具有二次收敛速度)。
牛顿法的另一个解释是在极小值附近用二次曲面来近似目标函数f(x),然后求二次曲面的极小值作为步径。为了看出这一点,考虑f(x)的二阶泰勒展开:
f(x+v)≈f(x)+∇f(x)Tv+12vT∇2f(x)v
上式是关于v的二次函数,易知其极小值为v=−[∇2f(x)]−1∇f(x),刚好是牛顿法的步径。相比之下,梯度下降法则是用平面来近似(参见最速下降法的推导)。
牛顿法相比梯度下降法的优点有:
在极值点附近具有二次收敛性。一旦进入二次收敛阶段,最多再经过6次的迭代便可以得到很高精度的解。
具有仿射不变性,对坐标选择或者目标函数下水平集不敏感(牛顿法本身相当于做了一次线性变换以保证目标函数下水平集近似为I)。
和问题规模有很好的比例关系,求解R1000中问题的性能和R10中问题的性能类似。
性能不依赖于参数的选择。
牛顿法的缺点是需要计算黑塞矩阵和其逆矩阵,这使得存储和计算的开销相比梯度下降法要大很多。为了解决这个问题,人们提出了所谓的拟牛顿法。
另外,牛顿法还有个问题就是在远离极值点的时候,目标函数的黑塞矩阵可能并不是正定的,所以牛顿法给出的搜索方向并不能保证是下降方向。为了解决这个问题,可以对黑塞矩阵做一些更改,比如加上一个矩阵E使其变得正定。
3. 拟牛顿法
拟牛顿法与牛顿法类似,只是用一个SPD矩阵代替精确的黑塞矩阵。
线性回归的评估指标
1、SSE(误差平方和)
计算公式如下: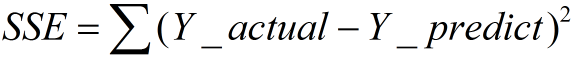
同样的数据集的情况下,SSE越小,误差越小,模型效果越好
缺点:
SSE数值大小本身没有意义,随着样本增加,SSE必然增加,也就是说,不同的数据集的情况下,SSE比较没有意义
2、R-square(决定系数)
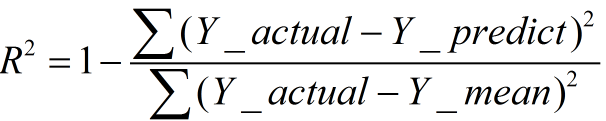
数学理解: 分母理解为原始数据的离散程度,分子为预测数据和原始数据的误差,二者相除可以消除原始数据离散程度的影响
其实“决定系数”是通过数据的变化来表征一个拟合的好坏。
理论上取值范围(-∞,1], 正常取值范围为[0 1] ------实际操作中通常会选择拟合较好的曲线计算R²,因此很少出现-∞
越接近1,表明方程的变量对y的解释能力越强,这个模型对数据拟合的也较好
越接近0,表明模型拟合的越差
经验值:>0.4, 拟合效果好
缺点:
数据集的样本越大,R²越大,因此,不同数据集的模型结果比较会有一定的误差
3、Adjusted R-Square (校正决定系数)
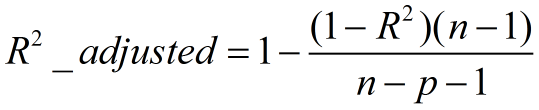
n为样本数量,p为特征数量
消除了样本数量和特征数量的影响
sklearn参数详解
KNN
KNneighborsClassifier参数说明:
n_neighbors:默认为5,就是k-NN的k的值,选取最近的k个点。
weights:默认是uniform,参数可以是uniform、distance,也可以是用户自己定义的函数。uniform是均等的权重,就说所有的邻近点的权重都是相等的。distance是不均等的权重,距离近的点比距离远的点的影响大。用户自定义的函数,接收距离的数组,返回一组维数相同的权重。
algorithm:快速k近邻搜索算法,默认参数为auto,可以理解为算法自己决定合适的搜索算法。除此之外,用户也可以自己指定搜索算法ball_tree、kd_tree、brute方法进行搜索,brute是蛮力搜索,也就是线性扫描,当训练集很大时,计算非常耗时。kd_tree,构造kd树存储数据以便对其进行快速检索的树形数据结构,kd树也就是数据结构中的二叉树。以中值切分构造的树,每个结点是一个超矩形,在维数小于20时效率高。ball tree是为了克服kd树高纬失效而发明的,其构造过程是以质心C和半径r分割样本空间,每个节点是一个超球体。
leaf_size:默认是30,这个是构造的kd树和ball树的大小。这个值的设置会影响树构建的速度和搜索速度,同样也影响着存储树所需的内存大小。需要根据问题的性质选择最优的大小。
metric:用于距离度量,默认度量是minkowski,也就是p=2的欧氏距离(欧几里德度量)。
p:距离度量公式。在上小结,我们使用欧氏距离公式进行距离度量。除此之外,还有其他的度量方法,例如曼哈顿距离。这个参数默认为2,也就是默认使用欧式距离公式进行距离度量。也可以设置为1,使用曼哈顿距离公式进行距离度量。
metric_params:距离公式的其他关键参数,这个可以不管,使用默认的None即可。
n_jobs:并行处理设置。默认为1,临近点搜索并行工作数。如果为-1,那么CPU的所有cores都用于并行工作。
KMeans
参数的意义:
n_clusters:簇的个数,即你想聚成几类
init: 初始簇中心的获取方法
n_init: 获取初始簇中心的更迭次数,为了弥补初始质心的影响,算法默认会初始10次质心,实现算法,然后返回最好的结果。
max_iter: 最大迭代次数(因为kmeans算法的实现需要迭代)
tol: 容忍度,即kmeans运行准则收敛的条件
precompute_distances:是否需要提前计算距离,这个参数会在空间和时间之间做权衡,如果是True 会把整个距离矩阵都放到内存中,auto 会默认在数据样本大于featurs*samples 的数量大于12e6 的时候False,False 时核心实现的方法是利用Cpython 来实现的
verbose: 冗长模式(不太懂是啥意思,反正一般不去改默认值)
random_state: 随机生成簇中心的状态条件。
copy_x: 对是否修改数据的一个标记,如果True,即复制了就不会修改数据。bool 在scikit-learn 很多接口中都会有这个参数的,就是是否对输入数据继续copy 操作,以便不修改用户的输入数据。这个要理解Python 的内存机制才会比较清楚。
n_jobs: 并行设置
algorithm: kmeans的实现算法,有:’auto’, ‘full’, ‘elkan’, 其中 ‘full’表示用EM方式实现
参考:https://blog.csdn.net/yyy430/article/details/80535845
西瓜书
cs229吴恩达机器学习课程
李航统计学习
谷歌搜索
公式推导参考:http://t.cn/EJ4F9Q0














 708
708











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









