






本篇写于2024年7月,请注意甄别
环境准备
LMDeploy 提供了快速安装、模型量化、离线批处理、在线推理服务等功能。每个功能只需简单的几行代码或者命令就可以完成。
环境安装:
### 启动环境
source /mnt/lustre/share/platform/env/lmdeploy
### 新建 conda 环境
conda create -n lmdeploy python=3.8 # 大于3.8即可
# CUDA12
pip install lmdeploy
pip install timm
# 手动下载 flash_attn.whl 并安装 : https://github.com/Dao-AILab/flash-attention/releases/
# CUDA 11+
# 浏览器下载 https://github.com/InternLM/lmdeploy/releases/download/v0.5.0/lmdeploy-0.5.0+cu118-cp38-cp38-manylinux2014_x86_64.whl
pip install lmdeploy-0.5.0+cu118-cp38-cp38-manylinux2014_x86_64.whl
# 除上述包之外,可能需要手动下载 torch2.2.2-cu118-cp38、torchvision-0.17.2-cu118-cp38
# 下载地址:https://download.pytorch.org/whl/cu118
## 联网情况下
# export LMDEPLOY_VERSION=0.5.0
# export PYTHON_VERSION=38
# pip install https://github.com/InternLM/lmdeploy/releases/download/v${LMDEPLOY_VERSION}/lmdeploy-${LMDEPLOY_VERSION}+cu118-cp${PYTHON_VERSION}-cp${PYTHON_VERSION}-manylinux2014_x86_64.whl --extra-index-url https://download.pytorch.org/whl/cu118推理引擎:可选Turbomind和Pytorch【支持的模型链接】
【注意】:
1. pipeline 默认申请一定比例显存,用来存储推理过程中产生的 k/v。v0.2.0 默认比例为 0.5,表示 GPU****总显存的 50% 被分配给 k/v cache,lmdeploy > v0.2.1分配策略改为从空闲显存中按比例为 k/v cache 开辟空间。默认比例值调整为 0.8
2. 比例由参数TurbomindEngineConfig.cache_max_entry_count 控制,OOM或缓解显存占用问题可以修改这个参数,V100的机器无法使用 FlashAttention (only supports Ampere GPUs or newer), 通过修改模型根目录下的 config.json 文件来规避这个问题
use_flash_attn: false
attn_implementation:eager
离线推理
from lmdeploy import pipeline
from lmdeploy.messages import TurbomindEngineConfig
from lmdeploy.vl import load_image
model = '/path/to/InternVL-Chat-V1-5'
image = load_image('/path/to/infering_image.jpeg')
backend_config = TurbomindEngineConfig(tp=4) # 量化模型加 model_format='awq'
pipe = pipeline(model, backend_config=backend_config, log_level='INFO')
response = pipe((prompt, image))
print(response)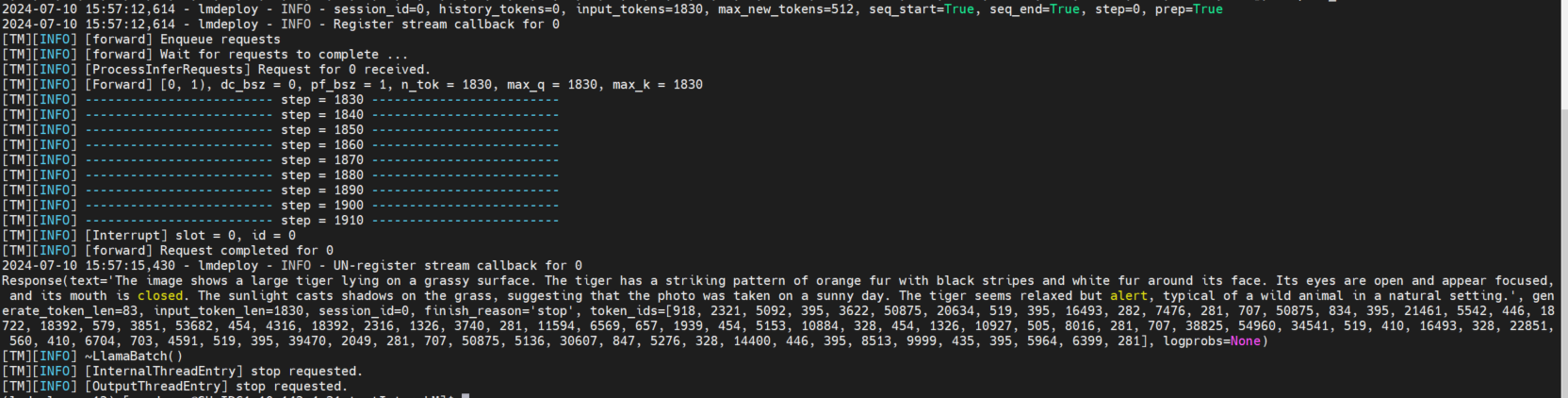
API-Server
服务端口
srun -p pat_dev --gres=gpu:4 -w target_ip lmdeploy serve api_server /path/to/InternVL-Chat-V1-5/ --server-port 23333 --tp 4
# 量化模型要加 --model-format awq
# 如果现存占用过大 --cache-max-entry-count 0.5 # 默认是 0.8
Infer脚本
from lmdeploy.serve.openai.api_client import APIClient
api_client = APIClient(f'http://{target_ip}:23333')
model_name = api_client.available_models[0]
messages = [
{'role':'user',
'content': [
{
'type': 'text',
'text': 'Describe the image please',
},{
'type': 'image_url',
'image_url': {
'url':'/path/to/infering_image.jpeg',
},
}]
}]
res = api_client.chat_completions_v1(model=model_name,messages=messages):
for item in res:
for k,v in item.items():
print(k, v)
print("---")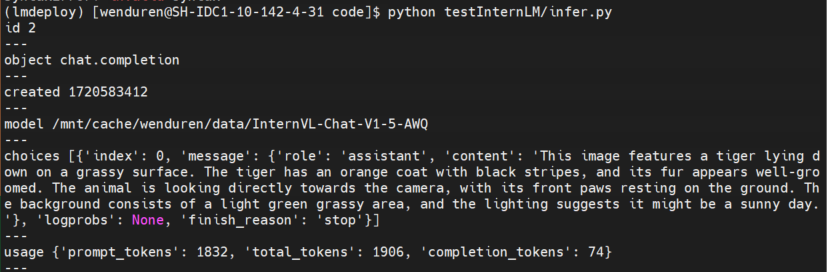
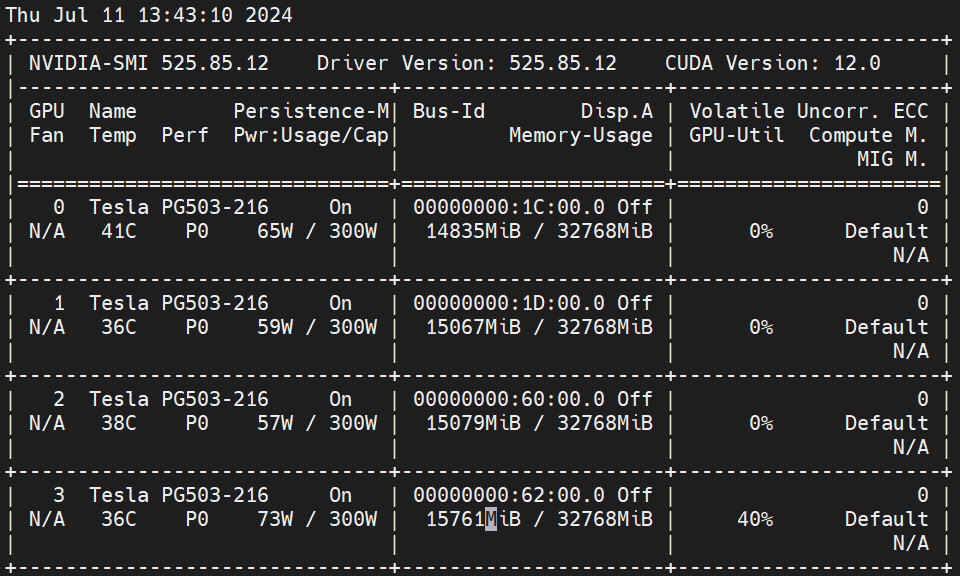
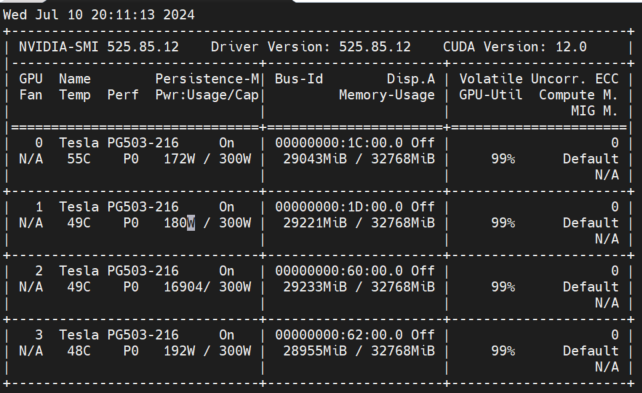
推理速度
环境:V100 * 4,CUDA 12,lmdeploy 0.5.0
数据:
图像:coco2014测试集(5k)
图像平均分辨率486*575,最大640*640,最小144*176
文本 prompt 统一为“describe this image”
显存占用,cache_max_entry_count=0.5 的情况下,左侧为仅加载模型,右侧为推理状态
batch推理脚本
from lmdeploy import pipeline
from lmdeploy.messages import TurbomindEngineConfig
from lmdeploy.vl import load_image
import os, time, json
def batchInfer(batch_size):
idx = 0
res_lists = {}
while idx < 100-batch_size:
prompt = 'describe this image'
images = []
image_names = []
for i in range(batch_size):
image = load_image(os.path.join(image_path, imnames[idx]))
images.append(image)
image_names.append(imnames[idx])
idx += 1
batch = [(prompt, images[i]) for i in range(batch_size)]
start_time = time.time()
response = pipe.batch_infer(batch)
end_time = time.time()
stage_time = end_time - start_time
for idx, res in enumerate(response):
res_lists[image_names[idx]] = {'modelout': res.text, 'time': stage_time/batch_size}
return res_lists
if __name__ == '__main__':
model = '/mnt/cache/wenduren/data/InternVL-Chat-V1-5'
image_path = "/mnt/cache/wenduren/data/images_coco_2014_5k_test"
backend_config = TurbomindEngineConfig(tp=4, cache_max_entry_count=0.5)
pipe = pipeline(model, backend_config=backend_config)#, log_level='INFO')
imnames = os.listdir(image_path)
test_batch_size = [1, 4, 8, 16, 32]
for batch_size in test_batch_size:
res_lists = batchInfer(batch_size)
with open(f"result/bs{batch_size}/result.txt", "w") as f:
json.dump(res_lists,f,indent=4)
print(f'Infererence on Batch Size = {batch_size} Done.')可能遇到的问题
- 输入文本prompt没有问题,输入图片就报错
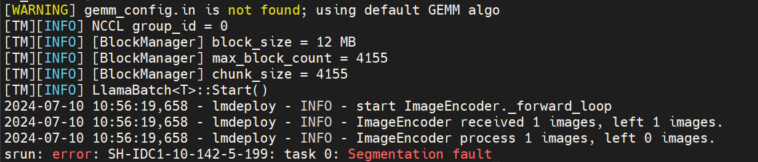
解决方法;
echo $LD_LiBRARY_PATH # 检查是否为空,否则
unset LD_LiBRARY_PATH # 加到 ~/.bashrc
















 1560
1560

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









