




 本文详细介绍使用Scrapy框架进行图片爬取的过程,包括项目创建、爬虫文件编写及设置配置等关键步骤,适合初学者快速上手。
本文详细介绍使用Scrapy框架进行图片爬取的过程,包括项目创建、爬虫文件编写及设置配置等关键步骤,适合初学者快速上手。
Scrapy爬取图片。
创建项目:scrapy startproject 项目名(CrawlPic)
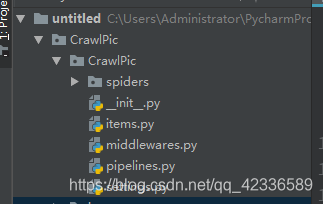
然后在二级CrawlPic目录的spiders目录下创建爬虫文件。PicSpider.py(当然也可以cd到你的项目文件夹下,使用scray genspider ‘文件名’ win4000.com 创建爬虫文件。它会自动创建到spider文件夹下,当然也可以进入spider文件夹下创建。效果一样。这是scrapy提供的一个模板。)
然后在一级CrawlPic目录下创建main.py,用于运行scrapy项目
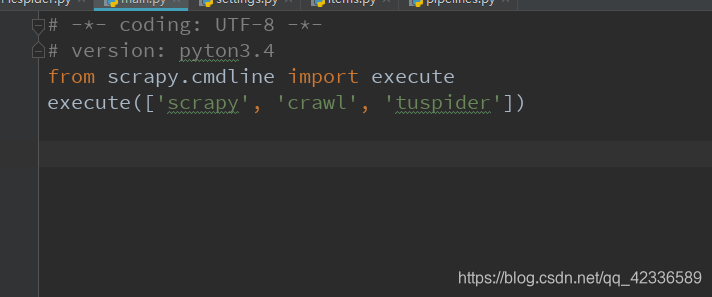
其中的内容如下。
然后编写爬虫文件。
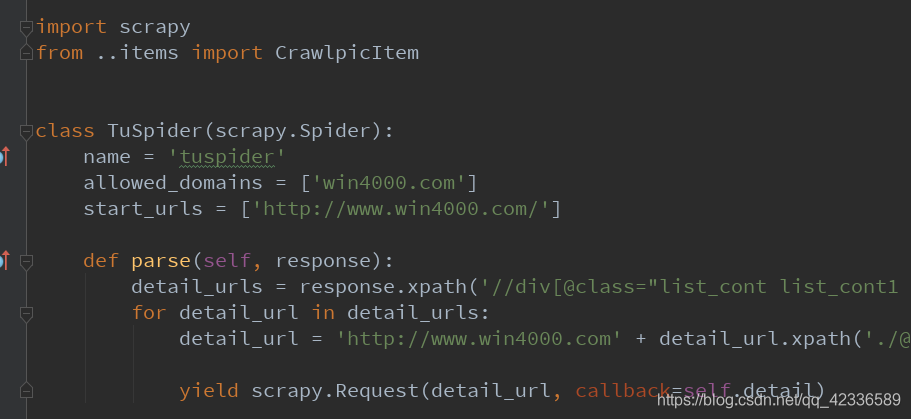
这里需要注意的点是。
- 爬虫文件里面有三个定义量。Name = ‘’, allowed_domains = [‘’]
Start_urls = [‘’]
- 第一个函数需要定义成parse。因为每次callback它都会重新寻找parse函数,你不定义成parse它不知道去哪找。会报一个parse错误。
- 然后需要注意的是for循环里面不能直接取到实际的detail_urls的href属性.因为取不出来,它只是一个生成器对象,它需要在for循环里面取。当然,如果你只要一个网址,你可以直接找到它的href属性,只需要在它后面加上.extract_first(‘’)就行了。
- 用yield返回,return会跳出循环。当然,For里面你也写不了return。会报错
然后来看setting配置:
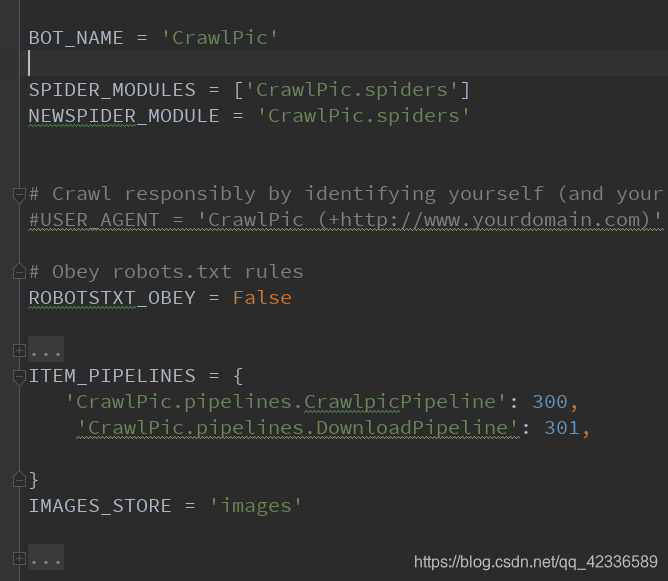
就这么多。前三个不用改,系统已经默认好了。用处从名字就可以看出来。
然后机器行为改为false,避免一些不必要的错误。
Images_store文件存储位置。
Items.py文件就没什么说的了。
Pipelines.py 文件:
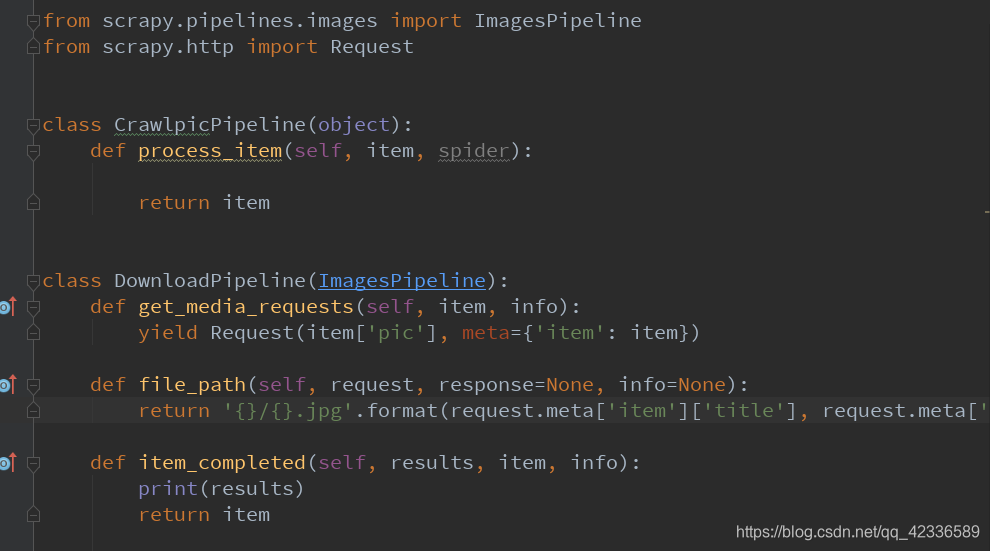
第一个函数是默认的,不用管。存图片用不到这个功能
第二个函数是自定义的
这三个def都是系统内部写好的。只不过内部只是莫版没有内容。
第一个def, 用来发起请求,请求数据
第二个def,存储文件
第三个def 是请求结果,这里print了一下results,可以在代码运行的时候看一下是否成功。
Middware中间件。没用到。里面是一些中间件配置
一个简单的爬取图片的代码。之后慢慢拓展。

















 1088
1088

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









