







RNN / LSTM
RNN
Why RNN?
他们都只能单独的取处理一个个的输入,前一个输入和后一个输入是完全没有关系的。但是,某些任务需要能够更好的处理序列的信息,即前面的输入和后面的输入是有关系的。
比如,当我们在理解一句话意思时,孤立的理解这句话的每个词是不够的,我们需要处理这些词连接起来的整个序列; 当我们处理视频的时候,我们也不能只单独的去分析每一帧,而要分析这些帧连接起来的整个序列。
RNN结构
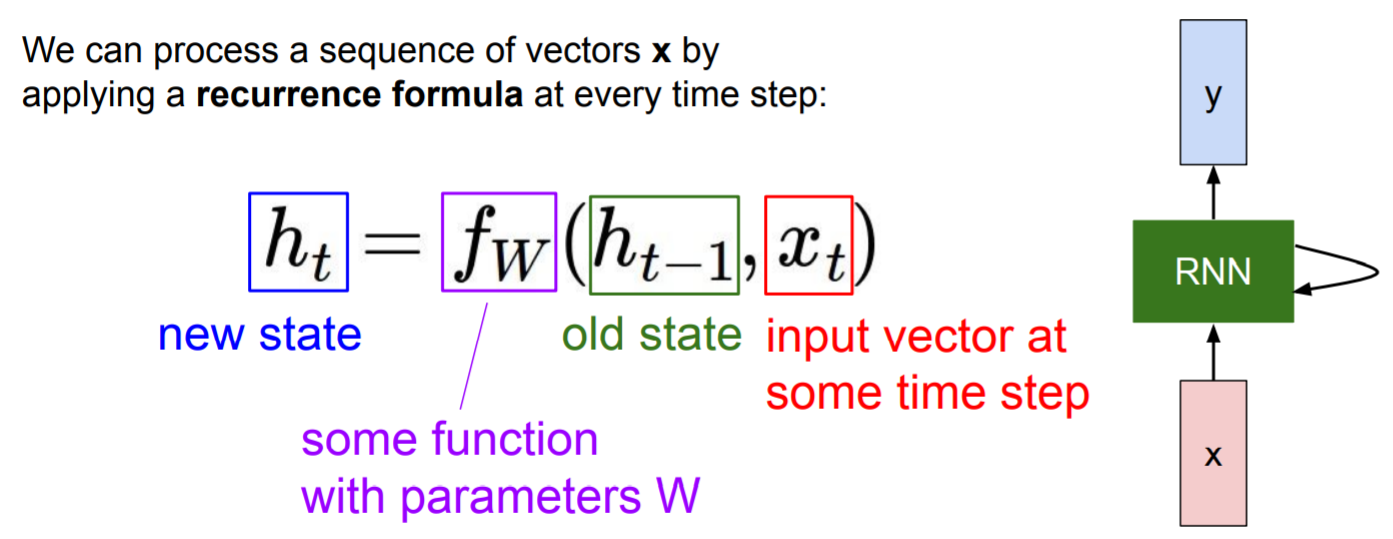

函数
f
f
f依赖权重
W
W
W,
f
f
f接受隐藏态
h
t
−
1
h_{t-1}
ht−1,当前态
x
t
x_{t}
xt,输出下一个隐藏态
h
t
h_{t}
ht。
当我们读取下一个输入时,此时的隐藏态
h
t
h_{t}
ht作为新的输入,同时读取输入
x
t
+
1
x_{t+1}
xt+1。
注:每次计算都使用同样的函数和参数。
最原始的RNN版本(Vanilla RNN):
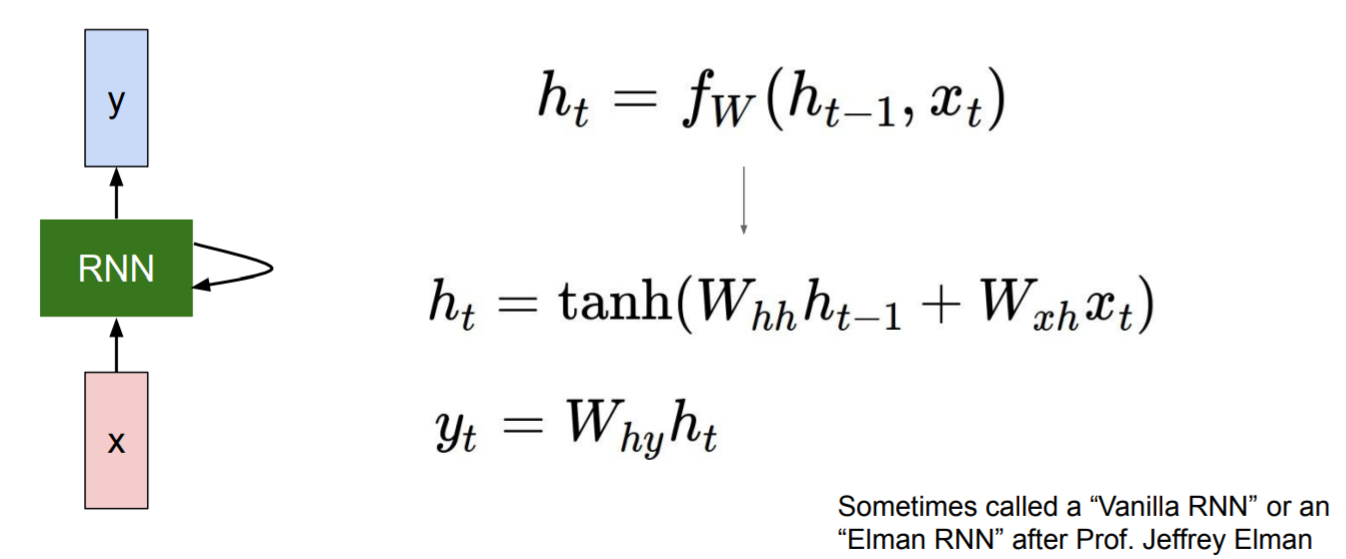
RNN结构有多种变体,针对不同的应用: 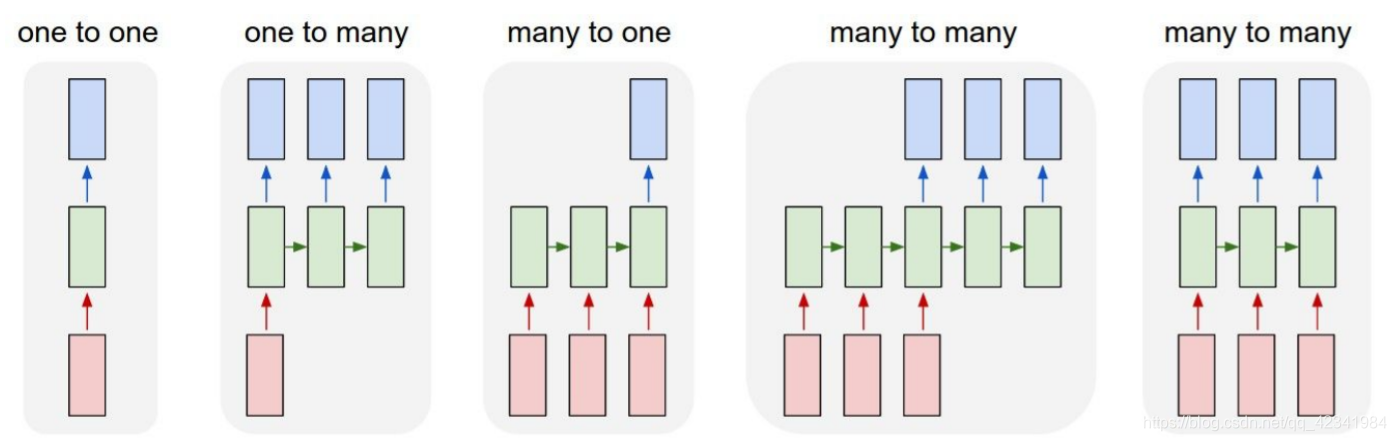
one2many:
- 图像描述:输入为一张图片,输出是对这张图片的描述信息。
many2one:
- 情感分类:输入为一段文本或者一段评论数据,输出相应的打分数据,来判别这段话的情感。
many2many:
- 机器翻译:输入为源语言中的一个序列数据(比如:英语),输出是目标语言序列数据(比如:汉语),比如谷歌翻译、有道翻译等。
- 文本摘要:输入为一段文本序列,输出是这段文本序列的摘要序列。
- 语音识别:输入为语音新号序列数据,输出为文本序列,比如 ASR 功能。
- 阅读理解:输入为一段文章和问题,对其分别编码,在对其进行解码,输出得到问题的答案。
seq2seq(many2one + one2many)
seq2seq属于encoder-decoder结构的一种,基本思想就是利用两个RNN,一个RNN作为encoder,另一个RNN作为decoder。
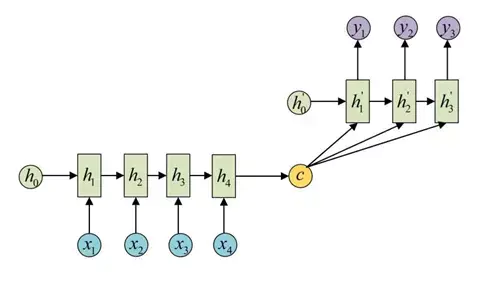
encoder负责将输入序列压缩成指定长度的向量,这个向量就可以看成是这个序列的语义,这个过程称为编码,如下图左侧,获取语义向量最简单的方式就是直接将最后一个输入的隐状态作为语义向量C。也可以对最后一个隐含状态做一个变换得到语义向量,还可以将输入序列的所有隐含状态做一个变换得到语义变量。
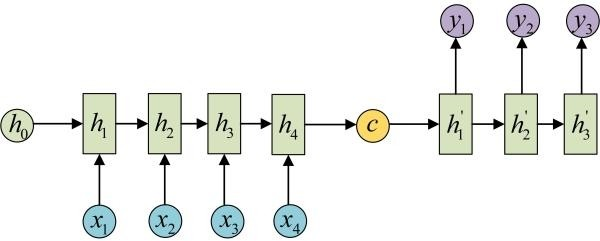
而decoder则负责根据语义向量生成指定的序列,这个过程也称为解码,如上图右侧,最简单的方式是将encoder得到的语义变量作为初始状态输入到decoder的RNN中,得到输出序列。可以看到上一时刻的输出会作为当前时刻的输入,而且其中语义向量C只作为初始状态参与运算,后面的运算都与语义向量C无关。
decoder处理方式还有另外一种,就是语义向量C参与了序列所有时刻的运算,如下图,上一时刻的输出仍然作为当前时刻的输入,但语义向量C会参与所有时刻的运算。
语言模型(character-level)
Example
我们训练一个“hello”的序列:

其中,targets chars是我们希望出现的字母,即正确预测的字母,可以发现第一列预测(output layer)到的为o(4.1分),与我们的期望(e)不一致。
测试阶段:

如上图,经过第一个time step得到的所有可能的输出是经过softmax层后得到的概率,sample做的是:根据这个softmax的分布,进行随机采样,即利用np.random.choice根据概率的分布进行采样。采样结果作为下一个time step的输入。
Sample:
这里根据概率分布随机采样,而没有直接取最高概率对应的字符,是为了保证生成序列的多样性。
例如:图中第一个time step概率最高的为o(.84),但随机采样选中了e。
理解:RNN生成模型的采样策略
Backpropagation through time
利用loss来backpropagation,修正整个网路,但是如果直接是全局在计算的话,会发现显存或内存不够,而且会计算的十分的久,因为训练集是十分巨大的。
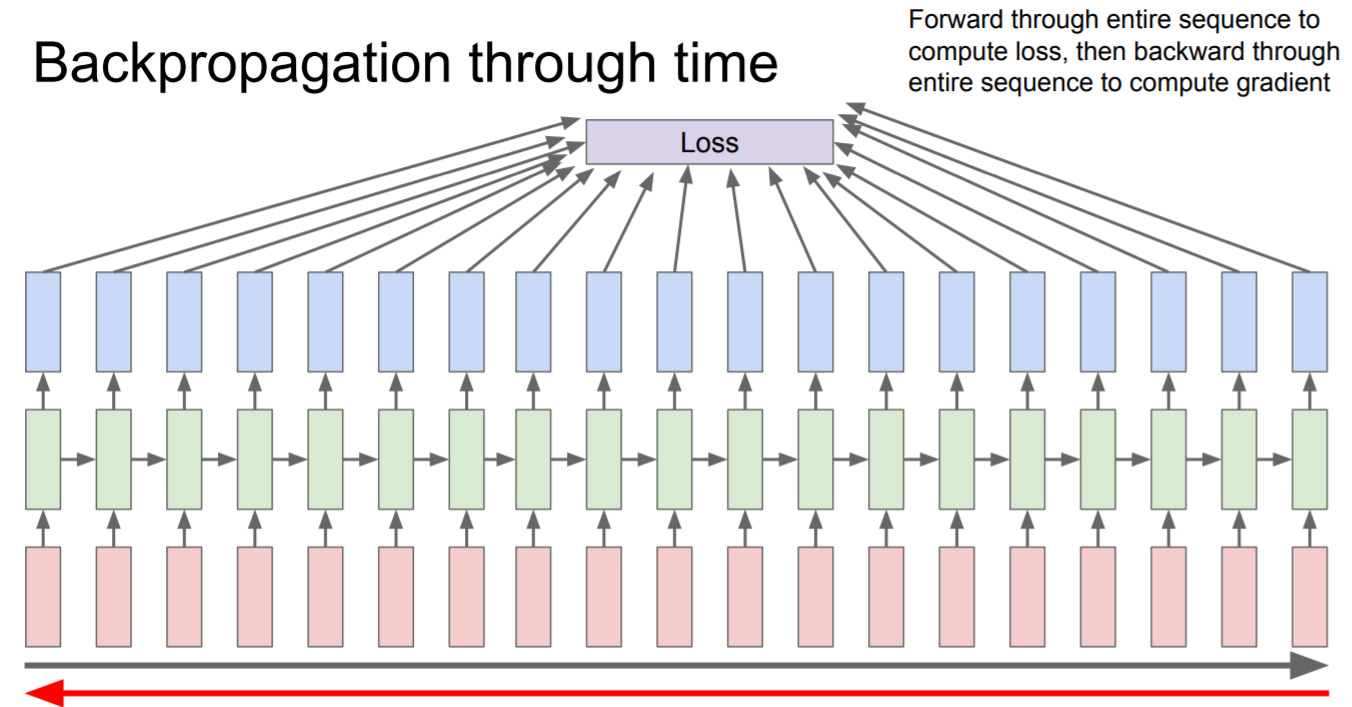
那么有什么办法呢?truncated,也就是分块计算,我们每次只训练一部分序列,例如向前计算100步,然后只计算这100步子序列的损失,然后沿着100步反向计算梯度。

Truncated Backpropagation through time:截断反向传播法
图像标注
先由CNN处理输入的图像,产生图像的特征向量。接下来将特征向量输入到RNN语言模型的第一个时序。
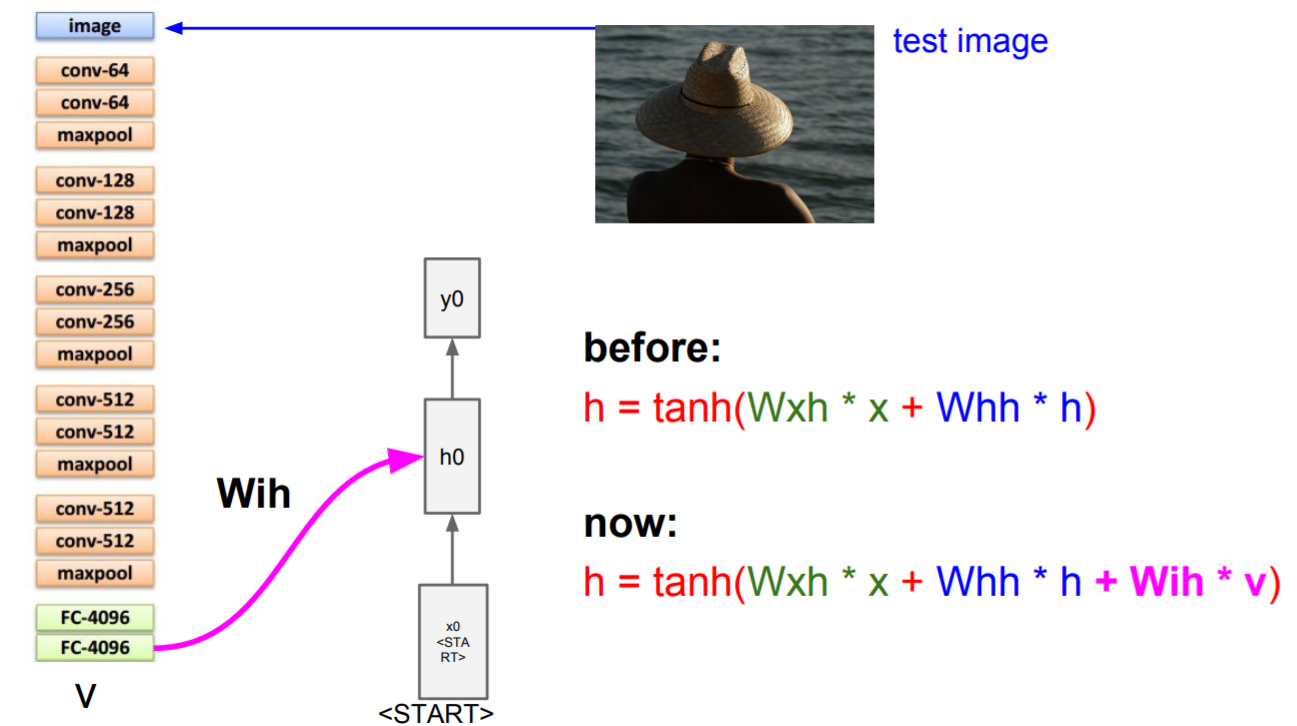
如上图,有一个起始的token,例如<START>。给生成隐藏状态的公式增加
v
v
v 的计算,增加第三个权重矩阵
W
i
h
W_{ih}
Wih,它在每个time step中添加图像信息,来计算下一个隐藏状态。

然后对生成的
y
0
y_{0}
y0 从分布中采样,并在下一个time step作为输入继续计算。直到sample到结束符号<END>。
这是有监督的训练,但是效果不是特别理想。
Attention
attention的提出
把输入X编码成一个固定的长度,对于句子中每个词都赋予相同的权重,这样是不合理的,没有区分度往往使模型性能下降。因此提出Attention Mechanism(注意力机制),用于对输入X的不同部分赋予不同的权重,进而实现软区分的目的。
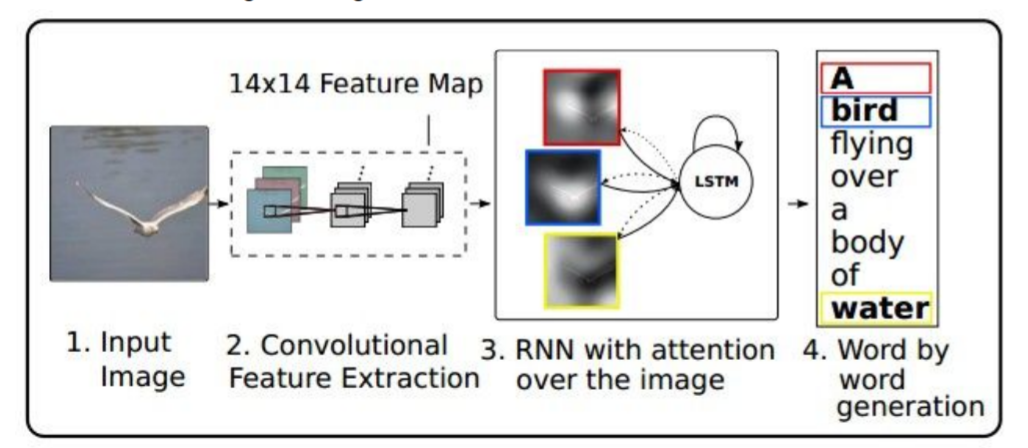
Kelvin Xu等人与2015年发表论文《Show, Attend and Tell: Neural Image Caption Generation with Visual Attention》,在Image Caption中引入了Attention,当生成第i个关于图片内容描述的词时,用Attention来关联与i个词相关的图片的区域。
model
通过CNN产生向量构成的网络,每个图片中特殊的location都用一个向量 v i v_i vi 来表示。
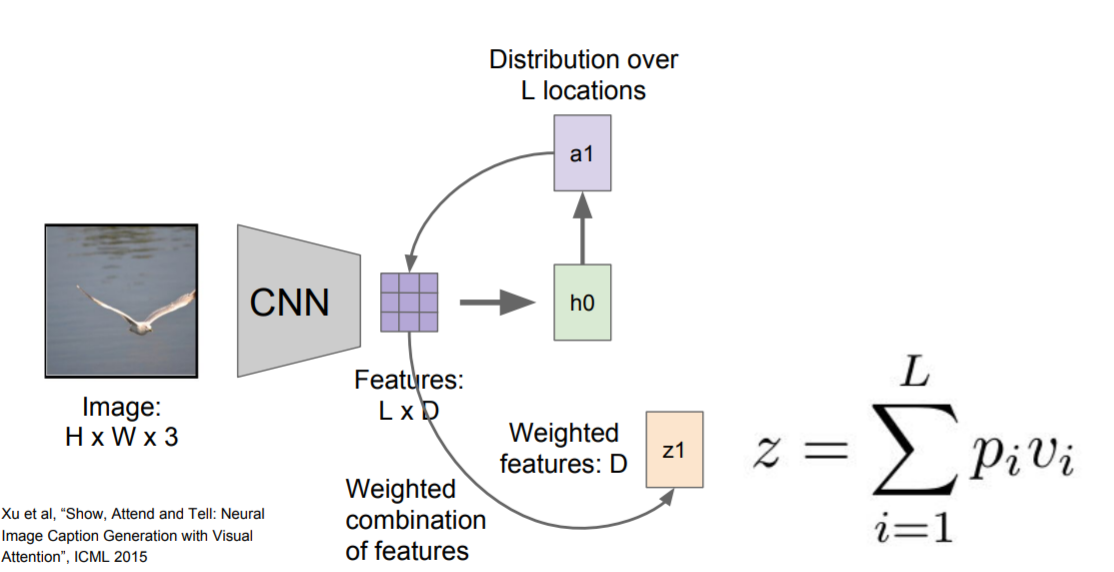
a a a:L个locations上的分布
z z z:概要矢量
p i p_i pi:在第i个location上注意力的大小
v i v_i vi:表示图片上第i个location的向量
模型forward pass时,除了在每一步采样,也会产生一个分布(如上图a1),即图像中它想要看到的位置,图像位置的分布可以看做模型在训练过程中应该关注哪里的张量。第一个隐藏态计算在图片位置上的分布,它将回到向量集合(Features)给出一个概要矢量(z1),把注意力集中到图像的一部分上。
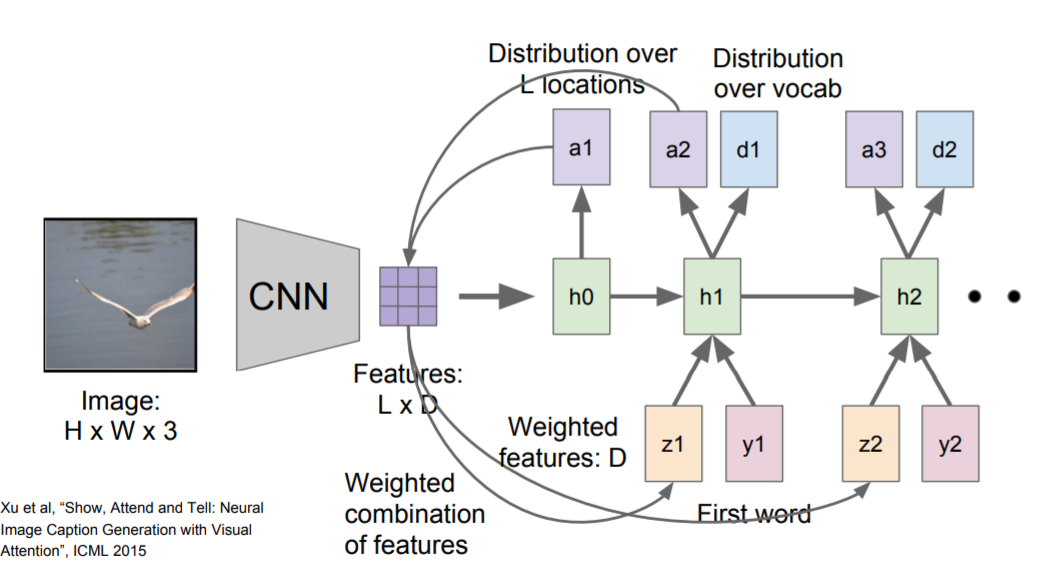
概要向量( z i z_i zi)作为下一个time step的额外输入,它会产生两个输出,一个是在词汇表上的分布( d i d_i di),另一个是图像位置的分布( a i + 1 a_{i+1} ai+1)。
soft / hard attention可视化理解

理解:soft / hard attention 机制 理解——机器学习中的soft 和 hard
- Soft attention是一种全局的attention,其中权重被softly地放在源图像所有区域
- Hard attention一次关注图像的一个区域,采用0-1编码,时间花费较少,但是不可微分,所以需要更复杂的技术来进行训练
视觉问答
LSTM
Why not Vanilla RNN(梯度消失和梯度爆炸)
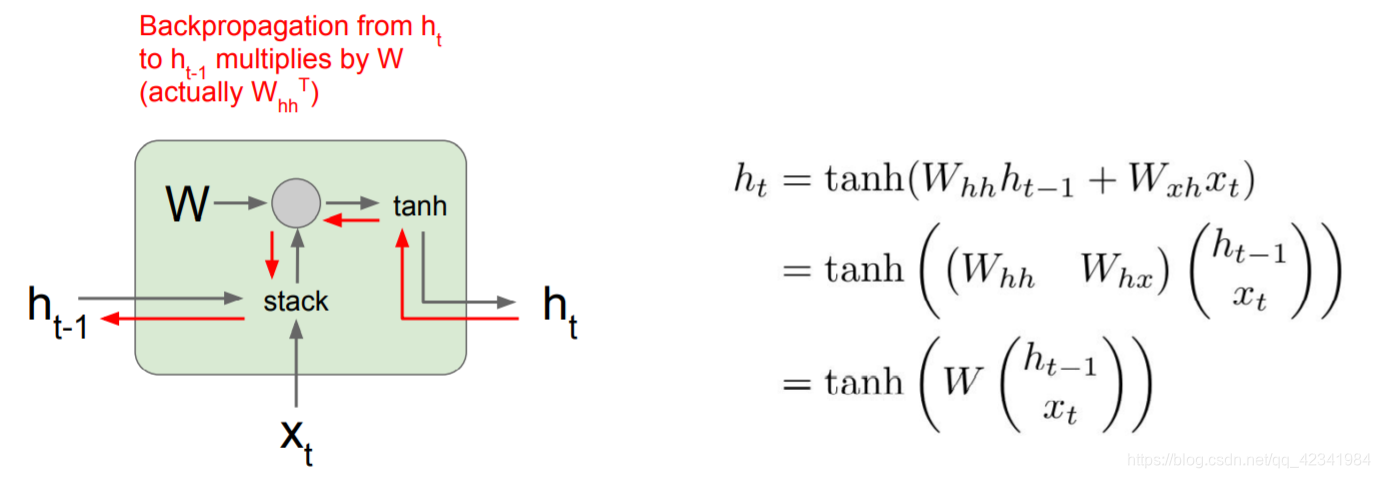
Vanilla RNN的梯度流:
-
forward pass:
x t x_t xt作为当前时间步的输入,输入前一个隐藏态 h t − 1 h_{t-1} ht−1,两个堆叠(stack)起来与权重矩阵 W W W做乘法,得到一个输出,将输出送入tanh激活函数,得到下一个隐藏状态 h t h_t ht。 -
backpropagation:
当计算反向传播时,梯度沿着红色线反向流动。梯度反向流过tanh门和矩阵乘法门。从 h t h_t ht到 h t − 1 h_{t-1} ht−1的反向传播,需要乘以 W W W的转置;如下图,计算损失函数关于 h 0 h_0 h0的梯度,反向传播需要经过RNN中的每一个单元,每经过一个单元都要与其中 W W W的转置做运算,意味着最终的表达式将会包含很多权重矩阵因子。
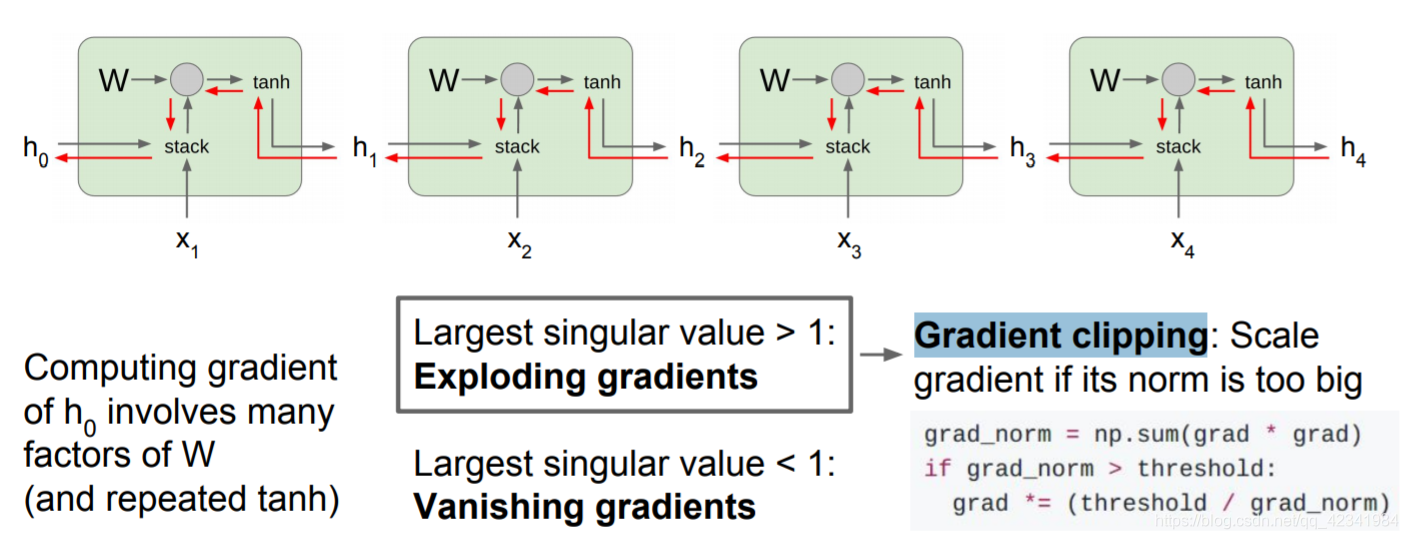
- 考虑标量形式,不断做乘法,会发生梯度爆炸或者梯度消失。
- 考虑矩阵时,矩阵的最大奇异值大于1,权重矩阵一个个相乘, h 0 h_0 h0的梯度将会非常大;最大奇异值小于1,发生梯度消失。
解决方法:
梯度爆炸:计算梯度后,如果L2的范式大于某个阈值,就将它剪断做除法(Gradient clipping/梯度裁剪),这样梯度就有最大阈值。(在训练RNN时比较有效)。
梯度消失:换一种更为复杂的RNN结构(LSTM网络)。
Why LSTM
LSTM用来缓解梯度消失和梯度爆炸,即设计更好的结构来获取更好的梯度流动。
理解:LSTM如何解决梯度消失问题
LSTM 刚提出时没有遗忘门,或者说相当于 f t = 1 f_t=1 ft=1,这时候在 C t − 1 → C t C_{t-1}\rightarrow C_{t} Ct−1→Ct 直接相连的短路路径上, d l / d C t dl/dC_t dl/dCt 可以无损地传递给 d l / d C t − 1 dl/dC_{t-1} dl/dCt−1 ,从而这条路径上的梯度畅通无阻,不会消失。类似于 ResNet 中的残差连接。
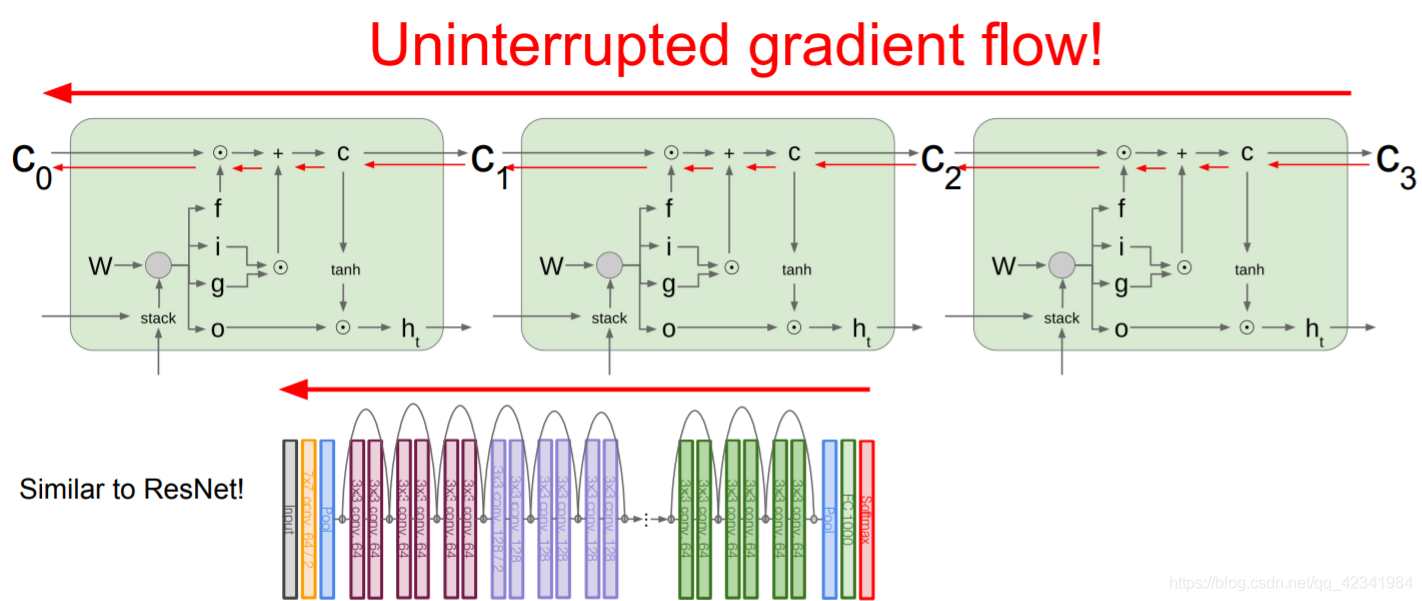
LSTM 核心思想
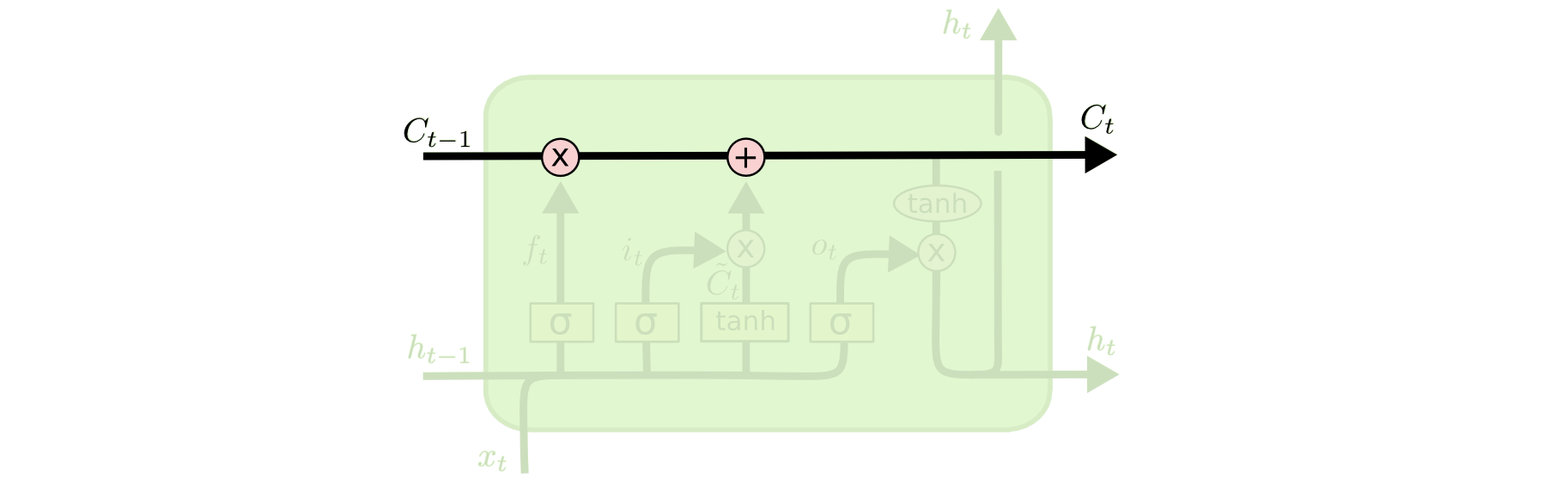
LSTM 的关键就是细胞状态(cell state),水平线在图上方贯穿运行。
细胞状态类似于传送带。直接在整个链上运行,只有一些少量的线性交互。信息在上面流传保持不变会很容易。
LSTM 门
LSTM 通过“门”的结构来去除或者增加信息到细胞状态。门是一种让信息选择式通过的方法,包含一个 sigmoid 神经网络层和一个 pointwise 乘法操作。

Sigmoid 层输出 0 到 1 之间的数值,描述每个部分有多少量可以通过。0 代表“不许任何量通过”,1 就指“允许任意量通过”。
LSTM 拥有三个门,来保护和控制细胞状态。
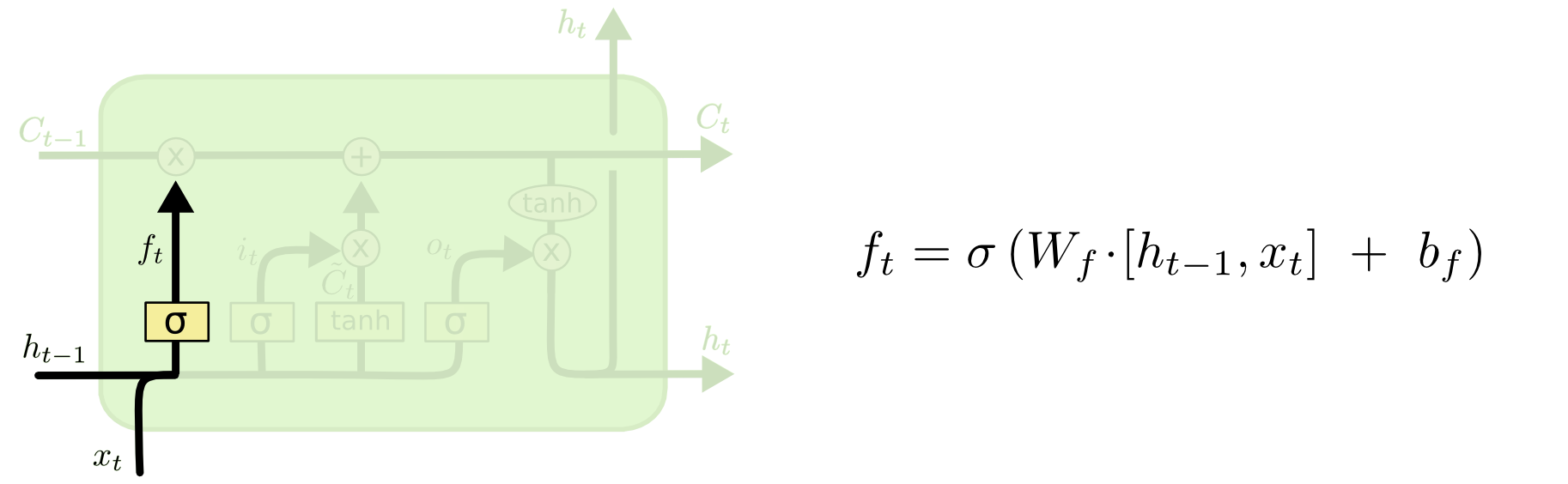
遗忘门
在 LSTM 中的第一步是决定从细胞状态中丢弃什么信息。该门会读取 h t − 1 h_{t-1} ht−1和 x t x_t xt,输出一个在 0 到 1 之间的数值给每个在细胞状态 C t − 1 C_{t-1} Ct−1 中的数字。1 表示“完全保留”,0 表示“完全舍弃”。
语言模型的例子:预测下一个词。
在这个问题中,细胞状态可能包含当前主语的性别,因此正确的代词可以被选择出来。当我们看到新的主语,我们希望忘记旧的主语。
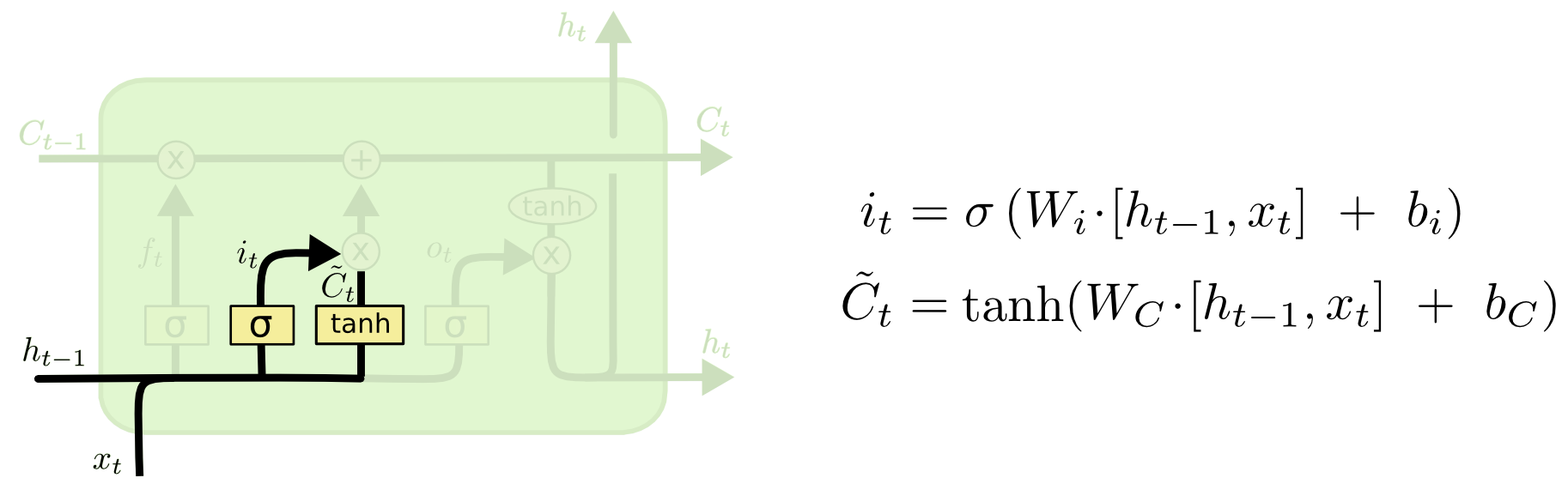
输入门
下一步是决定给细胞状态添加哪些新的信息。这一步又分为两个步骤,首先,利用 h t − 1 h_{t-1} ht−1和 x t x_t xt 通过一个称为“输入门”的操作来决定更新哪些信息。然后利用 h t − 1 h_{t-1} ht−1和 x t x_t xt 通过一个tanh层得到新的候选细胞信息,这些信息可能会被更新到细胞信息中。这两步描述如下图所示:
语言模型的例子:我们希望增加新的主语的性别到细胞状态中,来替代旧的需要忘记的主语。
下面将更新旧的细胞信息 C t − 1 C_{t-1} Ct−1,变为新的细胞信息 C t C_{t} Ct。更新的规则就是通过忘记门选择忘记旧细胞信息的一部分,通过输入门选择添加候选细胞信息 C ~ t \tilde C_{t} C~t 的一部分得到新的细胞信息 C t C_{t} Ct 。更新操作如下图所示:
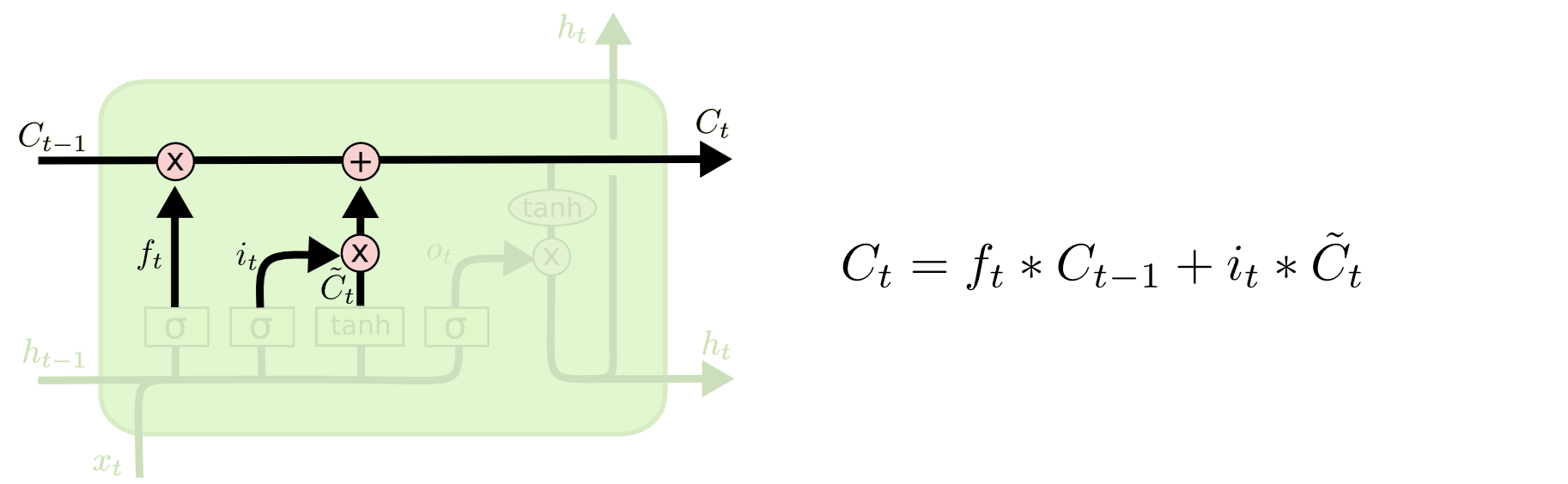
语言模型的例子:这就是我们实际根据前面确定的目标,丢弃旧代词的性别信息并添加新的信息的地方。
输出门
更新完细胞状态后需要根据输入的 h t − 1 h_{t-1} ht−1和 x t x_t xt 来判断输出细胞的哪些状态特征,这里需要将输入经过一个称为“输出门”的sigmoid层得到判断条件,然后将细胞状态经过tanh层得到一个-1~1之间值的向量,该向量与输出门得到的判断条件相乘就得到了最终该RNN单元的输出。该步骤如下图所示:
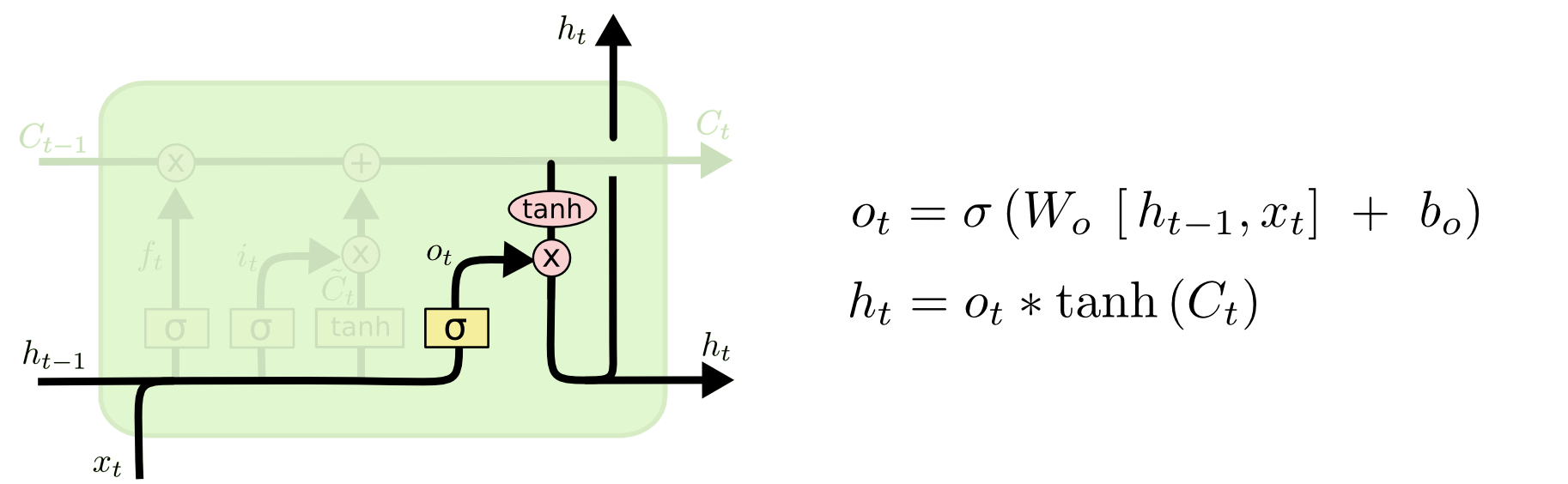
语言模型的例子:在预测动词形式的时候,我们需要通过输入的主语是单数还是复数来推断输出门输出的预测动词是单数形式还是复数形式。
LSTM的变种
GRU
一种比其他形式变化更为显著的LSTM变式是由 Cho, et al. (2014)提出的门循环单元(GRU)。它将忘记门和输入门合并成一个新的门,称为更新门。GRU还有一个门称为重置门。如下图所示:
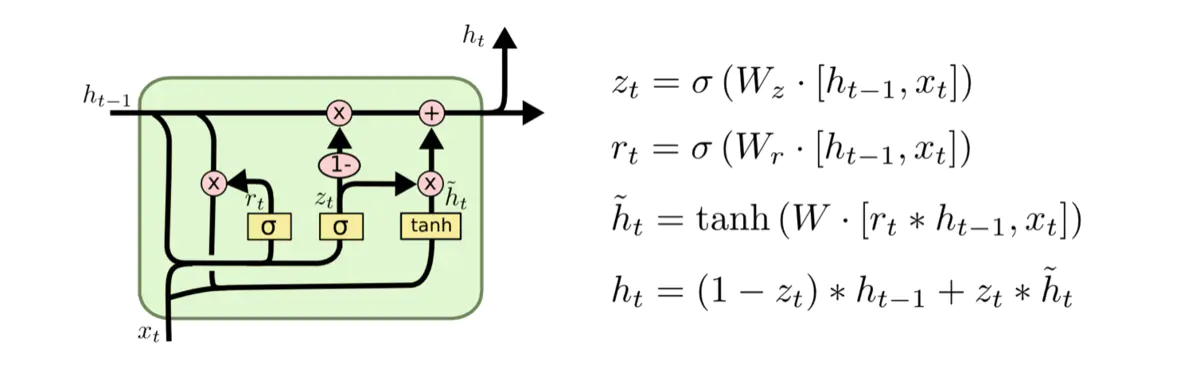
其中重置门为上图中前面那个门,决定了如何将新的输入信息与前面的记忆相结合。更新门为上图中后面那个门,定义了前面记忆保存到当前时间步的量。由于该变式的简单有效,后来被广泛应用。
reference
[1]【译】理解LSTM(通俗易懂版)
[2] LSTM 为何如此有效?














 1787
1787











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









