









Semantic Parsing with Semi-Supervised Sequential Autoencoders
1 Introduction
背景:常规的监督学习是学习从输入序列x到输出序列y的映射,一般 y y y(大量无监督数据)很容易获得,而 ( x , y ) (x,y) (x,y)形式的有监督数据难以获得。
本文提出了一种新的半监督训练架构,以适应序列转导任务(sequence transduction tasks)。即用自动编码目标 ( y → x → y ) (y → x→ y) (y→x→y)增强转导目标 ( x → y ) (x→ y) (x→y),其中输入序列 x x x被视为一个隐变量(latent variable)。
2 Model
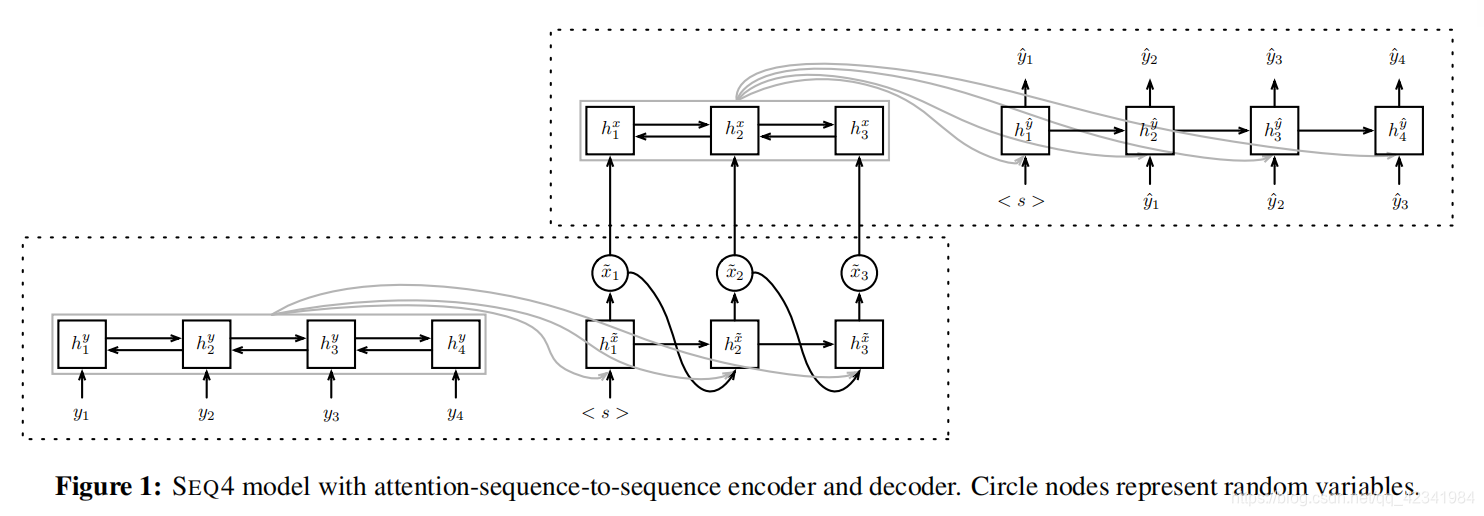
该模型由四个LSTM组成,因此被称为SEQ4。
- 双向LSTM:对序列y进行编码;
- 一个具有随机输出的LSTM:在词汇Σx上绘制一个分布 x ~ \tilde{x} x~的序列;
- LSTM:对这些分布进行编码;
- LSTM:将 y y y重构为 y ~ \tilde{y} y~ 。
2.1 Encoding y y y
h t y = ( f y → ( y t , h t − 1 y , → ) ; f y ← ( y t , h t + 1 y , ← ) ) h_{t}^{y}=\left(f_{y}^{\rightarrow}\left(y_{t}, h_{t-1}^{y, \rightarrow}\right) ; f_{y}^{\leftarrow}\left(y_{t}, h_{t+1}^{y, \leftarrow}\right)\right) hty=(fy→(yt,ht−1y,→);fy←(yt,ht+1y,←))
2.2 Predicting a Latent Sequence x ~ \tilde{x} x~
通过词汇表
Σ
x
\Sigma x
Σx上的多项分布(multinomial distributions)来预测离散的符号序列不能执行反向传播,因此,在
Σ
x
\Sigma x
Σx上预测一个分布为
x
~
\tilde{x}
x~的序列:
x
~
=
q
(
x
∣
y
)
=
∏
t
=
1
L
x
q
(
x
~
t
∣
{
x
~
1
,
⋯
,
x
~
t
−
1
}
,
h
y
)
\tilde{x}=q(x \mid y)=\prod_{t=1}^{L_{x}} q\left(\tilde{x}_{t} \mid\left\{\tilde{x}_{1}, \cdots, \tilde{x}_{t-1}\right\}, h^{y}\right)
x~=q(x∣y)=t=1∏Lxq(x~t∣{x~1,⋯,x~t−1},hy)其中,
x
~
t
\tilde{x}_{t}
x~t是词汇
Σ
x
\Sigma x
Σx上的分布,
Σ
x
\Sigma x
Σx来自于一个logistic正态分布。
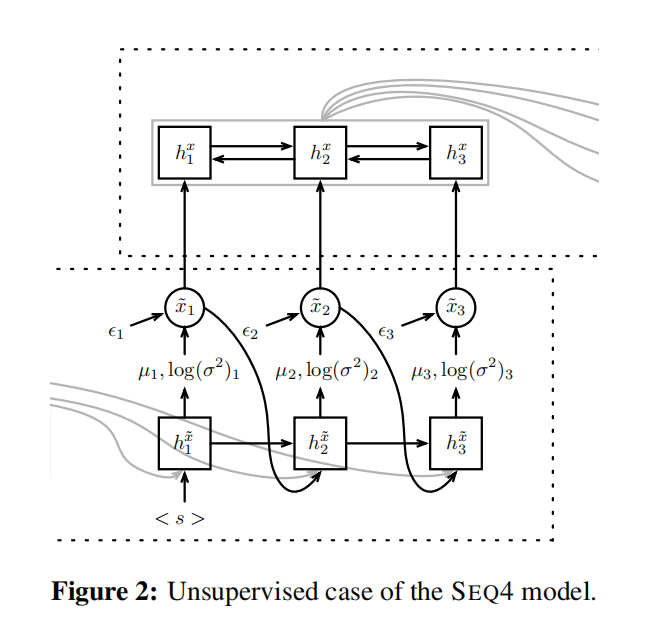
图2中下半部分的虚线框计算过程为:
h
t
x
~
=
f
x
~
(
x
~
t
−
1
,
h
t
−
1
x
~
,
h
y
)
μ
t
,
log
(
σ
t
2
)
=
l
(
h
t
x
~
)
ϵ
∼
N
(
0
,
I
)
γ
t
=
μ
t
+
σ
t
ϵ
x
~
t
=
softmax
(
γ
t
)
\begin{aligned} h_{t}^{\tilde{x}} &=f_{\tilde{x}}\left(\tilde{x}_{t-1}, h_{t-1}^{\tilde{x}}, h^{y}\right) \\ \mu_{t}, \log \left(\sigma_{t}^{2}\right) &=l\left(h_{t}^{\tilde{x}}\right) \\ \epsilon & \sim \mathcal{N}(0, I) \\ \gamma_{t} &=\mu_{t}+\sigma_{t} \epsilon \\ \tilde{x}_{t} &=\operatorname{softmax}\left(\gamma_{t}\right) \end{aligned}
htx~μt,log(σt2)ϵγtx~t=fx~(x~t−1,ht−1x~,hy)=l(htx~)∼N(0,I)=μt+σtϵ=softmax(γt)其中,
f
x
~
f_{\tilde{x}}
fx~是LSTM,
l
l
l是线性变换。
2.3 Encoding x x x
图2中上半部分的虚线框计算过程为:
h
t
x
=
(
f
x
→
(
x
~
t
,
h
t
−
1
x
,
→
)
;
f
x
←
(
x
~
t
,
h
t
+
1
x
,
←
)
)
h_{t}^{x}=\left(f_{x}^{\rightarrow}\left(\tilde{x}_{t}, h_{t-1}^{x, \rightarrow}\right) ; f_{x}^{\leftarrow}\left(\tilde{x}_{t}, h_{t+1}^{x, \leftarrow}\right)\right)
htx=(fx→(x~t,ht−1x,→);fx←(x~t,ht+1x,←))
2.4 Reconstructing y y y
在最后一个LSTM,解码得到
y
y
y:
p
(
y
^
∣
x
~
)
=
∏
t
=
1
L
y
p
(
y
^
t
∣
{
y
^
1
,
⋯
,
y
^
t
−
1
}
,
h
x
~
)
p(\hat{y} \mid \tilde{x})=\prod_{t=1}^{L_{y}} p\left(\hat{y}_{t} \mid\left\{\hat{y}_{1}, \cdots, \hat{y}_{t-1}\right\}, h^{\tilde{x}}\right)
p(y^∣x~)=t=1∏Lyp(y^t∣{y^1,⋯,y^t−1},hx~)具体过程为:
h
t
y
^
=
f
y
^
(
y
^
t
−
1
,
h
t
−
1
y
^
,
h
x
~
)
y
^
t
∼
softmax
(
l
′
(
h
t
y
^
)
)
\begin{array}{l} h_{t}^{\hat{y}}=f_{\hat{y}}\left(\hat{y}_{t-1}, h_{t-1}^{\hat{y}}, h^{\tilde{x}}\right) \\ \hat{y}_{t} \sim \operatorname{softmax}\left(l^{\prime}\left(h_{t}^{\hat{y}}\right)\right) \end{array}
hty^=fy^(y^t−1,ht−1y^,hx~)y^t∼softmax(l′(hty^))在training时feed的是ground truth
y
t
−
1
{y}_{t-1}
yt−1而不是
y
^
t
−
1
\hat{y}_{t-1}
y^t−1。
2.5 Loss function
SEQ4完整模型给出了一个重建函数
(
y
→
y
^
)
(y → \hat{y})
(y→y^)。在此重构上定义了一个损失,适用于Unsupervised case,其中
x
x
x在训练数据中没有被观察到,而Supervised case,其中(x, y)对是可用的。二者一起构成半监督训练,实验表明比纯监督训练效果更好。
- Unsupervised case
当 x x x没有被观察到时,我们在训练中最小化的损失是 y y y上的重建损失,表示为真实标签 y y y相对于预测 y ^ \hat{y} y^的负对数似然(negative loglikelihood) N L L ( y ^ , y ) NLL(\hat{y}, y) NLL(y^,y)。
unsupervised loss: L unsup = N L L ( y ^ , y ) + α K L [ q ( γ ∣ y ) ∥ p ( γ ) ] \mathcal{L}_{\text {unsup }}=N L L(\hat{y}, y)+\alpha K L[q(\gamma \mid y) \| p(\gamma)] Lunsup =NLL(y^,y)+αKL[q(γ∣y)∥p(γ)]
其中, K L [ q ( γ ∣ y ) ∥ p ( γ ) ] = ∑ i = 1 L x K L [ q ( γ i ∣ y ) ∥ p ( γ ) ] K L[q(\gamma \mid y) \| p(\gamma)]=\sum_{i=1}^{L_{x}} KL\left[q\left(\gamma_{i} \mid y\right) \| p(\gamma)\right] KL[q(γ∣y)∥p(γ)]=i=1∑LxKL[q(γi∣y)∥p(γ)]这有平滑 logistic-normal distribution 的效果,我们从中绘制 x x x的符号上的分布,防止将 x x x上的潜在分布过度拟合到下面讨论的Supervised case的符号上。 - Supervised case
当 x x x被观察到时,我们额外地最小化 x x x上的预测损失,表示为真实标签 x x x相对于预测 x ~ \tilde{x} x~的负对数似然 N L L ( x ~ , x ) NLL(\tilde{x}, x) NLL(x~,x),并且不强加KL损失。
supervised loss: L sup = N L L ( x ~ , x ) + N L L ( y ^ , y ) \mathcal{L}_{\text {sup }}=NLL(\tilde{x}, x)+NLL(\hat{y}, y) Lsup =NLL(x~,x)+NLL(y^,y) - Semi-supervised training and inference
用上述监督和非监督损失的加权组合进行训练。推理时只需使用模型的 ( x → y ) (x→ y) (x→y)解码器部分。当解码器在没有编码器的情况下以完全监督的方式进行训练时即退化为Seq2Seq baseline。
3 Tasks and Data Generation
4 Experiments
5 Discussion
Semi-supervised training:
表8显示了一些将无监督逻辑形式转换为自然语言的示例,演示了模型如何学习合理地处理无监督数据:















 9157
9157











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









