







 本文介绍了WDL模型,涵盖了记忆能力、泛化能力的讨论,详细解释了模型的提出背景和结构,并展示了如何通过交叉积变换在谷歌实践中应用,以及使用TensorFlow 2进行实际编码实现。
本文介绍了WDL模型,涵盖了记忆能力、泛化能力的讨论,详细解释了模型的提出背景和结构,并展示了如何通过交叉积变换在谷歌实践中应用,以及使用TensorFlow 2进行实际编码实现。
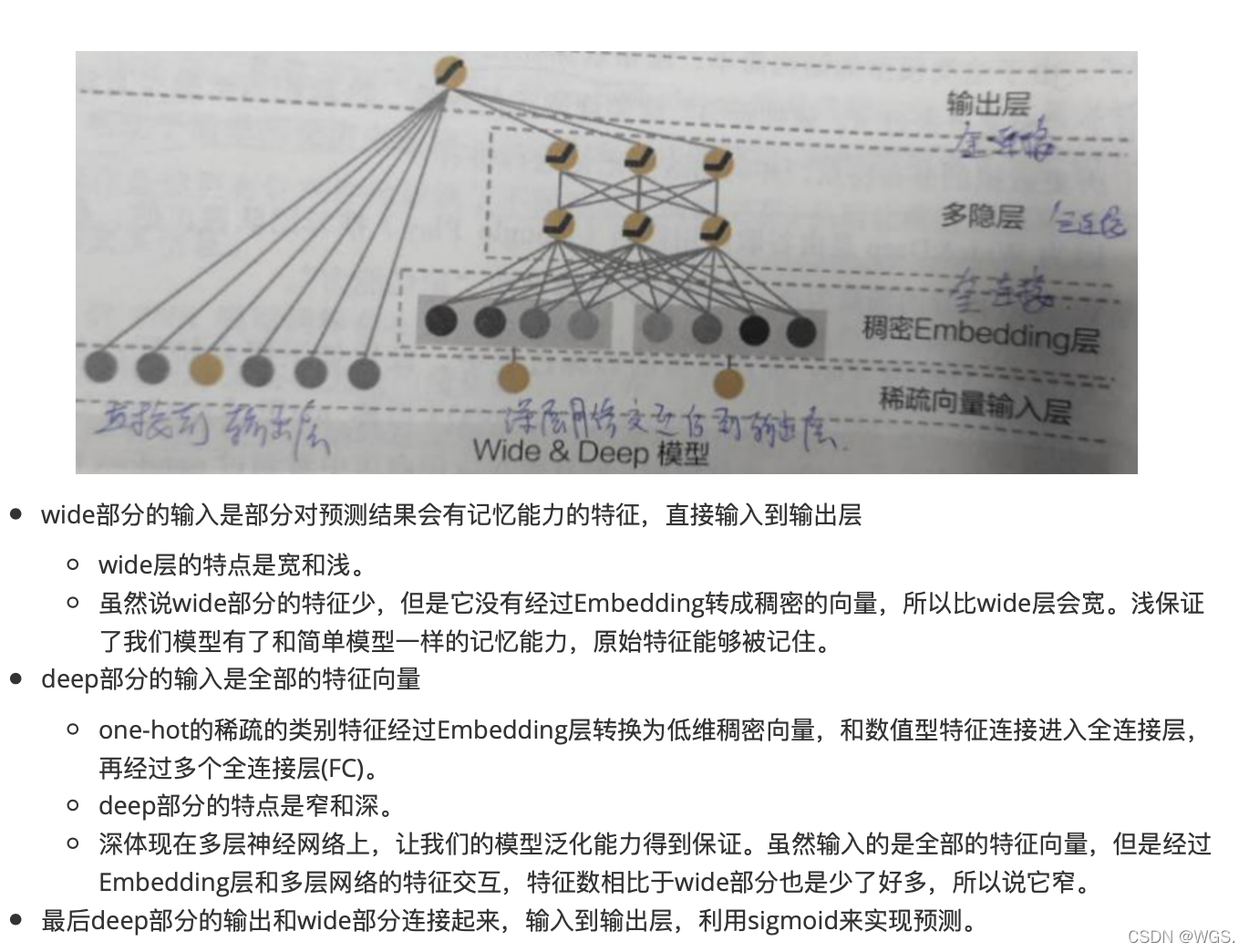
记忆能力

泛化能力

提出动机

结构
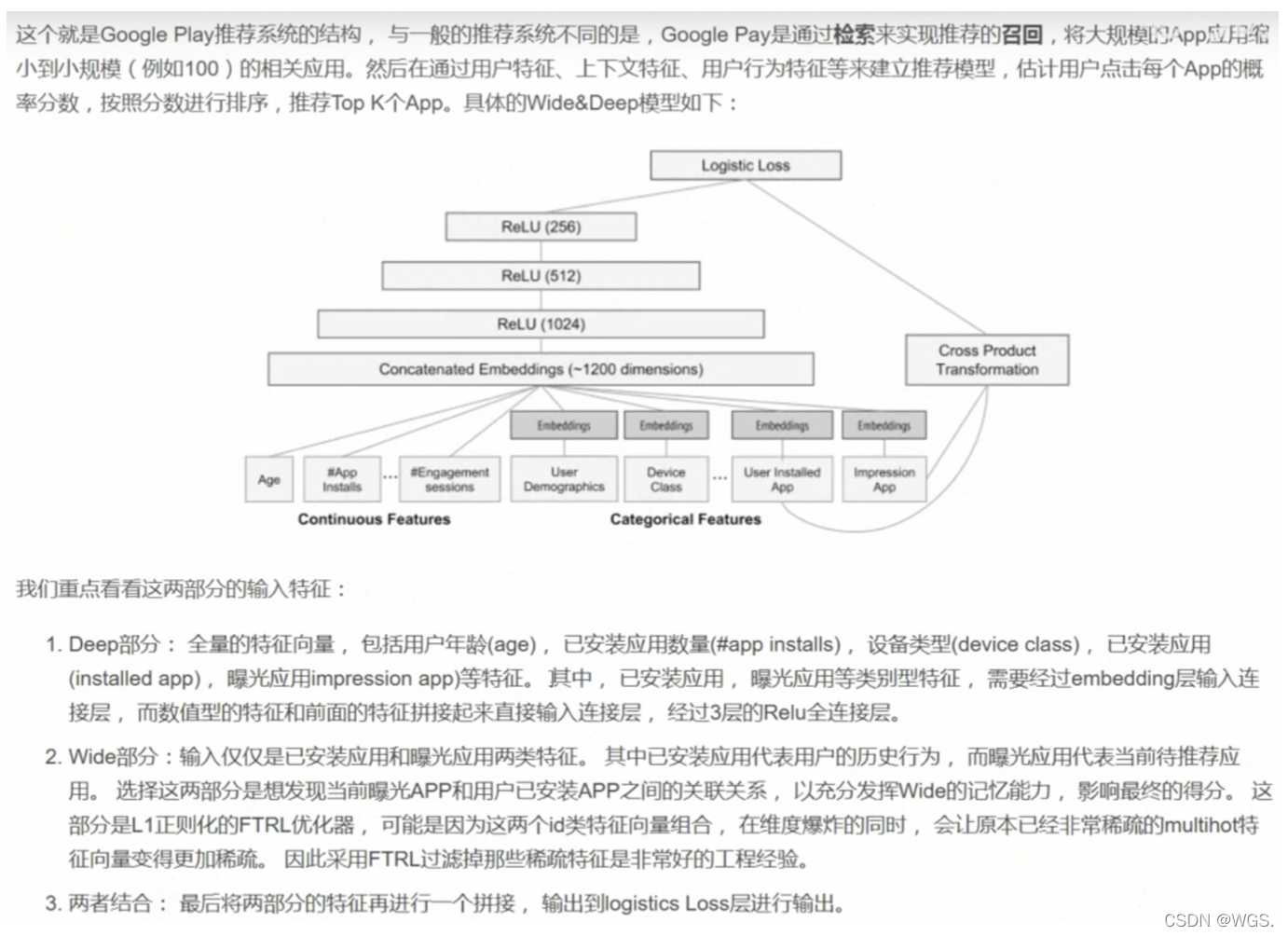
交叉积变换


谷歌的实践
tf2实现
# coding:utf-8
# @Time: 2021/12/30 5:18 下午
# @File: ctr_WDL.py
'''
WDL
'''
'''
WDL
'''
import numpy as np
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras import Model
from tensorflow.keras import optimizers
from tensorflow.keras import metrics
from tensorflow.keras import regularizers
from sklearn.model_selection import train_test_split
import yaml
from tools import *
class WideDeepNet(Model):
def __init__(self, spare_feature_columns, dense_feature_columns, hidden_units, output_dim, activation, droup_out, w_reg):
super(WideDeepNet, self).__init__()
self.dense_feature_columns = dense_feature_columns
self.spare_feature_columns = spare_feature_columns
self.w_reg = w_reg
# embedding
self.embedding_layer = {'embed_layer{}'.format(i): layers.Embedding(feat['vocabulary_size'], feat['embed_dim'])
for i, feat in enumerate(self.spare_feature_columns)}
# deep
self.DNN = tf.keras.Sequential()
for hidden in hidden_units:
self.DNN.add(layers.Dense(hidden))
self.DNN.add(layers.BatchNormalization())
self.DNN.add(layers.Activation(activation))
self.DNN.add(layers.Dropout(droup_out))
self.DNN.add(layers.Dense(output_dim, activation=None))
def build(self, input_shape):
self.w = self.add_weight(name='w', shape=(input_shape[-1], 1), initializer=tf.random_normal_initializer(),
trainable=True, regularizer=regularizers.l2(self.w_reg))
self.b = self.add_weight(name='b', shape=(1,), initializer=tf.zeros_initializer(), trainable=True)
def call(self, inputs):
# dense_inputs: 数值特征,13维
# sparse_inputs: 类别特征,26维
dense_inputs, sparse_inputs = inputs[:, :13], inputs[:, 13:]
# wide
wide_out = inputs @ self.w + self.b # (batchsize, 1)
# deep
sparse_embed = tf.concat([self.embedding_layer['embed_layer{}'.format(i)](sparse_inputs[:, i]) for i in
range(sparse_inputs.shape[-1])], axis=-1) # (batchsize, 26*embed_dim)
dnn_input = tf.concat([sparse_embed, dense_inputs], axis=-1) # (batchsize, 26*embed_dim + 13)
deep_out = self.DNN(dnn_input) # # (batchsize, 1)
output = tf.sigmoid(wide_out + deep_out)
return output
if __name__ == '__main__':
with open('config.yaml', 'r') as f:
config = yaml.Loader(f).get_data()
data = pd.read_csv('../../data/criteo_sampled_data_OK.csv')
data_X = data.iloc[:, 1:]
data_y = data['label'].values
# I1-I13:总共 13 列数值型特征
# C1-C26:共有 26 列类别型特征
dense_features = ['I' + str(i) for i in range(1, 14)]
sparse_features = ['C' + str(i) for i in range(1, 27)]
dense_feature_columns = [denseFeature(feat) for feat in dense_features]
spare_feature_columns = [sparseFeature(feat, data_X[feat].nunique(), config['WDL']['embed_dim']) for feat in
sparse_features]
tmp_X, test_X, tmp_y, test_y = train_test_split(data_X, data_y, test_size=0.2, random_state=42, stratify=data_y)
train_X, val_X, train_y, val_y = train_test_split(tmp_X, tmp_y, test_size=0.1, random_state=42, stratify=tmp_y)
model = WideDeepNet(spare_feature_columns=spare_feature_columns,
dense_feature_columns=dense_feature_columns,
hidden_units=config['WDL']['hidden_units'],
output_dim=config['WDL']['output_dim'],
activation=config['WDL']['activation'],
droup_out=config['WDL']['droup_out'],
w_reg=config['WDL']['w_reg'])
adam = optimizers.Adam(lr=config['train']['adam_lr'], beta_1=0.95, beta_2=0.96,
decay=config['train']['adam_lr'] / config['train']['epochs'])
model.compile(
optimizer=adam,
loss='binary_crossentropy',
metrics=[metrics.AUC(), metrics.Precision(), metrics.Recall()]
)
model.fit(
train_X.values, train_y,
validation_data=(val_X.values, val_y),
batch_size=config['train']['batch_size'],
epochs=config['train']['epochs'],
verbose=1,
)
model.summary()
Epoch 1/3
215/216 [============================>.] - ETA: 0s - loss: 362.3944 - auc: 0.5093 - precision: 0.2697 - recall: 0.2706Tensor("wide_deep_net/concat_1:0", shape=(2000, 117), dtype=float32)
216/216 [==============================] - 8s 37ms/step - loss: 360.7360 - auc: 0.5095 - precision: 0.2699 - recall: 0.2699 - val_loss: 9.5656 - val_auc: 0.5045 - val_precision: 0.2571 - val_recall: 0.8003
Epoch 2/3
216/216 [==============================] - 8s 36ms/step - loss: 8.1209 - auc: 0.5805 - precision: 0.3577 - recall: 0.3609 - val_loss: 4.0739 - val_auc: 0.5357 - val_precision: 0.6106 - val_recall: 0.0254
Epoch 3/3
216/216 [==============================] - 8s 36ms/step - loss: 2.9503 - auc: 0.6771 - precision: 0.4734 - recall: 0.4667 - val_loss: 5.3457 - val_auc: 0.5337 - val_precision: 0.6819 - val_recall: 0.0340




















 580
580

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











