







解析库
对于网页的节点来说,它可以定义id、 class或其他属性。而且节点之间还有层次关系,在网页中可以通过XPath或CSS选择器来定位(或提取)一个或多个节点。然后再调用相应方法获取它的正文内容或者属性,就可以提取我们想要的信息。
[第四部分 解析库的使用(XPath、Beautiful Soup、PyQuery][https://www.cnblogs.com/Micro0623/p/10496376.html]
XPath
全称 XML Path Language,XML 路径语言
最初是设计用来搜寻XML文档,同样适用于HTML文档的搜索(也可以说用于信息抽取),所以爬虫也可以适用
XPath对应的库是lxml库
XPath的选择功能十分强大,提供了非常简洁明了的路径选择表达式。另外,还提供了超过100个内建函数,用于字符串、数值、时间的匹配以及节点、序列的处理等。几乎所有想要定位的节点,都可以用XPath来选择。
1. 概念
xpath简介:
-
XML路径语言,拥有在数据结构树中查找节点的能力
-
被开发者当作小型查询语言来使用
-
XPath通过元素和属性进行导航
-
通常来说,lxml是抓取数据的最好选择,因为该方法既快速又健壮。
为什么学习Xpath:
1、支持html
2、比正则表达式简单,强大
3、scrapy
Xpath的基本概念:
节点:
Parent(父)Children(子)Sibling(同胞)Ancestor(先辈)Descendant(后代)
路径表达式:XPath 使用路径表达式来选取 XML 文档中的节点或节点集。节点是通过沿着路径 (path) 或者步 (steps) 来选取的。
2. 官方学习网址
https://www.w3school.com.cn/xpath/index.asp
3. XPath组成
3.1 表达式
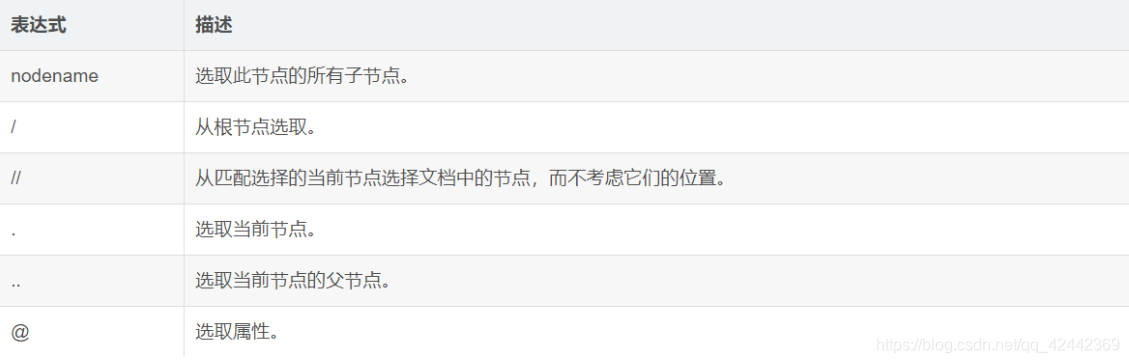
3.2 路径表达式
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1vwIMhX5-1592754095075)(C:\Users\sevier_yang_laptop\Documents\WXWork\1688852877258705\WeDrive\正研数据\3. 爬虫\images\1585204947444.png)]](https://img-blog.csdnimg.cn/2020062123424961.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQyNDQyMzY5,size_16,color_FFFFFF,t_70)
3.3 谓语
谓语(Predicates)
谓语用来查找某个特定的节点或者包含某个指定的值的节点
谓语被嵌在方括号中
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-36Cjjgwn-1592754095076)(C:\Users\sevier_yang_laptop\Documents\WXWork\1688852877258705\WeDrive\正研数据\3. 爬虫\images\1585206905191.png)]](https://img-blog.csdnimg.cn/20200621234307545.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQyNDQyMzY5,size_16,color_FFFFFF,t_70)
3.4 选取未知节点,通配符
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5KPauMLH-1592754095078)(C:\Users\sevier_yang_laptop\Documents\WXWork\1688852877258705\WeDrive\正研数据\3. 爬虫\images\1585206914752.png)]](https://img-blog.csdnimg.cn/20200621234319340.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQyNDQyMzY5,size_16,color_FFFFFF,t_70)
3.5 选取若干路径
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AoVAajVK-1592754095081)(C:\Users\sevier_yang_laptop\Documents\WXWork\1688852877258705\WeDrive\正研数据\3. 爬虫\images\1585206934860.png)]](https://img-blog.csdnimg.cn/2020062123432724.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQyNDQyMzY5,size_16,color_FFFFFF,t_70)
4. 实操项目
常用方法
#!/usr/bin/env python
#-- coding:utf-8 --
# 可以考虑借鉴这种署名格式
"""
@Author : LiuZhian
@Time : 2019/4/24 0024 上午 9:19
@Comment :
"""
import lxml.etree as etree
html = """
<!DOCTYPE html>
<html>
<head lang="en">
<title>xpath测试</title>
</head>
<body>
<div id="content">
<ul id="ul">
<li>NO.1</li>
<li>NO.2</li>
<li>NO.3</li>
</ul>
<ul id="ul2">
<li>one</li>
<li>two</li>
</ul>
</div>
<div id="url">
<a href="http:www.58.com" title="58">58</a>
<a href="http:www.csdn.net" title="CSDN">CSDN</a>
</div>
</body>
</html>
"""
print(type(html))
# 传入参数,调用etree模块下的HTML方法,生成选择器对象selector
selector = etree.HTML(html)
# 截取内容 no.1 # 运用路径表达式(节点+表达式)和谓语 用 @ 符号进行属性过滤
str = selector.xpath('//div[@id="content"]/ul[@id="ul"]/li/text()')[0] # 之所以用索引,是因为返回的是列表
print(str)
# 截取内容 no.2
str2 = selector.xpath('//div[@id="content"]/ul[@id="ul"]/li/text()')[1]
print(str2)
# 截取内容 one
str3 = selector.xpath('//div[@id="content"]/ul[@id="ul2"]/li/text()')[0]
print(str3)
# 第二种方法截取内容 one,也可以的,是利用//获取子孙节点
str3_1 = selector.xpath('//ul[@id="ul2"]/li/text()')[0]
print(str3_1)
# 测试,不加属性=值
str3_2 = selector.xpath('//ul/li/text()') # 获取所有ul里面的li的文本,返回列表
print(str3_2)
# ['NO.1', 'NO.2', 'NO.3', 'one', 'two']
# 截取内容 CSDN
str4 = selector.xpath('//div[@id="url"]/a/text()')
print(str4)
# ['58', 'CSDN']
# 截取标题 测试
str5 = selector.xpath('//title/text()')
print(str5)
# ['xpath测试']
# 重要:获取文件中div的属性id为”url“里面的所有a标签的href属性 # a[@href=] 获取到哪个a ,不对!!!/text() 这个也不对
# 属性匹配是中括号加属性名和值来限定某个属性,如 [@href="link1.html"],而此处的 @href 指的是获取节点的某个属性值,注意二者的区分。
str6 = selector.xpath('//div[@id="url"]/a/@href')
print(str6)
# ['http:www.58.com', 'http:www.csdn.net']
# 试验 // 和 *
# 读取所有节点, 整个HTML文本中所有节点都会被获取,每个原始都是element对象
str7 = selector.xpath('//*') # // Invalid expression
print(str7)
# 没读文本,text()和 属性,肯定就没有啊,傻逼
### 多个可以按序选择,就是使用方括号[],谓语
result21 = selector.xpath('//ul/li[3]/@class') # 注意 @之后是 属性名
print(result21)
# [<Element html at 0x1ed2eff4d88>, <Element body at 0x1ed2eff4ec8>, <Element div at 0x1ed2eff4f08>]
# 一个属性 多值
# contains()函数,修改代码如下:
from lxml import etree
text = '''
<li class="li li-first"><a href="link.html">first item</a></li>
'''
html = etree.HTML(text)
result = html.xpath('//li[contains(@class, "li")]/a/text()')
print(result) # 输出结果是:['first item']
通过contains()方法,第一个参数传入属性名称,第二个参数传入属性值,只要此属性包含所传入的属性值,就可以完成匹配。
# # 多个属性 多值
根据多个属性确定一个节点,需要同时匹配多个属性,可使用运行符 and 来连接。示例如下:
from lxml import etree
text = '''
<li class="li li-first" name="item"><a href="link.html">first item</a></li>
'''
html = etree.HTML(text)
result = html.xpath('//li[contains(@class, "li") and @name="item"]/a/text()')
print(result) # 输出是:['first item']
这里的li节点增加了一个属性name。要确定这个节点,需要同时根据class和name属性来选择,一个条件是class属性里面包含li字符串,另一个条件是name属性为item字符串,二者需要同时满足,需要用and操作符相连,相连之后置于中括号内进行条件筛选。
# 父节点
还有 按序选择,属于谓语
li[last()]
li[position<3]
li[last()-2]
在一些匹配任务中,可能在某些属性会同时匹配多个节点,但是只想要其中的某个节点,如第二个节点或第一个节点,这时可利用中括号传入索引的方法获取特定次序的节点。注意这里的索引是从1开始
text = """
<div>
<ul>
<li class="item-0"><a href="link1.html"><span>first item</span></a></lis>
<li class="item-1"><a href="link2.html"><span>second item</span></a></lis>
<li class="item-inactive"><a href="link3.html"><span>third item</span></a></lis>
<li class="item-1"><a href="link4.html"><span>fourth item</span></a></lis>
<li class="item-0"><a href="link5.html"><span>fifth item</span></a></lis>
</ul>
</div>
"""
其他方法
如果节点需要修正,补充?etree.tostring()
# 针对:li节点没有闭合,需要自动修正
from lxml import etree
html = etree.HTML(text) # 调用HTML类初始化,自动修正HTML文本
result = etree.tostring(html) # 输出修正后的HTML代码,是bytes类型print(result.decode("utf-8"))
调用tostring()方法即可输出修正后的HTML代码,结果是bytes类型。利用decode()方法将其转成str类型,在输出结果中,经过处理后,li节点的标签被补全,并且还自动添加了body、html节点
如何直接读取文本文件进行解析? etree.parse()
from lxml import etree
html = etree.parse('./test.html', etree.HTMLParser())
result = etree.tostring(html)
print(result.decode('utf-8'))
节点轴的各种选择方法
[XPath 教程][https://www.runoob.com/xpath/xpath-tutorial.html]
[XPath 轴(Axes)][https://www.runoob.com/xpath/xpath-axes.html]
### 节点轴选择方法,选取 兄弟元素,父元素,子元素,祖先元素
## 调用ancestor轴
# 选取所有祖先节点 ancestor::*
result3 = selector.xpath('//ul/ancestor::*')
# print(result3)
# [<Element html at 0x1ed2eff4d88>, <Element body at 0x1ed2eff4ec8>, <Element div at 0x1ed2eff4f08>]
# 选取ancestor里面的div
result4 = selector.xpath('//ul/ancestor::div')
# print(result4)
# [<Element div at 0x1631b1e4f08>]
## 调用attribute轴
# 选取某节点里的所有属性
result5 = selector.xpath('//ul/li/attribute::*') # ul没有属性,li有属性
# print(result5)
# 选取某节点里的所有属性
result6 = selector.xpath('//ul/li[@class="item-0"]/a/span/text()') # /子节点子节点,子孙节点不行 都是['\n', '\n\n\n']
# print(result6)
# ['first item', 'fifth item']
## 调用child轴
# 选取 属性为link4的 a节点
result7 = selector.xpath('//ul/li/child::a[@href="link4.html"]')
# print(result7)
## 调用descendant轴
# 选取 属性为link4的 a节点
# result8 = selector.xpath('//ul/li/descendant::a')
result8 = selector.xpath('//ul/li/descendant::*')
# print(result8)
## 调用following轴
# following 相当于 当前节点,下面的所有节点
# result9 = selector.xpath('//ul/li[@class="item-inactive"]/following::*')
# result9 = selector.xpath('//li[1]/following::*[1]')
# result10 = selector.xpath('//li[1]/following::*[2]')
# result11 = selector.xpath('//li[1]/following::*[3]')
# print(result9, result10, result11)
# [<Element li at 0x1da39fa4fc8>] [<Element a at 0x1da39fe7508>] [<Element span at 0x1da39fe7548>]
#
## following-sibling节点,当前节点之后的所有兄弟节点
# result9 = selector.xpath('//ul/li[@class="item-inactive"]/following::*')
result9 = selector.xpath('//li[1]/following-sibling::*')
result10 = selector.xpath('//li[1]/following::*[1]')
result11 = selector.xpath('//li[1]/descendant::*')
print(result9)
print(result10)
print(result11)
# [<Element li at 0x1da39fa4fc8>] [<Element a at 0x1da39fe7508>] [<Element span at 0x1da39fe7548>]
有用的链接
https://blog.csdn.net/qq_25343557/article/details/81912992?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase
https://blog.csdn.net/baidu_32542573/article/details/79675420
https://www.cnblogs.com/dxqNet/p/10136665.html
http://www.voidcn.com/article/p-cjeefole-btv.html














 867
867











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









