






绿色字体
红色字体
粉色字体
蓝色字体
需求:统计各个城市所属区域下最受欢迎的Top 3产品
需要用到窗口函数 (下面再说)
大数据处理:离线、实时(不管是离线还是实时,都要进行以下的步骤:)
input :HDFS、mysql、Hbase...... 处理之前肯定有数据输入进来(数据可以存放的位置)
处理(分布式) MapReduce/Hive/Spark/Flink 处理的方式有很多种
output :mysql、HDFS..... 处理之后肯定要输出到某个地方
本次案例中,从hdfs和mysql拿数据,然后用hive进行处理,然后输入到mysql中去。
本次需求:统计各个城市所属区域下最受欢迎的Top 3产品
我们可以查看一下电商网站,点击一个商品,(再浏览器里的开发者工具,查看一下列如:log。gif的日志,)会发现:
日志中会有:商品信息,比如城市ID,产品ID,用户信息,但是没有城市所属区域的名字和产品的名字。我么可以从日志中获取所需要的商品信息,但是城市的名称和产品的名称日志里是没有的。
一般固定的信息,不变的信息是存放在关系型数据库中的,比如:mysql中:
mysql下还会存放两张表格:
城市区域对应的表
产品信息表
Hive中存放的是:
用户点击行为的日志表
MySQL里有两张表,city_info城市信息表、product_info产品信息表:

city_info城市信息表:
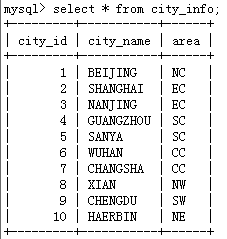
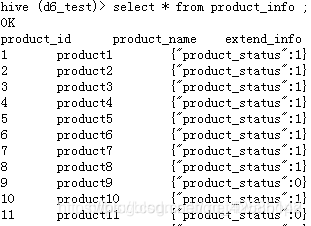
product_info产品信息表:
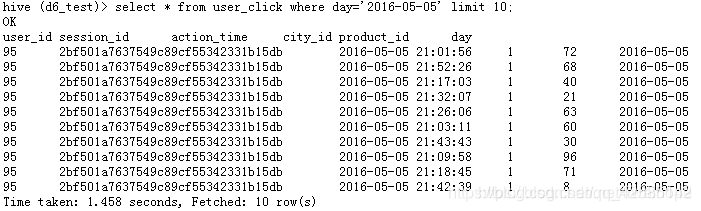
 在user_click.txt中有5列,第一列是用户id,第二列是session id 不需要关心,第三列是访问的时间,第四列是城市的id,第五列是产品的id。
在user_click.txt中有5列,第一列是用户id,第二列是session id 不需要关心,第三列是访问的时间,第四列是城市的id,第五列是产品的id。
现在用hive创建一张 用户点击行为日志表 :
create table user_click(
user_id int,
session_id string,
action_time string,
city_id int,
product_id int
) partitioned by (day string)
row format delimited fields terminated by ',';
然后加载数据进去:
load data local inpath '/home/hadoop/data/topn/user_click.txt' overwrite into
table user_click partition(day='2016-05-05');
就是说现在有三张表:city_info城市信息表、product_info产品信息表(MySQL),user_click用户点击行为日志表(hive)
现在需要在hive中操作这三张表,所以需要把MySQL中的两张表想办法弄到hive上来。在Hive里面完成我们的业务逻辑统计操作,在hive中处理过后再把处理的结果输出到MySQL中去。在这里就需要一个工具:Sqoop。
Sqoop也是个顶级项目。网址:http://sqoop.apache.org/

Sqoop:关系型数据库 <==> Hadoop
Sqoop是一个工具,可以在hadoop和关系型数据库之间高效的批量转移数据。就是把hadoop的数据
传输到关系型数据库,或者把关系型数据库的数据传输到hadoop上。
Sqoop有两个版本 :一和二
Sqoop: 1.4.7
Sqoop2: 1.99.7 (用的很少,不好用)
 下载Sqoop软件:
下载Sqoop软件:
 wget http://archive.cloudera.com/cdh5/cdh/5/sqoop-1.4.6-cdh5.7.0.tar.gz
wget http://archive.cloudera.com/cdh5/cdh/5/sqoop-1.4.6-cdh5.7.0.tar.gz
解压:
tar -zxvf sqoop-1.4.6-cdh5.7.0.tar.gz
解压之后把MySQL的驱动拷贝到lib目录下:
cp mysql-connector-java.jar sqoop-1.4.6-cdh5.7.0/lib/
配置:进入到/home/hadoop/app/sqoop-1.4.6-cdh5.7.0/conf 目录:
 vi sqoop-env.sh 编辑一下:
vi sqoop-env.sh 编辑一下:
加入这几行:
export HADOOP_COMMON_HOME=/home/hadoop/software/compile/hadoop-2.6.0-cdh5.7.0
export HADOOP_MAPRED_HOME=/home/hadoop/software/compile/hadoop-2.6.0-cdh5.7.0
export HIVE_HOME=/home/hadoop/app/hive-1.1.0-cdh5.7.0
 配置完后:
配置完后:
 配置一下环境变量:[hadoop@10-9-140-90 ~]$ vi .bash_profile 加入这两行:
配置一下环境变量:[hadoop@10-9-140-90 ~]$ vi .bash_profile 加入这两行:
export SQOOP_HOME=/home/hadoop/app/sqoop-1.4.6-cdh5.7.0
export PATH=$SQOOP_HOME/bin:$PATH
source生效一下。
然后就可以启动sqoop了:
 用 sqoop help 可以查看sqoop的用法:
用 sqoop help 可以查看sqoop的用法:
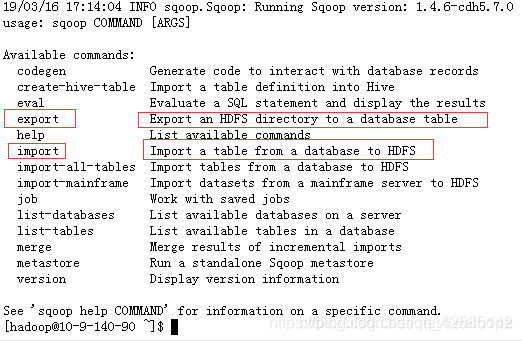
导入导出的出发点是Hadoop
导入(import): MySQL ==> Hadoop
导出(export): Hadoop ==> MySQL
可以 sqoop import --help 查看import的具体用法。
现在需要把MySQL上的城市区域信息和产品信息导入到hive中。
MySQL ==> Hive
需要先在hive中建立两张表:
create table city_info(
city_id int,
city_name string,
area string
)row format delimited fields terminated by '\t';
create table product_info(
product_id int,
product_name string,
extend_info string
)row format delimited fields terminated by '\t';
然后用sqoop工具把数据导入进来:
通过:sqoop import --help 看一下如何导入的。
sqoop import \
--connect jdbc:mysql://localhost:3306/ruozedata \
--username root --password 123456 \
--delete-target-dir \
--table city_info \
--hive-import \
--hive-table city_info \
--hive-overwrite \
--fields-terminated-by '\t' \
--lines-terminated-by '\n' \
--split-by city_id \
-m 2
看上面的语句,总结下来就是,前面先是连接到数据库、用户名、密码、表名,后面是 导入到hive、导入到hive的表名、重写、字段分隔符、行分隔符。
加delete-target-dir 是因为跑MapReduce的时候,如果指定的目录已经存在会报错,所以加上这个,如果目录存在就删除。
加split-by 是因为 在Sqoop里面默认的mapper数是4,它处理会以主键id进行区分,比如如果有40条记录,那么就是按照主键id进行分配,每个mapper处理10条数据。但是我们的表是没有主键的,所以在这里要手动指定一下。
-m 2 指定map的数量为2 m不指定的话就是4
导入的时候报错了:
Exception in thread “main” java.lang.NoClassDefFoundError: org/json/JSONObject
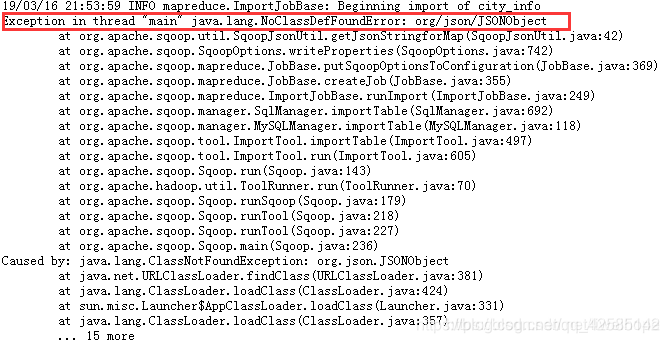
这是由于sqoop缺少java-json.jar包 导致的,下载这个jar包,然后放到/home/hadoop/app/sqoop-1.4.6-cdh5.7.0/lib/下即可。
下载:weget http://www.java2s.com/Code/JarDownload/java-json/java-json.jar.zip
下载后需要解压一下。
然后再运行import语句,发现还有错误:
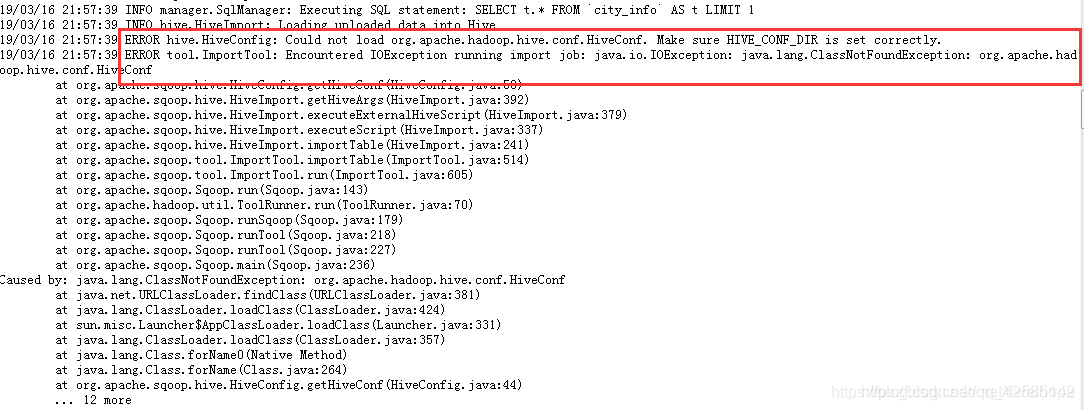 这是因为缺少hive下的hive-exec-1.1.0-cdh5.7.0.jar这个jar包导致的,需要把
这是因为缺少hive下的hive-exec-1.1.0-cdh5.7.0.jar这个jar包导致的,需要把
/home/hadoop/app/hive-1.1.0-cdh5.7.0/lib/hive-exec-1.1.0-cdh5.7.0.jar
拷贝到 ~/app/sqoop-1.4.6-cdh5.7.0/lib/ 下。
然后再运行语句,运行成功了,但是去d6_test数据库查还是没有,
仔细检查上面那个语句发现少了个 --hive-database d6_test \ ,
然后发现数据导入到default数据库里面了。
sqoop import \
--connect jdbc:mysql://localhost:3306/ruozedata \
--username root --password 123456 \
--delete-target-dir \
--table city_info \
--hive-import \
--hive-database d6_test \
--hive-table city_info \
--hive-overwrite \
--fields-terminated-by '\t' \
--lines-terminated-by '\n' \
--split-by city_id \
-m 2
然后就可以看到了:
 到现在 前期的准备工作已经做完,‘
到现在 前期的准备工作已经做完,‘
Hive中已经有三张表: city_info product_info user_click
下面要做的就是统计分析:
 先做一张 商品基础信息 表
先做一张 商品基础信息 表
create table tmp_product_click_basic_info
as
select u.product_id, u.city_id, c.city_name, c.area
from
(select product_id, city_id from user_click where day='2016-05-05' ) u
join
(select city_id, city_name,area from city_info) c
on u.city_id = c.city_id ;
再创建一张 各区域下各商品的访问次数 的表
create table tmp_area_product_click_count
as
select
product_id, area, count(1) click_count
from
tmp_product_click_basic_info
group by
product_id, area ;
再创建一张 获取完整的商品信息的各区域的访问次数 的表:
create table tmp_area_product_click_count_full_info
as
select
a.product_id, b.product_name, a.area, a.click_count
from
tmp_area_product_click_count a join product_info b
on a.product_id = b.product_id
最后需要一个窗口函数,根据区域进行分组,然后过滤:
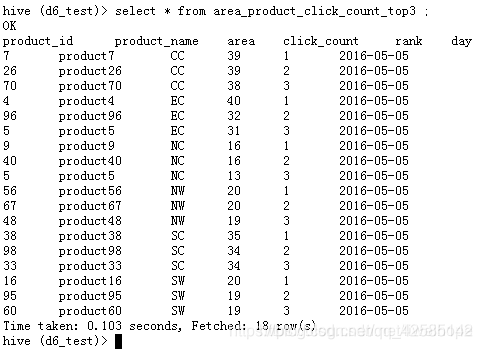
这个就是所要的结果:
create table area_product_click_count_top3 as
select t.*,‘2016-05-05’ as day
from (
select
product_id, product_name,area, click_count,
==row_number() over(partition by area order by click_count desc) rank ==(窗口函数,通过区域分区,再通过点击量排名)
from tmp_area_product_click_count_full_info
) t where t.rank <=3;(在获取最后的结果时,要将day带上,我们是通过分区建表的,最后当然要将day带上,这样才知道统计的是哪一天的。)
最后把统计结果输出到MySQL 用 sqoop export。
在MySQL中创建一张一样的表:
create table area_product_click_count_top3
(product_id int(11),
product_name varchar(255),
area varchar(255),
click_count int(11),
rank int(11),
day varchar(255))
ENGINE=InnoDB DEFAULT CHARSET=utf8;

然后用 sqoop export 把hive的这张表的数据导入进来。
用下面语句:
sqoop export \
--connect jdbc:mysql://localhost:3306/ruozedata \
--username root --password 123456 \
--table area_product_click_count_top3 \
--columns product_id,product_name,area,click_count,rank,day \
--export-dir /user/hive/warehouse/d6_test.db/area_product_click_count_top3 \
--input-fields-terminated-by '\001' \
-m 2
运行成功后,去mysql里看一下:
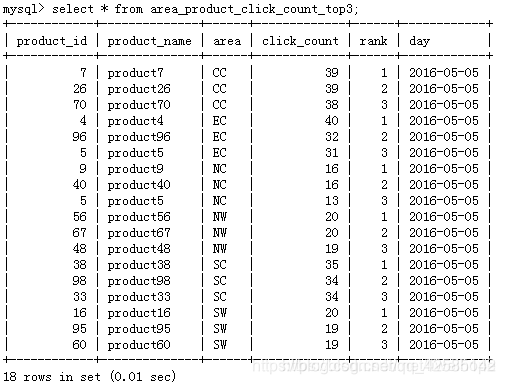 再重新运行一下上面的sqoop export 语句,再看:
再重新运行一下上面的sqoop export 语句,再看:
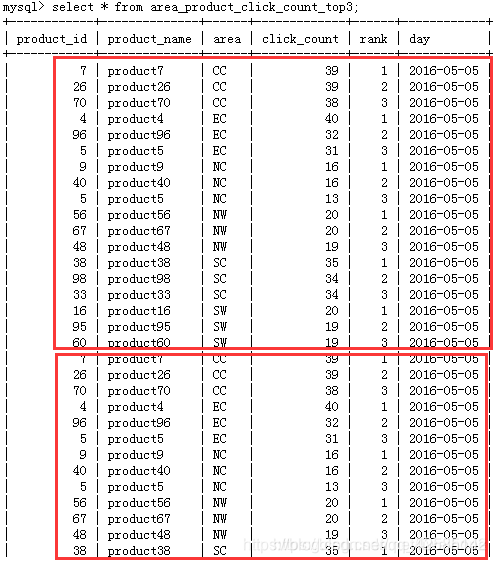 发现重复了。这时需要加上两行 去重:(下面蓝色标注)
发现重复了。这时需要加上两行 去重:(下面蓝色标注)
sqoop export
–connect jdbc:mysql://localhost:3306/ruozedata
–username root --password 123456
–table area_product_click_count_top3
–columns product_id,product_name,area,click_count,rank,day
–export-dir /user/hive/warehouse/d6_test.db/area_product_click_count_top3
–update-key product_id
–update-mode updateonly </font>
–input-fields-terminated-by ‘\001’
-m 2
另外:上面的过程如果每天需要处理,不可能每次都要像上面一样处理,需要把上面的整个过程放在shell脚本里面,每天凌晨去执行处理昨天的数据,这个就是离线处理。离线处理的时间一般都比较久,比如几小时、十几个小时等。
另外,上面很多group by 这可能会导致数据倾斜,那么数据倾斜应该怎么去解决???(面试必问)














 1274
1274











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









