







1 Excel表格自动化
使用Excel自动化处理,将会用到Python第三方库,所以我们需要提前通过pip3来进行安装。安装Python第三方库的命令如下:
pip3 install xlrd
pip3 install xlwt
pip3 install xlutils
pip3 install openpyxl
pip3 install pandas
这些第三方库的主要功能是对Excel表格进行不同的操作,其中会涉及一些重叠的功能,如多个第三方库都有对Excel工作簿进行读写的功能。之所以要介绍多个第三个库,主要原因在于不同第三方库的设计理念不同,因此不同的第三方库有其相应的特性与缺陷,只有多个第三方库配合使用,互补各自的缺陷,我们才可以完美地控制Excel表格。
为了避免歧义,下面使用Excel表示Excel软件本身,使用工作簿表示Excel文件,使用工作表表示Excel文件中的表格。
1.1 读写Excel数据
首先,我们来学习xlrd与xlwt这两个Python第三方库。
xlrd 的主要作用是读取工作簿中的数据,而xlwt 的主要作用是将数据写入工作簿中。
工作簿具有两种格式,分别是以*.xls为扩展名结尾的格式,以及以*.xlsx为扩展名结尾的格式,两种格式有本质的区别。
*.xls 是2003版工作簿使用的格式,它是一种具有特定规律的二进制格式文件,其核心结构是2003版Excel特有的复合文档类型结构;而*.xlsx是2007版及以后版本工作簿默认使用的格式,其核心结构是XML数据结构。相对于*.xls,*.xlsx的核心结构更加清晰,压缩后占用的空间更小。
此外,*.xls与*.xlsx的另一个重要的差异在于*.xls类型文件最多可写入 65535行、256列的数据量,而*.xlsx类型文件最多可写入1048576行、16384列的数据量(当存储的数据大于工作簿存储极限时,就可以考虑使用数据库来存储数据,如MySQL数据库)。
无论是*.xls类型的工作簿还是*.xlsx类型的工作簿,xlrd 都可以读取,但是xlwt只能将数据写入*.xls类型的工作簿中,这一点需要注意。
1.2 使用xlrd读取工作簿数据
使用 xlrd 读取工作簿中的数据可以分成以下3步:
- 使用
xlrd.open_workbook方法载入工作簿 - 使用
sheet_by_index等方法选取工作簿中的某个工作表 - 使用
cell_value方法获取工作表中某个单元格中的信息
(1)通过pip3 安装 xlrd 后,即可使用,代码如下:
# 导入 xlrd
import xlrd
# 1 读取xlsx
book = xlrd.open_workbook("./xlrd_excel.xlsx")
上述代码中,将 ./xlrd_excel.xlsx文件的具体路径作为xlrd.open_workbook方法的参数,从而将工作簿导入计算机内存中。如果 xlrd_excel.xlsx 文件与代码文件在相同目录,可以直接使用文件名(这其实是当前文件相对路径的写法)。
(2)一个工作簿至少由一个工作表组成,读入工作簿后,还要选择要处理的工作表。选择工作表的方式有多种,代码如下:
# 读取sheet
# 获取第1个sheet
sheet = book.sheets()[0]
# 获取第1个sheet
sheet = book.sheet_by_index(0)
# 选择名为 sheet1 的工作表
sheet = book.sheet_by_name("Sheet1")
一个工作簿至少有一个工作表构成,而一个工作表由多个单元格构成,单元格中存放具体的数据。工作表中的每个单元格都可以通过“行号+列号”的方式定位,在Python中,通常也通过“行号+列号”的方式来获取相应位置的单元格中的信息。示例代码如下:
# 读取表格
# sheet.cell_value(row, col)
data1 = sheet.cell_value(1, 0)
data2 = sheet.cell_value(0, 1)
print(f"data1: {data1}")
print(f"data2: {data2}")
上述代码中,通过cell 方法将行号与列号传入,可以获取对应位置单元格中的信息。需要注意,在通过 xlrd 操作工作表获取单元格信息时,单元格的行号与列号都以0作为起始值,而工作表中以1 作为起始值。
如果想要批量读取单元格中的信息,那么必然需要使用循环语句。在使用循环语句前,可能需要获取如下信息:
# 获取工作簿中的工作表数目
sheets_num = book.nsheets
# 获取工作簿中工作表名称列表
sheets_names = book.sheet_names()
# 获取工作表中有值单元格的行数
nrows = sheet.nrows
# 获取工作表中有值单元格列数
ncols = sheet.ncols
通过上述代码获取的数据,可以使用循环语句将整个工作簿中的所有工作表中的所有数据读取出来。
# 获取工作簿中所有的工作表
sheets = books.sheets()
for sheet in sheets:
# 获取工作表中有值单元格的行数
nrows = sheet.nrows
# 获取工作表中有值单元格列数
ncols = sheet.ncols
for row in range(0, nrows):
for col in range(0, ncols):
# 输出单元格中的内容
print(sheet.cell_value(row, col))
关于日期的读取
# 读入日期
time_value1 = sheet.cell_value(1, 6)
time_value2 = sheet.cell_value(2, 6)
因为Python中没有与工作簿中日期类型对应的数据类型,所以cell_value 方法会将日期类型根据相应的规则转为浮点型。
如果想要获取工作簿中原始的日期值,可以使用 xlrd.xldate_as_tuple方法或者xlrd.xldate_as_datetime方法。示例代码如下:
# 将读入的日期转换为元组的形式
# (2019, 5, 6, 12, 10, 32)
time_tuple = xlrd.xldate_as_tuple(time_value1, 0)
# 将日期数据转换为datetime对象
time_datetime = xlrd.xldate_as_datetime(time_value1, 0)
# 将datetime对象格式化转化为对应的字符串
# 2019-05-06
time_str = time_datetime.strftime("%Y-%m-%d %H:%M:%S")
xlrd.xldate_as_tuple 方法与 xlrd.xldate_as_datetime 方法本质上是通过读取日期数据计算出可用的日期数据,它们都针对于工作簿中的日期格式。如果工作簿中日期本身就是字符串型,那么则无法使用这两个方法。
需要注意的是,xlrd.xldate_as_tuple 方法与 xlrd.xldate_as_datetime 方法中的第二个参数可以取 0 或 1 。当取 0 时,这两个方法会以1900-01-01 为基准日期将当前获取的浮点型日期转为当前日期;当取 1 时,这两个方法会以 1904-01-01 为基准日期将当前获取的浮点型日期转为当前日期。
1.3 使用 xlwt 将数据写入工作簿
xlwt 将数据写入新工作簿需要4步:
- 实例化
xlwt.Workbook类,创建新工作簿 - 使用
add_sheet方法创建新工作表 - 使用
write方法将数据写入单元格 - 使用
save方法保存工作簿
(1)首先,创建空白的 *.xls 类型工作簿:
# 创建xls类型文件对象
book = xlwt.Workbook()
(2)一个工作簿至少要有一个工作表,创建一个新的工作表:
# 新建名为Sheet1的工作表
sheet = book.add_sheet("Sheet1")
(3)将数据写入对应的单元格:
# 写入数据到第一行第一列的单元格
# 按(row, col, value) 的方式添加数据
sheet.write(0, 0, "xlwt写入的数值")
(4)将写入了数据的新工作簿保存:
# 保存工作簿
book.save("./people2.xls")
xlwt 只支持 *.xls 格式的工作簿,如果在使用save 方法时,将工作簿存为 *.xlsx格式,程序在运行过程中并不会报错,但保存的 *.xlsx格式的工作簿将无法通过Excel打开。
此外,还需要注意xlwt 不允许对相同的单元格进行重复赋值:
# 按(row, col, value) 的方式添加数据
sheet.write(0, 0, "xlwt写入的数值")
# 重复对相同单元格赋值 程序会报错崩溃
sheet.write(0, 0, "写入的值")
1.4 使用 xlutils 修改工作簿数据
xlutils 依赖于 xlrd 与 xlwt ,它最常用的功能就是将 xlrd 的Book对象复制成 xlwt 的Workbook对象的目的,操作非常简单。
通过 xlutils 实现对工作簿的修改:
import xlrd
from xlutils.copy import copy
# 读入数据 获取Book对象
# 如果想连样式都一起复制,则需要将formatting_info的参数设置为True的格式
rd_book = xlrd.open_workbook("./xlutils_test.xlsx", formatting_info=True)
# 获取工作簿中第一个工作表 方便后续操作
rd_sheet = rd_book.sheets()[0]
# 复制Book对象为WorkBook对象
wt_book = copy(rd_book)
# 从workbook对象中获取Sheet对象
wt_sheet = wt_book.get_sheet(0)
# 循环处理每一行的第一列数据 修过其中的内容
for row in range(rd_sheet.nrows):
wt_sheet.write(row, 0, "修改内容")
wt_book.save("./xlutils_test_copy.xls")
2.1 操作大型工作簿
openpyxl 相较于 xlrd、xlwt,有更丰富的功能,通过openpyxl可以对工作簿进行读写及修改操作。此外,openpyxl同时支持*.xls与*.xlsx格式的工作簿,不用再考虑格式问题。
使用openpyxl 读取工作簿数据
要读取工作簿数据,首先应载入工作簿并选择对应的工作表:
import openpyxl
# 打开已有的 *.xlsx文件
wb = openpyxl.load_workbook("./openpyxl_excel.xlsx")
# 选择第一个工作表
ws = wb.worksheets[0]
# 获取第3行第2列的值
ws.cell(row=3, column=2).value
需要注意,openpyxl与xlrd、xlwt不同,cell方法中的row、column参数从1开始,即工作表中的行号、列号与Excel工作表一样,都以1作为起始坐标,而xlrd、xlwt 却以0作为起始坐标。
在openpyxl中,获取工作表的其他数据:
# 打开已有的 *.xlsx文件
wb = openpyxl.load_workbook("./openpyxl_excel.xlsx")
# 选择第一个工作表
ws = wb.worksheets[0]
# 返回sheet中有数据的最大行数
print('最大行数:',ws.max_row)
# 返回 sheet 中有数据的最小行数
print('最小行数:',ws.min_row)
# 返回 sheet 中有数据的最大列数
print('最大列数:',ws.max_column)
# 返回 sheet 中有数据的最小列数
print('最小列数:',ws.min_column)
openpyl提供了相应的方法让循环处理工作表的代码变得更加简单:
# 打开已有的 *.xlsx文件
wb = openpyxl.load_workbook("./openpyxl_excel.xlsx")
# 选择第一个工作表
ws = wb.worksheets[0]
# 遍历工作表中的部分区域
# 获取单元格中的值,可以利用 iter_cols 方法并将其中的 value_only 参数设置为True
for col in ws.iter_cols(min_col=3, max_col=5, max_row=2, values_only=True):
# 输出数据
print(col)
iter_cols方法中还使用了除values_only外的多个参数,其中min_col、max_col用于控制循环的列,min_row、max_row用于控制循环的行,它们默认都是从1开始计数的。
此外,openpyxl中直接通过ws.values属性也可以轻松获取整个工作表中的值:
# 获取工作表中所有的行的值,只读模式下不可用
# 返回一个生成器对象
all_values = ws.values
print(type(all_values))
for i, value in enumerate(all_values):
print(value)
if i == 3:
break
ws.values会返回一个生成器,这里通过 for 循环的形式获取其中的值。此外,代码中还使用了 enumerate方法,该方法会向当次循环值返回对应的下标,如在第一次for循环时,enumerate方法会返回0,此时变量i的值就为0。
2.2 使用openpyxl 将数据写入工作簿
通过实例化 openpyxl.Workbook 类来创建新的工作簿对象,然后,通过create_sheet方法创建新工作表,最后即可向其中添加数据:
# 创建工作簿
wb = openpyxl.Workbook()
# wb.active 默认返回第一个工作表
ws = wb.active
# 第一个工作表的名称
print(f"ws: title {ws.title}")
# 新建一个工作簿
ws2 = wb.create_sheet("new_sheet", 1)
# 修改title
ws2.title = "update_sheet"
# 添加内容
ws2.cell(row=5, column=1).value = "设置了一个值"
# 保存excel
wb.save("./openpyxl_excel.xlsx")
如果想修改已存在的工作簿,只需要将创建工作簿的openpyxl.Workbook方法替换为openpyxl.load_workbook方法即可:
# 修改工作簿
wb = openpyxl.load_workbook("./test.xlsx")
ws = wb.active
# 修改A2~C3区域的值
for row in ws['A2':'C3']:
for cell in row:
cell.value = "new value"
wb.save("test.xlsx")
2.3 修改工作簿中的单元格样式
openpyxl 可以修改工作表中单元格的样式,相关的方法都在 openpyxl.styles 中,主要分为以下几部分:
- Font : 修改字体、字体大小、字体颜色、字体样式等
- PatternFill:填充颜色、渐变色等
- Border:调整单元格边框等
- Alignment:单元格对齐方式等
(1)首先创建一个新的工作簿与工作表,并向其中写入一些内容,代码如下:
wb = openpyxl.Workbook()
ws = wb.active
rows = [
["id", "name", "age"],
[1, "张三", 13],
[2, "李四", 15],
[3, "王五", 18]
]
for row in rows:
# 添加到ws中
ws.append(row)
(2)通过Font 修改单元格中数据的字体,代码如下:
from openpyxl.styles import Font, colors
# 字体设为微软雅黑,字体大小25,斜体,红色
font = Font(name='微软雅黑', size=25, italic=True, color="FF0000", bold=True)
# 设置对应单元格的字体样式
ws['A1'].font = font
wb.save("./test2.xlsx")
(3)通过PatternFill 修改单元格背景填充颜色:
from openpyxl.styles import PatternFill
# 填充样式,将单元格背景色填充为绿色
fill = PatternFill(fill_type='solid', start_color="008000")
ws['B1'].fill = fill
(4)通过 Border 设置单元格边框样式:
from openpyxl.styles import Border,Side
# Border Side 设置单元格边框样式
border = Border(
left=Side(border_style="double", color="FFBB00"),
right=Side(border_style="double", color="FFBB01"),
top=Side(border_style="double", color="FFBB02"),
bottom=Side(border_style="double", color="FFBB03")
)
ws['C1'].border = border
(5) 通过 Alignment 设置单元格内容对齐方式:
from openpyxl.styles import Alignment
# Alignment 设置对其格式
align = Alignment(horizontal="left", vertical="center", wrap_text=True)
ws['D1'].alignment = align
(6) 通过openpyxl 设置单元格的行高与列宽:
# 修改单元格高度 和 长度
ws.row_dimensions[3].height = 40
ws.column_dimensions["A"].width = 30
(7) 通过 merge_cells 方法将要合并的区域传入即可:
# 合并一行中的几个单元格
ws.merge_cells("A7:C7")
# 合并一个矩形区域中的单元格
ws.merge_cells("A9:C13")
ws["A9"] = "合并单元格"
ws["A9"].comment = Comment(text="这是一个批注", author="二两")
wb.save("./test2.xlsx")
2.4 使用openpyxl 操作大型工作簿
为了读取大型工作簿中的数据或将大量数据写入工作簿,需要使用openpyxl 的 read_only 模式与 write_only 模式。
在 read_only 模式下,openpyxl可以使用恒定的内存来处理无限的数据,其原理就是先处理一部分数据,处理完后,释放占用的内存,然后继续读入部分数据进行处理。这种方式可以快速读取大型工作簿中的数据。但需要注意,在该模式下,不允许对工作表进行写操作。
使用 openpyxl 的 read_only 模式非常简单,只需要在使用 load_workbook 方法时将 read_only 参数设置为 True即可:
from openpyxl import load_workbook
# 在 read_only 模式下载入大型工作簿 big.xlsx
wb = load_workbook(filename="./big.xlsx",read_only=True)
# 选择big_sheet 工作表
ws = wb['big_sheet']
# 遍历工作表中的行
for row in ws.rows:
# 遍历每行中的每一列
for cell in row:
print(cell.value)
使用 write_only 模式只需要在实例化 Workbook类时,将 write_only参数设置为True即可:
from openpyxl import Workbook
from openpyxl.cell import WriteOnlyCell
from openpyxl.comments import Comment
from openpyxl.styles import Font
# write_only 设置为True
wb = Workbook(write_only=True)
# write_only 模式下不会包含任何工作表,需要使用 create_sheet方法自行创建
ws = wb.create_sheet()
# write_only 模式下,单元格想要具有样式,就只能使用WriteOnlyCell创建单元格
cell = WriteOnlyCell(ws, value='write_only状态写入的内容')
# 为单元格设置字体样式
cell.font = Font(name='微软雅黑', size=36)
# 插入Excel批注
cell.comment = Comment(text='这是一个批注', author='二俩')
# write_only模式下只能使用append方法添加数据
ws.append([cell, 2.333,None])
# 保存
wb.save('./write_only.xlsx')
注意,在write_only 模式下,不可以在任意位置使用 cell或iter_rows方法,在添加数据时只能使用appen方法。
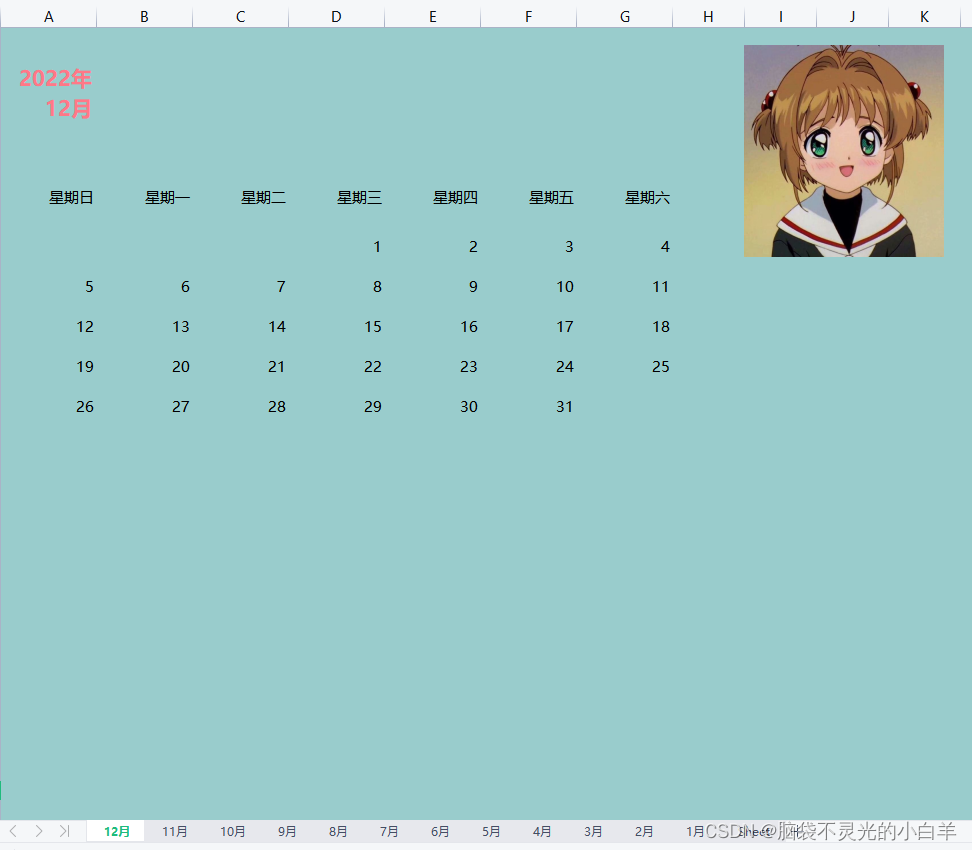
2.5 使用openpyxl 实现Excel日历
(1)使用 calendar 内置库来获取日历数据:
import calendar
import openpyxl
# 创建excel
wb = openpyxl.Workbook()
# 指定一周的第一天 0是星期一 6是星期天
calendar.setfirstweekday(firstweekday=6)
year = 2022
# 循环月份
for i in range(1, 13):
# 添加工作表 每个月份对应一个工作表
sheet = wb.create_sheet(index=0, title=str(i) + "月")
# 每月中的第一行 一行表示一周
for j in range(len(calendar.monthcalendar(year, i))):
# 每一天
for k in range(len(calendar.monthcalendar(year, i)[j])):
# 具体的日期
value = calendar.monthcalendar(year, i)[j][k]
wb.save("./test3.xlsx")
(2)将获取的日历数据写入工作表对应的位置、设置背景颜色、标注日期对应着星期几:
import calendar
from openpyxl.styles import Alignment,PatternFill,Font
import openpyxl
# 创建excel
wb = openpyxl.Workbook()
# 指定一周的第一天 0是星期一 6是星期天
from openpyxl.utils import get_column_letter
year = 2022
# 循环月份
for i in range(1, 13):
# 添加工作表 每个月份对应一个工作表
sheet = wb.create_sheet(index=0, title=str(i) + "月")
# 每月中的第一行 一行表示一周
for j in range(len(calendar.monthcalendar(year, i))):
# 每一天
for k in range(len(calendar.monthcalendar(year, i)[j])):
# 具体的日期
value = calendar.monthcalendar(year, i)[j][k]
if value == 0:
# 将0值变为空值 没有日期的单元格天空值
value = ''
sheet.cell(row=j + 9, column=k + 1).value = value
else:
# 将日期数据添加到具体的单元格中
sheet.cell(row=j + 9, column=k + 1).value = value
# 设置字体
sheet.cell(row=j + 9, column=k + 1).font = Font("微软雅黑", size=11)# 单元格文字设置,右对齐,垂直居中
# 单元格文字设置,右对齐,垂直居中
align = Alignment(horizontal='right', vertical='center')
# 单元格填充属性设置
fill = PatternFill("solid", fgColor="99CCCC")
# 对单元格进行颜色填充
for k1 in range(1,50):
for k2 in range(1,50):
sheet.cell(row=k1, column=k2).fill = fill
# 星期日开头
days = ["星期日", "星期一", "星期二", "星期三", "星期四", "星期五", "星期六"]
num = 0
# 添加星期几相关信息
for k3 in range(1, 8):
sheet.cell(row=8, column=k3).value = days[num]
# 设置样式
sheet.cell(row=8, column=k3).alignment = align
sheet.cell(row=8, column=k3).font = Font("微软雅黑", size=11)
# 设置列宽12
c_char = get_column_letter(k3)
sheet.column_dimensions[c_char].width = 12
num += 1
# 将日历所在单元格的行高都修改为30
for k4 in range(8, 15):
sheet.row_dimensions[k4].height = 30
wb.save("./test3.xlsx")
(3)将图片插入到工作表中:
import calendar
from openpyxl.styles import Alignment,PatternFill,Font
import openpyxl
from openpyxl.drawing.image import Image
# 创建excel
wb = openpyxl.Workbook()
# 指定一周的第一天 0是星期一 6是星期天
from openpyxl.utils import get_column_letter
year = 2022
# 循环月份
for i in range(1, 13):
# 添加工作表 每个月份对应一个工作表
sheet = wb.create_sheet(index=0, title=str(i) + "月")
# 每月中的第一行 一行表示一周
for j in range(len(calendar.monthcalendar(year, i))):
# 每一天
for k in range(len(calendar.monthcalendar(year, i)[j])):
# 具体的日期
value = calendar.monthcalendar(year, i)[j][k]
if value == 0:
# 将 0 值变为空值,没有日期的单元格填空值
value = ''
sheet.cell(row=j + 9, column=k + 1).value = value
# 设置字体
sheet.cell(row=j + 9, column=k + 1).font = Font(u'微软雅黑', size=11)
# 单元格文字设置,右对齐,垂直居中
align = Alignment(horizontal='right', vertical='center')
# 单元格填充属性设置
fill = PatternFill("solid", fgColor="99CCCC")
# 对单元格进行颜色填充
for k1 in range(1,50):
for k2 in range(1,50):
sheet.cell(row=k1, column=k2).fill = fill
# 星期日开头
days = ["星期日", "星期一", "星期二", "星期三", "星期四", "星期五", "星期六"]
num = 0
# 添加星期几相关信息
for k3 in range(1, 8):
sheet.cell(row=8, column=k3).value = days[num]
# 设置样式
sheet.cell(row=8, column=k3).alignment = align
sheet.cell(row=8, column=k3).font = Font("微软雅黑", size=11)
# 设置列宽12
c_char = get_column_letter(k3)
sheet.column_dimensions[c_char].width = 12
num += 1
# 将日历所在单元格的行高都修改为30
for k4 in range(8, 14):
sheet.row_dimensions[k4].height = 30
# 合并单元格
sheet.merge_cells('I1:P20')
# 添加图片
img = Image("./1.jpg")
# 设置图片大小
newSize = (200, 200)
img.width, img.height = newSize
# 顶部加一些距离
sheet.add_image(img, "I2")
wb.save("./test3.xlsx")
(4)至此,日历内容部分与图片部分就完成了,最后将年月文字添加到工作表中:
import calendar
from openpyxl.styles import Alignment,PatternFill,Font
import openpyxl
from openpyxl.drawing.image import Image
# 创建excel
wb = openpyxl.Workbook()
# 指定一周的第一天 0是星期一 6是星期天
from openpyxl.utils import get_column_letter
year = 2022
# 循环月份
for i in range(1, 13):
# 添加工作表 每个月份对应一个工作表
sheet = wb.create_sheet(index=0, title=str(i) + "月")
# 每月中的第一行 一行表示一周
for j in range(len(calendar.monthcalendar(year, i))):
# 每一天
for k in range(len(calendar.monthcalendar(year, i)[j])):
# 具体的日期
value = calendar.monthcalendar(year, i)[j][k]
if value == 0:
# 将0值变为空值 没有日期的单元格天空值
value = ''
sheet.cell(row=j + 9, column=k + 1).value = value
else:
# 将日期数据添加到具体的单元格中
sheet.cell(row=j + 9, column=k + 1).value = value
# 设置字体
sheet.cell(row=j + 9, column=k + 1).font = Font("微软雅黑", size=11)# 单元格文字设置,右对齐,垂直居中
align = Alignment(horizontal='right', vertical='center')
# 单元格填充属性设置
fill = PatternFill("solid", fgColor="99CCCC")
# 对单元格进行颜色填充
for k1 in range(1,50):
for k2 in range(1,50):
sheet.cell(row=k1, column=k2).fill = fill
# 星期日开头
days = ["星期日", "星期一", "星期二", "星期三", "星期四", "星期五", "星期六"]
num = 0
# 添加星期几相关信息
for k3 in range(1, 8):
sheet.cell(row=8, column=k3).value = days[num]
# 设置样式
sheet.cell(row=8, column=k3).alignment = align
sheet.cell(row=8, column=k3).font = Font("微软雅黑", size=11)
# 设置列宽12
c_char = get_column_letter(k3)
sheet.column_dimensions[c_char].width = 12
num += 1
# 将日历所在单元格的行高都修改为30
for k4 in range(8, 15):
sheet.row_dimensions[k4].height = 30
# 合并单元格
sheet.merge_cells('I1:P20')
# 添加图片
img = Image("./1.jpg")
# 设置图片大小
newSize = (200, 200)
img.width, img.height = newSize
# 顶部加一些距离
sheet.add_image(img, "I2")
# 添加年份及月份
sheet.cell(row=3, column=1).value = f"{year}年"
sheet.cell(row=4, column=1).value = str(i) + "月"
# 设置年份及月份文本样式
sheet.cell(row=3, column=1).font = Font("微软雅黑", size=16, bold=True, color="FF7887")
sheet.cell(row=4, column=1).font = Font("微软雅黑", size=16, bold=True, color="FF7887")
# 设置年份及月份文本对齐方式
sheet.cell(row=3, column=1).alignment = align
sheet.cell(row=4, column=1).alignment = align
wb.save("./test3.xlsx")
3.1 代替与超越Excel
Pandas概述
Pandas在操作Excel时,依赖于xlrd和xlwt。
要理解Pandas,就必须先理解Series和DataFrame.
Series是一种类似于一维数组的对象,它由一组数据(可支持各种NumPy数据类型),以及一组与之相关的数据标签(索引)组成。
DataFrame是Pandas中的一个表格型的数据结构,由一组有序的列构成,其中每一列都可以是不同的值类型。DataFrame即有行索引也有列索引,可以看作是由Series组成的字典。
DataFrame本身就是一种二维数据结构,其行与列都是Series,多个Series可以组成一个DataFrame。
使用Pandas创建Series:
import pandas as pd
# 实例化Series对象
s1 = pd.Series([1, 2, 3], index=[1, 2, 3], name="s1")
# 输出Series对象
print(s1)
# 输出Series对象的索引
print(s1.index)
# 输出Series对象中索引为1的值
print(s1[1])
# 输出结果
'''
1 1
2 2
3 3
Name: s1, dtype: int64
Int64Index([1, 2, 3], dtype='int64')
1
'''
使用Pandas创建DataFrame:
# 创建Series对象
s1 = pd.Series([1, 2, 3], index=[1, 2, 3], name="A")
s2 = pd.Series([10, 20, 30], index=[1, 2, 3], name="B")
s3 = pd.Series([100, 200, 300], index=[1, 2, 3], name="C")
# 创建Series对象实例化DataFrame对象
df = pd.DataFrame([s1, s2, s3])
print(df)
'''
1 2 3
A 1 2 3
B 10 20 30
C 100 200 300
'''
可以发现DataFrame对象中的每一行就是对应的Series对象。
如果Series对象想成为DataFrame对象中的列:
# 通过字典形式构建DataFrame对象
df2 = pd.DataFrame({
s1.name: s1,
s2.name: s2,
s3.name: s3
})
print(df2)
'''
A B C
1 1 10 100
2 2 20 200
3 3 30 300
'''
3.2 Pandas 自动操作Excel
通过read_excel方法可以轻松读取工作簿中相应工作表的数据,最基本的使用方法如下:
filepath = "people.xlsx"
# 读出工作簿名为Sheet1的工作表
people = pd.read_excel(filepath, sheet_name="Sheet1")
print(people)
如果不想从第一行开始读取工作表中的数据,可以使用 header 参数跳过指定行数。如果工作表中前几行本身就没有数据,则不需要使用 header 参数,因为Pandas 会自动跳过空行;但如果工作表中前几行数据,想要跳过这几行数据,则需要使用 header 参数:
# header = 2 表示从第3行开始 相当于跳过了第2行
people1 = pd.read_excel(filepath, header=2, sheet_name="Sheet1")
print(people1)
读取工作表中的部分数据,使用 skiprows 参数跳过开头几行数据,效果与 header 参数类似。此外,还可以使用 usecols 参数指定要读取列的范围:
# skiprows 跳过开头几行 usecols表示使用哪些列的数据
people3 = pd.read_excel(filepath, sheet_name="Sheet1", skiprows=4, usecols="B:C")
print(people3)
Pandas 会将读取的工作表转为 DataFrame 对象,此时会产生 DataFrame 默认的索引,如果不想使用默认索引,可以通过 index_col 参数指定某列为 DataFrame 的索引。此外,还可以通过dtype 参数设置读取 DataFrame 对象中对应列的数据类型:
# 指定id列为索引 dtype设置某一列数据的类型
people2 = pd.read_excel(filepath, sheet_name="Sheet1", index_col="id", dtype={"name": str, "data": str})
print(people2)
如果不设置 dtype 参数,Pandas 在遇到 NaN 数据(空数据)时 会将其类型转为64位浮点型,在后续操作时,就无法将其指定为64 位整型。为了避免出现这种情况,通常会先将数据类型指定为字符串型。
Pandas 可以将DataFrame 对象直接保存为工作表,DataFrame 中的每一行数据会作为工作表中的一行:
import pandas as pd
# 通过字典形式构建DataFrame
df = pd.DataFrame({
"id": [1, 2, 3],
"name": ["张三", "李四", "王五"],
"age": [26, 50, 30]
})
# 自定义索引
df = df.set_index("id")
print(df)
df.to_excel("people_result.xlsx")
利用 Pandas 将左表的形式转为右表的形式:
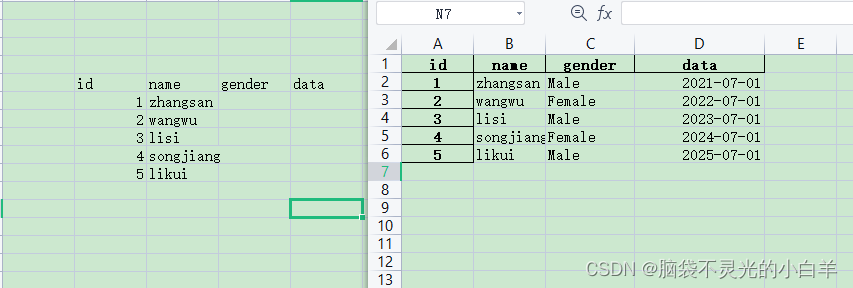
people = pd.read_excel("./people2.xlsx", skiprows=4, usecols="B:E", dtype={
"id": str,
"name": str,
"gender": str,
"data": str
})
将工作表读取成DataFrame对象后,就可以对其进行各种操作,代码如下:
from datetime import date, timedelta
# 开始日期
startday = date(2021, 7, 1)
for i in people.index:
# 累加ID
people.at[i, "id"] = i + 1
# 判断性别
people.at[i, "gender"] = "Male" if i % 2 == 0 else "Female"
# 计算生日时间
people.at[i, "birthday"] = date(startday.year + i, startday.month, startday.day)
# inplace 表示就地修改 DateFrame 不必再重新创建一个新的DateFrame来存储修改后的状态
people.set_index("id", inplace=True)
people.to_excel("people2_result.xlsx")
如果需要对工作表中的某一列进行相同的修改,比如对某一列进行 +3000 的操作,在Pandas 中可以很方便的实现:
import pandas as pd
filepath = "people.xlsx"
peoples = pd.read_excel(filepath, index_col='id')
# 加数
def add_1000(x):
return x + 1000
# Series 对象加add_1000
peoples['data'] = peoples['data'] + 1000
# apply 会逐个元素地调用函数
peoples['data'] = peoples['data'].apply(add_1000)
# apply 会逐个元素地调用匿名函数
peoples['data'] = peoples['data'].apply(lambda x: x + 1000)
peoples.to_excel('people3.xlsx')
3.3 使用Pandas 实现工作表中的数据排序
Pandas 可以通过 sort_values 方法实现数据排序,而如果要对工作表中的数据进行排序,只是多了读入工作表中的数据这一步。
假设要对公司员工的工资进行排序,并找出工资最高的那个员工:
import pandas as pd
# 数据排序
peoples = pd.read_excel("people.xlsx", index_col="id")
# by是根据字段 inplace就地执行 ascending为False是从大到小
peoples.sort_values(by="工资", inplace=True, ascending=False)
print(peoples)
print("============================")
'''
名称 工资 靠谱
id
5 likui 44 no
4 songjiang 33 no
3 lisi 14 yes
2 wangwu 13 no
1 zhangsan 12 yes
'''
在上述代码中,通过 sort_values 方法实现排序。其中,by参数指定工作表中要排序的列; inplace 参数为True,表示排序操作就地执行;ascending 参数用于指定排序的方式,False 表示从大到小排序。
现在要将员工做事情不靠谱且工资较高的几个人开除,如何通过排序找到这几个人呢?只需要通过 sort_values方法对多列进行排序即可:
# 多列排序
peoples = pd.read_excel("people.xlsx", index_col="id")
peoples.sort_values(by=["靠谱", "工资"], inplace=True, ascending=[True, False])
print(peoples)
print("============================")
'''
名称 工资 靠谱
id
5 likui 44 no
4 songjiang 33 no
2 wangwu 13 no
3 lisi 14 yes
1 zhangsan 12 yes
'''
3.4 使用 Pandas 实现Excel 数据过滤
Pandas 的过滤机制非常简单,假如需要将表中分数大于或等于 60 分的女性数据,以及分数在 50~90 分且年龄在 20~30岁的男性过滤出来,如果表中有缺失的数据,在进行数据处理时,需要通过 Pandas 的 dropna 方法将缺失数据对应的行删除,避免影响后续操作。
import pandas as pd
peoples = pd.read_excel('people.xlsx', index_col='ID')
# 检查 peoples DataFrame中是否有NaN
print(peoples.isnull().any())
# 清除NaN的行
peoples.dropna(inplace=True)
空数据处理完成后,接着过滤出分数大于或等于60分的女性数据:
# 分数及格的女性(大于或等于 60 分)
pass_womans = peoples[(peoples['性别'] == 'F') & (peoples['分数'] >= 60)]
print(pass_womans)
上述代码中,peoples 对象直接利用中括号语法将对应的条件写入其中,通过小括号隔离不同条件,通过“&” 符号(“&”符号表示多个条件需同时满足)连接多个条件。
过滤完满足条件的女性数据后,接着过滤 50~90分的20~30岁的男性数据。这里除可以使用上述过滤方式外,还可以使用 loc 属性,该属性会将满足条件的数据保留:
def score_50_to_90(a):
return 50 <= a < 90
def age_20_to_30(a):
return 20 <= a < 30
# 50~90 分的20~30 岁的男性
mans_50_to_90 = peoples[peoples['性别'] == 'M'].loc[
peoples['分数'].applying(score_50_to_90).loc[peoples['年龄'].apply(age_20_to_30)]]
print(mans_50_to_90)
3.5 使用 Pandas实现Excel数据拆分
假如想将工作表中某列的数据拆分成多列,例如对 “姓名“这一列,将其拆分为“姓氏”和“名字”两列。
在 Pandas 中,可以使用 str.split 方法对列进行拆分,该方法默认以空格为拆分标识:
import pandas as pd
peoples = pd.read_excel("people.xlsx")
# 将FullName拆分成 姓氏 和 名字 列
df = peoples["Full Name"].str.split(expand=True)
# 创建 姓氏 列
peoples["姓氏"] = df[0]
# 创建 名字 列
peoples["名字"] = df[1]
print(peoples)
print("===================")
'''
id Full Name 姓氏 名字
0 1 Carig Davis Carig Davis
1 2 Samantha Montoya Samantha Montoya
2 3 Ivan Montgomery Ivan Montgomery
3 4 Allen Smith Allen Smith
4 5 Mark Dominguez Mark Dominguez
'''
expand 参数设置为 True,这会返回包含拆分后的数据的DataFrame对象;如果设置为False,则会返回Series对象,Series对象中的每个元素都是一个列表,列表中包含拆分结果。
3.6 使用 Pandas 实现多表联合操作
假设现在有3个工作簿,依次为 Student、score 和 age,每个工作簿中各有一个工作表,每个工作表中均有ID 这一列,3个工作表中每一行数据都是相互对应的,现在需要获取年龄大于 20 岁且分数大于 60 分的学生姓名。
(1)首先需要合并3个工作簿中的工作表:
# 多表联合
# 学生姓名表
students = pd.read_excel("student.xlsx", sheet_name="Sheet1")
# 分数表
score = pd.read_excel("score.xlsx", sheet_name="Sheet1")
# 年龄表
age = pd.read_excel("age.xlsx", sheet_name="Sheet1")
# 合并
# fillna 将 NaN 填充为0
table = students.merge(score, how="left", on="id").fillna(0)
table["分数"] = table["分数"].astype(int)
table2 = table.merge(age, how="left", on="id").fillna(0)
table2["年龄"] = table2["年龄"].astype(int)
print(table2)
print("===================")
'''
id 名称 分数 年龄
0 1 Carig Davis 83 22
1 2 Samantha Montoya 44 33
2 3 Ivan Montgomery 99 15
3 4 Allen Smith 0 17
4 5 Mark Dominguez 87 18
'''
how 参数用于指定合并方式,当参数设置为 left,为左合并,设当参数置为right,为右合并,不设置任何参数,students与score两个DataFrame会取交集合并。
除了 how 参数外,在使用 merge 方法时还设置了 on 参数,该参数用于设置合并的列, students与score 两者都有ID列,所以指定ID列作为合并列。
如果 students 与 score 中不存在相同名称的列,可以使用 left_on 指定左表用于合并的列,以及使用 right_on 指定右表用于合并的列:
# 读取时 将id设置为index 读入的DataFrame对象中就不存在名为id的列
students = pd.read_excel("student.xlsx", sheet_name="Sheet1", index_col="id")
score = pd.read_excel("score.xlsx", sheet_name="Sheet1", index_col="id")
# DataFrame中没有名为ID 的列就无法使用 on = ID,可使用left_on或right_on
table = students.merge(score, how="left", left_on=students.index, right_on=score.index).fillna(0)
print(table)
合并3个工作簿中的工作表后,就可以轻松过滤出满足条件的内容:
pass_womans = table2[(table2['年龄']) >= 20]&(table2['分数'] >= 60)
print(pass_womans['名称'])
3.7 使用 Pandas 对 Excel 数据进行统计运算
Pandas 中可以轻松通过 sum、mean等方法对 DataFrame 中的数据进行统计运算,想要用好这些方法,需要理解一个重要的参数:axis 参数。
axis 参数在二维DataFrame中的作用理解为:axis = 0 将作用于每列中的所有行,axis = 1 将作用于每行中的所有列。
import pandas as pd
# 统计运算基础
df = pd.DataFrame(
[[1, 1, 1, 1], [2, 2, 2, 2], [3, 3, 3, 3]],
columns=["col1", "col2", "col3", "col4"]
)
print(df)
print("=====")
'''
col1 col2 col3 col4
0 1 1 1 1
1 2 2 2 2
2 3 3 3 3
'''
# mean 方法用来求某一行或列的平均数
result = df.mean(axis=1)
print(result)
print("======")
'''
0 1.0
1 2.0
2 3.0
dtype: float64
'''
# 删除某一行 或者 某一列
result = df.drop("col4", axis=1)
print(result)
print("======")
'''
col1 col2 col3
0 1 1 1
1 2 2 2
2 3 3 3
'''
# axis=1将作用于每行中的所有列
# axis=0将作用于每列中的所有行
理解 axis 参数后,对工作表中的数据进行求和、求平均运算:
# 多种运算
peoples = pd.read_excel("peoples.xlsx", index_col="id")
column_name = ["小测1", "小测2", "小测3"]
# 对每一行中的每一列进行求和
row_sum = peoples[column_name].sum(axis=1)
# 对每一行中的每一列进行求平均值
row_mean = peoples[column_name].mean(axis=1)
total = "总分"
average = "平均分"
peoples[total] = row_sum
peoples[average] = row_mean
column_name += [total, average]
# axis默认为0 对每一列中的每一行进行求平均操作
col_mean = peoples[column_name].mean()
col_mean["名称"] = "Summary"
# append 方法添加新的一行 ignore_index为True表示忽略index
peoples = peoples.append(col_mean, ignore_index=True)
print(peoples)
print("======")
'''
名称 小测1 小测2 小测3 总分 平均分
0 Carig Davis 88.0 100.0 88.0 276.0 92.000000
1 Samantha Montoya 30.0 76.0 35.0 141.0 47.000000
2 Ivan Montgomery 55.0 99.0 55.0 209.0 69.666667
3 Allen Smith 90.0 90.0 30.0 210.0 70.000000
4 Mark Dominguez 76.0 70.0 99.0 245.0 81.666667
5 Summary 67.8 87.0 61.4 216.2 72.066667
'''
此外,Pandas 还提供了很多类似的统计计算方法:
# 非空元素计算
peoples.count()
# 最小值
peoples.min()
# 最大值
peoples.max()
# 最小值的位置
# peoples.idxmin()
# 最大值的位置
# peoples.idxmax()
# 10%分位数
peoples.quantile(0.1)
# 求和
peoples.sum()
# 均值
peoples.mean()
# 中位数
peoples.median()
# 众数
peoples.mode()
# 方差
peoples.var()
# 标准差
peoples.std()
# 平均绝对偏差
peoples.mad()
# 偏度
peoples.skew()
# 峰度
peoples.kurt()
# 一次性输出多个描述性统计指标
peoples.describe()
3.8 使用 Pandas 实现数据的可视化
Pandas 绘制图表依赖于Matplotlib 第三方库,Matplotlib 是 Python中知名的数据可视化库,常用于2D图像绘制,是大多数Python数据可视化库的基础库,需要通过pip3进行安装:
pip3 install matplotlib
(1)首先来绘制柱状图,因为在 Matplotlib 库中绘制柱状图本身就是一个简单的操作,所以Pandas 没有对其进行再次封装,直接使用 Matplotlib 绘制即可:
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
students = pd.read_excel("students.xlsx")
name = "名称"
score = "分数"
age = "年龄"
# sort_values 方法排序 inplace表示原地修改 ascending=False表示从大到小
students.sort_values(by=score, inplace=True, ascending=False)
# 绘制成柱状图
plt.bar(students[name], students[score], color="orange")
# Font Properties 文字属性
# 传入字体路径 实例化对应的字体
myfont = FontProperties(fname="C:/Windows/Fonts/SimHei.ttf")
# 指定渲染字体
# 标题
plt.title("学生分数", fontproperties=myfont, fontsize=16)
# x轴
plt.xlabel(name, fontproperties=myfont)
# y轴
plt.ylabel(score, fontproperties=myfont)
# x旋转一下 方便显示名字
plt.xticks(students[name], rotation=90)
# 紧凑型布局
plt.tight_layout()
plt.show()
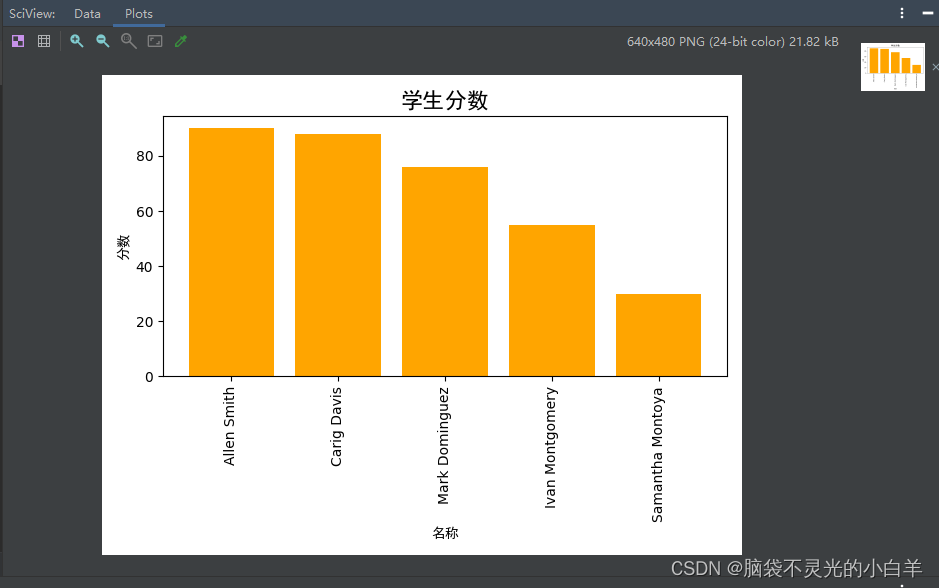
需要注意的是 Matplotlib 默认字体是不支持中文的,如果要显示成中文,需要引入相应的字体。
# Font Properties 文字属性
from matplotlib.font_manager import import FontProperties
# 传入字体路径,实例化对应的字体,SimHei.ttf表示黑体
myfont = FontProperties(fname="C:/Windows/Fonts/SimHei.ttf")
# 指定渲染字体
plt.title("学生分数",fontproperties = myfont,fontsize = 16)
plt.xlabel(name,fontproperties = myfont)
plt.ylabel(score,fontproperties = myfont)
plt.xticks(students[name],rotation='90')
plt.tight_layout()
plt.show()
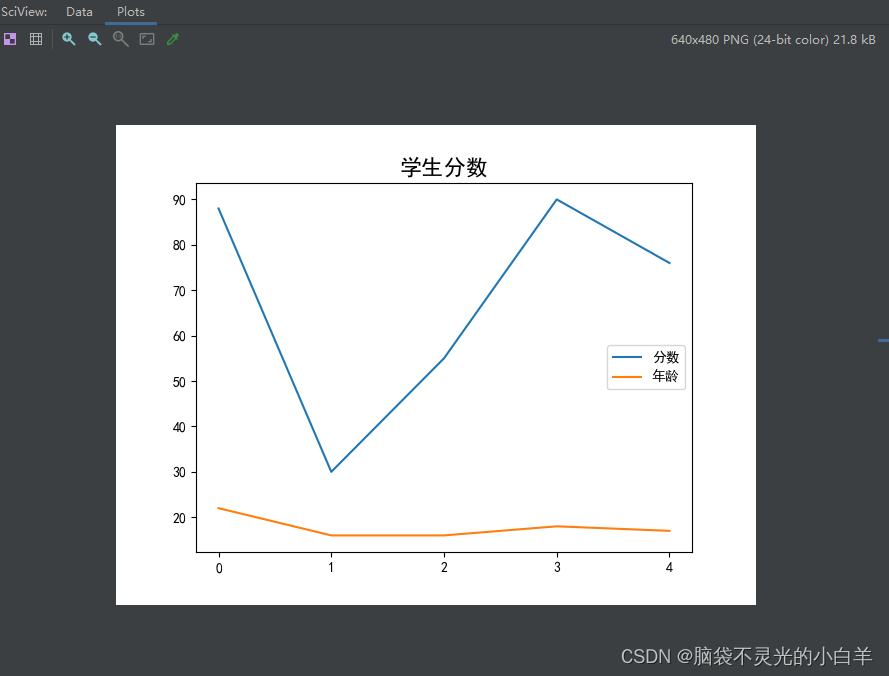
(2)绘制折线图:
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
students = pd.read_excel("students.xlsx")
name = "名称"
score = "分数"
age = "年龄"
# 指定默认字体 正常显示中文版标签
plt.rcParams["font.sans-serif"] = ["SimHei"]
# 解决负号 显示为方块的问题
plt.rcParams["axes.unicode_minus"] = False
# 传入字体路径 实例化对应的字体
myfont = FontProperties(fname="C:/Windows/Fonts/SimHei.ttf")
# 绘制折线图
students.plot(y=[score, age])
plt.title("学生分数", fontproperties=myfont, fontsize=16, fontweight="bold")
# 重绘x轴坐标
plt.xticks(students.index)
plt.show()
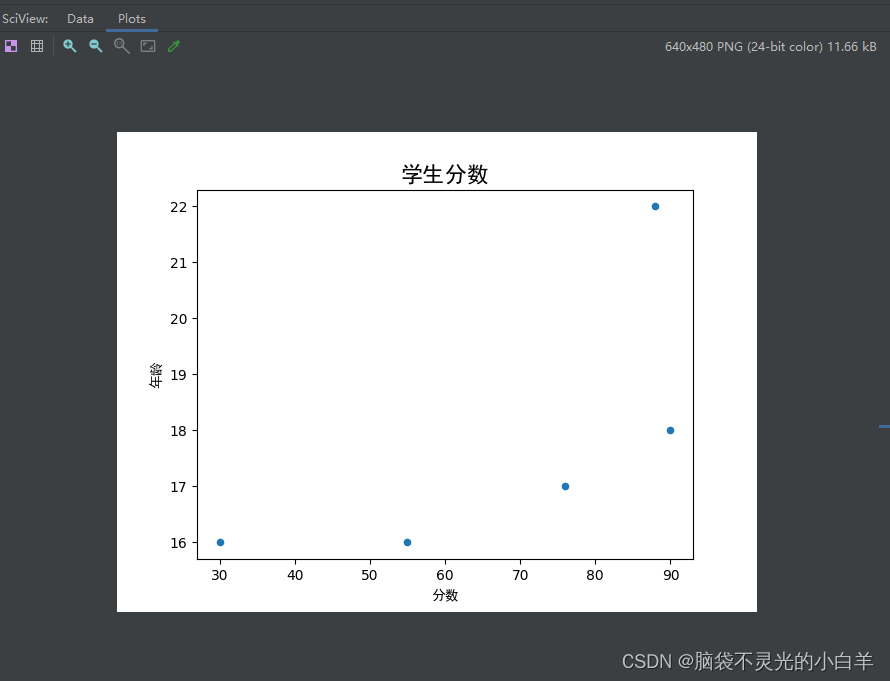
(3)绘制散点图,散点图通常用于判断绘制值之间的关系,这里使用学生体重与身高数据来绘制散点图:
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
students = pd.read_excel("students.xlsx")
score = "分数"
age = "年龄"
# 传入字体路径 实例化对应的字体
myfont = FontProperties(fname="C:/Windows/Fonts/SimHei.ttf")
# 绘制散点图
students.plot.scatter(x=score, y=age)
plt.title("学生分数", fontsize=16, fontweight="bold", fontproperties=myfont)
plt.xlabel(score, fontproperties=myfont)
plt.ylabel(age, fontproperties=myfont)
plt.show()
扩展知识:
简单了解 Matplotlib 在载入字体时的默认行为。
首先,通过 matplotlib_fname 方法找到当前Python环境中Matplotlib 库配置文件的目录:
import matplotlib
print(matplotlib.matplotlib_fname())
根据 matplotlib_fname() 方法输出的内容可知配置文件所在的目录,进入 mpl_data 文件夹,可以发现该文件下存在 fonts/ttf 目录,而该目录中保存了 Matplotlib 默认可以使用的字体文件。 Matplotlib 会利用这些字体文件以及系统中已有的字体生成 *.json格式的配置文件,并存放在缓存目录中,当用户使用 Matplotlib 时会自动载入该配置文件,具体代码逻辑在 matplotlib/font_manager.py 中.
为了让 Matplotlib 支持中文,首先要将缓存目录下的 *.json 配置文件删除,不同系统的缓存目录不同,具体如下(username 表示系统当前用户名)
Linux:/.cache/matplotlib/
Windows:C:\Users\username.matplotlib
macOS:/Users/usersname/.matplotlib/
将缓存目录中名为 fontlist-v*.json 的配置文件删除,然后将下载好的字体安装到系统字体中,
再次使用 Matplotlib 时会生成新的 fontlist-v*.json 配置文件,此时就可以在代码中使用安装好的字体:
import pandas as pd
import matplotlib.pyplot as plt
# 指定默认字体
plt.rcParams['font.sana-serif']=['SimHei']
# 解决负号 “-”显示为方块的问题
plt.rcParams['axes.unicode_minus']=Fales














 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









