







《博主简介》
小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。
✌更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~
👍感谢小伙伴们点赞、关注!
《------往期经典推荐------》
二、机器学习实战专栏【链接】,已更新31期,欢迎关注,持续更新中~~
三、深度学习【Pytorch】专栏【链接】
四、【Stable Diffusion绘画系列】专栏【链接】
五、YOLOv8改进专栏【链接】,持续更新中~~
六、YOLO性能对比专栏【链接】,持续更新中~
《------正文------》
基本功能演示
基于YOLOv10/YOLOv9/YOLOv8深度学习的蔬菜目标检测与识别系统【python源码+Pyqt5界面+数据集+训练代码】深度学习实战、目标检测、卷积
摘要:
蔬菜目标检测与识别系统的开发与应用对提高蔬菜的流通效率和保障食品安全具有巨大的价值,不仅能提高生产效率和蔬菜质量,还能降低成本,优化物流,给消费者提供更好的购买体验。本文基于YOLOv10/YOLOv9/YOLOv8深度学习框架,通过5477张不同种类蔬菜的相关图片,分别训练了可进行不同蔬菜种类目标检测的模型,可以对12种类别的蔬菜进行实时检测识别,同时全面对比分析了YOLOv8n、YOLOv9t、YOLOv10n这3种模型在验证集上的评估性能表现。最终基于训练好的模型制作了一款带UI界面的蔬菜目标检测与识别系统,更便于进行功能的展示。该系统是基于python与PyQT5开发的,支持图片、视频以及摄像头进行目标检测,并保存检测结果。本文提供了完整的Python代码和使用教程,给感兴趣的小伙伴参考学习,完整的代码资源文件获取方式见文末。
文章目录
前言
研究背景
蔬菜目标检测与识别系统的开发与应用对提高蔬菜的流通效率和保障食品安全具有巨大的价值。通过YOLOv10/YOLOv9/YOLOv8深度学习框架训练目标检测模型,使得该系统能够实时准确地识别和分类不同种类的蔬菜,这对于自动化生产线的优化、减少人工成本、提高产品质量以及增强消费者信心非常重要。
其主要应用场景包括:
农业自动化:在自动化农场管理中,用于识别成熟度和健康状态,实现精准农业。
食品加工:在加工过程中辨别不同种类的蔬菜,帮助自动分类和分拣。
零售管理:在超市或蔬菜店内,识别不同类别的蔬菜,帮助自动结账和库存管理。
线上零售:在电子商务平台中,精确识别和描述上架的蔬菜产品,提高购物体验。
消费者教育:帮助消费者识别和了解不同种类的蔬菜,提升其营养认知和购买决策。
餐饮业使用:在餐饮业中,用于管理库存,确保菜品的新鲜度和品质。
数据分析:为农业生产和供应链管理提供数据支持,助力市场分析和策略制定。
总结来说,蔬菜目标检测与识别系统极大地推动了信息技术在农业领域的应用,增强了从农田到餐桌整个环节的智能化水平。这不仅能提高生产效率和蔬菜质量,还能降低成本,优化物流,给消费者提供更好的购买体验。随着技术的不断进步,未来此类系统将在全球食品产业链中发挥越来越关键的作用。
主要工作内容
本文的主要内容包括以下几个方面:
搜集与整理数据集:搜集整理实际场景中不同蔬菜的相关数据图片,并进行相应的数据处理,为模型训练提供训练数据集;训练模型:基于整理的数据集,根据最前沿的YOLOv10/YOLOv9/YOLOv8目标检测技术训练目标检测模型,实现对需要检测的对象进行实时检测功能;模型性能对比:,对训练出的3种模型在验证集上进行了充分的结果评估和对比分析,主要目的是为了揭示每个模型在关键指标(如Precision、Recall、mAP50和mAP50-95等指标)上的优劣势。这不仅帮助我们在实际应用中选择最适合特定需求的模型,还能够指导后续模型优化和调优工作,以期获得更高的检测准确率和速度。最终,通过这种系统化的对比和分析,我们能更好地理解模型的鲁棒性、泛化能力以及在不同类别上的检测表现,为开发更高效的计算机视觉系统提供坚实的基础。可视化系统制作:,基于训练出的目标检测模型,搭配Pyqt5制作的UI界面,用python开发了一款界面简洁的水果质量好坏智能检测系统,可支持图片、视频以及摄像头检测,同时可以将图片或者视频检测结果进行保存。其目的是为检测系统提供一个用户友好的操作平台,使用户能够便捷、高效地进行检测任务。通过图形用户界面(GUI),用户可以轻松地在图片、视频和摄像头实时检测之间切换,无需掌握复杂的编程技能即可操作系统。这不仅提升了系统的可用性和用户体验,还使得检测过程更加直观透明,便于结果的实时观察和分析。此外,GUI还可以集成其他功能,如检测结果的保存与导出、检测参数的调整,从而为用户提供一个全面、综合的检测工作环境,促进智能检测技术的广泛应用。
软件初始界面如下图所示:

检测结果界面如下:

一、软件核心功能介绍及效果演示
软件主要功能
1. 可用于实际场景中12种不同蔬菜检测识别,12个检测类别分别是'甜菜', '甜椒', '卷心菜', '胡萝卜', '黄瓜', '鸡蛋','茄子','大蒜','洋葱','土豆','西红柿','西葫芦';
2. 支持图片、视频及摄像头进行检测,同时支持图片的批量检测;
3. 界面可实时显示目标位置、目标总数、置信度、用时等信息;
4. 支持图片或者视频的检测结果保存;
5. 支持将图片的检测结果保存为csv文件;
界面参数设置说明

置信度阈值:也就是目标检测时的conf参数,只有检测出的目标置信度大于该值,结果才会显示;
交并比阈值:也就是目标检测时的iou参数,只有目标检测框的交并比大于该值,结果才会显示;
检测结果说明

显示标签名称与置信度:表示是否在检测图片上标签名称与置信度,显示默认勾选,如果不勾选则不会在检测图片上显示标签名称与置信度;
总目标数:表示画面中检测出的目标数目;
目标选择:可选择单个目标进行位置信息、置信度查看。
目标位置:表示所选择目标的检测框,左上角与右下角的坐标位置。默认显示的是置信度最大的一个目标信息;
主要功能说明
功能视频演示见文章开头,以下是简要的操作描述。
(1)图片检测说明
点击打开图片按钮,选择需要检测的图片,或者点击打开文件夹按钮,选择需要批量检测图片所在的文件夹,操作演示如下:
点击目标下拉框后,可以选定指定目标的结果信息进行显示。
点击保存按钮,会对检测结果进行保存,存储路径为:save_data目录下,同时会将图片检测信息保存csv文件。
注:1.右侧目标位置默认显示置信度最大一个目标位置,可用下拉框进行目标切换。所有检测结果均在左下方表格中显示。
(2)视频检测说明
点击视频按钮,打开选择需要检测的视频,就会自动显示检测结果,再次点击可以关闭视频。
点击保存按钮,会对视频检测结果进行保存,存储路径为:save_data目录下。
(3)摄像头检测说明
点击打开摄像头按钮,可以打开摄像头,可以实时进行检测,再次点击,可关闭摄像头。
(4)保存图片与视频检测说明
点击保存按钮后,会将当前选择的图片【含批量图片】或者视频的检测结果进行保存,对于图片图片检测还会保存检测结果为csv文件,方便进行查看与后续使用。检测的图片与视频结果会存储在save_data目录下。
【注:暂不支持视频文件的检测结果保存为csv文件格式。】
保存的检测结果文件如下:

图片文件保存的csv文件内容如下,包括图片路径、目标在图片中的编号、目标类别、置信度、目标坐标位置。
注:其中坐标位置是代表检测框的左上角与右下角两个点的x、y坐标。

二、YOLOv8/YOLOv9/YOLOv10简介
YOLO(You Only Look Once)是一种流行的计算机视觉算法,用于实现实时对象检测。它由Joseph Redmon等人首次在2015年提出,并随后进行了多次改进。YOLO的核心思想是将整个图像划分为一个固定数量的格子(grid cells),然后在每个格子内同时预测多个边界框(bounding boxes)和类别概率。
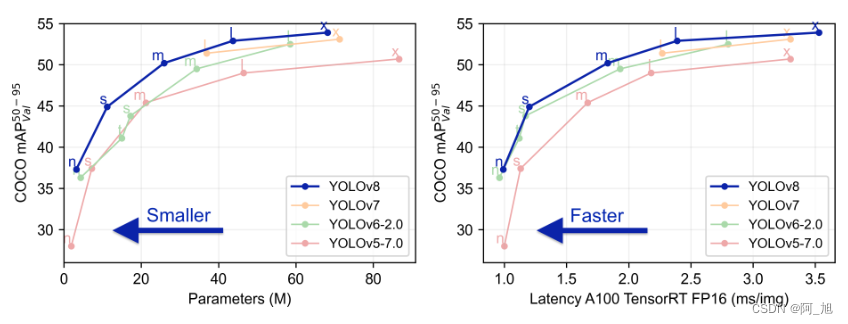
YOLOv8、YOLOv9、YOLOv10是YOLO系列中最前沿的3个系列版本,他们均是基于先前YOLO版本在目标检测任务上的成功,对模型结构进行不断地优化改进,从而不断提升了性能和灵活性,在精度和速度方面都具有尖端性能。

上图是前沿的SOTA目标检测模型在经典的COCO数据集上的性能表现对比。从上图可以看出,YOLOv8、YOLOv9、YOLOv10都有较好的性能表现。下面详细介绍各个版本的相关信息。
YOLOv8简介
源码地址:https://github.com/ultralytics/ultralytics
Yolov8是一个SOTA模型,它建立在Yolo系列历史版本的基础上,并引入了新的功能和改进点,以进一步提升性能和灵活性,使其成为实现目标检测、图像分割、姿态估计等任务的最佳选择。其具体创新点包括一个新的骨干网络、一个新的Ancher-Free检测头和一个新的损失函数,可在CPU到GPU的多种硬件平台上运行。
YOLOv8网络结构如下:

YOLOv8创新点:
Yolov8主要借鉴了Yolov5、Yolov6、YoloX等模型的设计优点,其本身创新点不多,偏重在工程实践上,具体创新如下:
- 提供了一个全新的SOTA模型(包括P5 640和P6 1280分辨率的目标检测网络和基于YOLACT的实例分割模型)。并且,基于缩放系数提供了N/S/M/L/X不同尺度的模型,以满足不同部署平台和应用场景的需求。
- Backbone:同样借鉴了CSP模块思想,不过将Yolov5中的C3模块替换成了C2f模块,实现了进一步轻量化,同时沿用Yolov5中的SPPF模块,并对不同尺度的模型进行精心微调,不再是无脑式一套参数用于所有模型,大幅提升了模型性能。
- Neck:继续使用PAN的思想,但是通过对比YOLOv5与YOLOv8的结构图可以看到,YOLOv8移除了1*1降采样层。
- Head部分相比YOLOv5改动较大,Yolov8换成了目前主流的解耦头结构(Decoupled-Head),将分类和检测头分离,同时也从Anchor-Based换成了Anchor-Free。
- Loss计算:使用VFL Loss作为分类损失(实际训练中使用BCE Loss);使用DFL Loss+CIOU Loss作为回归损失。
- 标签分配:Yolov8抛弃了以往的IoU分配或者单边比例的分配方式,而是采用Task-Aligned Assigner正负样本分配策略。
YOLOv8不同模型尺寸信息:
YOLOv8提供了5种不同大小的模型尺寸信息,详情如下:
| Model | size (pixels) | mAPval 50-95 | params (M) | FLOPs (B) |
|---|---|---|---|---|
| YOLOv8n | 640 | 37.3 | 3.2 | 8.7 |
| YOLOv8s | 640 | 44.9 | 11.2 | 28.6 |
| YOLOv8m | 640 | 50.2 | 25.9 | 78.9 |
| YOLOv8l | 640 | 52.9 | 43.7 | 165.2 |
| YOLOv8x | 640 | 53.9 | 68.2 | 257.8 |
一般来说,选择模型大小的原则如下:
数据集小(几百张图片):使用yolov8n或yolov8s。过大模型会过拟合。
数据集中等(几千张图片):yolov8s或yolov8m。能获得较高精度,不易过拟合。
数据集大(几万张图片):yolov8l或yolov8x。模型容量大,充分拟合大数据量,能发挥模型效果。
超大数据集(几十万张以上):首选yolov8x。超大模型才能处理海量数据并取得最优效果。
YOLOv9简介
论文地址:https://arxiv.org/abs/2402.13616
源码地址:https://github.com/WongKinYiu/yolov9

YOLOv9在YOLOv8的网络基础上做了进一步创新,其主要专注于解决深度神经网络中信息丢失带来的挑战。信息瓶颈原理和可逆函数的创新使用是其设计的核心,确保了 YOLOv9 保持高效率和准确性。
YOLOv9引入了两项关键创新概念:
可编程梯度信息 (PGI):PGI 是 YOLOv9 中引入的一个新概念,用于解决信息瓶颈问题,确保跨深度网络层保存基本数据。这样可以生成可靠的梯度,促进准确的模型更新并提高整体检测性能。

广义高效层聚合网络(GELAN):GELAN代表了架构的战略进步,使YOLOv9能够实现卓越的参数利用率和计算效率。它的设计允许灵活集成各种计算块,使 YOLOv9 在不牺牲速度或准确性的情况下适应广泛的应用。

YOLOv9架构创新点
更强大的骨干网络:YOLOv9采用了一种新的骨干网络设计,该设计在保持计算效率的同时,增强了特征的提取能力。通过引入更深的网络层次和更复杂的连接方式,YOLOv9能够更有效地捕捉图像中的上下文信息,从而提高了对目标的识别和定位精度。
改进的检测头设计:在检测头方面,YOLOv9进行了精心的设计和优化。它采用了多尺度特征融合的策略,使得模型能够同时关注不同大小的目标。此外,YOLOv9还引入了一种新的损失函数,以更好地平衡正负样本之间的权重,从而提高了模型的训练稳定性和检测性能。
可编程梯度信息利用:YOLOv9的一个显著创新点是它对梯度信息的利用方式。通过引入可编程的梯度信息学习策略,YOLOv9能够更有效地进行模型参数的更新和优化。这种方法不仅加速了模型的收敛速度,还有助于提高模型对复杂场景和多样化任务的适应性。
YOLOv9不同模型尺寸信息:
YOLOv9同样提供了5种不同大小的模型尺寸信息,详情如下:
| Model | size (pixels) | mAPval 50-95 | mAPval 50 | params (M) | FLOPs (B) |
|---|---|---|---|---|---|
| YOLOv9t | 640 | 38.3 | 53.1 | 2.0 | 7.7 |
| YOLOv9s | 640 | 46.8 | 63.4 | 7.2 | 26.7 |
| YOLOv9m | 640 | 51.4 | 68.1 | 20.1 | 76.8 |
| YOLOv9c | 640 | 53.0 | 70.2 | 25.5 | 102.8 |
| YOLOv9e | 640 | 55.6 | 72.8 | 58.1 | 192.5 |
YOLOv10介绍
论文地址:https://arxiv.org/abs/2405.14458
源码地址:https://github.com/THU-MIG/yolov10

YOLOv10 的架构建立在以前 YOLO 模型的优势之上,通过消除非最大抑制 (NMS) 和优化各种模型组件, 实现了最先进的性能,并显著降低了计算开销。
模型网络结构由以下组件组成:
主干网:YOLOv10 中的主干网负责特征提取,使用增强版的 CSPNet(Cross Stage Partial Network)来改善梯度流并减少计算冗余。
颈部:颈部被设计成聚合来自不同尺度的特征,并将它们传递到头部。它包括 PAN(路径聚合网络)层,用于有效的多尺度特征融合。
一对多头:在训练过程中为每个对象生成多个预测,以提供丰富的监督信号,提高学习准确性。
一对一头:在推理过程中为每个对象生成一个最佳预测,消除对 NMS 的需求,从而减少延迟并提高效率。
YOLOv10创新点如下
无 NMS 训练:利用一致的双重分配来消除对 NMS 的需求,从而减少推理延迟。
整体模型设计:从效率和精度两个角度对各种组件进行全面优化,包括轻量级分类头、空间通道解耦下采样和秩引导块设计。
增强的模型功能:整合大核卷积和部分自注意力模块,可在不增加大量计算成本的情况下提高性能。
YOLOv10不同模型尺寸信息:
YOLOv10 提供6种不同的型号规模模型,以满足不同的应用需求:
| Model | Input Size | APval | params (M) | FLOPs (G) |
|---|---|---|---|---|
| YOLOv10-N | 640 | 38.5 | 2.7 | 6.7 |
| YOLOv10-S | 640 | 46.3 | 7.2 | 21.6 |
| YOLOv10-M | 640 | 51.1 | 15.4 | 59.1 |
| YOLOv10-B | 640 | 52.5 | 19.1 | 92.0 |
| YOLOv10-L | 640 | 53.2 | 24.4 | 120.3 |
| YOLOv10-X | 640 | 54.4 | 29.5 | 160.4 |
YOLOv10-N:Nano 版本,适用于资源极度受限的环境。
YOLOv10-S:平衡速度和精度的小型版本。
YOLOv10-M:通用的中型版本。
YOLOv10-B:平衡版本,宽度增加,精度更高。
YOLOv10-L:大版本,以增加计算资源为代价,实现更高的精度。
YOLOv10-X:超大版本,可实现最大的精度和性能。
二、模型训练、评估与推理
本文主要基于YOLOv8n、YOLOv9t、YOLOv10n这3种模型进行模型的训练,训练完成后对3种模型在验证集上的表现进行全面的性能评估及对比分析。模型训练和评估流程基本一致,包括:数据集准备、模型训练、模型评估。
下面主要以YOLOv8为例进行训练过程的详细讲解,YOLOv9与YOLOv10的训练过程类似。
1. 数据集准备与训练
通过网络上搜集关于不同种类蔬菜的相关图片,并使用Labelimg标注工具对每张图片进行标注。然后对数据进行离线数据增强处理:包括马赛克数据增强、旋转、添加噪点、透视变换等策略,对数据集进行扩充,以增加模型的训练效果与泛化能力。
最终数据集一共包含5477张图片,其中训练集包含4755张图片,验证集包含475张图片、测试集包含247张图片,分为12个检测类别,分别是'甜菜', '甜椒', '卷心菜', '胡萝卜', '黄瓜', '鸡蛋','茄子','大蒜','洋葱','土豆','西红柿','西葫芦'。
部分图像及标注如下图所示:



数据集各类别数目分布如下:

2.模型训练
准备好数据集后,将图片数据以如下格式放置在项目目录中。在项目目录中新建datasets目录,同时将检测的图片分为训练集与验证集放入Data目录下。

同时我们需要新建一个data.yaml文件,用于存储训练数据的路径及模型需要进行检测的类别。YOLOv8在进行模型训练时,会读取该文件的信息,用于进行模型的训练与验证。data.yaml的具体内容如下:
train: D:\2MyCVProgram\2DetectProgram\VegetableDetection_v8\datasets\Data\train
val: D:\2MyCVProgram\2DetectProgram\VegetableDetection_v8\datasets\Data\valid
test: D:\2MyCVProgram\2DetectProgram\VegetableDetection_v8\datasets\Data\test
nc: 12
names: ['Beet', 'BellPepper', 'Cabbage', 'Carrot', 'Cucumber', 'Egg', 'Eggplant', 'Garlic', 'Onion', 'Potato', 'Tomato', 'Zucchini']
注:train与val后面表示需要训练图片的路径,建议直接写自己文件的绝对路径。
数据准备完成后,通过调用train.py文件进行模型训练,epochs参数用于调整训练的轮数,batch参数用于调整训练的批次大小【根据内存大小调整,最小为1】,代码如下:
#coding:utf-8
from ultralytics import YOLO
import matplotlib
matplotlib.use('TkAgg')
# 模型配置文件
model_yaml_path = "ultralytics/cfg/models/v8/yolov8.yaml"
#数据集配置文件
data_yaml_path = 'datasets/Data/data.yaml'
#预训练模型
pre_model_name = 'yolov8n.pt'
if __name__ == '__main__':
#加载预训练模型
model = YOLO(model_yaml_path).load(pre_model_name)
#训练模型
results = model.train(data=data_yaml_path,
epochs=150, # 训练轮数
batch=4, # batch大小
name='train_v8', # 保存结果的文件夹名称
optimizer='SGD') # 优化器
模型常用训练超参数参数说明:
YOLOv8 模型的训练设置包括训练过程中使用的各种超参数和配置。这些设置会影响模型的性能、速度和准确性。关键的训练设置包括批量大小、学习率、动量和权重衰减。此外,优化器、损失函数和训练数据集组成的选择也会影响训练过程。对这些设置进行仔细的调整和实验对于优化性能至关重要。
以下是一些常用的模型训练参数和说明:
| 参数名 | 默认值 | 说明 |
|---|---|---|
model | None | 指定用于训练的模型文件。接受指向 .pt 预训练模型或 .yaml 配置文件。对于定义模型结构或初始化权重至关重要。 |
data | None | 数据集配置文件的路径(例如 coco8.yaml).该文件包含特定于数据集的参数,包括训练数据和验证数据的路径、类名和类数。 |
epochs | 100 | 训练总轮数。每个epoch代表对整个数据集进行一次完整的训练。调整该值会影响训练时间和模型性能。 |
patience | 100 | 在验证指标没有改善的情况下,提前停止训练所需的epoch数。当性能趋于平稳时停止训练,有助于防止过度拟合。 |
batch | 16 | 批量大小,有三种模式:设置为整数(例如,’ Batch =16 ‘), 60% GPU内存利用率的自动模式(’ Batch =-1 ‘),或指定利用率分数的自动模式(’ Batch =0.70 ')。 |
imgsz | 640 | 用于训练的目标图像尺寸。所有图像在输入模型前都会被调整到这一尺寸。影响模型精度和计算复杂度。 |
device | None | 指定用于训练的计算设备:单个 GPU (device=0)、多个 GPU (device=0,1)、CPU (device=cpu),或苹果芯片的 MPS (device=mps). |
workers | 8 | 加载数据的工作线程数(每 RANK 多 GPU 训练)。影响数据预处理和输入模型的速度,尤其适用于多 GPU 设置。 |
name | None | 训练运行的名称。用于在项目文件夹内创建一个子目录,用于存储训练日志和输出结果。 |
pretrained | True | 决定是否从预处理模型开始训练。可以是布尔值,也可以是加载权重的特定模型的字符串路径。提高训练效率和模型性能。 |
optimizer | 'auto' | 为训练模型选择优化器。选项包括 SGD, Adam, AdamW, NAdam, RAdam, RMSProp 等,或 auto 用于根据模型配置进行自动选择。影响收敛速度和稳定性 |
lr0 | 0.01 | 初始学习率(即 SGD=1E-2, Adam=1E-3) .调整这个值对优化过程至关重要,会影响模型权重的更新速度。 |
lrf | 0.01 | 最终学习率占初始学习率的百分比 = (lr0 * lrf),与调度程序结合使用,随着时间的推移调整学习率。 |
3. 训练结果评估
在深度学习中,我们通常用损失函数下降的曲线来观察模型训练的情况。YOLOv8在训练时主要包含三个方面的损失:定位损失(box_loss)、分类损失(cls_loss)和动态特征损失(dfl_loss),在训练结束后,可以在runs/目录下找到训练过程及结果文件,如下所示:

各损失函数作用说明:
定位损失box_loss:预测框与标定框之间的误差(GIoU),越小定位得越准;
分类损失cls_loss:计算锚框与对应的标定分类是否正确,越小分类得越准;
动态特征损失(dfl_loss):DFLLoss是一种用于回归预测框与目标框之间距离的损失函数。在计算损失时,目标框需要缩放到特征图尺度,即除以相应的stride,并与预测的边界框计算Ciou Loss,同时与预测的anchors中心点到各边的距离计算回归DFLLoss。
本文训练结果如下:

我们通常用PR曲线来体现精确率和召回率的关系,本文训练结果的PR曲线如下。mAP表示Precision和Recall作为两轴作图后围成的面积,m表示平均,@后面的数表示判定iou为正负样本的阈值。mAP@.5:表示阈值大于0.5的平均mAP,可以看到本文模型目标检测的mAP@0.5值为0.905,结果还是十分不错的。

4. 使用模型进行推理
模型训练完成后,我们可以得到一个最佳的训练结果模型best.pt文件,在runs/train/weights目录下。我们可以使用该文件进行后续的推理检测。
图片检测代码如下:
#coding:utf-8
from ultralytics import YOLO
import cv2
# 所需加载的模型目录
path = 'models/best.pt'
# 需要检测的图片地址
img_path = "TestFiles/b3b8fbb3ceb8cc2e04792c59b4a21c_jpg.rf.556d13555a82c710604cb5b940c477b0.jpg"
# 加载预训练模型
model = YOLO(path, task='detect')
# 检测图片
results = model(img_path)
res = results[0].plot()
res = cv2.resize(res,dsize=None,fx=0.5,fy=0.5,interpolation=cv2.INTER_LINEAR)
cv2.imshow("YOLOv8 Detection", res)
cv2.waitKey(0)
执行上述代码后,会将执行的结果直接标注在图片上,结果如下:

更多检测结果如下:


三、YOLOv8/YOLOv9/YOLOv10性能对比分析
本文在介绍的数据集上分别训练了YOLOv8n、YOLOv9t、YOLOv10n这3种模型用于对比分析,训练轮数为150个epoch。主要分析这3种模型的训练结果在Precision(精确度)、Recall(召回率)、mAP50、mAP50-95、F1-score等性能指标上的表现,以选出更适合本数据集的最优模型。
3种模型基本信息如下:
| Model | size (pixels) | mAPval 50-95 | params (M) | FLOPs (B) |
|---|---|---|---|---|
| YOLOv8n | 640 | 37.3 | 3.2 | 8.7 |
| YOLOv9t | 640 | 38.3 | 2.0 | 7.7 |
| YOLOv10n | 640 | 38.5 | 2.7 | 6.7 |
FlOPs(floating point operations):浮点运算次数,用于衡量算法/模型的复杂度。
params (M):表示模型的参数量
这3种模型都是各个YOLO系列种最小尺寸结构的模型,在模型参数与计算量上都相差不大,属于同一个级别的模型,因此能够进行横向的对比分析。
1.常用评估参数介绍

-
Precision(精确度):
-
精确度是针对预测结果的准确性进行衡量的一个指标,它定义为预测为正例(即预测为目标存在)中真正正例的比例。
-
公式:

-
其中,TP(True Positives)是正确预测为正例的数量,FP(False Positives)是错误预测为正例的数量。
-
-
Recall(召回率):
-
召回率衡量的是模型检测到所有实际正例的能力,即预测为正例的样本占所有实际正例的比例。
-
公式:

-
其中,FN(False Negatives)是错误预测为负例(即漏检)的数量。
-
-
mAP50(平均精度,Mean Average Precision at Intersection over Union 0.5):
- mAP50是目标检测中一个非常重要的指标,它衡量的是模型在IoU(交并比)阈值为0.5时的平均精度。IoU是一个衡量预测边界框与真实边界框重叠程度的指标。
- mAP50通常在多个类别上计算,然后取平均值,得到整体的平均精度。
- 计算方法:对于每个类别,首先计算在IoU阈值为0.5时的精度-召回率曲线(Precision-Recall Curve),然后计算曲线下的面积(AUC),最后对所有类别的AUC取平均值。
这三个指标共同提供了对目标检测模型性能的全面评估:
- 精确度(Box_P)关注预测的准确性,即减少误检(FP)。
- 召回率(Box_R)关注检测的完整性,即减少漏检(FN)。
- mAP50提供了一个平衡精确度和召回率的指标,同时考虑了模型在不同类别上的表现。
在实际应用中,根据具体需求,可能会更侧重于精确度或召回率,例如在需要减少误报的场合,可能会更重视精确度;而在需要确保所有目标都被检测到的场合,可能会更重视召回率。mAP50作为一个综合指标,能够帮助研究者和开发者平衡这两个方面,选择最合适的模型。
- mAP50-95:
- 这是衡量目标检测模型在不同IoU阈值下性能的指标。IoU是预测的边界框与真实边界框之间的重叠程度,mAP50-95计算了从IoU为0.5到0.95的范围内,模型的平均精度。
- 精度-召回率曲线在不同的IoU阈值上绘制,然后计算曲线下的面积(AUC),最后取这些AUC的平均值,得到mAP50-95。
- 这个指标反映了模型在不同匹配严格度下的性能,对于评估模型在实际应用中的泛化能力非常重要。
- F1分数:
-
这是精确度和召回率的调和平均数,能够平衡两者的影响,是一个综合考虑精确度和召回率的指标。
-
公式:

-
当精确度和召回率差距较大时,F1分数能够提供一个更全面的模型性能评估。
-
2. 模型训练过程对比
YOLOv8n、YOLOv9t、YOLOv10n这3种模型的训练过程损失曲线与性能曲线如下。
训练过程的损失曲线对比如下:

训练过程中的精确度(Precision)、召回率(Recall)、平均精确度(Mean Average Precision, mAP)等参数的对比如下:

直观的从曲线上看,3种模型在训练收敛速度以及模型精度上看,差别不是很大。下面对具体的性能数值进行详细分析。
3.各模型性能评估
在YOLOv8n、YOLOv9t、YOLOv10n这3种模型训练完成后,我们可以通过验证集对各个模型分别进行性能评估。
YOLOv8n模型在验证集上的性能评估结果如下:

表格列说明:
Class:表示模型的检测类别名称;
Images:表示验证集图片数目;
Instances:表示在所有图片中目标数;
P:表示精确度Precison;
R:表示召回率Recall;
mAP50:表示IoU(交并比)阈值为0.5时的平均精度。
mAP50-95:表示从IoU为0.5到0.95的范围内【间隔0.05】,模型的平均精度。
表格行说明:
第一行all,除Instances是
所有类别目标数之和,其他参数表示所有类别对应列参数的平均值;
其他行,表示每一个类别对应参数的值。
YOLOv9t模型在验证集上的性能评估结果如下:

YOLOv10n模型在验证集上的性能评估结果如下:

4.模型在各类别上性能对比
为了更好的对比YOLOv8n、YOLOv9t、YOLOv10n这3种模型的各个类别上的性能表现。我们将上述模型评估结果汇总在一张表上进行分析对比。
下表为YOLOv8n、YOLOv9t、YOLOv10n在本文数据集上各个类别在验证集上的评估结果汇总。
在该表格中,粗体 代表该类别中每个指标的最大值。
每个类别的每一个指标都标记了最大值,以便于比较不同模型在同一类别上的表现。
| Class | Model | Box_P | Box_R | mAP50 | mAP50-95 |
|---|---|---|---|---|---|
| Beet | YOLOv8n | 0.938 | 0.879 | 0.953 | 0.804 |
| YOLOv9t | 0.928 | 0.919 | 0.964 | 0.799 | |
| YOLOv10n | 0.957 | 0.889 | 0.967 | 0.814 | |
| bellPepper | YOLOv8n | 0.927 | 0.899 | 0.945 | 0.810 |
| YOLOv9t | 0.909 | 0.859 | 0.936 | 0.798 | |
| YOLOv10n | 0.928 | 0.879 | 0.951 | 0.822 | |
| Cabbage | YOLOv8n | 0.952 | 0.964 | 0.974 | 0.915 |
| YOLOv9t | 0.960 | 0.960 | 0.977 | 0.914 | |
| YOLOv10n | 0.952 | 0.960 | 0.971 | 0.920 | |
| Carrot | YOLOv8n | 0.898 | 0.871 | 0.891 | 0.748 |
| YOLOv9t | 0.898 | 0.854 | 0.893 | 0.743 | |
| YOLOv10n | 0.893 | 0.844 | 0.890 | 0.747 | |
| Cucumber | YOLOv8n | 0.894 | 0.879 | 0.902 | 0.751 |
| YOLOv9t | 0.896 | 0.839 | 0.916 | 0.761 | |
| YOLOv10n | 0.909 | 0.852 | 0.895 | 0.733 | |
| Egg | YOLOv8n | 0.976 | 0.935 | 0.971 | 0.811 |
| YOLOv9t | 0.967 | 0.936 | 0.977 | 0.805 | |
| YOLOv10n | 0.969 | 0.931 | 0.965 | 0.799 | |
| Eggplant | YOLOv8n | 0.913 | 0.827 | 0.877 | 0.705 |
| YOLOv9t | 0.929 | 0.862 | 0.890 | 0.706 | |
| YOLOv10n | 0.927 | 0.837 | 0.873 | 0.706 | |
| Garlic | YOLOv8n | 0.927 | 0.603 | 0.761 | 0.569 |
| YOLOv9t | 0.863 | 0.667 | 0.762 | 0.579 | |
| YOLOv10n | 0.737 | 0.619 | 0.582 | 0.480 | |
| Onion | YOLOv8n | 0.944 | 0.899 | 0.943 | 0.840 |
| YOLOv9t | 0.941 | 0.879 | 0.941 | 0.834 | |
| YOLOv10n | 0.944 | 0.885 | 0.942 | 0.852 | |
| Potato | YOLOv8n | 0.912 | 0.917 | 0.945 | 0.814 |
| YOLOv9t | 0.949 | 0.917 | 0.954 | 0.812 | |
| YOLOv10n | 0.927 | 0.882 | 0.938 | 0.816 | |
| Tomato | YOLOv8n | 0.820 | 0.774 | 0.797 | 0.649 |
| YOLOv9t | 0.853 | 0.758 | 0.807 | 0.661 | |
| YOLOv10n | 0.815 | 0.765 | 0.802 | 0.660 | |
| Zucchini | YOLOv8n | 0.914 | 0.826 | 0.897 | 0.737 |
| YOLOv9t | 0.870 | 0.826 | 0.878 | 0.699 | |
| YOLOv10n | 0.871 | 0.833 | 0.901 | 0.719 |
为了方便更加直观的查看与对比各个结果,我们将表格绘制成图表的形式进行分析。
各类别在不同模型上的精确率(Precision)对比柱状图如下:

Precision指标对比分析:
- YOLOv9t在Potato和Tomato类别上Precision表现出了相对比较明显的优势,Precision分别为95.4%和80.7%,这表明YOLOv9t在检测Potato和Tomato类别时,正确的概率最高。
- YOLOv8n在Garlic和Zucchini类别上Precision表现突出,Precision分别为92.7%和91.4%。
- YOLOv8n在每个类别上的Precision表现都十分均衡,而且精确率较高;
- YOLOv10n在Garlic(大蒜)类别上表现较差,精确率比YOLOv8n的少了19%,这表明在大蒜检测中,YOLOv10n的假阳性率较高。
从精确率Precision上看,YOLOv8n在各个类别上表现更加均衡与出色。
各类别在不同模型上的召回率(Recall)对比柱状图如下:

Recall指标对比分析:
- 3种模型在Garlic(大蒜)类别上的Recall召回率相较于其他类别表现较差,相较于其他类别有20%-30%的差距。说明3种模型对于Garlic类别的漏检率较高;
- YOLOv9t在Beet和Garlic类别上Recall表现出了相对比较明显的优势,Recall分别为91.9%和66.7%,这表明YOLOv9t在检测Beet和Garlic类别时,相较于YOLOv8n与YOLOv10n,漏检率要低一些。
- YOLOv8n在BellPepper和Cucumber类别上Recall表现出了相对比较明显的优势,Recall分别为89.9%和87.9%,这表明YOLOv8n在检测BellPepper和Cucumber类别时,相较于其他两个模型漏检率要低一些。
各类别在不同模型上的mAP50对比柱状图如下:

mAP50指标对比分析:
- 3种模型除了检测Garlic类别时,YOLOv10n的mAP50表现较差,与YOLOv8n和YOLOv9t模型的mAP50指标相差了约18%。而在其他类别上3种模型mAP50性能指标差别不大。
各类别在不同模型上的mAP50-95对比柱状图如下:

mAP50-95指标对比分析:
- YOLOv8n在Zucchini类别上mAP50-95表现出了相对比较明显的优势,比YOLOv9t和YOLOv10n分别提高了1.8%和3.8%;
- 同样3种模型在Garlic(大蒜)类别上的mAP50-95相较于其他类别表现较差,相较于其他类别有15%-30%的差距。说明模型对于Garlic类别的泛化能力不足,这可能与Garlic类别训练数据样本较其他类别少很多的原因,后续可以考虑扩充Garlic类别的样本数,进一步提高模型对Garlic类别检测的泛化能力。
总结:
总体上看,在此数据集上YOLOv8n和YOLOv9t的在各类别上的性能表现要略优于YOLOv10n。每个模型在不同类别上的表现各有千秋,没有哪个模型在所有类别上都占据绝对优势。这可能表明不同模型对不同类别的目标检测有特定的偏好或优势。在实际应用中,选择哪个模型可能取决于具体任务的需求和对不同性能指标的重要性。
模型总体性能对比
上面我们分析了YOLOv8n、YOLOv9t、YOLOv10n这3不同模型在各个类别上的性能指标对比情况,下面我们从总体的平均指标上对这3种模型进行进一步的对比分析。
下表是YOLOv8n、YOLOv9t、YOLOv10n这3不同模型目标检测结果的整体性能平均指标对比情况:
| Model | Precision | Recall | mAP50 | mAP50-95 | F1-score |
|---|---|---|---|---|---|
| YOLOv8n | 0.918 | 0.856 | 0.905 | 0.763 | 0.886 |
| YOLOv9t | 0.914 | 0.856 | 0.908 | 0.759 | 0.884 |
| YOLOv10n | 0.902 | 0.848 | 0.890 | 0.756 | 0.874 |
为了方便更加直观的查看与对比各个结果,同样我们将表格绘制成图表的形式进行分析。

结果分析:
- 从各项指标整体上看,YOLOv8n和YOLOv9t的表现均略优于YOLOv10n,但差距并不十分显著,差距在1%左右;
- 在精确率Precision与召回率Recall上,YOLOv8n和YOLOv9t整体表现基本差不多,YOLOv8n比YOLOv9t在精确度Precison指标上略高0.4%;
- 在mAP50指标上,YOLOv9t比YOLOv8n略胜一筹,高了0.3%;但是在mAP50-95指标上YOLOv8n则显示出更好的稳定性;
- 从F1-score上看,YOLOv8n表现最佳,YOLOv9t和YOLOv8n基本接近,但是YOLOv10n表现略差一点,较YOLOv8n低了1.2%。
性能对比总结
整体来看,在此数据集上,YOLOv8n在各个指标方面都表现出了较好的结果,其次是YOLOv9t,YOLOv10n表现略差。但是每个模型在不同类别上的表现各有千秋,没有哪个模型在所有类别上都占据绝对优势。这可能表明不同模型对不同类别的目标检测有特定的偏好或优势。在实际应用中,选择哪个模型可能取决于具体任务的需求和对不同性能指标的重要性。
可视化系统制作
基于上述训练出的目标检测模型,为了给此检测系统提供一个用户友好的操作平台,使用户能够便捷、高效地进行检测任务。本文基于Pyqt5开发了一个可视化的系统界面,通过图形用户界面(GUI),用户可以轻松地在图片、视频和摄像头实时检测之间切换,无需掌握复杂的编程技能即可操作系统。【系统详细展示见第一部分内容】
Pyqt5简介
PyQt5 是用于 Python 编程语言的一个绑定库,提供了对 Qt 应用程序框架的访问。它常用于开发跨平台的桌面应用程序,具有丰富的功能和广泛的控件支持。PyQt5 提供了一个功能强大且灵活的框架,可以帮助 Python 开发者迅速构建复杂的桌面应用程序。其事件驱动编程模型、丰富的控件和布局管理、强大的信号与槽机制以及跨平台能力,使得 PyQt5 成为开发桌面应用程序的理想选择。下面对PyQt5 的基本原理进行详细介绍:
1. 基本架构
PyQt5 是 Python 和 Qt 库之间的一层接口,Python 程序员可以通过 PyQt5 访问 Qt 库的所有功能。Qt 是由 C++ 编写的跨平台软件开发框架,PyQt5 使用 SIP(一个用于创建 Python 与 C/C++ 语言之间的绑定工具)将这些功能导出到 Python。
2. 事件驱动编程
PyQt5 基于事件驱动编程模型,主要通过信号(signals)和槽(slots)机制实现用户与应用程序之间的交互。当用户与 GUI 进行交互(如点击按钮、调整滑块等)时,会触发信号,这些信号可以连接到槽函数或方法,以执行特定操作。
from PyQt5.QtWidgets import QApplication, QPushButton
def on_click():
print("Button clicked!")
app = QApplication([])
button = QPushButton('Click Me')
button.clicked.connect(on_click)
button.show()
app.exec_()
3. Qt 对象模型
PyQt5 的核心是 Qt 对象模型,所有的控件和窗口部件都是从 QObject 类派生而来的。它们拥有复杂的父子关系,确保父对象在销毁时自动销毁所有子对象,避免内存泄漏。
4. 部件(Widgets)
PyQt5 提供了丰富的内置部件,如按钮、标签、文本框、表格、树、标签页等,几乎涵盖了所有常见的 GUI 控件。这些部件可以直接使用,也可以通过继承进行自定义。
from PyQt5.QtWidgets import QApplication, QWidget, QLabel, QVBoxLayout
app = QApplication([])
window = QWidget()
layout = QVBoxLayout()
label = QLabel('Hello, PyQt5!')
layout.addWidget(label)
window.setLayout(layout)
window.show()
app.exec_()
5. 布局管理
PyQt5 提供了强大的布局管理功能,可以通过 QLayout 和其子类(如 QHBoxLayout, QVBoxLayout, QGridLayout)来控制部件在窗口内的摆放方式。这使得界面的设计变得灵活且易于维护。
6. 资源管理
PyQt5 支持资源文件管理,可以将图像、图标、样式表等资源打包进应用程序中。资源文件通常以 .qrc 格式存储,并通过资源管理器集成到应用程序中。
7. 信号与槽机制
信号与槽机制是 Qt 框架的核心特性之一,它允许对象之间进行松耦合通信。通过信号可以触发槽函数来处理各种事件,使代码逻辑更加清晰和模块化。
8. 跨平台性
PyQt5 是跨平台的,支持 Windows、Mac 和 Linux 等操作系统,编写一次代码即可运行在多个平台上。此外,PyQt5 还支持多语言国际化,助力开发全球化的应用程序。
博主基于Pyqt5框架开发了此款蔬菜目标检测与识别系统,即文中第一部分的演示内容,能够很好的支持图片、视频及摄像头进行检测,同时支持检测结果的保存。
关于该系统涉及到的完整源码、UI界面代码、数据集、训练代码、训练好的模型、测试图片视频等相关文件,均已打包上传,感兴趣的小伙伴可以通过下载链接自行获取。
【获取方式】
本文涉及到的完整全部程序文件:包括python源码、数据集、训练好的结果文件、训练代码、UI源码、测试图片视频等(见下图),获取方式见文末:

注意:该代码基于Python3.9开发,运行界面的主程序为
MainProgram.py,其他测试脚本说明见上图。为确保程序顺利运行,请按照程序运行说明文档txt配置软件运行所需环境。
结束语
以上便是博主开发的基于YOLOv10/YOLOv9/YOLOv8深度学习的蔬菜目标检测与识别系统的全部内容,由于博主能力有限,难免有疏漏之处,希望小伙伴能批评指正。
关于本篇文章大家有任何建议或意见,欢迎在评论区留言交流!
觉得不错的小伙伴,感谢点赞、关注加收藏哦!
















 1049
1049

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











