






点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达开发环境
软件版本信息:
Windows10 64位
Tensorflow1.15
Tensorflow object detection API 1.x
Python3.6.5
VS2015 VC++
CUDA10.0硬件:
CPUi7
GPU 1050ti如何安装tensorflow object detection API框架,看这里:
Tensorflow Object Detection API 终于支持tensorflow1.x与tensorflow2.x了
数据集处理与生成
首先需要下载数据集,下载地址为:
https://pan.baidu.com/s/1UbFkGm4EppdAU660Vu7SdQ总计7581张图像,基于Pascal VOC2012完成标注。分为两个类别,分别是安全帽与人(hat与person),json格式如下:
item {
id: 1
name: 'hat'
}
item {
id: 2
name: 'person'
}
数据集下载之后,并不能被tensorflow object detection API框架中的脚本转换为tfrecord,主要是有几个XML跟JPEG图像格式错误,本人经过一番磨难之后把它们全部修正了。修正之后的数据运行下面两个脚本即可生成训练集与验证集的tfrecord数据,命令行如下:

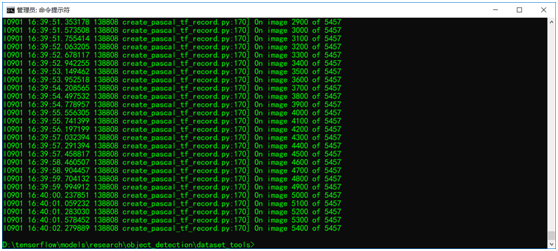
这里需要注意的是create_pascal_tf_record.py 脚本的165行把
'aeroplane_' + FLAGS.set + '.txt')修改为:
FLAGS.set + '.txt')原因是这里的数据集没有做分类train/val。所以需要修改一下,修改完成之后保存。运行上述的命令行,就可以正确生成tfrecord,否则会遇到错误。
模型训练
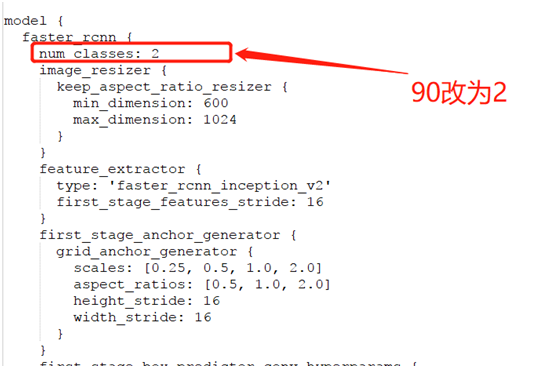
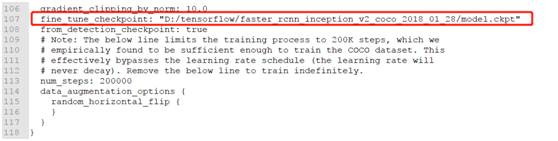
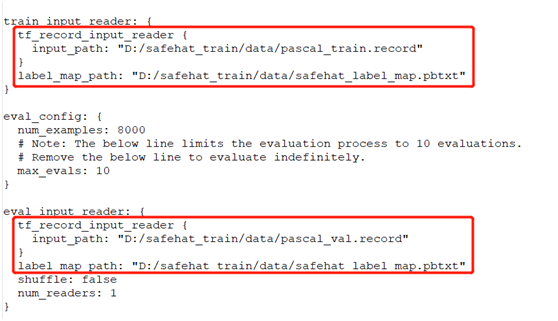
基于faster_rcnn_inception_v2_coco对象检测模型实现迁移学习,首先需要配置迁移学习的config文件,对应的配置文件可以从:
research\object_detection\samples\configs中发现,发现文件:
faster_rcnn_inception_v2_coco.config之后,修改配置文件的中相关部分,关于如何修改,修改什么,可以看这里:
修完完成之后,在D盘下新建好几个目录之后,执行下面的命令行参数:

就会开始训练,总计训练40000 step。训练过程中可以通过tensorboard查看训练结果:
模型导出
完成了40000 step训练之后,就可以看到对应的检查点文件,借助tensorflow object detection API框架提供的模型导出脚本,可以把检查点文件导出为冻结图格式的PB文件。相关的命令行参数如下:

得到pb文件之后,使用OpenCV4.x中的tf_text_graph_faster_rcnn.py脚本,转换生成graph.pbtxt配置文件。最终得到:
- frozen_inference_graph.pb
- frozen_inference_graph.pbtxt如何导出PB模型到OpenCV DNN支持看这里:
干货 | tensorflow模型导出与OpenCV DNN中使用
使用OpenCV DNN调用模型
在OpenCV DNN中直接调用训练出来的模型完成自定义对象检测,这里需要特别说明一下的,因为在训练阶段我们选择了模型支持600~1024保持比率的图像输入。所以在推理预测阶段,我们可以直接使用输入图像的真实大小,模型的输出格式依然是1x1xNx7,按照格式解析即可得到预测框与对应的类别。最终的代码实现如下:
1import cv2 as cv
2
3labels = ['hat', 'person']
4model = "D:/safehat_train/models/train/frozen_inference_graph.pb"
5config = "D:/safehat_train/models/train/frozen_inference_graph.pbtxt"
6
7# 读取测试图像
8image = cv.imread("D:/123.jpg")
9h, w = image.shape[:2]
10cv.imshow("input", image)
11
12# 加载模型,执行推理
13net = cv.dnn.readNetFromTensorflow(model, config)
14blob = cv.dnn.blobFromImage(cv.resize(image, (w, h)), swapRB=True, crop=False)
15net.setInput(blob)
16detectOut = net.forward()
17
18# 解析输出
19classIds = []
20confidences = []
21boxes = []
22for detection in detectOut[0,0,:,:]:
23 score = detection[2]
24 if score > 0.4:
25 left = detection[3]*w
26 top = detection[4]*h
27 right = detection[5]*w
28 bottom = detection[6]*h
29 classId = int(detection[1]) + 1
30 classIds.append(classId)
31 boxes.append([int(left), int(top), int(right), int(bottom)])
32 confidences.append(float(score))
33
34# 非最大抑制
35nms_indices = cv.dnn.NMSBoxes(boxes, confidences, 0.4, 0.4)
36for i in range(len(nms_indices)):
37 index = nms_indices[i][0]
38 box = boxes[index]
39 cid = classIds[index]
40 if cid == 1:
41 cv.rectangle(image, (box[0], box[1]), (box[2], box[3]), (140, 199, 0), 4, 8, 0)
42 else:
43 cv.rectangle(image, (box[0], box[1]), (box[2], box[3]), (255, 0, 255), 4, 8, 0)
44 cv.putText(image, labels[cid-1], (box[0], box[1]), cv.FONT_HERSHEY_SIMPLEX, 0.75, (255, 0, 0), 2)
45
46# 显示输出
47cv.imshow("safetyhat-detection-demo", image)
48cv.imwrite("D:/result123.png", image)
49cv.waitKey(0)
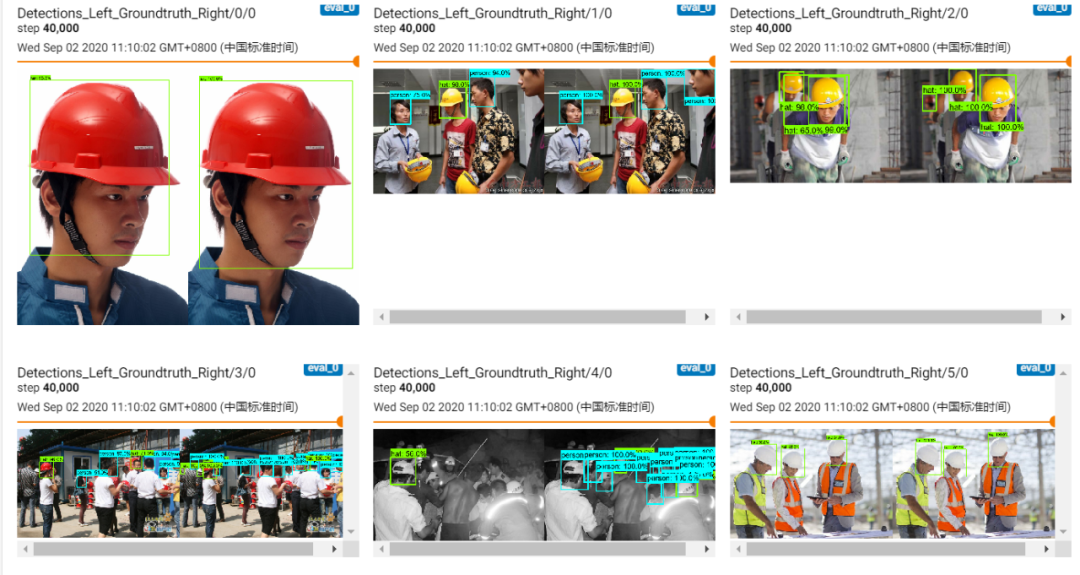
50cv.destroyAllWindows()一些测试图像的运行结果如下:





可以看到第二张途中有误识别情况发生!可见模型还可以继续训练!
避坑指南:
1. 下载的公开数据集,记得用opencv重新读取一遍,然后resave为jpg格式,这个会避免在生成tfrecord时候的图像格式数据错误。
ValueError: Image format not JPEG
2. 公开数据集中xml文件的filename有跟真实图像文件名称不一致的情况,要程序处理一下。不然会遇到
Windows fatal exception: access violation error
3. 使用非最大抑制之后,
SystemError: <built-in function NMSBoxes> returned NULL without setting an error, 解决:boxes 必须是int类型,confidences必须是浮点数类型
参考资料:
https://github.com/njvisionpower/Safety-Helmet-Wearing-Dataset
https://github.com/opencv/opencv/wiki/Deep-Learning-in-OpenCV
https://github.com/tensorflow/models/tree/master/research/object_detection
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









