






点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达作者丨LLLLLong@知乎(已授权)
来源丨https://zhuanlan.zhihu.com/p/654028373
编辑丨极市平台
极市导读
扩散模型是近年来非常火热的cv科研点,看此文章的读者应该需要具备一定的扩散模型基础知识,本文基于GitHub的扩散模型项目来详细讲解扩散模型训练以及测试之间的流程。重点在于DDPM的前向传播以及反向传播,即加噪和去噪过程,希望读者看完此篇文章后能有所收获。
项目介绍
本文项目来源与GitHub开源项目:https://github.com/zoubohao/DenoisingDiffusionProbabilityModel-ddpm-
该项目是利用了Cifar-10数据集来对扩散模型(diffusion)进行训练,主要分成有条件生成和无条件生成图像,其中的区别是 有否使用label来控制图像类别生成 ;其实这里也很简单,有条件控制就是把label转换成vector 加到image上面一起进行训练。
文章内容
扩散模型可以简单分成两个部分,去噪声和添加噪声。本文主要介绍无条件生成下的扩散模型训练以及推理的主要 代码内容。
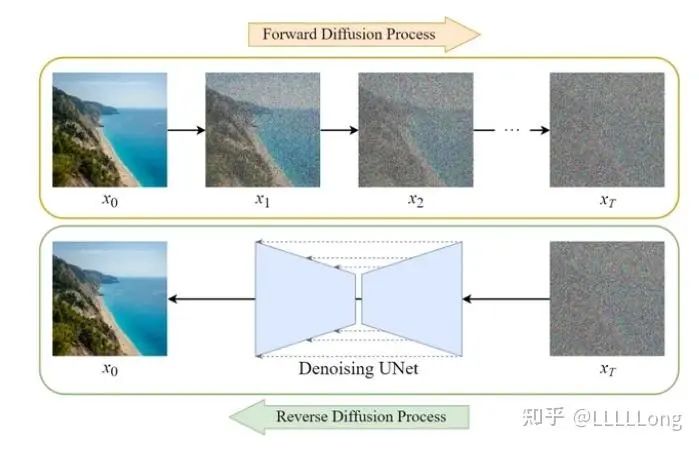
扩散模型工作过程(图侵删)
代码介绍
首先我们打开项目中的Main.py文件,里面包含了无条件生成下的各种不同的config,迭代次数,batch_size,去噪step,然后还有一些关于unet架构的config如:channel输入格式,attn注意力模块个数等超参数, 在这里还能通过‘state’来选择是训练(train)还是测试(eval)
from Diffusion.Train import train, eval
def main(model_config = None):
modelConfig = {
"state": "train", # or eval
"epoch": 200,
"batch_size": 80,
"T": 1000,
"channel": 128,
"channel_mult": [1, 2, 3, 4],
"attn": [2],
"num_res_blocks": 2,
"dropout": 0.15,
"lr": 1e-4,
"multiplier": 2.,
"beta_1": 1e-4,
"beta_T": 0.02,
"img_size": 32,
"grad_clip": 1.,
"device": "cuda:0", ### MAKE SURE YOU HAVE A GPU !!!
"training_load_weight": None,
"save_weight_dir": "./Checkpoints/",
"test_load_weight": "DiffusionWeight.pt",
"sampled_dir": "./SampledImgs/",
"sampledNoisyImgName": "NoisyNoGuidenceImgs.png",
"sampledImgName": "SampledNoGuidenceImgs.png",
"nrow": 8
}
if model_config is not None:
modelConfig = model_config
if modelConfig["state"] == "train":
train(modelConfig)
else:
eval(modelConfig)
if __name__ == '__main__':
main()2. Train.py
文件中包含了整个训练过程和测试过程的逻辑代码,我会把最重要的部分都挑选出来进行个人的解释。
trainer = GaussianDiffusionTrainer(
net_model, modelConfig["beta_1"], modelConfig["beta_T"], modelConfig["T"]).to(device)我们需要注意到第43行代码创建了trainer这一变量,这一行代码是经过Diffusion.py文件所创建的一个实例,其主要的作用是利用unet网络来对t时刻的噪声进行预测,具体来说使用unet预测不同t时刻的X_t的噪声,把预测出来的噪声加到X_t时刻的image上面,与原始服从高斯分布的噪声图进行loss计算,具体可以参考下图。

图中Train the UNet就是43行代码实例所要进行的操作
# start training
for e in range(modelConfig["epoch"]):
with tqdm(dataloader, dynamic_ncols=True) as tqdmDataLoader:
for images, labels in tqdmDataLoader:
# train
optimizer.zero_grad()
x_0 = images.to(device)
loss = trainer(x_0).sum() / 1000.
loss.backward()
torch.nn.utils.clip_grad_norm_(
net_model.parameters(), modelConfig["grad_clip"])
optimizer.step()
tqdmDataLoader.set_postfix(ordered_dict={
"epoch": e,
"loss: ": loss.item(),
"img shape: ": x_0.shape,
"LR": optimizer.state_dict()['param_groups'][0]["lr"]
})
warmUpScheduler.step()
torch.save(net_model.state_dict(), os.path.join(
modelConfig["save_weight_dir"], 'ckpt_' + str(e) + "_.pt"))Train.py文件后面的代码则是整个训练迭代过程的构建
3. Duffision.py
文件包含使用Unet预测不同t时刻噪声的训练过程以及DDPM反向去噪过程。
class GaussianDiffusionTrainer(nn.Module):
def __init__(self, model, beta_1, beta_T, T):
super().__init__()
self.model = model
self.T = T
self.register_buffer(
'betas', torch.linspace(beta_1, beta_T, T).double())
alphas = 1. - self.betas
alphas_bar = torch.cumprod(alphas, dim=0)
# calculations for diffusion q(x_t | x_{t-1}) and others
self.register_buffer(
'sqrt_alphas_bar', torch.sqrt(alphas_bar))
self.register_buffer(
'sqrt_one_minus_alphas_bar', torch.sqrt(1. - alphas_bar))
def forward(self, x_0):
"""
Algorithm 1.
"""
t = torch.randint(self.T, size=(x_0.shape[0], ), device=x_0.device)
noise = torch.randn_like(x_0)
x_t = (
extract(self.sqrt_alphas_bar, t, x_0.shape) * x_0 +
extract(self.sqrt_one_minus_alphas_bar, t, x_0.shape) * noise)
loss = F.mse_loss(self.model(x_t, t), noise, reduction='none')
return lossGaussianDiffusionTrainer类的就是利用Unet预测不同t时刻噪声的训练过程。在构造方法中,self.model传入的是Unet网络并且Unet网络会对输入的X_t和t进行格式转换和合并处理,让每一t时刻的噪声加入时间信息(step)。前向forward函数中,首先根据输入的batch_size创建x个相同的t时刻信息(由于Cifar-10数据集每一张图像的分辨率只有32*32,所以batch-size可以适当增大),随后X_t变量就是t时刻添加了噪声之后的image。我们需要通过Unet预测出最终的noisy图并且与服从高斯正太分布的noisy进行一个均方损失的计算。
class GaussianDiffusionSampler(nn.Module):
def __init__(self, model, beta_1, beta_T, T):
super().__init__()
self.model = model
self.T = T
self.register_buffer('betas', torch.linspace(beta_1, beta_T, T).double())
alphas = 1. - self.betas
alphas_bar = torch.cumprod(alphas, dim=0)
alphas_bar_prev = F.pad(alphas_bar, [1, 0], value=1)[:T]
self.register_buffer('coeff1', torch.sqrt(1. / alphas))
self.register_buffer('coeff2', self.coeff1 * (1. - alphas) / torch.sqrt(1. - alphas_bar))
self.register_buffer('posterior_var', self.betas * (1. - alphas_bar_prev) / (1. - alphas_bar))
def predict_xt_prev_mean_from_eps(self, x_t, t, eps):
assert x_t.shape == eps.shape
return (
# 利用X_t噪声图减去X_t-1
extract(self.coeff1, t, x_t.shape) * x_t -
extract(self.coeff2, t, x_t.shape) * eps
)
def p_mean_variance(self, x_t, t):
# below: only log_variance is used in the KL computations
var = torch.cat([self.posterior_var[1:2], self.betas[1:]])
var = extract(var, t, x_t.shape)
# eps为unet预测出来Xt-1刻的噪声图
eps = self.model(x_t, t)
xt_prev_mean = self.predict_xt_prev_mean_from_eps(x_t, t, eps=eps)
return xt_prev_mean, var
def forward(self, x_T):
"""
Algorithm 2.
"""
x_t = x_T
for time_step in reversed(range(self.T)):
print(time_step)
t = x_t.new_ones([x_T.shape[0], ], dtype=torch.long) * time_step
mean, var= self.p_mean_variance(x_t=x_t, t=t)
# no noise when t == 0
if time_step > 0:
noise = torch.randn_like(x_t)
else:
noise = 0
# 这一条就是算法里面求得X_t-1的公式,其中torch.sqrt(var) * noise对应DDPM中的σ
x_t = mean + torch.sqrt(var) * noise
assert torch.isnan(x_t).int().sum() == 0, "nan in tensor."
x_0 = x_t
return torch.clip(x_0, -1, 1)GaussianDiffusionSampler这一个类主要的作用是进行DDPM_Backward也就是反向去噪,其中p_mean_variance方法的作用是利用X_t时刻的输入预测X_t-1刻的噪声,该方法返回的参数有X_t-1刻的噪声图以及var-关于时间t的一个系数,后续用于forward方法中X_t噪声图的计算。为什么在forward方法中有 x_t = mean + torch.sqrt(var) * noise这一公式?可能很多人都会有一个疑惑,论文中是用t刻的noisy减去t-1刻的noisy,为什么在这里会加?那是因为相减的操作已经在predict_xt_prev_mean_from_eps这一方法中处理了,按照DDPM论文所提出来的公式,得到X_t-1并不单纯地相减,后续还要通过一个公式加上适当的噪声。

具体地可以参考原论文的这一行公式
4.Model.py
顾名思义,这一个文件中主要包括了有Unet、注意力模块、time-embedding模块、残差模块 等结构;其中最重要的应该是time-embedding模块以及把时间向量合并到image向量中的映射模块(包含在残差模块中)
class TimeEmbedding(nn.Module):
def __init__(self, T, d_model, dim):
assert d_model % 2 == 0
super().__init__()
emb = torch.arange(0, d_model, step=2) / d_model * math.log(10000)
emb = torch.exp(-emb)
pos = torch.arange(T).float()
emb = pos[:, None] * emb[None, :] # 合并组成【1000,64】的位置编码
assert list(emb.shape) == [T, d_model // 2]
emb = torch.stack([torch.sin(emb), torch.cos(emb)], dim=-1)
assert list(emb.shape) == [T, d_model // 2, 2]
emb = emb.view(T, d_model)
self.timembedding = nn.Sequential(
nn.Embedding.from_pretrained(emb),
nn.Linear(d_model, dim),
Swish(),
nn.Linear(dim, dim),
)
self.initialize()
def initialize(self):
for module in self.modules():
if isinstance(module, nn.Linear):
init.xavier_uniform_(module.weight)
init.zeros_(module.bias)
def forward(self, t):
emb = self.timembedding(t)
return embTimeEmbedding类就是把每一个T时刻(不是全部,因为在训练的过程中是随机挑选t的)转换成对应的向量然后把对应的向量放入残差模块
class ResBlock(nn.Module):
def __init__(self, in_ch, out_ch, tdim, dropout, attn=False):
super().__init__()
self.block1 = nn.Sequential(
nn.GroupNorm(32, in_ch),
Swish(),
nn.Conv2d(in_ch, out_ch, 3, stride=1, padding=1),
)
self.temb_proj = nn.Sequential(
Swish(),
nn.Linear(tdim, out_ch),
)
self.block2 = nn.Sequential(
nn.GroupNorm(32, out_ch),
Swish(),
nn.Dropout(dropout),
nn.Conv2d(out_ch, out_ch, 3, stride=1, padding=1),
)
if in_ch != out_ch:
self.shortcut = nn.Conv2d(in_ch, out_ch, 1, stride=1, padding=0)
else:
self.shortcut = nn.Identity()
if attn:
self.attn = AttnBlock(out_ch)
else:
self.attn = nn.Identity()
self.initialize()
def initialize(self):
for module in self.modules():
if isinstance(module, (nn.Conv2d, nn.Linear)):
init.xavier_uniform_(module.weight)
init.zeros_(module.bias)
init.xavier_uniform_(self.block2[-1].weight, gain=1e-5)
def forward(self, x, temb):
h = self.block1(x) # x=[8,132,32,32], h= [
h += self.temb_proj(temb)[:, :, None, None] # 把时间向量从(128,512) 变成(8,128,1,1)
h = self.block2(h)
h = h + self.shortcut(x)
h = self.attn(h)
return h要注意的是在残差模块中的self.temb_proj类,该类的主要作用就是把TimeEmbedding类对t时刻转换成的向量vector(输入的格式与image的通道相适应)与image进行融合,把时间信息放入image中。其中的forward就是二者相融合的地方。
实验效果
相信大家最关心的就是实验效果,我认为这个项目对于新手来说非常友好,可以快速地学习掌握扩散模型的一些相关细节,并且代码可以在3060 6G的环境下运行,相信也能适配大部分的新手。

高斯分布随机选取的噪声图
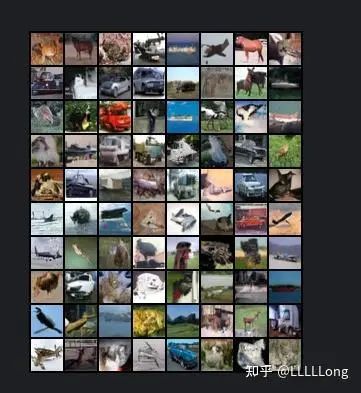 利用DDPM推理出来的图像
利用DDPM推理出来的图像
最后希望这篇文章能帮到有需要的人,如有错误也欢迎在评论区提出。
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
















 2847
2847

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









