




记录OpenCV中学习的函数用法
文章目录
图像阈值
cv.threshold()全局阈值
源:ret, mask = cv.threshold(img2gray, 10, 255, cv.THRESH_BINARY)
作用:根据设定的阈值,将图像转变为黑色或白色
| Python: cv2.threshold(src, thresh, maxval, type[, dst]) → retval, ds |
在其中
src:表示的是图片源,是一个灰度图像
thresh:表示的是阈值(起始值)
maxval:表示的是最大值,一般为255
type:表示的是这里划分的时候使用的是什么类型的算,常用值为0(THRESH_BINARY)

ret, mask = cv.threshold(img2gray, 10, 255, cv.THRESH_BINARY)
ret: 返回的阈值
mask:返回的二值化图像
import cv2 as cv
img0 = cv.imread('MyLove.jpg')
img = cv.cvtColor(img0, cv.COLOR_BGR2GRAY)
ret, mask = cv.threshold(img, 100, 255, cv.THRESH_BINARY)
cv.imshow('Binary', mask)
cv.waitKey(0)
cv.adaptiveThreshold()自适应阈值
源:th2 = cv2.adaptiveThreshold(img,255,cv2.ADAPTIVE_THRESH_MEAN_C,
cv2.THRESH_BINARY,11,2)代码出处CSDN
作用: 根据图片一小块区域的值来计算对应区域的阈值,从而得到也许更为合适的图片。
| Python: dst = cv2.adaptiveThreshold(src, maxval, thresh_type, type, Block Size, C) |
src:输入图,只能输入单通道图像,通常来说为灰度
dst:输出图
maxval:当像素值超过了阈值(或者小于阈值,根据type来决定),所赋予的值
thresh_type: 阈值的计算方法,包含以下2种类型
cv2.ADAPTIVE_THRESH_MEAN_C;
cv2.ADAPTIVE_THRESH_GAUSSIAN_C
type:二值化操作的类型,与固定阈值函数相同,包含以下5种类型:
cv2.THRESH_BINARY
cv2.THRESH_BINARY_INV
cv2.THRESH_TRUNC;
cv2.THRESH_TOZERO
cv2.THRESH_TOZERO_INV.
Block Size: 图片中分块的大小
C :阈值计算方法中的常数项
Otsu’s Binarization: 基于直方图的二值化
源:ret2,th2 = cv2.threshold(img,0,255,cv2.THRESH_BINARY+cv2.THRESH_OTSU)代码出处CSDN
特点:需要和threshold函数配合使用。0和255为阈值取值范围。ret2可以返回最后的阈值。
Otsu过程:
1. 计算图像直方图;
2. 设定一阈值,把直方图强度大于阈值的像素分成一组,把小于阈值的像素分成另外一组;
3. 分别计算两组内的偏移数,并把偏移数相加;
4. 把0~255依照顺序设置为阈值,重复1-3的步骤,直到得到最小偏移数,其所对应的值即为结果阈值。
图像上的算术运算
cv.subtract() 图像减法
源:L = cv.subtract(gpA[i-1],GE) 代码出处
作用:查找图像之间的差异
1. 两个图像矩阵相减, 要求两个矩阵必须有相同大小和通道数
2. 1个图像矩阵和1个标量相减, 要求src2是标量或者与src1的通道数相同的元素个数,经实际测试应该是一个四元组,如果src1是3通道的,则按通道顺序依次与该四元组的前3个元素相减
3. 1个标量和一个图像数组相减, 要求src1是标量或者与src1的通道数相同的元素个数
最后结果为第一个图像减去第二个图像
| Python: cv2.subtract(src1, src2[, dst[, mask[, dtype]]]) -> dst |
在其中
src1:第一个图像
src2:第二个图像
dst:可选参数,输出结果保存的变量,默认值为None,如果为非None,输出图像保存到dst对应实参中,其大小和通道数与输入图像相同,图像的深度(即图像像素的位数)由dtype参数或输入图像确定
mask:图像掩膜,可选参数,为8位单通道的灰度图像,用于指定要更改的输出图像数组的元素,即输出图像像素只有mask对应位置元素不为0的部分才输出,否则该位置像素的所有通道分量都设置为0
dtype:可选参数,输出图像数组的深度,即图像单个像素值的位数(如RGB用三个字节表示,则为24位)。
cv.add() 图像加法
源:ls_ = cv.add(ls_, LS[i])
作用:OpenCV加法是饱和运算,而Numpy加法是模运算。
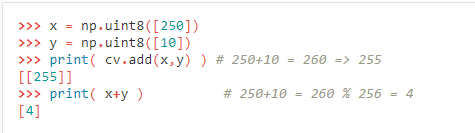
最后结果为第一个图像加上第二个图像
| Python: cv2.add(src1, src2[, dst[, mask[, dtype]]]) -> dst |
在其中
src1:第一个图像
src2:第二个图像
dst:可选参数,输出结果保存的变量,默认值为None,如果为非None,输出图像保存到dst对应实参中,其大小和通道数与输入图像相同,图像的深度(即图像像素的位数)由dtype参数或输入图像确定
mask:图像掩膜,可选参数,为8位单通道的灰度图像,用于指定要更改的输出图像数组的元素,即输出图像像素只有mask对应位置元素不为0的部分才输出,否则该位置像素的所有通道分量都设置为0
dtype:可选参数,输出图像数组的深度,即图像单个像素值的位数(如RGB用三个字节表示,则为24位)。
cv.addWeighted()权重融合
源:dst = cv.addWeighted(img1, 0.7, img2, 0.3, 0)

alpha=0.7,beta=0.3,gama=0
cv.bitwise_and()or() xor() not() 按位处理
作用:进行图像之间的逻辑运算,在处理ROI区域有很大作用
转化为二进制便于理解
# 按位操作函数
# 3x3图像,全(1,1,1)
i = np.ones((3, 3, 3), dtype=np.uint8)
# 3x3图像,全(2,2,2)
j = np.ones((3, 3, 3), dtype=np.uint8) + 1
# 图像i,j每个像素与运算结果
k = cv.bitwise_and(i, j) # 与 每一个像素都为1,那么二进制表示就是0001。则2的二进制表示就是0010。那么两幅图像进行与操作,就会变成0000
l = cv.bitwise_or(i, j) # 或 0001 or 0010 为 0011 , 全部是3
n = cv.bitwise_xor(i, j) # 异或(相同的是0,不同的是1) 0000 0001 xor 0000 0010 为 0000 0011 ,全部是3
m = cv.bitwise_not(i) # '非' 0000 0001 not 为1111 1110 , 全是254
print(i, j, k, l, n, m)
改变颜色空间
cv.inRange()和掩模Mask
源:mask = cv.inRange(hsv, lower_yellow, upper_yellow)代码出处
作用: 将低于lower_red和高于upper_red的部分分别变成0,lower_red~upper_red之间的值变成255查找各种颜色范围
注意:需要HSV颜色的图片,它更容易表示颜色,HSV的色相范围为[0,179],饱和度范围为[0,255],值范围为[0,255]
hsv = cv2.cvtColor(rgb_image, cv2.COLOR_BGR2HSV)
图像掩膜Mask就像AE里面的遮罩
作用: 对处理的图像(全部或局部)进行遮挡用于
提取感兴趣区、对图像上某些区域作屏蔽、结构特征提取等
源:res = cv.bitwise_and(cp, cp, mask=mask) # mask为RIO区域,只针对这一区域处理
cv.bitwise_and(cp, cp)的结果还是cp。 使用mask=mask后只提取mask区域
import cv2 as cv
import numpy as np
# set blue thresh
lower_yellow = np.array([11, 43, 46])
upper_yellow = np.array([25, 255, 255])
frame = cv.imread("tulips.jpg") # 读取图像
cv.imshow("who", frame)
# compress
cp = cv.resize(frame, (300, 300), interpolation=cv.INTER_AREA) # 放缩
cv.imwrite("tulips_1.jpg", cp)
# change to hsv model
hsv = cv.cvtColor(cp, cv.COLOR_BGR2HSV)
# get mask
mask = cv.inRange(hsv, lower_yellow, upper_yellow)
cv.imshow('Mask', mask)
# detect blue
res = cv.bitwise_and(cp, cp, mask=mask) # mask为RIO区域,只针对这一区域处理
cv.imshow('Result', res)
cv.waitKey(0)
cv.destroyAllWindows()

图像的几何变换
cv.resize()
源:cp = cv.resize(frame, (300,300), interpolation=cv.INTER_AREA)
作用: 缩小或者放大函数至某一个大小
| Python: cv2.resize(src, dsize[, dst[, fx[, fy[, interpolation]]]]) |
src:图片源
dsize:输出图像所需大小
fx:沿水平轴的比例因子
fy:沿垂直轴的比例因子
interpolation:插值方式
cv.INTER_NEAREST : 最邻近插值
cv.INTER_LINEAR:双线性插值
cv.INTER_CUBIC:三次插值
cv.INTER_AREA:区域插值(使用像素区域关系重新采样,提供无莫尔条纹的结果)
一般缩小使用cv.INTER_AREA,放缩使用cv.INTER_CUBIC(较慢)和cv.INTER_LINEAR(较快效果也不错)。默认都使用cv.INTER_LINEAR。
| img = cv.resize(img0, (0, 0), fx=2, fy=2, interpolation=cv.INTER_AREA) # 将原图像扩大2倍 |
cv.warpAffine()仿射变换函数(移动)
warp:弯曲,使变形 Affine:仿射的
源:M = np.float32([[1, 0, 100], [0, 1, 50]])
dst = cv.warpAffine(img, M, (cols, rows))代码出处
作用: 将图像沿着x轴平移100px, y轴平移50px
| Python: cv2.warpAffine(src, M, dsize) -> dst |
src:图片源
M:转换矩阵,是一个2*3的矩阵(float32格式),tx和ty表示x,y轴方向位移
dsize:输出图像大小
形式为 (width,height) =(cols, rows)注意倒过来了

cv.getRotationMatrix2D()构造旋转矩阵
源:M = cv.getRotationMatrix2D(((cols-1)/2.0,(rows-1)/2.0),90,1)
dst = cv.warpAffine(img,M,(cols,rows))代码出处
作用: 构造绕着图像中点逆时针旋转90°,不缩放的转换矩阵M
| Python: cv2.getRotationMatrix2D(center, angle, scale) -> retval |
center:旋转中心
angle:旋转角度(逆时针为正)
scale:缩放比例
绕任意位置旋转的转换矩阵M

cv.getAffineTransform()仿射变换
源:M = cv.getAffineTransform(pts1,pts2)
dst = cv.warpAffine(img,M,(cols,rows))代码出处
作用: 构造 将img0中的三个点变换自定义的三个点位置 的转换矩阵M
特点:原始图像中的所有平行线在输出图像中仍将平行
| Python: cv2.getAffineTransform(src, dst) -> retval |
<font color=black size=>在其中
src:img0中的三个点,注意是float32格式
dst:想要将原来的三个点变换到想要的(自定义的)三个点
def test3():
img0 = cv.imread('Affine.jpg')
img = cv.cvtColor(img0, cv.COLOR_BGR2RGB)
rows, cols, ch = img.shape
pts1 = np.array([[49, 35], [335, 86], [46, 292]], dtype=np.float32) # 变换前原图像的3个点
pts2 = np.array([[10, 10], [360, 10], [10, 350]], dtype=np.float32) # 自定义的变换后原图像对应的3个点
M = cv.getAffineTransform(pts1, pts2) # 构造仿射变换的转换矩阵M
dst = cv.warpAffine(img, M, (cols, rows))
plt.subplot(121), plt.imshow(img), plt.title('Input')
plt.subplot(122), plt.imshow(dst), plt.title('Output')
plt.show() # 不加此行代码,无法显示图片

*cv.getPerspectiveTransform()透视变换
源:M = cv.getPerspectiveTransform(pts1,pts2)
dst = cv.warpPerspective(img,M,(300,300))代码出处
作用: 构造 将img0中的三个点变换自定义的三个点位置 的转换矩阵M
特点:原始图像中的所有直线也将保持直线
需要输入4个点,在这四个点中,其中三个不应共线。
| Python: cv2.getAffineTransform(src, dst) -> retval |
src:img0中的四个点,注意是float32格式
dst:想要将原来的四个点变换到想要的(自定义的)四个点
# 透视变换
def test4():
img = cv.imread('perspective.jpg')
rows, cols, ch = img.shape
pts1 = np.float32([[432, 299], [592, 307], [605, 471], [424, 465]]) # 绿点坐标
pts2 = np.float32([[0, 0], [300, 0], [300, 300], [0, 300]]) # 变换后坐标
M = cv.getPerspectiveTransform(pts1, pts2)
dst = cv.warpPerspective(img, M, (300, 300))
plt.subplot(121), plt.imshow(img), plt.title('Input')
plt.subplot(122), plt.imshow(dst), plt.title('Output')
plt.show()

图像平滑
cv.blur() 平均模糊(平滑)
源:blur = cv.blur(img,(5,5))代码出处
作用:它仅获取内核区域下所有像素的平均值,并替换中心元素。用标准化的盒式过滤器来平滑图像
| Python: cv2.blur(src, ksize[, dst[, anchor[, borderType]]] -> dst |
在其中
src:原图像
dst:目标图像
ksize:用于平滑操作的核大小
anchor:内核的锚点,指示内核中过滤点的相对位置;锚应位于内核中;默认值(-1,-1)表示锚位于内核中心。
borderType: 边界模式,指定处理边界像素时如何确定图像范围外的像素的取值
cv.GaussianBlur()高斯模糊(平滑)
源:blur = cv.GaussianBlur(img,(5,5),0)代码出处
作用:代替盒式滤波器,使用了高斯核。将源图像与指定的高斯内核进行卷积,同时也支持in-place滤波。
| Python: cv2.GaussianBlur(src, ksize, sigmaX[, dst[, sigmaY[, borderType]]]) -> dst |
在其中
src:原图像
dst:目标图像
ksize:用于平滑操作的核大小(width*hight)必须是大于1的正奇数
sigmaX:高斯核在x方向的标准差
sigmaX:高斯核在y方向的标准差(sigmaY=0时,其值自动由sigmaX确定(sigmaY=sigmaX);sigmaY=sigmaX=0时,它们的值将由ksize.width和ksize.height自动确定)
borderType: 边界模式,指定处理边界像素时如何确定图像范围外的像素的取值
cv.medianBlur()中位模糊(平滑)
源:median = cv.medianBlur(img,5)代码出处
作用:代替盒式滤波器,使用了高斯核。将源图像与指定的高斯内核进行卷积,同时也支持in-place滤波。
| Python: cv2.GaussianBlur(src, ksize, sigmaX[, dst[, sigmaY[, borderType]]]) -> dst |
在其中
src:原图像
dst:目标图像
ksize:用于平滑操作的核大小(width*hight)必须是正奇数
sigmaX:高斯核在x方向的标准差
sigmaX:高斯核在y方向的标准差(sigmaY=0时,其值自动由sigmaX确定(sigmaY=sigmaX);sigmaY=sigmaX=0时,它们的值将由ksize.width和ksize.height自动确定)
borderType: 边界模式,指定处理边界像素时如何确定图像范围外的像素的取值
| 中值滤波是一种非线性滤波,它的原理是选取一个窗口S,在整幅图像上从左到右,从上到下滑动,滑动过程中,窗口S所框选的范围可确定一个邻域,在该邻域内所有像素点的灰度值进行从小到大的排列,取其中值作为该像素点的灰度值。 中值滤波在滤除椒盐噪声方面效果极佳,同时对图像边缘的保护效果较好,可以对车道线图像进行滤波处理。 |
cv.bilateralFilter()双边滤波
源:blur = cv.bilateralFilter(img,9,75,75)代码出处
作用:在去除噪声的同时保持边缘清晰锐利。
| Python: cv2.bilateralFilter(src, d, sigmaColor, sigmaSpace[, dst[, borderType]]) -> dst |
在其中
src:原图像,可以是Mat类型,图像必须是8位或浮点型单通道、三通道的图像。
dst:输出图像,和原图像有相同的尺寸和类型。
d: 表示在过滤过程中每个像素邻域的直径范围,整数。如果这个值是非正数,则函数会从第五个参数sigmaSpace计算该值。
sigmaColor: 颜色空间过滤器的sigma值,这个参数的值越大,表明该像素邻域内有越宽广的颜色会被混合到一起,产生较大的半相等颜色区域。
sigmaSpace: 坐标空间中滤波器的sigma值,如果该值较大,则意味着颜色相近的较远的像素将相互影响,从而使更大的区域中足够相似的颜色获取相同的颜色。当d>0时,d指定了邻域大小且与sigmaSpace五官,否则d正比于sigmaSpace.
borderType: 边界模式,指定处理边界像素时如何确定图像范围外的像素的取值
cv.filter2D()2D卷积图像过滤
源:dst = cv.filter2D(img,-1,kernel)代码出处
作用: 通过定义内核kernel对图像进行模糊,锐化,轮廓或浮雕操作。它们还用于机器学习中的“特征提取”,是一项特别重要的图像处理操作。
特点:自定义内核(如3×3、5×5、7×7、9×9、11×11)对图像进行卷积参考filter2D描述
我们必须 手动定义每个内核以应用各种操作,例如平滑,锐化和边缘检测。这并不是一件简单的事情,但使用CNN就不用了定义过滤器了。
| Python: dst=cv2.filter2D(src, ddepth, kernel[, dst[, anchor[, delta[, borderType]]]]) |
在其中
src:原图像
dst:输出图像
ddepth: 目标图像的所需深度,当ddepth=-1时,表示输出图像与原图像有相同的深度。
kernel: 卷积核(或相当于相关核,需要归一化处理),单通道浮点矩阵;如果要将不同的内核应用于不同的通道,请使用拆分将图像拆分为单独的颜色平面,然后单独处理它们。
anchor: 内核的锚点,指示内核中过滤点的相对位置;锚应位于内核中;默认值(-1,-1)表示锚位于内核中心。
detal: 在将它们存储在dst中之前,将可选值添加到已过滤的像素中。类似于偏置。
borderType: 像素外推法,参见BorderTypes
形态学变换
形态学的主要用途:获取物体拓扑和结果信息,通过物体和结构元素的某些运算,得到物体更本质的形态。在图像处理中的主要应用有:
(1). 利用形态学的基本运算对图像进行观察和处理,从而达到改善图像质量的目的
(2). 描述和定义图像的各种几何参数和特征如面积、周长、连通、颗粒度、骨架和方向性
我们通过腐蚀和膨胀两种基本的形态学操作实现开运算、闭运算、形态梯度、顶帽、黑帽五种形态学操作。
腐蚀(erosion)和膨胀(dilate)的主要作用有:
. 消除噪声
. 分割(splite)独立的图像元素以及连接(join)相邻的元素
. 寻找图像中的明显的极大值区域或极小值区域
. 求出图像的梯度
cv.erode()腐蚀
源:erosion = cv.erode(img,kernel,iterations = 1)代码出处
作用:内核窗口在图像A上滑动,将内核B覆盖的区域最小像素值提取并代替锚点位置的像素值。白色的像素值(255)要远远大于黑色的像素值(0)。通常图像向黑色部分扩展,白色部分减小。
| Python: cv2.erode(src, kernel[, dst[, anchor[, iterations[, borderType[, borderValue]]]]]) -> dst |
在其中
src:原图像,可以是Mat类型,可以是任意通道图像,图像深度只能是CV_8U、CV_16U、CV_16S、CV_32F或CV_64F其中的一个。
dst:输出图像,和原图像有相同的尺寸和类型。
kernel: 用于腐蚀操作的kernel,当参数=Mat(),即NULL时,kernel是一个锚点位于中心的3x3模板。
anchor:锚点位置
iterations: 迭代腐蚀操作次数,默认值为1
borderType: 边界模式,指定处理边界像素时如何确定图像范围外的像素的取值
cv.dilate()膨胀
源:dilation = cv.dilate(img,kernel,iterations = 1) 代码出处
作用:内核窗口在图像A上滑动,将内核B覆盖的区域最大像素值提取并代替锚点位置的像素值。与腐蚀相反,通常图像向白色部分扩展,黑色部分减小。
| Python: cv2.dilate(src, kernel[, dst[, anchor[, iterations[, borderType[, borderValue]]]]]) -> dst |
在其中
src:原图像,可以是Mat类型,可以是任意通道图像,图像深度只能是CV_8U、CV_16U、CV_16S、CV_32F或CV_64F其中的一个。
dst:输出图像,和原图像有相同的尺寸和类型。
kernel: 用于腐蚀操作的kernel,当参数=Mat(),即NULL时,kernel是一个锚点位于中心的3x3模板。
anchor: 锚点位置
iterations: 迭代腐蚀操作次数,默认值为1
borderType: 边界模式,指定处理边界像素时如何确定图像范围外的像素的取值
cv.morphologyEx() 开操作
源:opening = cv.morphologyEx(img, cv.MORPH_OPEN, kernel)代码出处
作用:对图像先腐蚀再扩张,放大了裂缝或局部降低亮度的区域
| Python: cv2.morphologyEx(src, cv.MORPH_OPEN, kernel) -> dst |
在其中
src:原图像
dst:输出图像,和原图像有相同的尺寸和类型。
kernel: 用于腐蚀操作的kernel,当参数=Mat(),即NULL时,kernel是一个锚点位于中心的3x3模板。
cv.MORPH_OPEN: 形态学打开
cv.morphologyEx() 闭操作
源:opening = cv.morphologyEx(img, cv.MORPH_CLOSE, kernel)代码出处
作用:对图像先扩张再腐蚀
| Python: cv2.morphologyEx(src, cv.MORPH_CLOSE, kernel) -> dst |
在其中
src:原图像
dst:输出图像,和原图像有相同的尺寸和类型。
kernel: 用于腐蚀操作的kernel,当参数=Mat(),即NULL时,kernel是一个锚点位于中心的3x3模板。
cv.MORPH_CLOSE: 形态学关闭
cv.morphologyEx() 形态学梯度
源:gradient = cv.morphologyEx(img, cv.MORPH_GRADIENT, kernel)=代码出处
作用:形态梯度是膨胀图与腐蚀图之差,能够保留物体的边缘轮廓
| Python: cv2.morphologyEx(src,cv.MORPH_GRADIENT, kernel) -> dst |
在其中
src:原图像
dst:输出图像,和原图像有相同的尺寸和类型。
kernel: 用于腐蚀操作的kernel,当参数=Mat(),即NULL时,kernel是一个锚点位于中心的3x3模板。
cv.MORPH_GRADIENT: 形态学梯度
cv.morphologyEx() 顶帽
源:tophat = cv.morphologyEx(img, cv.MORPH_TOPHAT, kernel)代码出处
作用:顶帽操作是原图像与开运算结果图之差,注意内核太小可能没有结果
| Python: cv2.morphologyEx(src,cv.MORPH_TOPHAT, kernel) -> dst |
在其中
src:原图像
dst:输出图像,和原图像有相同的尺寸和类型。
kernel: 用于腐蚀操作的kernel,当参数=Mat(),即NULL时,kernel是一个锚点位于中心的3x3模板。
cv.MORPH_TOPHAT: 顶帽操作
cv.morphologyEx() 黑帽
源:blackhat = cv.morphologyEx(img, cv.MORPH_BLACKHAT, kernel)代码出处
作用:黑帽操作是原图像与闭运算结果图之差,注意内核太小可能没有结果
| Python: cv2.morphologyEx(src,cv.MORPH_BLACKHAT, kernel) -> dst |
在其中
src:原图像
dst:输出图像,和原图像有相同的尺寸和类型。
kernel: 用于腐蚀操作的kernel,当参数=Mat(),即NULL时,kernel是一个锚点位于中心的3x3模板。
cv.MORPH_BLACKHAT: 黑帽操作
import cv2 as cv
import numpy as np
import matplotlib.pyplot as plt
def test1():
# 形态学操作
# 图像侵蚀erode、膨胀dialte、开操作、闭操作、形态学梯度、顶帽、黑帽
img = cv.imread('j.png', 0)
kernel = np.ones((5, 5), np.uint8) # 5*5全为1的内核
erosion = cv.erode(img, kernel, iterations=1) # erosion
dilation = cv.dilate(img, kernel, iterations=1) # dilation
opening = cv.morphologyEx(img, cv.MORPH_OPEN, kernel) # 开操作
closing = cv.morphologyEx(img, cv.MORPH_CLOSE, kernel) # 闭操作
gradient = cv.morphologyEx(img, cv.MORPH_GRADIENT, kernel) # 形态学梯度
kernel01 = np.ones((9, 9), np.uint8) # 9*9全为1的内核
tophat = cv.morphologyEx(img, cv.MORPH_TOPHAT, kernel01) # 顶帽
blackhat = cv.morphologyEx(img, cv.MORPH_BLACKHAT, kernel01) # 黑帽
# BGR to RGB
img_RGB = cv.cvtColor(img, cv.COLOR_BGR2RGB)
erosion_RGB = cv.cvtColor(erosion, cv.COLOR_BGR2RGB)
dilation_RGB = cv.cvtColor(dilation, cv.COLOR_BGR2RGB)
opening_RGB = cv.cvtColor(opening, cv.COLOR_BGR2RGB)
closing_RGB = cv.cvtColor(closing, cv.COLOR_BGR2RGB)
gradient_RGB = cv.cvtColor(gradient, cv.COLOR_BGR2RGB)
tophat_RGB = cv.cvtColor(tophat, cv.COLOR_BGR2RGB)
blackhat_RGB = cv.cvtColor(blackhat, cv.COLOR_BGR2RGB)
plt.subplot(421), plt.imshow(img_RGB, 'gray'), plt.title('image')
plt.subplot(422), plt.imshow(erosion_RGB, 'gray'), plt.title('erosion')
plt.subplot(423), plt.imshow(dilation_RGB, 'gray'), plt.title('dilation')
plt.subplot(424), plt.imshow(opening_RGB, 'gray'), plt.title('opening')
plt.subplot(425), plt.imshow(closing_RGB, 'gray'), plt.title('closing')
plt.subplot(426), plt.imshow(gradient_RGB, 'gray'), plt.title('gradient')
plt.subplot(427), plt.imshow(tophat_RGB, 'gray'), plt.title('tophat')
plt.subplot(428), plt.imshow(blackhat_RGB, 'gray'), plt.title('blackhat')
plt.show()
if __name__ == '__main__':
test1()

图像梯度
cv.Sobel() 算子和Scharr算子
源:sobelx = cv.Sobel(img,cv.CV_64F,1,0,ksize=5)代码出处 参考链接
作用:Sobel算子是一个离散微分算子(discrete differentiation operator),它用来计算图像灰度函数的近似梯度并结合了高斯平滑和微分求导。
特点:Sobel算子一般与高斯滤波配合使用。
Sobel算子是基于图像边缘部分,像素值会出现较大的变化,因此在边缘部分求取一阶导得到极值点的方法。(图像的高频分量一般出现在像素值显著改变的地方,而高频分量的出现就容易勾画出图像的轮廓。)
| Python: cv2.Sobel(src, ddepth, dx, dy[, dst[, ksize[, scale[, delta[, borderType]]]]]) -> dst |
在其中
src:原图像
dst:输出图像,和原图像有相同的尺寸和类型。
ddepth: 输出图像深度,为-1时,表示与原图像深度相同

dx: x方向上的差分阶数
dy: y方向上的差分阶数
ksize = 3: Sobel函数核尺寸,只能是1、3、5、7中的一个,默认值是3。当ksize=1时,内核形式为3x1或1x3(没有高斯平滑),ksize=1只能用于一阶或二阶x或y方向上的导数。当ksize=CV_SCHARR(-1) 是一个特殊值,将会调用内核为3x3比Sobel计算的结果精确的Scharr滤波器
scale = 1: 计算导数值可选的缩放因子,默认值是1表示没有缩放
borderType = BORDER_DEFAULT:边界模式,可以查询borderInterpolate得到详细信息。
Laplace算子
源:laplacian = cv.Laplacian(img,cv.CV_64F)代码出处 参考链接
作用:Laplace算子与Sobel算子相比,它是二阶求导找极值点。其定义为:
特点:函数只有在ksize>1时才能正常计算,当ksize==1时,Laplacian将由下面的模板进行计算:
Laplace算子内部调用了Sobel算子
| Python: cv2.Laplacian(src, ddepth[, dst[, ksize[, scale[, delta[, borderType]]]]]) -> dst |
在其中
src:原图像
dst:输出图像,和原图像有相同的尺寸和类型。
ddepth: 输出图像深度,为-1时,表示与原图像深度相同
ksize: 用于计算二阶导的kernel尺寸,可以查看getDerivKernels函数查看详细信息,尺寸必须是正奇数。
scale: Laplacian算子的可选因子,有默认值1,此时没有应用缩放因子,可查看getDerivKernels查看详细信息
delta: 存储目标图像前可选的delta值,有默认值
borderType = BORDER_DEFAULT:边界模式,可以查询borderInterpolate得到详细信息。
import cv2 as cv
import numpy as np
import matplotlib.pyplot as plt
def test2():
# 图像梯度
img = cv.imread('dave.jpg', 0)
laplacian = cv.Laplacian(img, cv.CV_64F) # 输出图像深度为64位浮点型,ddepth=cv.CV_64F
sobelx = cv.Sobel(img, cv.CV_64F, 1, 0, ksize=5) # x方向一阶导,y方向不求导,水平Sobel滤波器
sobely = cv.Sobel(img, cv.CV_64F, 0, 1, ksize=5) # 垂直Sobel滤波器
plt.subplot(2, 2, 1), plt.imshow(img, cmap='gray')
plt.title('Original'), plt.xticks([]), plt.yticks([])
plt.subplot(2, 2, 2), plt.imshow(laplacian, cmap='gray')
plt.title('Laplacian'), plt.xticks([]), plt.yticks([])
plt.subplot(2, 2, 3), plt.imshow(sobelx, cmap='gray')
plt.title('Sobel X'), plt.xticks([]), plt.yticks([])
plt.subplot(2, 2, 4), plt.imshow(sobely, cmap='gray')
plt.title('Sobel Y'), plt.xticks([]), plt.yticks([])
plt.show()
if __name__ == '__main__':
test2()

SobelX可以理解为x方向的过滤器,SobelY为y方向的过滤器。
一个重要事项
黑色到白色的过渡被视为正斜率(具有正值),而白色到黑色的过渡被视为负斜率(具有负值)。因此,当您将数据转换为np.uint8时,所有负斜率均设为零。简而言之,您会错过这一边缘信息。
如果要检测两个边缘,更好的选择是将输出数据类型保留为更高的形式,例如cv.CV_16S,cv.CV_64F等,取其绝对值,然后转换回cv.CV_8U。
import cv2 as cv
import numpy as np
import matplotlib.pyplot as plt
def test3():
# 防止错过图像的一些边缘信息
# 将输出数据类型保留为更高的形式,例如cv.CV_16S,cv.CV_64F等,取其绝对值,然后转换回cv.CV_8U。
img = cv.imread 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









