







问题描述:df表是学生的刷卡记录数据,df1表是学生的各个课程的绩点数据,现在要计算每个学生的刷卡频数以及其对应的平均绩点。
解决:先用value_counts计算df表的频数,再用groupby计算每个学生的平均绩点,最后再用merge函数连接。
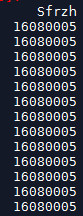

value_counts()计算频数
value_counts是对计算频数的函数需要注意,value_counts生成的结果索引是sfrzh,值是频数,如果需要将索引转化为列还需要转化一下。
import pandas as pd
from datetime import datetime
df = pd.read_csv(r'G:\zhxy\20190921\tsg.csv')
df 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 3350
3350











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









